SpanBERT: Improving Pre-training by Representing and Predicting Spans
Abstract
우리는 텍스트의 범위를 더 잘 표현하고 예측하도록 설계된 pre-training 방식인 SpanBERT를 제시한다. 우리의 접근 방식은 (1) random token이 아닌 contiguous random span을 maksing하고 (2) masked span의 전체 내용을 예측하도록 span boundary representation을 학습함으로써 BERT를 확장한다. SpanBERT는 question-answering이나 coreference resolution와 같은 span selection task에서 상당한 이점을 얻으면서 BERT와 더 잘 tuned된 baseline들을 지속적으로 능가한다. 특히 BERT large와 동일한 training data와 model size로 SQuAD 1.1과 2.0에서 각각 94.6%, 88.7%를 얻었다. 우리는 또한 OnNotes coreference resolution task(79.6% F1)와 TACRED relation extraction benchmark에서 강력한 성능을 보였으며, 심지어 GLUE에서도 SOTA를 달성했다.
1. Introduction
BERT와 같은 pre-train 방법은 individual words나 subword units을 mask하는 self-supervised training을 사용하여 강력한 성능향상을 보여줬다. 그러나 많은 NLP Task는 두 개 이상의 텍스트 범위 사이의 관계에 대한 추론을 포함한다. 예를들어 extractive question answering에서 'Denver Broncos'가 'NLF team'의 한 종류라고 판단하는 것은 'Which NFL team won Super Bowl 50'라는 질문에 답하는 것에 매우 중요하다. 이러한 spans은 self supervision tasks에서 더욱 까다로운 target을 제공한다. 예를 들어, 'Denver Broncos'를 예측하는 것은 다음 단어가 'Broncos'라는 것을 알 때 'Denver'만을 예측하는 것보다 훨씬 어렵다. 이 논문에서는 question answering and coreference task에서 가장 큰 이점을 얻으면서 BERT를 지속적으로 능가하는 span-level pre-training approach를 소개한다.
우리의 방법은 masking scheme과 training objectives 모두 BERT와 다르다. 첫째, 우리는 random individual token이 아닌, random contiguous token을 mask한다. 둘째 새로운 span boundary objective(SBO)를 도입하여 모델이 boundary에서 관찰한 token에서 전체 masked span을 예측하는 것을 학습한다. span-based masking은 모델이 나타나는 context만을 사용하여 전체 span을 예측하도록 강제한다. 또한 SBO는 모델이 fine-tuning 단계에서 쉽게 접근할 수 있는 boundary token에 이 span-level 정보를 저장하도록 권장한다. Figure 1은 이 접근방식을 보여준다.
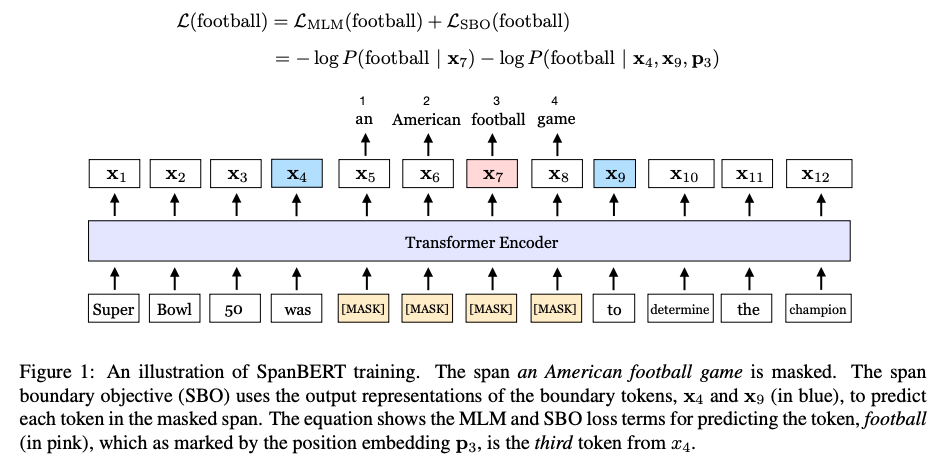
SpanBERT를 구현하기 위해, 우리는 BERT의 well tuned replica를 기반으로 했으며, 이것만으로 BERT를 크게 능가했다. baseline을 구축하는 동안, next sentence prediction(NSP) 목표를 가진 두개의 half-length segments 대신 single segments에 대한 pre-training이 대부분의 downstream task에서 성능을 향상시킨다는 것을 찾았다. 따라서 이것을 tuned single-sequence BERT baseline의 맨위에 추가한다.
우리의 pre-training process는 광범위한 task에서 모든 BERT baseline을 능가하는 모델을 산출하고, 특히 span selection task에서 훨씬 나은 성능에 도달한다. 구체적으로 우리의 방법은 SQuAD 1.1과 2.0에서 각각 94.6%와 88.7% F1에 도달하며 tuned BERT replica 대비 오류를 27%까지 줄였다. 또한 5가지 extractive question answering benchmarks(NewsQA, TriviaQA, SearchQA, HotpotQA, Natural Questions)에서도 유사한 이점이 있다.
SpanBERT는 또한 document-level coreference resolution을 위한 challenge CoNLL-2012(OntoNotes) shared task에서 79.6% F1로 이전 상위 모델을 6.6% 초과하며 SOTA를 달성했따. 마지막으로 SpanBERT가 TACRED와 GLUE에서도 성능향상을 함으로써 span selection을 명시적으로 포함하지 않는 task에도 도움이 된다는 것을 입증한다.
다른 사람들은 더 많은 데이터를 추가하고 모델 크기를 증가시키는 이점을 보여주고 있는 반면, SpanBERT는 좋은 pre-train 및 objective를 설계하는 것의 중요성을 보여주며, 이 또한 주목할만한 영향을 끼칠 수 있다.
2. Background: BERT
BERT는 특정 downstream task에 대해 fine-tuning을 하기 전에 pre-training a deep transformer encoder를 위한 self-supervised approach이다. BERT는 masked language model(MLM)과 next sentence prediction(NSP) 두가지 training objectives를 optimize하고 이것은 unlabeld text의 large collection만 필요로 한다.
Notation
word 또는 sub-word tokens의 sequence 이 주어졌을 때, BERT는 각 token에 대한 contextualized vector representation을 생성하는 encoder를 훈련시킨다.
Masked Language Model(MLM)
cloze test라고도 하는 MLM은 그들의 placeholder로부터 sequence의 missing token을 예측하는 task이다. 특히, token의 subset 은 샘플링되고 다른 token 집합으로 대체된다. BERT 구현에서 는 에 속한 토큰의 15%를 차지하며, 그 중 80%는 [MASK]로 대체되고, 10%는 (unigram distribution에 따라) random token으로 대체되며, 10%는 변경되지 않는다. task는 수정된 입력에서 의 원래 토근을 예측하는 것이다.
BERT는 무작위로 subset을 선택하여 Y의 각 토큰을 독립적으로 선택한다. SpanBERT는 연속된 범위를 무작위로 선택하여 Y를 정의한다.
Next Sentence Prediction(NSP)
NSP 작업은 두개의 sequence 를 입력으로 사용하며, 가 직접 연속인지 여부를 예측한다. 이것은 먼저 corpus에서 를 읽은 다음, (1) 가 끝난 지점에서 를 읽거나 (2) corpus의 다른 지점에서 를 무작위로 샘플링하여 BERT에서 구현된다. 두 sequence는 특수 [SEP] 토큰으로 구분된다. 또한 특수 [CLS] 토큰이 , 에 추가되어 입력을 형성하며, 여기서 [CLS]의 목표는 가 실제로 corpus에서 를 따르는지 여부이다.
요약하자면, BERT는 bi-sequence sampling procedure에 의해 생성된 무작위 데이터에서 word piece를 균일하게 masking하여 MLM및 NSP 목표를 최적화한다. 다음 섹션에서는 데이터 파이프라인, masking 및 pre-train objectives에 대한 수정사항을 설명한다.
3. Model
텍스트의 범위를 더 잘 표현하고 예측하도록 설계된 self-supervised pretraining 방법인 SpanBERT를 제시한다. 접근방식은 BERT에서 영감을 받았지만, 세가지 측면에서 bi-text classification framework에서 벗어난다. 먼저 individual token이 아닌 spans of token을 mask하기 위해 다른 random process를 사용한다. 또한 span boundary에서 toekn의 표현만을 사용하여 전체 masked span을 예측하려는 새로운 보조 목표인 span boundary objective(SPO)를 소개한다. 마지막으로 SpanBERT는 각 훈련 예제에 대해 contiguous segment of text를 샘플링하므로 우리가 생각하는 BERT의 NSP objective를 사용하지 않는다.
3.1. Span Masking
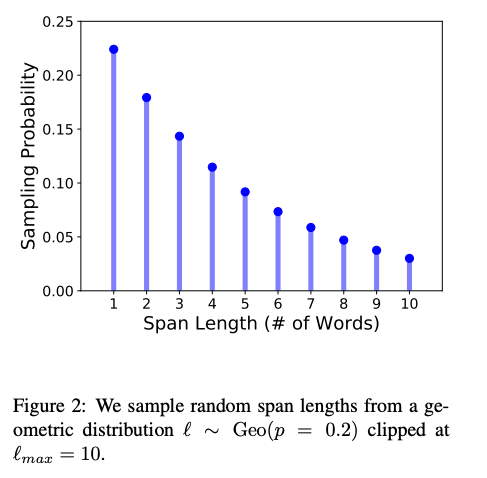
sequence of tokens 이 주어지면, masking budget(의 15%)이 소비될 때까지 반복적으로 샘플링하여 토큰의 하위집합 를 선택한다. 각 반복에서 먼저 더 짧은 간격으로 치우친 기하학적 분포 Geo(p)에서 span length(words의 수)를 샘플링한다. 그 다음 mask할 span의 시작점을 임의로(균일하게) 선택한다. 항상(subword token 대신) complete words sequence를 샘플링하며 시작점은 한 단어의 시작점이어야 한다. preliminary trial에 따라 로 설정하고 clip 은 로 설정한다. 이것은 span 평균 길이 를 산출한다. Figure 2는 span mask length의 분포를 보여준다.
BERT에서와 같이, 우리는 또한 총 15%의 token을 mask한다. mask된 토큰의 80%는 [MASK]로 10%는 random token으로, 10%s느 original token으로 설정한다. 그러나 우리는 각 토큰에 대해 개별적으로가 아니라 span level에서 이 교체를 수행한다. 즉 범위 모든 토큰이 [MASK] 또는 sampling된 token이 된다.
3.2. Span Boundary Objective(SBO)
Span selection model은 일반적으로 boundary token(시작 과 끝)을 사용하여 span의 fixed-length representation을 만든다. 이러한 모델을 지원하기 위해, 우리는 이상적으로 span의 끝에 대한 표현이 가능한 많은 내부 span content를 요약했으면 했다. 따라서 boundary에서 관찰된 토큰의 표현만을 사용하여 masked span의 각 토큰을 예측하는 것을 포함하는 span boundary objectives를 도입함으로써 그렇게 한다.(Figure 1)
형식적으로, 우리는 sequence의 각 token에 대한 transformer encoder의 output을 로 표시한다. masked span of token 가 주어졌을 때, 는 시작과 끝 위치를 의미하며, external boundary token 의 output encodings와 target token 의 position encoding을 사용하여 각 token 를 표현한다. 는 왼쪽 boundary token 에서 부터 masked token의 상대적 위치를 표시하는 position embedding이다.
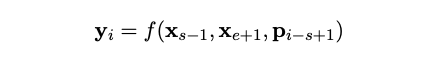
우리는 GeLU와 layer normalization을 가진 2-layer feed-forward network로 represention function 를 구현한다.
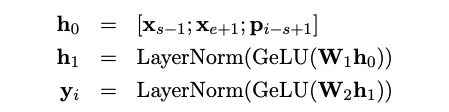
그런 다음 vector representation 를 사용하여 token 를 예측하고 MLM objective와 정확히 같은 cross-entropy loss를 계산한다.
SpanBERT는 MLM과 SBO 모두에서 target token에 대한 input embedding을 재사용하는 동안 masked span 의 각 token 에 대한 span boundary와 일반 MLM의 손실을 모두 합산한다.
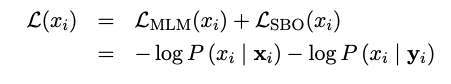
3.3. Single-Sequence Training
section 2에서 설명한 것과 같이, BERT의 example은 두 개의 text sequence 와 그들이 연결되었는지 예측하도록 모델(NSP)을 train하는 objectives가 포함되어 있다. 이 설정이 NSP objective없이 단순히 single sequence를 사용하는 것보다 거의 항상 더 나쁘다는 것을 발견했다(자세한 내용은 section 5참조). 우리는 (a) 모델이 더 긴 전체 길이 context에서 이익을 얻거나, (b) 다른 문서의 종종 관련이 없는 context를 조건화하는 것이 MLM에 noise를 추가하기 때문에 single-sequence training이 NSP를 사용한 bi-sequence training보다 우수하다고 추측한다. 따라서 우리의 접근 방식에서, NSP objective와 two-segment sampling procedure을 제거하고, 최대 n개의 token을 합한 두 개의 half-segment token이 아니라 최대 개의 token의 single contiguous segment를 sampling한다.
요약하면, SpanBERT는
(1) 기하학적 분포 기반 masking scheme(section 3.1)
(2) single-sequence data pipeline을 사용하는 MLM을 추가함으로써(section 3.3) auxilliary span-boundary objective 최적화(section 3.2)
함으로써 span representation을 pre-train한다. 절차 설명은 Appendix A에 있다.
4. Experimental Setup
4.1. Tasks
SpanBERT는
- seven question answering
- coreference resolution
- GLUE benchmark에서 9가지 task
- relation extraction
을 포함한 포괄적인 task suite에서 평가한다. 우리는 span selection task인 question answering과 coreference resolution이 특히 span-base pre-training의 혜택을 받을 것으로 기대한다.
Extractive Question Answering
text의 짧은 구절과 입력으로서의 질문이 주어지면, extractive question answering task는 해당 구절의 text 범위를 답변으로 선택하는 것이다.
[평가 데이터셋 설명 생략]
BERT에 이어 모든 데이터 세트에 동일한 QA model 아키텍쳐를 사용한다. 먼저 passage 과 question 를 single sequence 로 변환하고, pre-trained transformer encoder를 통과한 다음, 그 위에서 answer span boundary를 예측하기 위해 2개의 linear classifier를 독립적으로 학습한다. SQuAD 2.0의 답변 불가능한 질문의 경우 단순히 answer span을 훈련과 테스트 모두 스페셜 토큰 [CLS]로 설정한다.
Coreference Resolution
Coreference resolution은 text에서 동일한 real-world entity를 참조하는 mention들을 clustering하는 task이다. document-level의 coreference resolution을 위해 CoNLL-2012 shared task를 평가한다. 우리는 Joshi가 구현한 higher-oreder coreference model의 independent version을 사용한다. document는 사전 정의된 길이의 겹치지 않는(non-overlapping) segment로 분할한다. 각 세그먼트는 pre-trained transformer encoder를 통해 독립적으로 인코딩되며 이는 원래 LSTM-based encoder를 대체한다. 각 mention span 에 대해 모델은 가능한 antecedent span 의 분포 를 학습한다.
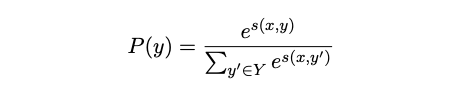
span pair scoring function 는 x와 y에 대한 fixed-length span representation과 수동 엔지니어링 features를 통한 feedforward neural network이다.
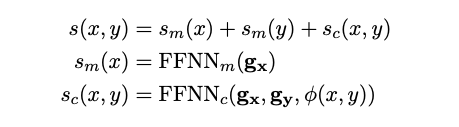
여기서 는 span representation을 나타내고, 이는 두개의 span endpoint의 transformer output states와 span에서 token의 output representation을 통해 계산된 attention vector의 concatenation이다.
과 는 한개의 hidden later를 가진 두개의 feedforward neural network를 의미하고 는 hand-engineered feature(예를 들어 spearker and genre information)를 나타낸다. 모델에 대한 자세한 설명은 joshi et al(2019b) 참조.
Relation Extraction - 생략
4.2 Implementation
의 모델 구성을 사용했으며, 동일한 corpus로 pre-train 시켰다.
원래 BERT구현과 비교하여, 구현의 주요 차이점은 다음과 같다.
(a) BERT가 데이터 처리 중에 각 sequence에 대해 10개의 다른 mask를 샘플링하는 동안 각 epoch에서 서로 다른 mask를 사용한다.
(b)우리는 이전에 사용된 모든 short-sequence 전략을 제거한다(그들은 0.1의 작은 확률로 더 짧은 sequence를 sampling했다. 또한 그들은 먼저 단계의 90$에 대해 128의 더 작은 sequence 길이로 사전 훈련했다)
대신 document boundary에 도달할 때까지 최대 512개의 token sequence를 항상 취한다.
BERT에서와 같이 learnming rate는 의 피크 값으로 처음 10,000단계에 걸쳐 워밍업된 다음 linearly decay된다. 우리는 hyperparameter와 0.1의 decoupled weight decay를 유지한다. 또한 모든 layer와 attention weights에 대해 0.1의 dropout과 GeLU activation function을 유지한다. 2.4M step 실행되고 AdamW에 대해 의 epsilon을 사용하여 더 나은 model parameter 집합으로 수렴함으로써 optimization에서 벗어난다. 우리는 512개의 token을 가진 256개의 sequence의 batch size를 사용한다. SBO의 경우 left boundary token에 상대적인 위치를 표시하기 위해 200 dim positional encoding 를 사용한다. pre-training은 32 Volta V100 GPU에서 수행되었으며 15일이 걸렸다.
Fine-tuning은 Appendix B에 나와있다.
4.3. Baselines - 생략
5. Results - 생략
6. Ablation Studies
우리는 random span masking scheme를 언어적으로 알려진 masking schemes과 비교하고, random span을 masking하는 것이 경쟁력 있고 종종 더 나은 접근 방식이라는 것을 발견했다. 그런 다음 span boundary objectives(SBO)의 영향을 연구하고 BERT의 NSP objective와 대조한다.
6.1. Masking Schemes
이전 작업은 중국어 데이터에 대한 pre-training동안 언어적으로 지식이 풍부한 범위를 masking하여 downstream task 성능이 향상되었음을 보여주었다. random span masking scheme을 언어적으로 알려진 span masking과 비교한다. 구체적으로 우리는 token이 masking되는 방법에서만 다른 다음 5가지 기준선 모델을 훈련시킨다.
Subword Tokens
원본 BERT에서와 같이 random Word-piece token을 샘플링한다.
Whole Words
random words를 샘플링한 다음 해당 단어에 있는 모든 subword tokens을 maskgㅏㄴ다. masked subtoken의 총 수는 15%이다.
Named Entities
50%에서 우리는 text에서 명명된 entity에서 표본을 추출하고 나머지 50%에 대해 무작위 전체 단어를 표본으로 추출한다. masked subtoken의 총수는 15%이다. 특히, 우리는 말뭉치에서 spaCy의 명명된 엔티티 인식기를 실행하고 숫자가 아닌 명명된 엔티티 언급 모두를 후보로 선택한다.
Noun Phrases
named entities와 유사하게, 50%의 시간에 명사구로부터 표본을 추출한다. 명사구는 spaCy의 선거구 parser를 실행함으로써 추출된다.
Geometric Spans
SpanBERT에서와 같이 기하학적 분포에서 random span을 샘플링한다.
