들어가며
SafetyFence는 독거노인, 치매 환자 등 취약계층의 위치를 실시간으로 추적하고 보호자에게 알림을 전송하는 복지 서비스입니다.
해당 서비스에 무중단 배포를 도입하면서 공부도 해봅시다.
Rolling, Blue-Green, Canary 세 가지 무중단 배포 전략을 비교하고, SafetyFence에 어떤 전략이 적합한지 판단해봅시다
무중단 배포란
무중단 배포(Zero-downtime Deployment)는 서비스 중단 없이 새 버전을 배포하는 방식
핵심은 트래픽을 받는 인스턴스와 배포 중인 인스턴스를 분리하는 것
세 전략 모두 이 원칙을 따르지만, 방식과 트레이드오프가 다르다. 어떤 전략이 유용한지는 서비스의 특성에 따라 달라진다.
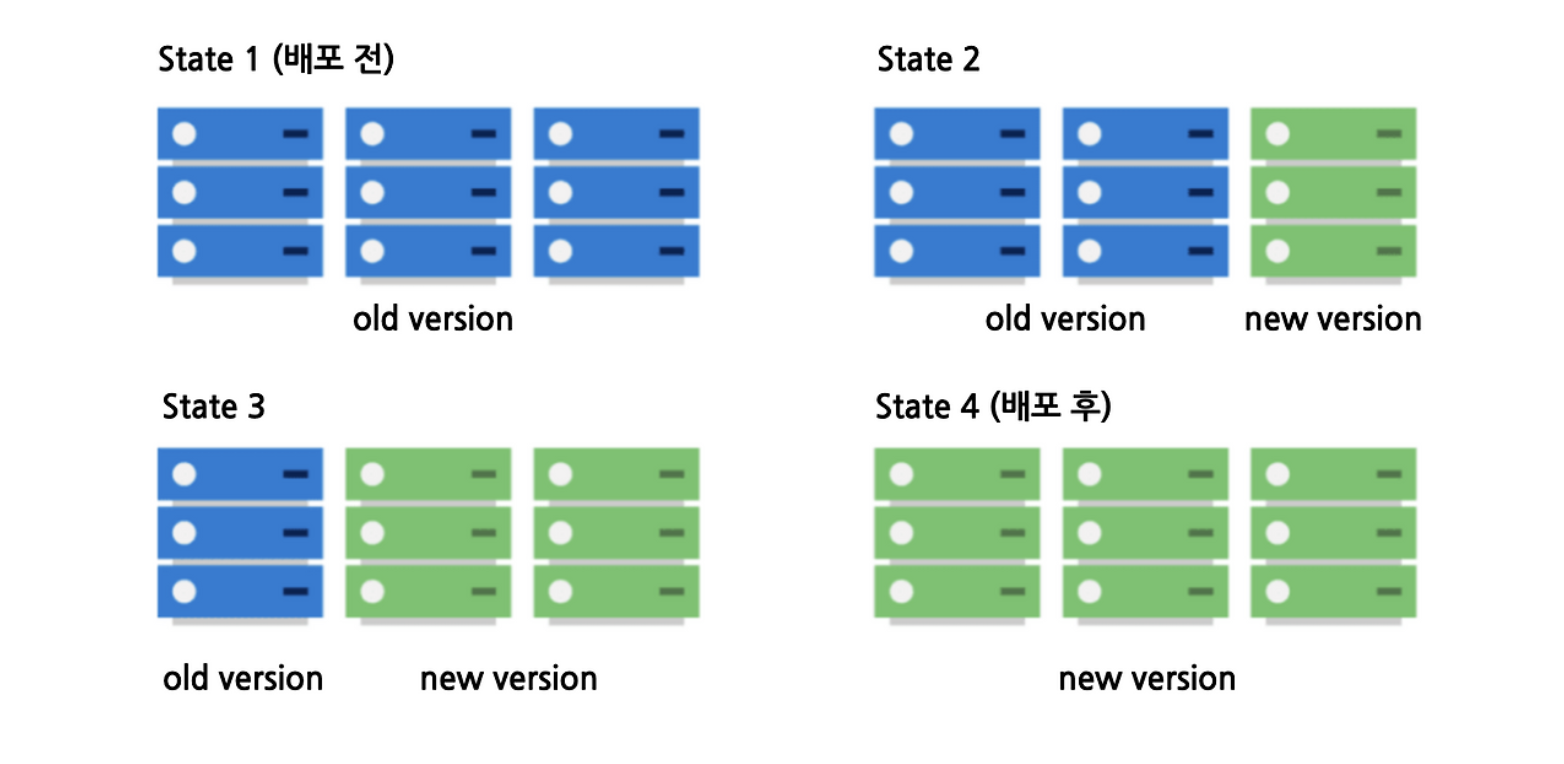
Rolling 배포
개념
기존 인스턴스를 하나씩 순차적으로 새 버전으로 교체한다. 인스턴스가 4개라면 1개씩 내리고 올리는 과정을 반복한다.
[v1][v1][v1][v1] ← 초기 상태
↓
[v2][v1][v1][v1] ← 1번 교체 완료
↓
[v2][v2][v1][v1] ← 2번 교체 완료 (v1/v2 혼재 구간)
↓
[v2][v2][v2][v2] ← 배포 완료장점
추가 인프라 없이 현재 인스턴스 안에서 교체가 이루어지기 때문에 비용이 들지 않는다. 구성도 단순해서 진입 장벽이 낮다.
단점
배포 중에 v1과 v2가 동시에 트래픽을 받는 혼재 구간이 발생한다. API 응답 포맷이나 DB 스키마가 버전 간 다르다면 이 구간에서 오동작이 생길 수 있다. 롤백할 때도 동일한 순차 교체 과정을 다시 거쳐야 해서 시간이 걸린다.
가장 큰 문제는 WebSocket 연결 중단이다. 인스턴스가 교체될 때 해당 인스턴스에 연결된 클라이언트 세션이 강제로 끊긴다.
SafetyFence에 적용하면?
위치 추적 WebSocket 연결은 특정 인스턴스에 고정된다. Rolling 배포로 해당 인스턴스가 내려가는 순간 연결이 강제 종료되고, 재연결 중 이벤트 유실 가능성이 생긴다. 더 큰 문제는 배포 중 v1/v2가 혼재하는 구간에서 지오펜스 판별 로직이나 알림 조건이 버전마다 다르게 동작할 수 있다는 점이다. Redis로 세션을 외부화하더라도 비즈니스 로직 자체가 버전마다 다르게 실행되는 건 막을 수 없다.
→ SafetyFence에는 부적합
Blue-Green 배포
개념
동일한 환경을 두 인스턴스로 유지한다. 현재 운영 중인 환경(Blue)과 새 버전을 올린 환경(Green)을 동시에 띄우고, Green의 준비가 완료되면 로드밸런서에서 트래픽을 한 번에 전환한다.
ALB
│
┌─────┴──────┐
[Blue-v1] [Green-v2]
(트래픽 ON) (Health Check 대기)
│
타겟 그룹 전환
│
[Blue-v1] [Green-v2]
(Drain) (트래픽 ON)트래픽 전환은 ALB의 타겟 그룹을 바꾸는 것으로 이루어진다. 이 전환은 순간적이기 때문에 v1/v2 혼재 구간이 존재하지 않는다.
장점
트래픽이 순간 전환되기 때문에 사용자 입장에서는 배포가 일어난 사실을 알 수 없다. Health Check를 통과한 Green 환경에만 트래픽이 붙기 때문에 안정성도 높다. 롤백도 빠르다. 문제가 생기면 ALB 타겟 그룹을 다시 Blue로 바꾸면 끝이다.
단점
인프라를 유지하는 동안 비용이 일시적으로 2배가 된다. 또한 Blue 환경에 맺어진 WebSocket 연결을 강제로 끊지 않고 자연스럽게 종료시키기 위한 Connection Draining 설정이 필요하다.
SafetyFence에 적용하면?
트래픽 전환 전까지 Blue 환경의 WebSocket 연결은 그대로 유지된다. ALB의 Deregistration Delay(기본 300초) 설정으로 Blue가 타겟 그룹에서 빠진 뒤에도 기존 연결이 안전하게 종료되도록 처리할 수 있다. Redis로 세션을 외부화해 두었기 때문에 Green으로 재연결이 발생하더라도 상태가 유지된다.
비용 2배 구간은 배포 시간(10~15분) 수준이라 운영 비용 관점에서 허용 가능하다.
→ SafetyFence에 가장 적합
Canary 배포
개념
새 버전을 전체가 아닌 일부 트래픽에만 먼저 노출한다. 문제가 없으면 점진적으로 비율을 늘려 전체 전환한다.
ALB 트래픽 분산
90% → [v1 인스턴스 x3]
10% → [v2 인스턴스 (카나리)]
이상 없으면
0% → [v1]
100% → [v2]장점
신규 버전을 실제 프로덕션 트래픽으로 검증할 수 있다. 장애가 발생해도 영향 범위가 카나리 비율(10%)로 제한된다. 대규모 서비스에서 배포 리스크를 낮추는 데 효과적이다.
단점
v1/v2 혼재 구간이 Rolling과 동일하게 존재한다. 트래픽 비율 제어를 위해 ALB Weighted Target Group 또는 서비스 메시 같은 추가 인프라가 필요하다. WebSocket 연결이 어떤 버전의 인스턴스에 붙을지 보장하기도 어렵다.
SafetyFence에 적용하면?
버전 간 데이터 포맷이 달라질 경우 카나리 비율에 해당하는 사용자에게만 문제가 생기는 상황을 통제하기 어렵다. 복지 서비스 특성상 일부 사용자라도 알림 유실이 발생해서는 안 된다. Canary는 트래픽 규모가 크고 피처 플래그 관리가 가능한 환경에서 유효한 전략이다.
→ SafetyFence에는 부적합
최종 판단: Blue-Green
판단 근거는 단순하다. Rolling과 Canary는 모두 배포 중 v1/v2가 혼재하는 구간이 생기고, 이 구간에서 WebSocket 연결이 끊기거나 버전 간 데이터 불일치가 발생할 수 있다.
Blue-Green은 트래픽을 순간 전환하고, Connection Draining으로 기존 연결을 안전하게 처리하며, 문제 발생 시 즉시 롤백할 수 있다. 비용 2배 구간은 배포 시간만큼만 유지되기 때문에 허용 가능한 트레이드오프다.
실제 배포 파이프라인
Blue-Green을 적용한 배포 흐름은 다음과 같다.
GitHub Push
↓
GitHub Actions 트리거
↓
Docker Build → ECR Push (새 이미지 태그)
↓
Green 환경 배포 (ECS Task 교체 or EC2 Auto Scaling Group)
↓
Health Check 통과 확인 (/actuator/health)
↓
ALB 타겟 그룹 전환 (Blue → Green)
↓
Blue 환경 Connection Draining (Deregistration Delay 300초)
↓
Blue 환경 종료Health Check 통과 여부를 확인하고 나서 타겟 그룹을 전환하는 순서가 핵심이다. 이 단계가 없으면 아직 준비되지 않은 Green으로 트래픽이 넘어가 장애가 생긴다.
마치며
무중단 배포 전략은 서비스 특성에 따라 선택이 달라진다. Stateless한 API 서버라면 Rolling으로도 충분하다. 하지만 SafetyFence처럼 무중단 WebSocket 연결이 필수적인 서비스는 Blue-Green이 아니면 배포 시마다 사용자 연결이 끊기는 리스크를 감수해야 한다.
