목차
- 하드 디스크 드라이버(HDD)와 솔리드 스테이트 드라이브(SSD)
- 랜덤 I/O와 순차 I/O
- 두 가지 I/O에 대한 고찰
Real MySQL 을 읽다가, 순차 I/O와 랜덤 I/O 단어가 많이 나와서, 정리해보고자 합니다.
컴퓨터는 CPU나 메모리처럼 전기적 특성을 띤 장치의 성능이 매우 빠른 속도로 발전해왔습니다. 하지만 디스크 같은 기계식 장치의 성능은 상당히 제한적으로 발전했습니다.
비록 최근에는 자기 디스크 원판에 의존하는 하드 디스크보다 SSD 드라이브가 많이 활용되고 있지만, 여전히 데이터 저장 매체는 컴퓨터에서 가장 느린 부분이라는 사실에는 변함이 없습니다. 즉, 데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관건입니다.
하드 디스크 드라이버(HDD)와 솔리드 스테이트 드라이브(SSD)
하드 디스크 드라이버(HDD)는 기계식 장치로서 어떤 기능을 수행하는 데에 병목점이 됩니다. 그래서 HDD를 대체하기 위해 솔리드 스테이트 드라이브(SSD)가 나왔습니다.
SSD는 하드 디스크 드라이브에서 데이터 저장용 플래터(원판)을 제거하고, 그 대신 NAND 플래시 메모리를 장착하고 있습니다. 디스크 원판을 기계적으로 회전시킬 필요가 없어져서 HDD에 비해 아주 빨리 데이터를 읽고 쓸 수 있습니다. 플래시 메모리는 전원이 공급되지 않아도 데이터가 삭제되지 않는 특징을 가집니다. 물론, 컴퓨터의 메모리(DRAM, Direct random access memory)에 비하면 훨씬 느립니다.
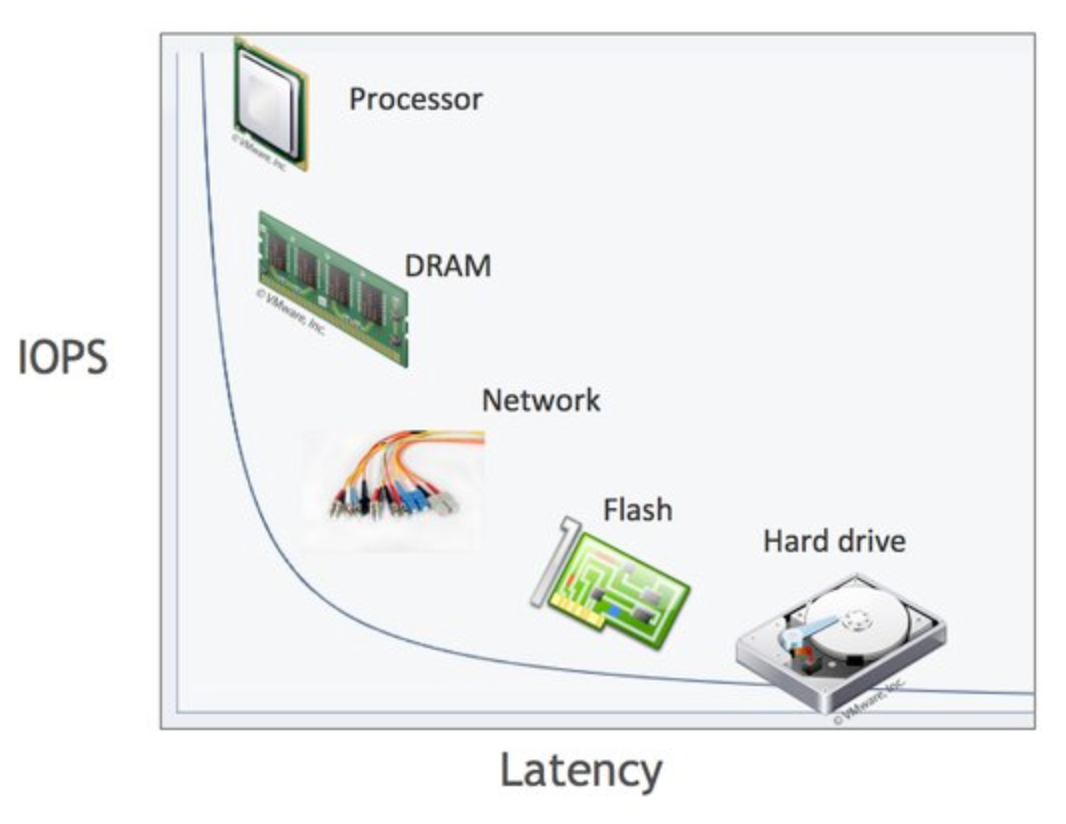
요즘은 DBMS용으로 사용할 서버에서 SSD를 채택하고 있습니다. 디스크의 헤더를 움직이지 않고, 한 번에 많은 데이터를 읽는 순차 I/O에서는 SSD가 HDD보다 조금 빠르거나 거의 비슷한 성능을 보입니다. 하지만 SSD의 장점은 HDD보다 랜덤 I/O 가 훨씬 빠르다는 점입니다.
- 대부분의 DBMS 서버에서는 순차I/O 작업보다 랜덤 I/O 작업들이 더 많기에 SSD가 최적입니다.
랜덤 I/O와 순차 I/O
우선, 랜덤 I/O(Random I/O, direct accss)는 하드 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더(disk arm)를 이동시킨 다음 데이터를 읽는 것을 의미합니다. 그리고 순차 I/O(Sequential I/O) 또한 이 과정은 같습니다.
그럼 뭐가 차이점이길래 분리했을까요? 여러 개의 데이터를 입력할 때, 순차 I/O는 디스크 헤드를 한 번만 움직이지만, 랜덤 I/O는 디스크 헤더를 데이터의 개수만큼 움직여야 합니다.
그리고 디스크 헤더를 움직이는 시간은 디스크에 데이터를 쓰고 읽는 데 걸리는 시간에서 가장 많이 차지하는 시간으로 병목이 되는 부분입니다. 그래서 여러 번 쓰기 또는 읽기를 요청하는 랜덤 I/O 작업이 작업 부하가 훨씬 더 큽니다.
하지만 SSD는 디스크 원판(플래터)를 가지지 않으므로 랜덤 I/O와 순차 I/O의 차이가 없어보이지만, 실제론 그렇지 않습니다. SSD 에서도 랜덤 I/O는 순차 I/O보다 처리율(Throughput)이 떨어집니다.
- SSD는 물리적으로 NAND 플래시 메모리에 저장된 데이터를 직접 읽고 쓰는 것이 아니라, 내부적으로 논리적인 주소를 물리적인 주소로 매핑하는 매핑 테이블을 사용합니다.
- 매핑 테이블을 업데이트하려면 NAND 플래시 메모리의 물리적인 위치를 찾아가야 하므로 랜덤 I/O의 경우에는 이 과정이 추가로 발생하여 전체 처리율이 떨어지게 됩니다.
- 만약 순차I/O라면, 논리적인 위치를 통해 알아낸 물리적인 위치를 통해 나머지 항목들도 업데이트해주면 됩니다.
랜덤 I/O와 순차 I/O 모두 파일에 쓰기를 실행하면, 반드시 동기화 (fsync, flush 작업)이 필요합니다. 그런데 순차 I/O 더라도, 파일 동기화 작업이 빈번히 발생한다면 랜덤I/O 와 같이 비효율적인 형태로 동작하게 됩니다. 그래서, 캐시 메모리가 장착된 RAID 컨트롤러를 사용해 순차 I/O를 효율적으로 처리할 수 있게 도와줍니다.
일반적으로 쿼리를 튜닝하는 것은 랜덤 I/O 자체를 줄여주는 것이 목적입니다. 즉 랜덤 I/O를 줄인다는 것은 쿼리를 처리하는 데에 꼭 필요한 데이터만 읽도록 쿼리를 개선하는 것을 의미합니다.
인덱스 레인지 스캔(Index Range scan)은 데이터를 읽기 위해 주로 랜덤 I/O를 이용하고 풀 테이블 스캔(Full Table scan)은 순차 I/O 를 사용합니다.
그래서 큰 테이블의 레코드 대부분을 읽는 작업에서는 인덱스를 사용하지 않고 풀 테이블 스캔을 사용하도록 옵티마이저가 유도하기도 합니다.
두 가지 I/O에 대한 고찰
"언제 순차 I/O를 하고, 언제 랜덤 I/O를 할까?" 에 대해 많은 문서와 블로그를 찾아봐도 명확한 답은 나오지 않았습니다.
그래서 배웠던 내용들을 종합해 생각해봤을 때, 제가 내린 결론은 다음과 같습니다.
클러스터링 인덱스를 활용한 스캔은 "순차 I/O"
클러스터링 인덱스(PK)를 이용해 레인지 스캔을 하게 되면, "순차 I/O" 방식으로 동작합니다. 왜? 클러스터링 인덱스는 메모리 상에 저장된 데이터 페이지의 논리적인 위치와 물리적으로 저장된 위치가 동일한 순서로 정렬됩니다.
그래서, 여러 개의 데이터를 조회하거나 수정할 때, 바로 옆의 데이터를 조회하면 되기 때문입니다. 그래서 랜덤 I/O 방식대로 동작할 이유가 없고, 순차 I/O 방식으로 동작하는 것이 훨씬 효율적입니다.
하지만, 클러스터링 인덱스를 통해서 조회하더라도, 순서대로 조회하는 것이 아니라 띄엄띄엄 조회하게 된다면 랜덤 I/O 방식으로 동작합니다.
물론,
클러스터링 인덱스또한 하나의 데이터에 대해 조회하거나 업데이트하는 것은 랜덤 I/O 방식이라고 봐도 무방합니다.
단,랜덤 I/O와순차 I/O를 구분짓는 차이점은 여러 개의 데이터를 어떻게 조회하는 것이므로 하나의 데이터를 조회하는 방법에 대해선 논의하지 않겠습니다.
세컨더리 인덱스를 활용한 스캔은 "랜덤 I/O"
세컨더리 인덱스는 클러스터링 인덱스와는 달리, 데이터 페이지의 위치와 물리적인 위치가 동일한 순서가 아닙니다. 세컨더리 인덱스는 인덱스 구조를 봐도, 물리적인 저장위치를 저장하는 것이 아니라, 클러스터링 인덱스의 위치를 저장하고 있습니다.
즉, 세컨더리 인덱스를 이용해 조회하는 명령은 여러 곳에 분산된 데이터를 조회하게 되므로, 랜덤 I/O 방식으로 동작합니다. 또한 수정하는 작업 또한 인덱스를 활용하므로, 여러 데이터를 동시에 수정하는 작업도 랜덤 I/O 방식으로 동작하게 됩니다.
Reference
Real MySQL 8.0.1
Operating system 10th edition - ABRHAM SILBERSCHATZ and 2 others
https://www.prepbytes.com/blog/general/difference-between-sequential-and-random-access-file/
