Kafka - 수집기술
- 링크드인에서 개발한 분산 메시징 시스템.
- 대용량 실시간 로그 처리에 특화되어 있다.
- Fast: 수 천개의 데이터로부터 초당 수백 MB의 데이터를 입력 받아도 안정적으로 처리가능
- Scalable: 메시지를 파티션으로 분리하여 분산 저장, 처리할 수 있어 클러스터로 구성하여 확장 가능
- Durable: 클러스터에 파티션 복제하여 fault tolerance.
publish - subscribe 모델
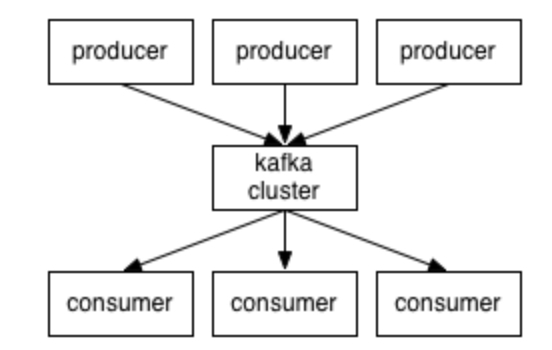
- producer(발행자)가 메세지를 topic에 맞게 브로커에게 전달하면 consumer(구독자)가 브로커에 요청해서 가져가는 방식.
- producer는 message를 topic으로 카테고리화
- consumer는 topic에 맞는 메시지를 broker에 요청
- producer와 consumer는 서로를 알지 못함.
topic - partition
topic
- message는 topic으로 분류
- topic은 producer가 stream을 발행하는 단위
- stream 발행과 subscribe는 topic 단위로 처리
partition
- 1개의 topic은 여러 partition으로 저장되고, 하나의 partition은 여러개의 log로 기록
- 하나의 topic을 여러 partition으로 나누면 메세지 분산 처리로 처리량을 높일 수 있고, 분산 저장을 통해 오류가 발생할 때 데이터를 복구할 수 있다.
- partition의 크기는 운영중에 동적으로 줄일 수 없기 때문에 partition 개수를 설정할 때 주의해야 함.
- partition에서 메세지의 상대적인 위치를 offset이라 하고, consumer는 현재까지 읽은 오프셋을 이용하여 데이터를 요청
- partition은 여러개의 복제본으로 나누어서 저장된다.
- partition replica 설정에 따라 동일한 데이터를 복제하여 저장.
- 데이터에 문제가 발생하면 복제된 데이터로 복구
- 파티션의 데이터 저장은 기본적으로 round-robin 방식으로 동작
- 파티션 분배 알고리즘을 설정하여 키를 기준으로 파티션 분류도 가능
producer - consumer
producer
- message를 만들고 broker에게 topic으로 분류된 message를 전달(배치형태로)
- producer는 consumer의 존재를 알지 못함.
consumer
- message를 소비하는 주체
- producer의 존재를 알지 못함
- 원하는 topic을 구독하여 스스로 조절해가면서 소비할 수 있음.
- 원하는 topic의 각 partition에 존재하는 offset의 위치를 기억하고 관리하여 데이터의 중복을 관리
- offset관리를 통해 publisher, consumer에 장애가 발생해도 마지막으로 읽었던 위치에서 부터 다시 구독 가능
broker(Kafka cluster)
- cluster로 구성된 message queue라고 할 수 있음
- 메세지는 cluster에 partition 단위로 나누어 관리/복제 됨
- file system에 message를 저장하므로 유실이 없고 복구 가능
- 하드디스크의 순차적 읽기 기능을 이용하여 속도를 유지
- 구독자가 메세지를 가져가도 바로 삭제하지 않음(default 7일)

Github - https://github.com/dddwsd