목차
- JIT 컴파일이란?
- JIT 컴파일러 vs AOT 컴파일러
- JIT 컴파일 vs 인터프리터
- JIT 컴파일러 기능들
- JIT 컴파일러 종류 (C1, C2, Graal)
- Tierd 컴파일 (단계별 컴파일)
- JIT 컴파일러 튜닝
JIT 컴파일이란?
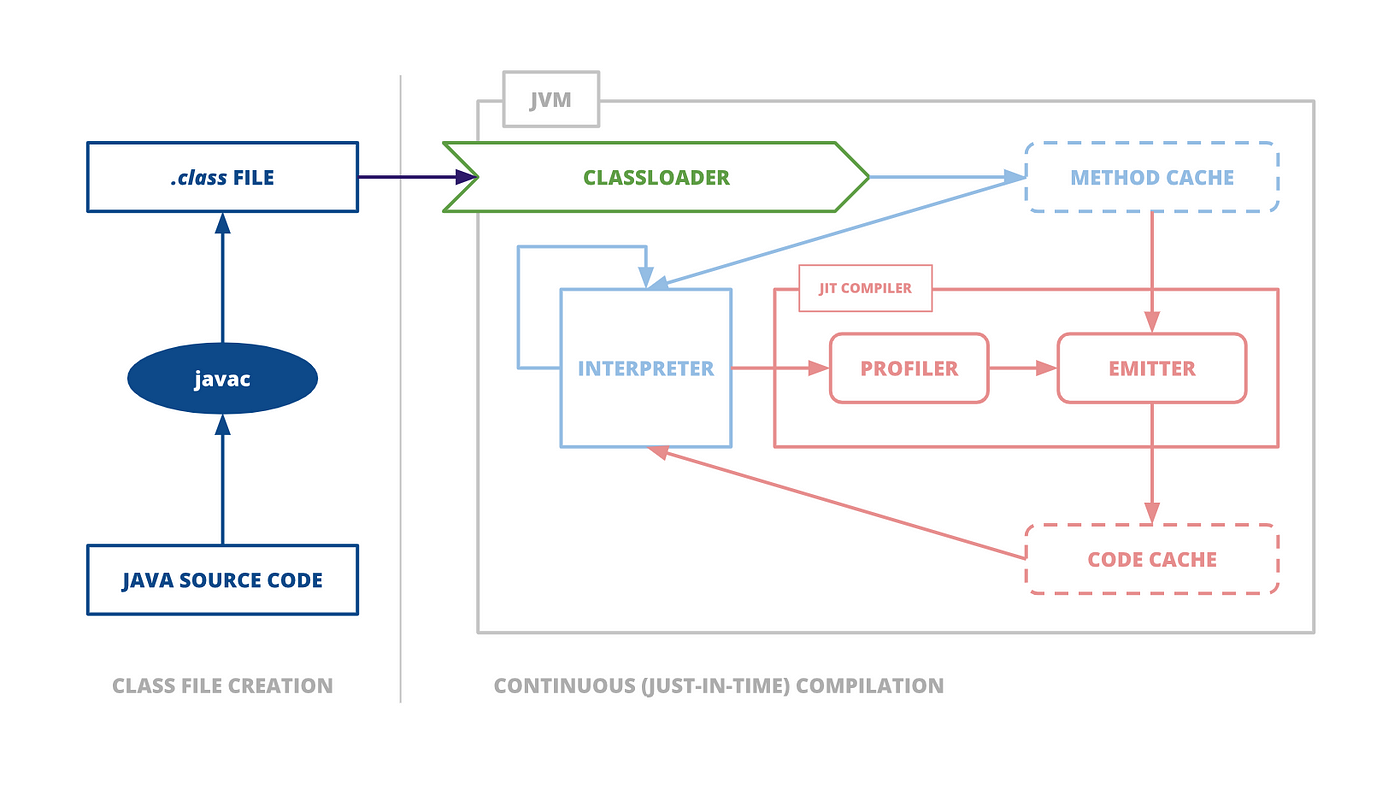
자바 프로그램은 바이트코드 인터프리터가 가상화한 스택 머신에서 명령어를 실행하며 시작됩니다. JVM에서 CPU를 추상화한 구조라서, 다른 플랫폼에 의존적이지 않고 실행이 가능합니다.
단, 프로그램이 성능을 최대로 내려면, 네이티브 기능을 활용해 CPU에서 직접 프로그램을 실행시켜야 합니다.
이를 위해, JVM은 프로그램 단위(메서드와 루프)를 Interpreted 바이트코드에서 Native code(기계어)로 컴파일합니다.
JVM은 인터프리티드 모드로 실행하는 동안, 애플리케이션을 모니터링하면서 가장 자주 실행되는 코드 파트를 발견해 JIT 컴파일을 수행합니다.
프로그램의 런타임 실행 정보를 수집해서 어느 부분이 가장 자주 쓰이고, 어느 부분을 최적화해야 가장 효과가 좋은지 프로파일을 만들어 결정을 내리는 것입니다.
- 이러한 기법은
프로파일 기반 최적화(PGO)라고 합니다. - 즉, 특정 메서드가 어느 threshold 값을 넘어가면,
프로파일러(Profiler)가 특정 코드 섹션을 컴파일/최적화합니다.
인터프리티드 모드란?
위의 그림처럼 JVM은 인터프리티드 모드와 JIT(Just-In-Time) 컴파일 모드를 함께 사용합니다.
인터프리티드 모드에서는 소스 코드를 한 줄씩 읽어들여서 해석하고 실행합니다. 이 과정에서는 빠르게 실행할 수 있지만, 반복적으로 실행되는 코드가 있을 경우 이를 매번 해석하고 실행하는 것은 비효율적입니다.
단, JVM은 실행되는 코드를 모니터링하여 가장 자주 실행되는 코드 부분을 찾아내고, 이를JIT 컴파일러를 사용하여 네이티브 코드로 변환합니다. 이렇게 변환된 코드는 이후부터는 인터프리터 모드보다 더욱 빠르게 실행됩니다.
프로파일러(Profiler)란?
프로파일(Profile)은 프로그램이 실행될 때, 실행 시간, 메모리 사용량, 함수 호출 횟수 등과 같은 정보를 수집하고 분석하여 프로그램의 동작을 분석하는 과정을 말합니다. 프로파일링을 통해 프로그램의 병목 지점을 찾고, 최적화할 부분을 결정할 수 있습니다.
프로파일러(Profiler)는 프로그램의 실행 정보를 수집하여 분석하는 도구입니다. 대표적으로 Java에는VisualVM이 있습니다.
JIT 컴파일러 vs AOT 컴파일러
C/C++ 언어는 소스코드를 컴파일하면 컴파일한 서버의 운영체제에 맞게, 기계어가 생성된다는 것을 알고 있습니다. 즉, C/C++은 정적 컴파일을 하여 소스코드를 컴파일합니다.
여기서 C/C++ 처럼 정적 컴파일을 해주는 컴파일러를 AOT 컴파일러(Ahead-of-Time)라고 합니다.
그리고, JIT 컴파일러는 앞서 살펴본 것처럼, 동적으로 코드를 컴파일하는 컴파일러를 의미합니다.
JIT 컴파일러는 왜 런타임에 컴파일하는가?
근본적인 질문입니다. 왜 JIT 컴파일러는 런타임에 컴파일할까요?
우선 AOT 컴파일러를 통해 컴파일 하게 되면, 어떤 식으로든 최적화할 기회는 단 한번입니다. 왜? 컴파일한 뒤에 기계어를 저장하고 기계어가 실행되기 때문입니다.
- 또한, 컴파일한 코드가 실행될 수 있도록 활용할 수 있는 모든 리소스를 사용하는 것이 아닌, 실제로 그렇지 못한 상황이 발생한다는 상황까지 고려해서 보수적인 선택을 해야합니다.
- 즉, 사용 가능한 프로세서 기능에 대해 최악의 상황도 고려해서 가장 안전한 선택을 해야한다는 것입니다.
근데 앞서 말했듯이 JIT 컴파일러는 런타임 시에 프로그램(정확히는 바이트코드)을 고도로 최적화한 기계어로 변환해줍니다.
- 즉, 프로그램의 런타임 실행 정보를 수집해서 어느 부분이 가장 자주 쓰이고, 언 부분을 최적화해야 가장 효과가 좋은지 프로파일을 만들어 결정을 내리는 것입니다.
- 이러한 기법은
프로파일 기반 최적화(PGO)라고 합니다.
단, 런타임 시에 컴파일되기에 바이트코드를 기계어로 변환하는 비용을 런타임에 지불해야합니다. 이 과정에서 프로그램 실행에만 온전히 동원됐을 일부 리소스(CPU 사이클, 메모리)가 소비되므로 JIT 컴파일러는 산발적으로 수행됩니다.
- 또, JVM은 최적화하면 가장 좋은 지점을 파악하기 위해(즉, 어디가 핫스팟(절호점)인지 찾고자) 각종 프로그램 관련 지표를 수집합니다.
JIT 컴파일 vs 인터프리터
JVM은 HotspotVM 이라고도 불리는데, 이 Hotspot이라는 단어는 Java의 컴파일 방법에서 유래된 단어입니다. HotspotVM은 핫스팟(자주 호출되고 실행되는 영역)을 찾아내 컴파일을 최적화합니다.
근데 JVM은 코드를 실행할 때 바로 코드 컴파일을 하지 않습니다. 여기에는 기본적인 이유가 두 가지가 있습니다.
- 첫째, 코드가 한 번만 실행된다면 컴파일은 헛수고다.
- 컴파일해서 컴파일된 코드를 한번만 실행하는 것보다 자바 바이트코드를 인터프리트하는 편이 더 빠를 것입니다.
- 둘째, 최적화 때문입니다.
- JVM이 특정 메소드나 루프를 실행하는 시간이 길어질 수록 코드에 대해 얻어지는 정보가 많습니다. 이를 통해 JVM이 코드를 컴파일할 때 최적화를 많이 적용할 수 있습니다.
첫 번째 이유의 예시를 들어보겠습니다.
public class RegisterTest{
private int sum;
public void calculateSum(int n){
for(int i=0;i<=n;i++){
sum += i;
}
}
}위의 코드에서, 인스턴스 변수인 sum은 메인 메모리 내에 있어야 하지만 메인 메모리에서 매번 값을 검색한다면 성능은 형편 없을 것입니다.
최적화를 한다면 컴파일러는 sum의 초기값을 레지스터에 로드하고 레지스터내의 값을 이용해 루프를 수행한 후 메인 메모리에 결과 값을 저장할 것입니다.
이 최적화는 매우 효과적이지만 한 번 사용되고 사용되지 않을 메서드에게 많은 메모리를 할당해준다는 것은 자원 낭비가 됩니다. 추후 다른 핫스팟에게 메모리를 할당해주지 못하는 문제의 원인이 될 수 있어서 성능 저하의 원인이 될 수 있습니다.
그렇기에 핫스팟이지 않은 영역(메서드)는 인터프리터 방식으로 호출되는 것이 훨씬 효율적일 것입니다.
Tip!🔥 JVM의 컴파일 단위는 메서드이므로, 메서드의 역할을 잘 구분지어 설계해둔다면 자주 호출되는 메서드가 명확해지므로 최적화할 때 훨씬 간편해집니다.
두 번째 원인(최적화)에 대해서, 설명해보겠습니다.
b = obj1.equals(obj2); equals() 메소드의 경우 모든 자바 객체에서 사용할 수 있는 메소드이며 흔히 오버라이드 됩니다.
인터프리터는 위의 문장에 맞닥뜨릴 때 실행시킬 equals() 메소드가 뭔지 알기 위해서 obj1의 타입을 찾기 위해 동적 look up을 해야 합니다. 이는 꽤 시간이 걸립니다.
시간이 흐르면서 이 문장을 많이 실행 해봤고 매번 obj1의 타입이 java.lang.String 이라는 사실을 알게되었다고 가정해봅시다.
그러면 JVM은 Object.equals()를 String.equals()로 최적화한 코드를 만들 수 있습니다.
JIT 컴파일러 기능들
코드 캐시(Code cache)
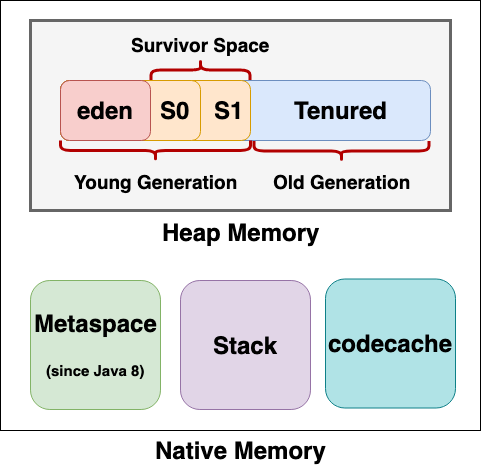
JVM 내에는 코드 캐시(Code cache) 라는 메모리영역이 있는데, 이 곳에는 JIT 컴파일드 코드가 저장됩니다. 뿐만아니라, 인터프리터 관련 코드 등 JVM 자체 네이티브 코드도 함께 들어있습니다.
JVM 시작 시, 코드 캐시는 설정된 값으로 최대 크기가 고정되므로 확장이 불가능합니다. 코드 캐시가 꽉 차면 그 때부터 더이상 JIT 컴파일은 안되며, 컴파일되지 않은 코드는 인터프리터 모드로만 실행됩니다.
- 즉, 애플리케이션의 많은 양의 부분이 인터프리터로 실행될 수 있다는 말입니다.
코드 캐시는 미할당 영역(unallocated region)과 프리 블록 연결 리스트를 담은 힙으로 구현됩니다. 네이티브 코드가 제거될 때마다 해당 블록이 프리 리스트에 추가됩니다. 블록 재활용은 Code cache sweeper(코드 캐시 스위퍼)라는 프로세스가 담당합니다.
다음과 같은 경우에는, Native code가 코드 캐시에서 제거됩니다.
- 역최적화될 때
- 다른 컴파일 버전으로 교체됐을 때 (단계별 컴파일)
- 메서드를 지닌 클래스가 언로딩될 때
역최적화(Deoptimization)란, 최적화된 코드가 더 이상 최적화 상태가 아니게 되는 것을 의미합니다. 보통 최적화된 코드는 일반적인 실행 경로에서는 매우 효율적이지만, 예외 상황이나 특정한 실행 경로에서는 최적화된 코드가 사용되지 못하고, 예상치 못한 결과를 초래할 수 있습니다.
역최적화는 JIT 컴파일러가 생성한 네이티브 코드를 해제하고, 원래의 바이트 코드로 다시 컴파일하는 작업을 수행합니다. 이 때, 역최적화가 발생하면, 네이티브 코드가 코드 캐시에서 제거되므로, 다시 최적화된 코드가 생성되기까지의 시간이 필요합니다.
Segmented Code cache
코드 캐시는 3가지 영역으로 나뉩니다.
Non-method: 이 영역에는 컴파일러 버퍼 및 바이트코드 인터프리터와 같은 비메서드 코드가 포함되어 있습니다. 이 코드 유형은 코드 캐시에 영원히 남아 있습니다. 코드 힙의 크기는 3MB로 고정되어 있으며 나머지 코드 캐시는 프로파일링된 코드 힙과 프로파일링되지 않은 코드 힙에 고르게 분산됩니다.Profiled: 이 영역에는 수명이 짧으며(short lifetime), 가볍게 최적화(lightly optimized)되고 프로파일링된 메서드(profiled) 가 포함되어 있습니다.Non-profiled: 이 영역에는 수명이 길고(long lifetime), 완전히 최적화되고 프로파일링되지 않은 메서드 가 포함되어 있습니다.
코드 캐시의 크기는 크면 클수록 좋은가?
그러면 최대 코드 캐시로 실제 큰 값을 지정하여 공간이 부족하지 않게 하면 되지 않을까? 라고 생각할 수 있습니다.
이는 실행되는 머신에서 사용할 수 있는 가상 메모리의 크기에 따라 달려 있습니다.
1GB로 코드 캐시 사이즈를 명시했다면 JVM은 네이티브 메모리 크기를 1GB로 예약합니다. 이 메모리는 필요로 하기 전까지 할당되진 않겠지만 예약되어 있으므로 이 메모리를 제외한 나머지 메모리에서 자원을 사용할 것입니다.
즉 예약 조건을 만족시키기 위해 머신에서 이용 가능한 가상 메모리가 충분하다면 사용하면 됩니다.
코드 캐시의 최대 크기는 -XX:ReservedCodeCacheSize=<n> 으로 조정가능합니다.
OSR(On-Stack-Replacment, 온-스택 치환)
JVM의 기본 컴파일 단위는 전체 메서드입니다. 따라서 한 메서드에 해당하는 바이트코드는 한꺼번에 네이티브 코드로 컴파일됩니다. JVM에는 핫 루프를 OSR 이라는 기법을 이용해 컴파일하는 기능이 있습니다.
OSR 은 어떤 메서드가 컴파일할 만큼 자주 호출되지는 않지만, 컴파일하기 적합한 루프가 포함돼있고 루프 바디 자체가 메서드인 경우에 사용합니다.
JVM은 klass 메타데이터 구조체에 있는 vtable 을 이용해 JIT 컴파일을 구현합니다.
klass, vtable, 포인터 스위즐링
JVM은 멀티 스레드 C++ 어플리케이션입니다. 모든 자바 프로그램은 OS 관점에서는 결국 멀티스레드 어플리케이션의 일부일 뿐입니다. 심지어 싱글 스레드 자바 어플리케이션이라고 하더라도, 결국 VM 스레드와 함께 실행되는 구조입니다.
- 공식 Github를 확인해보면 JVM이 C++로 구현되어 있다는 것을 알 수 있습니다.
JIT 컴파일 서브시스템을 구성하는 스레드는 JVM 내부에서 가장 중요한 스레드들입니다. 컴파일 대상 메서드를 찾아내는 프로파일링 스레드, 실제 기계어를 생성하는 컴파일 스레드도 다 여기에 포함됩니다.
컴파일 대상이 된 메서드는 컴파일러 스레드에 올려놓고 백그라운드에서 컴파일됩니다. 컴파일 과정은 아래 그림과 같습니다.
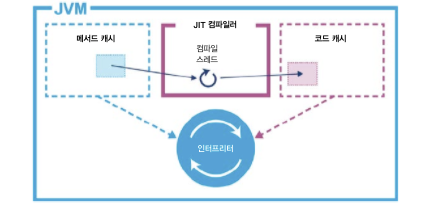
최적화된 기계어가 생성되면 해당 klass의 vtable 은 새로 컴파일된 코드를 가리키도록 수정됩니다.
- 이렇게 vtable 포인터를 업데이트하는 작업을
포인터 스위즐링(pointer swizzling)이라고 합니다.
즉, 앞으로 컴파일된 메서드를 호출하는 코드는 컴파일드 모드로 실행되지만, 현재 인터프리티드 모드로 실행 중인 스레드는 끝까지 인터프리티드 모드로 동작합니다. 물론 다음에 다시 호출되면 컴파일드 모드로 실행됩니다.
인라인 (Inline)
인라인(inline)은 메서드 호출 시 해당 메서드의 코드를 호출 부분에 직접 삽입하여 실행 속도를 높이는 최적화 기법입니다. 이는 컴파일러가 하는 최적화 기법 중 하나입니다.
일반적으로 메서드 호출 시 호출 스택에 메서드의 정보를 저장하고, 호출이 끝나면 스택에서 해당 정보를 제거합니다. 이 과정에서 스택에 대한 접근이 발생하며, 이는 프로그램 실행 속도를 느리게 만들 수 있습니다.
객체 지향 설계를 따르는 코드는 메서드가 하나의 역할만을 하기 위해서, 메서드를 분리하는 경우가 많습니다.
즉, 추후 유지보수를 위해, 객체지향 방식으로 작성한 코드 방식이 성능에 영향을 줄 수 있다는 것입니다...
하지만 JVM은 이런 종류의 메소드들을 기계적으로 인라인(inline)으로 만들어줌으로써 성능을 최적화시킵니다.
예시는 다음과 같습니다.
int result = addNumbers(1, 2); // 메서드 호출
public static int addNumbers(int a, int b) {
return a + b;
}인라인 메소드로 컴파일된 코드는 다음과 같습니다.
int result = 1 + 2 // inline즉, 메서드를 호출하지 않음으로써, 스택에 대한 접근을 최소화시켜 성능을 최적화시킬 수 있는 것입니다.
인라이닝은 디폴트로 사용 가능하며, 실제로 반드시 사용해야 할 정도로 성능을 매우 효과적으로 향상시킵니다.
-XX:-Inline플래그를 통해 사용하지 않을 수도 있습니다.
기본적으로 메소드의 인라인화를 결정하는 요소는 얼마나 자주 호출되는 가와 메소드의 크기 입니다.
- 메서드의 크기가 너무 크면 인라인(inline)하지 않습니다.
- 단,
-XX:MaxFreqInlineSize=<n>,-XX:MaxInlineSize=<n>옵션을 통해 어플리케이션의 성능을 최적화시킬 수 있습니다.
탈출분석 (Escape Analysis)
Escape Analysis 는 C2 Compiler가 실행 중인 코드의 객체를 분석하여, 객체가 특정 메서드나 스레드를 벗어나지 않고 사용되는 경우, 해당 객체를 스택에 할당하거나, 동기화 없이 스레드 간 공유할 수 있는 적절한 위치에 위치시키는 최적화 기법입니다.
이러한 Escape Analysis를 통해 불필요한 객체 생성과 GC의 비용을 줄일 수 있으며, 실행 시간과 메모리 사용량을 줄이는데 도움을 줄 수 있습니다.
Escape Analysis 기법에서는 객체를 다음 3가지의 이스케이프 상태(Escape state) 중 하나로 지정될 수 있습니다.
기본적으로는 객체는 Heap 영역에 저장되지만, 메서드 내에서 생성된 객체의 경우에는 다음과 같이 최적화를 진행합니다.
GlobalEscape- 해당 객체가 메서드 내에서 생성되었으며, 메서드 외부에서도 참조되는 경우를 의미합니다. 이 경우 객체는
힙 영역에 할당되어 GC의 대상이 됩니다.
- 해당 객체가 메서드 내에서 생성되었으며, 메서드 외부에서도 참조되는 경우를 의미합니다. 이 경우 객체는
ArgEscape- 해당 객체가 메서드의 인자로 전달되어 메서드 내에서 벗어나게 되는 상태를 말합니다. 즉, 해당 객체가 메서드 내에서 생성되었지만, 메서드의 호출이 종료된 후에는 해당 객체에 대한 참조가 유지되지 않는 경우입니다.
- 이러한 객체는
스택 영역에 생성되며, GC의 대상이 아닙니다.
NoEscape- 해당 객체가 메서드 내에서 생성되었으며, 해당 메서드 내에서만 사용되는 경우를 의미합니다.
- 이 경우 객체는 메서드 내에서만 사용되기 때문에, 이러한 객체는
스택 영역에 할당되며, GC의 대상이 아닙니다.
Escape Analysis 기법을 이용해 메모리와 GC의 부담을 줄여 어플리케이션의 성능을 최적화할 수 있습니다.
예시로 Escape Analysis 이해하기
public class Example {
public static void main(String[] args) {
Point p = new Point(3, 4);
int x = p.getX();
int y = p.getY();
System.out.println("x: " + x + ", y: " + y);
}
}
class Point {
private int x;
private int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int getX() {
return x;
}
public int getY() {
return y;
}
}위의 예제에서, Point 객체가 메서드 내부에서 생성되고, getX()와 getY() 메서드를 호출하여 객체의 필드값을 얻어옵니다.
이 때, Point 객체는 메서드 내부에서 생성되고 메서드 내부에서 사용되므로, 해당 객체는 NoEscape 상태입니다.
따라서, JVM은 해당 객체를 스택 메모리에 생성하고 GC 비용을 줄이기 위해 힙 메모리에 생성하지 않을 수 있습니다.
public class Factorial {
private BigInteger factorial;
private int n;
public Factorial(int n) {
this.n = n;
}
public synchronized BigInteger getFactorial(){
if(factorial == null) {
factorial = BigInteger.valueOf(0);
}
return factorial;
}
}public List<BigInteger> getList() {
// 팩토리얼 값 100개를 저장
List<BigInteger> list = new ArrayList<>();
for (int i = 0; i < 100 ; i++) {
Factorial factorial = new Factorial(i);
list.add(factorial.getFactorial());
}
return list;
}코드를 보면 Factorial 객체의 스코프는 루프 내(for문)에서만 참조됩니다. 그 외 다른 코드에서는 Factorial 객체에 접근하지 않습니다.
이와 같은 을 통해서 JVM은 최적화를 할 수 있습니다.
- getFactorial() 메소드를 호출할 때 동기화 락(synchronization lock)을 걸 필요가 없습니다. 락을 삭제해줍니다.
- for 문에서 사용되는 Factorial 객체는 스코프가 루프 내이므로, 스택 영역에 저장함으로써 메모리를 최적화하고 GC의 부담을 줄입니다.
JIT 컴파일러 종류 (C1, C2, Graal)
JVM 내에는 C1, C2 라는 두 가지 JIT 컴파일러가 있습니다. 각각 클라이언트 컴파일러, 서버 컴파일러라고 불리기도 합니다.
그리고 최근에 나온 컴파일러인 Graal 컴파일러가 있습니다.
C1 컴파일러와 C2 컴파일러
JVM 내에는 C1, C2 라는 두 가지 JIT 컴파일러가 있습니다. 각각 클라이언트 컴파일러, 서버 컴파일러라고 불리기도 합니다.
C1 컴파일러는 GUI 어플리케이션 및 기타 "클라이언트" 프로그램에, C2 컴파일러는 실행시간이 긴 "서버" 프로그램에서 주로 사용됐지만, 요즘 자바 어플리케이션에서는 이렇게 구분짓지 않고 JVM은 새로운 환경에 맞게 최대한 성능을 발휘하도록 변화했습니다.
C1, C2 컴파일러 모두 핵심 측정값, 즉 메서드 호출 횟수에 따라 컴파일이 트리거됩니다. 호출 횟수가 특정 임계값에 이르면 그 사실을 VM이 알림 받고 해당 메서드를 컴파일 큐에 넣습니다.
컴파일 프로세스는 가장 먼저 메서드의 내부 표현형을 생성한 다음, 인터프리티드 단계에서 수집한 프로파일링 정보를 바탕으로 최적화 로직을 적용합니다.
- 같은 코드라도 C1와 C2가 생성한 내부 표현형은 전혀 다릅니다. C1은 C2보다 컴파일 시간도 더 짧고, 단순하게 설계된 이유로 C2처럼 풀 최적화는 하지 않습니다.
두 컴파일러의 주요 차이점은 코드 컴파일에 있어서 적극성의 유무 입니다.
C1 컴파일러는 C2 컴파일러보다 먼저 컴파일하기 시작합니다. 이는 C2 컴파일러보다 상대적으로 더 많은 코드를 컴파일 한다는 의미이며 코드가 실행되기 시작하는 시간동안 C1 컴파일러가 보다 더 빠를 것입니다.
Graal 컴파일러
Graal 컴파일러는 Java로 작성되고 구현된 고성능과 최적화를 위해 나온 JIT 컴파일러입니다. Java로 작성되어 있어서, 개발자 입장에서 커스터마이징해서 사용할 수 있습니다.
Graal 컴파일러의 장점들
- Flexible speculative optimizations (유연한 추측 최적화)
- Better inlining (더 나은 인라인)
- Partial escape analysis (부분탈출 분석)
- Benefits from Java tooling and IDE support (Java 도구 및 IDE 지원의 이점)
- Metacircular approach that allows for tighter code generation control (보다 엄격한 코드 생성 제어를 허용하는 Metacircular 접근 방식)
Graal 컴파일러를 JIT 컴파일러로 활성화하려면, 다음 옵션을 입력해줘야합니다.
-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompilerSLASH 2022 컨퍼런스에서의 Java Native Memory Leak 원인을 찾아서 섹션을 보면, C2 컴파일러에서 Graal 컴파일러로 바꿈으로써, 메모리 사용량과 CPU 사용율을 최적화시킨 것을 확인할 수 있습니다.
Tiered Compile (단계별 컴파일)
JVM은 Tiered Compile 모드를 지원합니다. Tiered Compile 모드는 인터프리티드 모드로 실행되다가 단순한 C1 컴파일 형식으로 바뀌고, 다시 이를 C2가 고급 최적화를 수행하는 방식으로 단계를 바꾸는 것을 의미합니다.
총 5가지의 실행 레벨이 존재합니다. 이 모든 레벨을 거치는 것은 아니고, 컴파일 방식마다 경로가 다릅니다.
- 레벨0 : 인터프리터(Interpreter) 사용
- 레벨1 : C1 컴파일러 (프로파일링 사용X)
- 레벨2 : C1 컴파일러 (프로파일링 부분 이용 - 호출카운터, 백엣지 카운터)
- 레벨3 : C1 컴파일러 (풀 프로파일링)
- 레벨4 : C2 컴파일러
전형적인 컴파일 로그를 보면 대부분의 메소드는 3레벨인 전체 C1 컴파일된 코드로 처음 컴파일된다는 걸 보여줍니다.
모든 메소드는 0레벨부터 시작하고 매우 빈번하게 수행된다면 3레벨을 거쳐서 4레벨에서 컴파일 될 것입니다. 그리고 3레벨의 코드는 진입 불가 상태가 됩니다.
만약 C2 컴파일러 큐가 가득차서 4레벨의 컴파일이 불가능하다면 프로파일 피드백을 필요로 하지않는 2레벨에서 컴파일 될 것입니다. 그 후 프로파일 정보를 모은 후, C1 컴파일러가 3레벨에서 컴파일 하고 마지막으로 C2 컴파일러 큐가 덜 바쁘다면 4레벨에서 컴파일 됩니다.
반면 C1 컴파일러 큐가 가득 차면 3레벨에서 컴파일될 예정인 메소드가 4레벨 컴파일 대상이 될 수 있습니다. 이 경우에는 2레벨로 컴파일 된 다음 바로 4레벨로 넘어갑니다.
그리고 코드가 역최적화될 때, 다시 0레벨로 갑니다.
Reference
Optimizing Java
Java Performance: The Definitive Guide
https://docs.oracle.com/en/java/javase/11/vm/java-hotspot-virtual-machine-performance-enhancements.html
https://toss.im/slash-22/sessions/3-6
https://velog.io/@youngerjesus/자바-JIT-컴파일러
