클러스터링 인덱스에 대해서 알아보자!
Clustering Index
클러스터란 여러 개를 하나로 묶는다는 의미로 주로 사용된다.
MySQL에서 클러스터링 인덱스는 InnoDB와 TokuDB 스토리지 엔진에서만 지원하며, 나머지 스토리지 엔진에서는 지원되지 않는다.
클러스터링 인덱스는 PK(프라이머리 키)에 대해서만 적용되는 내용이다. 즉, 테이블당 1개만 생성 가능하다.
정리하면 테이블 당 1개만 생성 가능하고 프라이머리 키값이 비슷한 레코드끼리 묶어서 저장하는 것을 클러스터링 인덱스라 한다.
그럼 일반적인 인덱스와는 어떤 점이 다를까?
아래의 경우 일반적인 B-Tree 인덱스의 구조이다 .
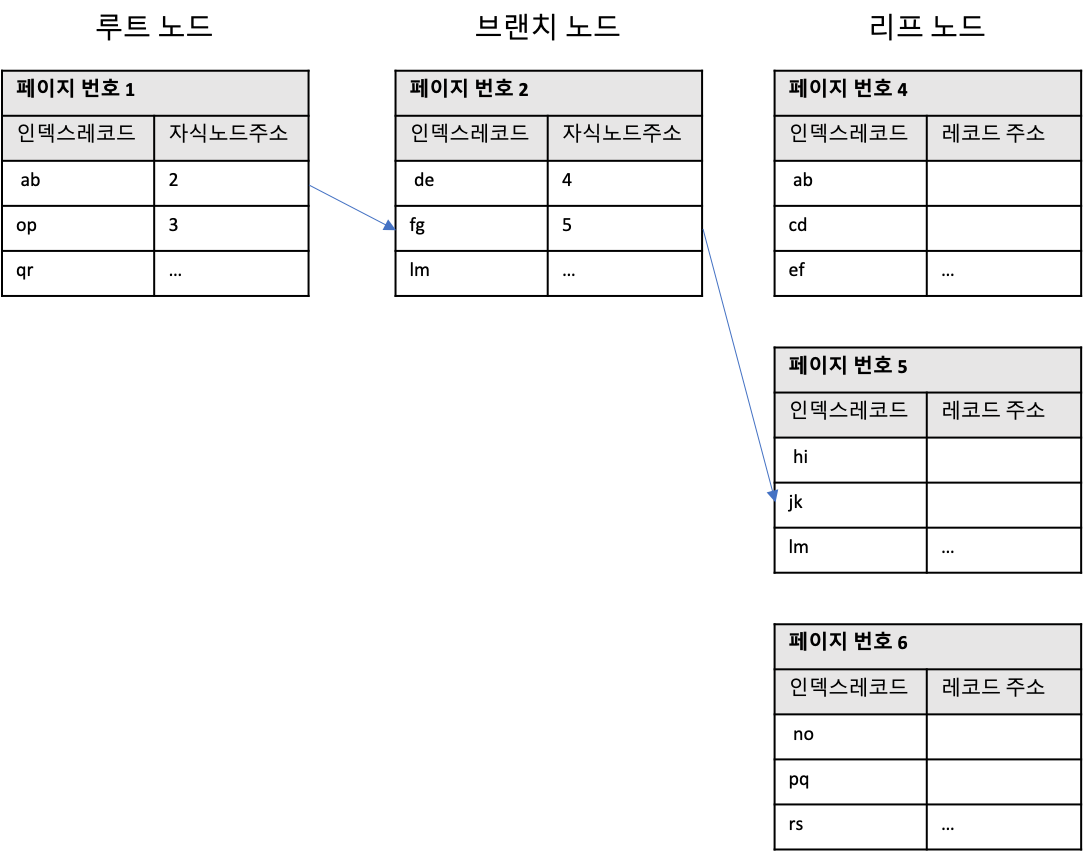
위의 그림처럼 특정 값을 찾기위해 루트노드부터 리프노드까지 찾아 들어가고 리프노드에서 찾은 레코드 주소를 통해 실제 데이터가
존재하는 위치를 찾아 데이터를 가져오는 방식이다.
이 방식의 경우 기본적으로 인덱스는 정렬되어 있을 지라도 데이터는 정렬되어져 있지 않다. 그러나 클러스터링 인덱스의 경우에는
구조가 비슷하면서도 다르다.
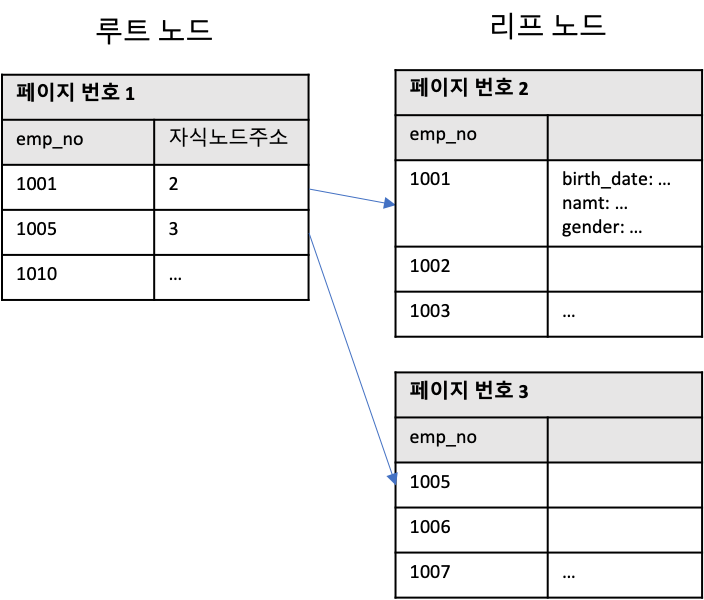
위 이미지와 같이 루트 노드, 리프 노드로만 구성되어 있으며, 리프 노드가 곧 데이터이다. 클러스터링 인덱스라 함은 결국 테이블 자체가 하나의 인덱스 구조로 관리되는 것이다.
이런 점으로 보면 클러스터링 인덱스는 인덱스 알고리즘 보다는 테이블 레코드의 저장 방식이라고 볼 수도 있다.
예를 들자면 일반적인 인덱스는 책의 가장 앞이나 뒤에 있는 찾아보기 정도로 생각할 수 있고, 클러스터링 인덱스는 키워드로 정렬되어 내용까지 같이 볼 수 있는 사전 정도로 생각할 수 있다.
이렇게 클러스터링 인덱스를 적용하기 위한 PK가 없을 시 MySQL의 InnoDB 엔진은 아래와 같은 우선순위로 프라이머리 키를 대체할 컬럼을 선택한다.
- NOT NULL 옵션의 유니크 인덱스 중에서 첫 번째 인덱스를 클러스터 키로 선택
- 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가한 후 클러스터 키로 선택
이런 클러스터링 인덱스에는 어떤 특징이 있을까?
- 프라이머리 키값에 의해 레코드의 저장 위치가 결정됨
- 프라이머리 키 기반의 검색이 매우 빠르며, 대신 레코드의 저장이나 프라이머리 키의 변경이 상대적으로 느릴 수밖에 없음
- 테이블의 모든 보조 인덱스가 클러스터링 키를 갖기 때문에 클러스터 키값의 크기가 클 경우 전체적으로 인덱스의 크기가 커짐
- 보조 인덱스로 검색할 때 프라이머리 키로 다시 한번 검색해야 하므로 처리 성능이 조금 느림
- 프라이머리 키를 변경할 때 레코드를 DELETE하고 INSERT하는 작업이 필요하기 때문에 처리 성능이 느림
이 부분을 조금 더 상세하게 설명하면 PK(클러스터링 키)에 의해 레코드 저장 위치가 결정된다고 위에 설명하였다.
즉 보조인덱스들의 경우 리프노드의 레코드주소로 데이터를 찾는데, 클러스터링 키가 변경될 때마다 모든 인덱스는 변경되어야 한다는 걸 의미한다.
이런 번거로움을 방지하고자 InnoDB 테이블의 모든 보조인덱스는 레코드 주소가 아닌 프라이머리 키를 저장하도록 구현되어 있다.
보조인덱스로 검색 시 보조인덱스를 통해 PK를 찾고 그 PK로 다시 클러스터링 인덱스를 검색하는 방식으로 구현되어 있다.
데이터베이스 성능 핵심과 기초에 대해서 더 알아보자!
데이터베이스 성능 핵심

-
데이터베이스는 디스크에 저장된다.
-
디스크는 메모리에 비해 훨씬 느리다.
-
데이터베이스 성능 핵심은 디스크 접근을 최소화 하는 것이다.
- 어떻게 디스크 접근을 줄일 수 있을까?
-
디스크에서 메모리에 올라온 데이터로 최대한 요청을 처리하는 것 = 메모리 캐시 히트율을 높이는 것
-
데이터베이스에 쓸 때도 곧 바로 디스크에 쓰는게 아니라 메모리에 쓴다. 메모리에 쓴 데이터가 날라가는 것을 대비해 WAL(Write Ahead Log)를 사용한다.
디스크에 접근 하는 방법은 두가지 방법이 있다.
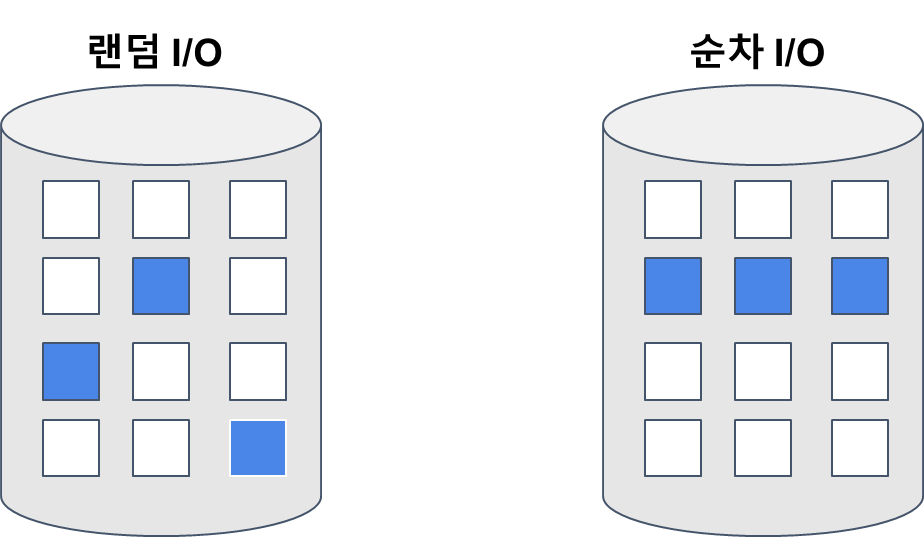
- 랜덤 I/O는 디스크에 랜덤으로 접근해서 데이터를 가져온다.
- 순차 I/O는 디스크에 순차적으로 접근
메모리에 순차적으로 저장시키면, 디스크에 랜덤 I/O로 접근하는 것을 최소화할 수 있다.
데이터베이스 성능의 핵심은 디스크의 랜덤 I/O (접근)을 최소화 하는 것이다.
인덱스를 사용하면, 이런 불필요한 랜덤 I/O 접근을 줄여서 데이터 탐색 성능을 개선할 수 있다.
인덱스만을 메모리에 적재하고, 원하는 데이터의 물리적 주소를 찾아 접근하면 되기 때문이다.
최근 DB 쿼리 최적화에 대해 관심이 많이 생겼는데 도움이 많이 되는 글들이었다.
출처:
Clustering Index란? https://dev-ppyong.tistory.com/11
인덱스와-클러스터링-인덱스 https://velog.io/@kevin_/posts
