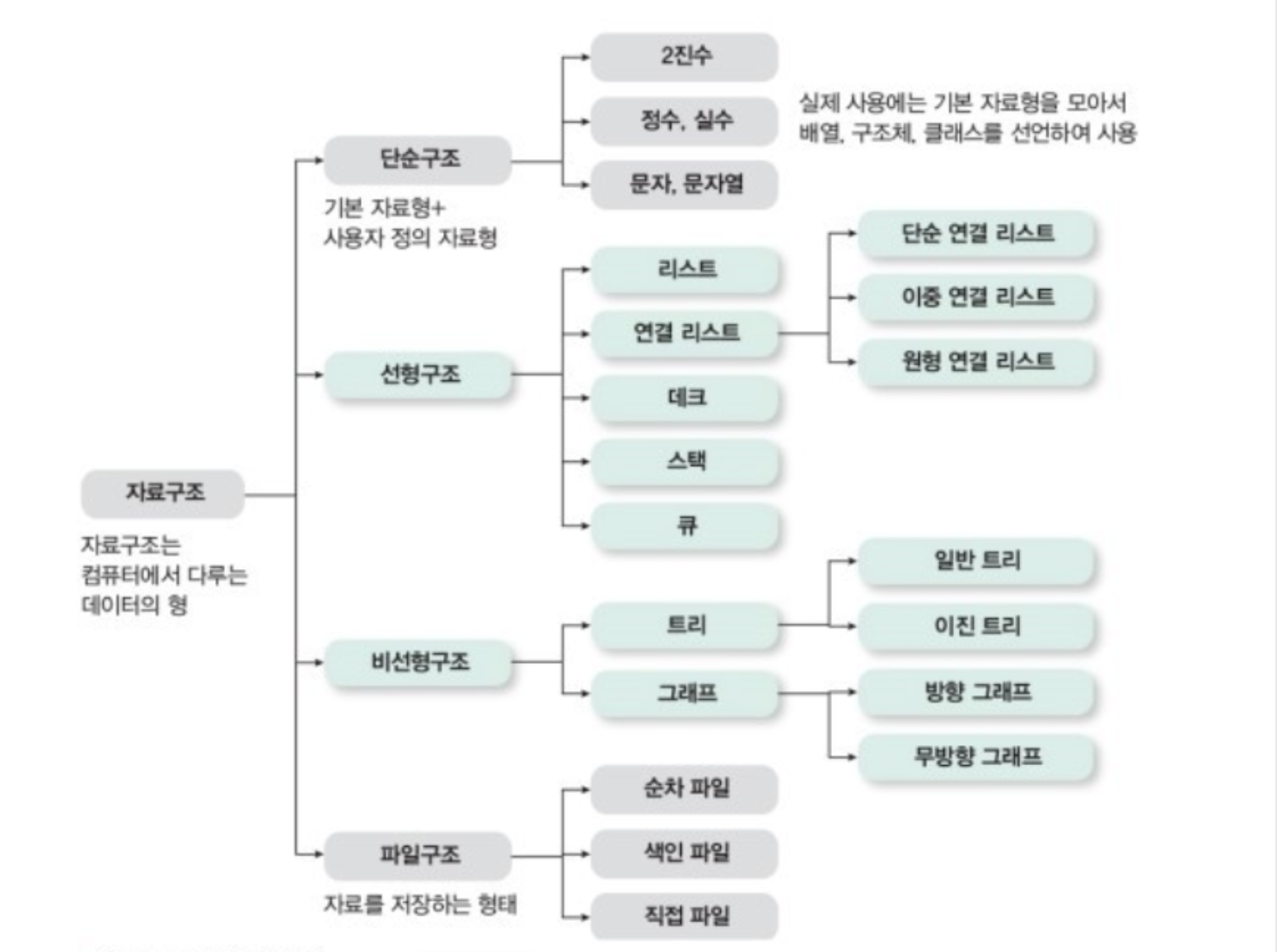
개발할 때 자주 사용하는 Object로 List Map Set이 있다.
모두 배열의 불편한 점을 개선하기 위해 나온 자료구조로만 알고 있지 정확히 개념에 대해서는 알지 못하고 있었다.
이번 기회에 특징과 차이점들을 정리하여 확실하게 파악해 두어야겠다.
참고
[자료구조] List, Map, Set 특징 정리
[자료구조] List Map Set의 특징과 차이점
Collection
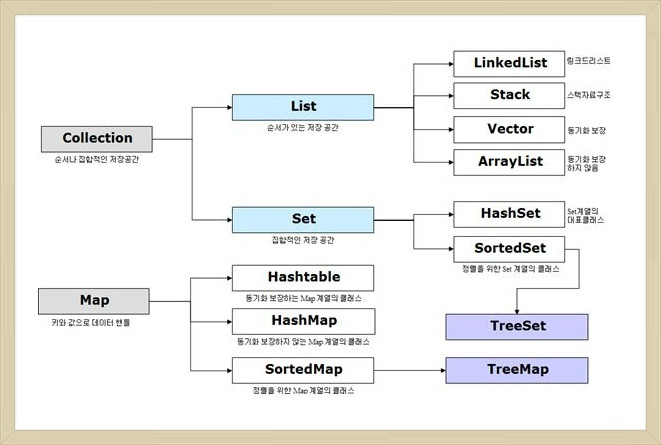
기존의 배열은 크기가 고정되어 있고 삽입 및 삭제 시간이 오래 걸린다. 이를 보완하기 위해서 동적 배열 개념인 컬렉션 프레임워크를 제공하였는데 종류는 대표적으로 List, Set, Map 등이 있다. 자료의 삽입, 삭제, 검색 등등이 용이해지고 어떠한 자료형이라도 담을 수 있으며 크기가 자유롭게 늘어난다는 강점을 가지고 있다.
List
순서와 중복이 있는 자료구조이다. 인덱스를 가지고 있고 가변적이다.
LinkedList
양방향 포인트 구조로 데이터 삽입, 삭제가 빠르지만 검색이 느리다.
ArrayList
단방향 포인트 구조로 배열을 기반으로 데이터를 저장한다. 데이터 삽입, 삭제가 느리지만 검색이 빠르다.
Map
Key, Value의 한 쌍으로 이루어진 데이터의 집합으로 Key에는 중복된 값을 입력할 수 없다. 순서를 보장하지 않고 인덱스가 존재하지 않아 iterator를 사용한다. 뛰어난 검색 속도를 가집니다.
HashMap
key와 value값으로 NULL을 허용한다. 동기화가 보장되지 않는다. 검색에 가장 뛰어난 성능을 가진다.
HashTable
key와 value값으로 NULL을 허용하지 않는다. 동기화가 보장되어 병렬프로그래밍이 가능하고 HashMap 보다 처리속도가 느리다.
LinkedHashMap
입력된 순서를 보장한다.
TreeMap
이진 탐색 트리를 기반으로 키와 값을 저장한다. Key값을 기준으로 오름차순 정렬되고 빠른 검색이 가능하다. 저장시 정렬을 하기 때문에 시간이 다소 오래 걸린다.
Set
데이터의 집합이며 순서가 없고 중복된 데이터를 허용하지 않습니다. 중복되지 않은 데이터를 구할 때 유용. index가 따로 존재하지 않기 때문에 iterator를 사용한다. 빠른 검색 속도를 가집니다.
HashSet
인스턴스의 해시값을 기준으로 저장하기 때문에 순서를 보장하지 않는다. NULL 값을 허용한다. TreeSet보다 삽입, 삭제가 빠르다.
LinkedHashSet
입력된 순서를 보장한다.
TreeSet
이진 탐색 트리를 기반으로 한다. 데이터들이 오름차순으로 정렬된다. 데이터 삽입, 삭제에는 시간이 걸리지만 검색, 정렬이 빠르다.
요약
List는 기본적으로 데이터들이 순서대로 저장되며 중복을 허용한다.
Map은 순서가 보장되지 않고 Key값의 중복은 허용하지 않지만 Value값의 중복은 허용된다.
Set은 순서가 보장되지 않고 데이터들의 중복을 허용하지 않는다.
