인덱스란?
인덱스 index : 테이블에 대한 동작의 속도를 높여주는 자료 구조
데이터와 데이터의 주소를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 도와준다.
인덱스의 장점/단점
[장점]
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
[단점]
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
- 인덱스를 관리하기 위해 추가 작업이 필요하다.
- 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
인덱스 관리
인덱스는 항상 최신 상태로 정렬되기 위해 데이터 갱신 작업에 대해 추가적인 연산이 발생한다.
INSERT: 새로운 데이터에 대한 인덱스를 추가DELETE: 삭제하는 데이터의 인덱스를 제거UPDATE: 기존의 인덱스를 제거하고, 갱신된 데이터에 대해 인덱스를 추가
인덱스의 자료구조
Hash Table, B-Tree, B+Tree
Hash Table
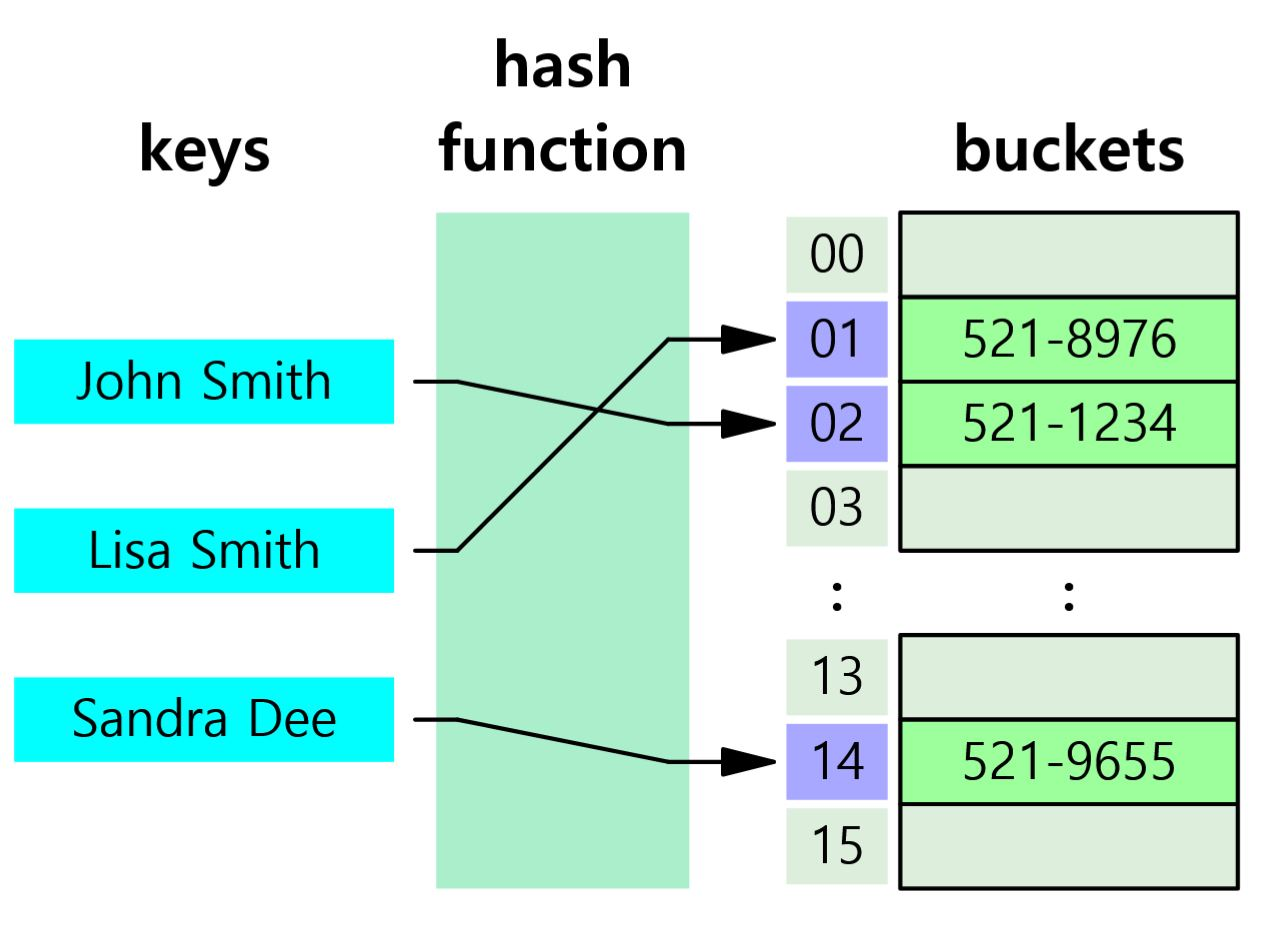
Hash Table : Key-Value로 이루어진 데이터를 저장하는 자료 구조
특정 컬럼의 값과 데이터의 위치를 Key-Value로 사용한다.
*해시 함수는 값이 달라지면 완전히 다른 해시 값을 생성하기 때문에 해시는 등호 연상에 특화되어 있고 부등호 연산에는 적합하지 않다.
B-Tree
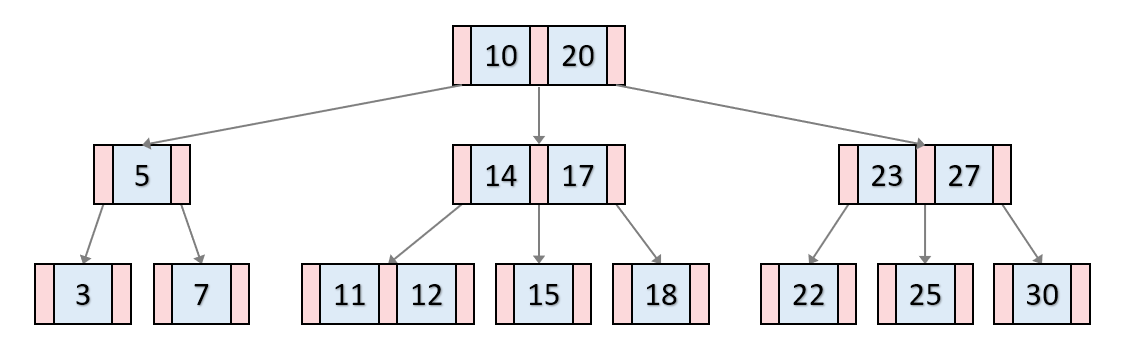
B-Tree : 자식 노드가 2개 이상인 트리
특정 컬럼의 값(Key)에 해당하는 노드에 데이터의 위치(Value)를 저장한다.
*항상 Key를 기준으로 오름차순 정렬되기 때문에 부등호 연산에 대해 효율적이다.
B+Tree
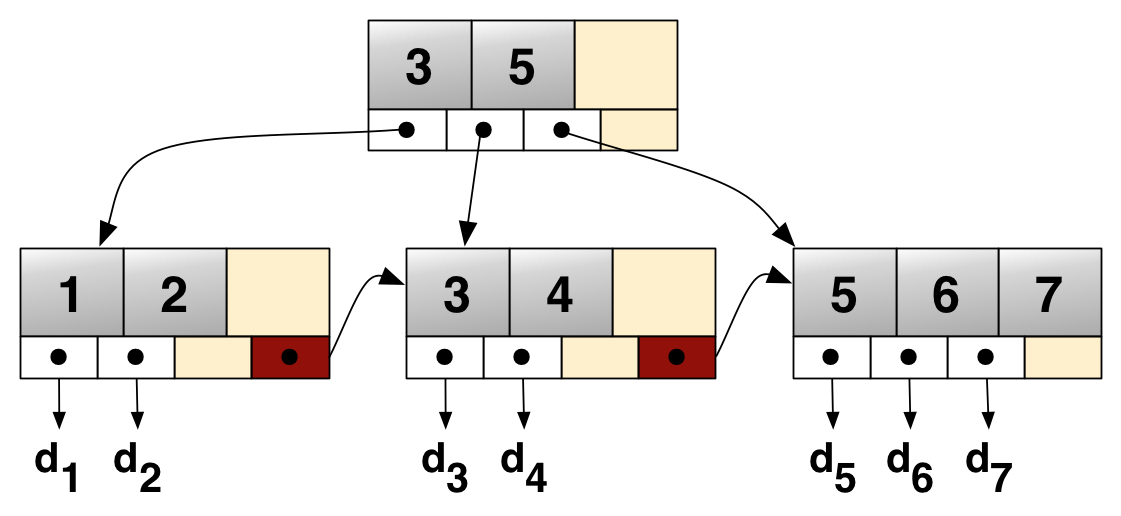
B+Tree : B-Tree를 확장 및 개선한 자료구조로 말단의 리프 노드에만 데이터의 위치(Value)를 관리
B-Tree보다 메모리를 덜 차지하기 때문에 더 많은 Key를 저장할 수 있으며, 따라서 트리의 높이가 더 낮다.
*말단의 리프 노드들끼리 LinkedList 구조로 서로를 참조하고 있기 때문에 부등호를 이용한 순차 검색 연산을 하는 경우 속도 이점이 있다.
참고
https://tecoble.techcourse.co.kr/post/2021-09-18-db-index/
https://mangkyu.tistory.com/96

🙇♀️ Android