MLOps
MLOps는 ML + Ops의 합성어로 ML model 배포와 운영 및 유지해주는 작업을 의미하며 주된 목표는 다음과 같다고 생각한다.
- ML model들이 빠르고 안정적으로 개발되도록 하는 것
- ML model들이 빠르고 안정적으로 serving되도록 하는 것
MLOps engineer가 되기 위해선?
MLOps engineer가 되기 위해서는 정말 다양한 지식이 있어야 한다.
여러 공고들을 보면서 종합해본결과
- ML pipeline
- data ingestion
- data preprocessing
- model training
- model tuning
- model monitoring
- model release
- model serving
- infra
- CI/CD(auto ml)
에 대한 역량들이 필요할 것으로 생각된다.
보다 디테일한 roadmap은 https://github.com/chris-chris/ml-engineer-roadmap 을 참고하고
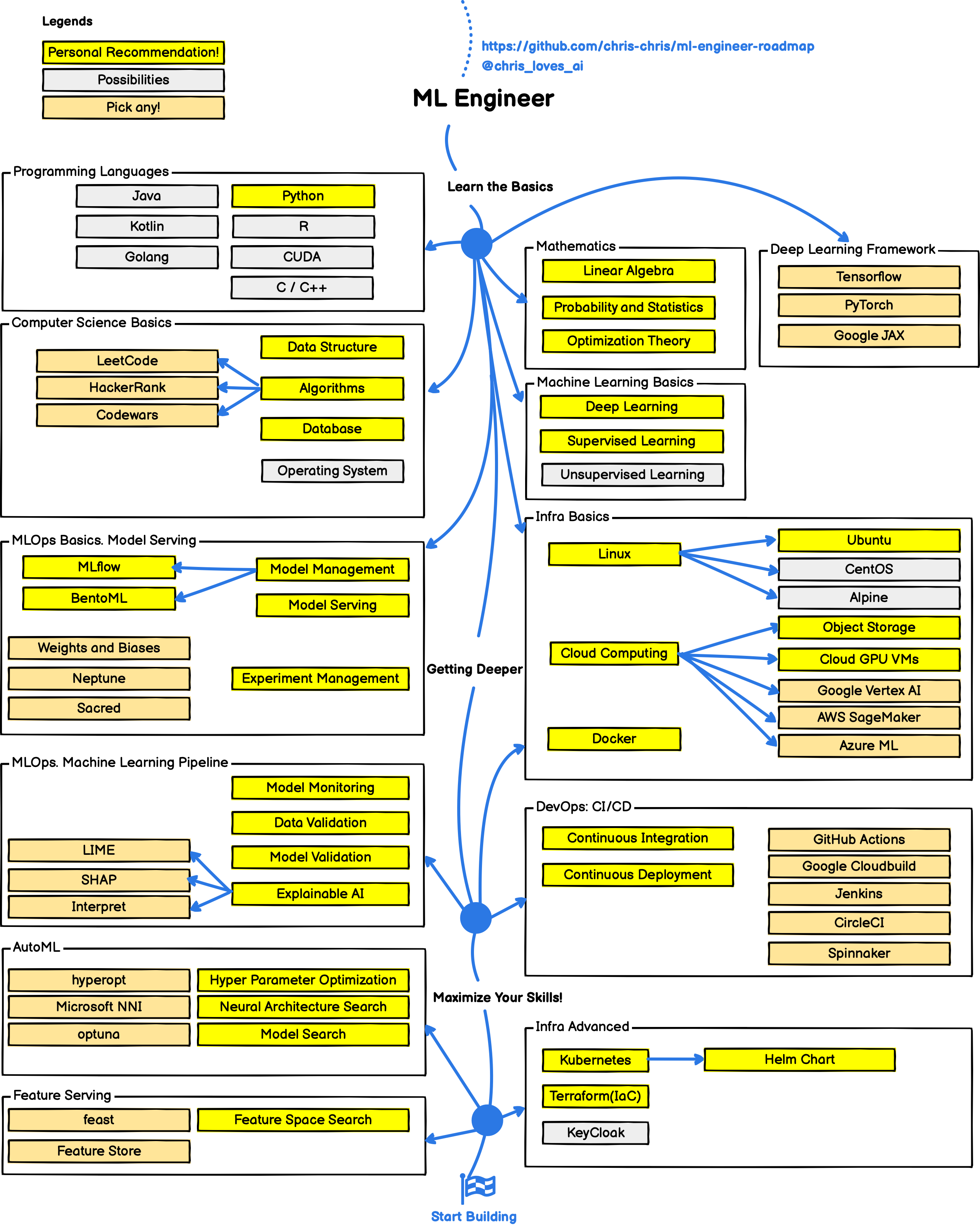
보다 디테일하게 MLOps engineer의 업무를 알고 싶다면
- https://zzsza.github.io/mlops/2018/12/28/mlops/
- https://post.naver.com/viewer/postView.naver?volumeNo=31517937
- https://github.com/visenger/awesome-mlops
- https://github.com/kelvins/awesome-mlops
- https://github.com/MLOpsKR/Awesome-MLOps-Contents
를 참고하는걸 추천한다.
체계적인 강의를 통해 진행하고 싶다면
- 모두의 MLOps - MakinaRocks
https://mlops-for-all.github.io/ - coursear - Andrew Ng - MLOps 특화과정
https://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops - Full Stack Deep Learning
https://fullstackdeeplearning.com/
MLOps engineer가 되기 위한 나만의 커리큘럼
- github repository 구축
- docker 설치
- kubernetes 설치
- mlops를 위한 model 선정 - tensorflow
- offline dataset이 존재하는 model 이면서
- modeling이 이미 되어 있어야 하고
- crawling을 통해 online data ingestion이 가능해야 함.
- ml pipeline 구현
- training data ingestion - kafka
- data preprocessing - spark
- feature store에 저장 - Feast
- model training - tensorflow
- model tuning - GCP ai platform HPO(hyper-parameter optimization
- ml pipeline 자동화 - airflow
- serving API 개발
- tensorflow serving + k8s
- bentoML
- data validation - tensorflow data validation
- infra management
- monitoring - neptune ai

Github - https://github.com/dddwsd