Wide & Deep Learning for Recommender Systems
Abstract
non linear feature 변환이 있는 일반화 linear model은 sparse 입력의 대규모 regression 또는 classification 문제에 널리 사용된다. 다양한 feature들의 cross-product 변환을 통한 feature interaction의 memorication은 효과적이고 해석할 수 있지만 generalization에는 feature engineering 작업이 더 필요하다. feature engineering이 적을수록, dnn은 sparse feature에 대해 학습된 low-dim dense embedding을 통해 보이지 않는 feature combinations으로 더 잘 일반화 시킬 수 있다. 그러나 emb이 포함된 dnn은 user-item interaction이 sparse하고 high-rank일때 관련성이 낮은 항목을 over-generalize하고 추천할 수 있다.
이 논문에서는, wide linear model과 dnn을 jointly train하는 Wide & Deep learning을 소개하며 이는 recommender system에 대한 memorization과 generalization의 이점을 결합하고 있다. 10억명 이상의 active user와 100만개 이상의 앱을 보유한 Google Play에서 시스템을 제작하고 평가했다. online 실험 결과 Wide & Deep은 wide-only, deep-only 모델 대비 app acquisition이 크게 증가했다. 또한 Tensorflow에서의 구현도 오픈 소스화 했다.
Introduction
추천 시스템은 검색 순위 시스템으로 볼 수 있으며, 여기서 입력 쿼리는 사용자 및 컨택스트 정보이며 출력은 항목의 순위 리스트이다. 쿼리를 지정하면 추천 task는 데이터베이스에서 관련 항목을 찾은 다음 클릭이나 구매와 같은 특정 목표에 따라 항목의 순위를 매긴다.
일반적인 검색 순위 문제와 유사한 추천 시스템의 한가지 과제는 memorization과 generalization을 모두 달성하는 것이다. Memorization이란 feature 또는 item의 빈번한 공존을 학습하고 historical data에서 이용가능한 상관관계를 이용하는 것으로 느슨하게 정의할 수 있다. 반면에, Generalization은 correlation의 transitivity에 근거하고 과거에 발생한적이 없는 새로운 feature combination을 탐색하는 것이다. memorization에 기초한 추천은 일반적으로 더 시사적이고 사용자가 이미 조치를 수행한 항복과 직접적으로 연관이 있다. memorization에 비해 generalization은 추천항목의 다양성을 높이는 경향이 있다. 이 논문에서는 Google Play 스토어에 대한 앱 추천 문제에 초점을 맞췄지만 일반 추천 시스템에도 적용될 수 있다.
산업 환경에서 대규모 online 추천 및 ranking 시스템의 경우 단순하고 확장가능하며 해석할 수 있기 때문에 logistic regression과 같은 일반 linear model이 널리 사용된다. 모델에서는 종종 one-hot encoding을 통한 binarized sparse feature에 대해 학습한다. 예를들어 사용자가 Netflix를 설치한 경우 "user_installed_app=netflix"의 binary feature는 1이다. Memorization은 AND(user_installed_app=netflix, impression_app=pandora)(사용자가 neflix를 설치한 후 나중에 Pandora를 볼경우 value가 1)와 같은 sparse feature에 대한 cross product transformation을 통해 효과적으로 암기할 수 있다. 이것은 feature pair의 공존이 어떻게 target label과 연관되어 있는지를 설명한다. 일반화는 AND(user_installed_category=video, impression_category=music)과 같은 세밀도가 낮은 feature를 사용하여 추가할 수 있지만 수동 feature engineering이 필요한 경우가 많다. cross-product transformation의 한가지 제한사항은 학습 데이터에 나타나지 않은 query-item feature pair로 일반화되지 않는다는 것이다.
factorization machine 또는 dnn과 같은 embedding-based model은 각 query와 item feature에 대한 low-dim dense embedding vector를 학습함으로써 이전에 볼 수 없었던 query-item feature pair로 일반화할 수 있으며 feature engineering의 부하를 줄일 수 있다. 그러나 특정 선호도를 가진 사용자나 좁은 매력을 가진 틈새 항목과 같이 query-item matrix가 sparse하고 high-rank를 가진 경우 query와 item에 대한 효과적인 low-dim representation을 학습하는 것은 어렵다. 이러한 경우 대부분 query-item pair 사이에 상호작용이 없어야 하지만, dense embedding은 모든 query-item pair에 대해 0이 아닌 prediction을 초래할 것이며, 따라서 지나치게 일반화되어 관련성이 낮은 권고사항을 만들 수 있다. 한편 cross-product feature transformation이 있는 linear model에서는 훨씬 적은 parameter로 예외 규칙을 memorize할 수 있다.
이 논문에서는 Figure 1과 같이 linear model component와 neural network component를 jointly training 함으로써 하나의 모델에서 암기와 일반화를 실현하기 위한 wide & deep learning framework를 제시한다.
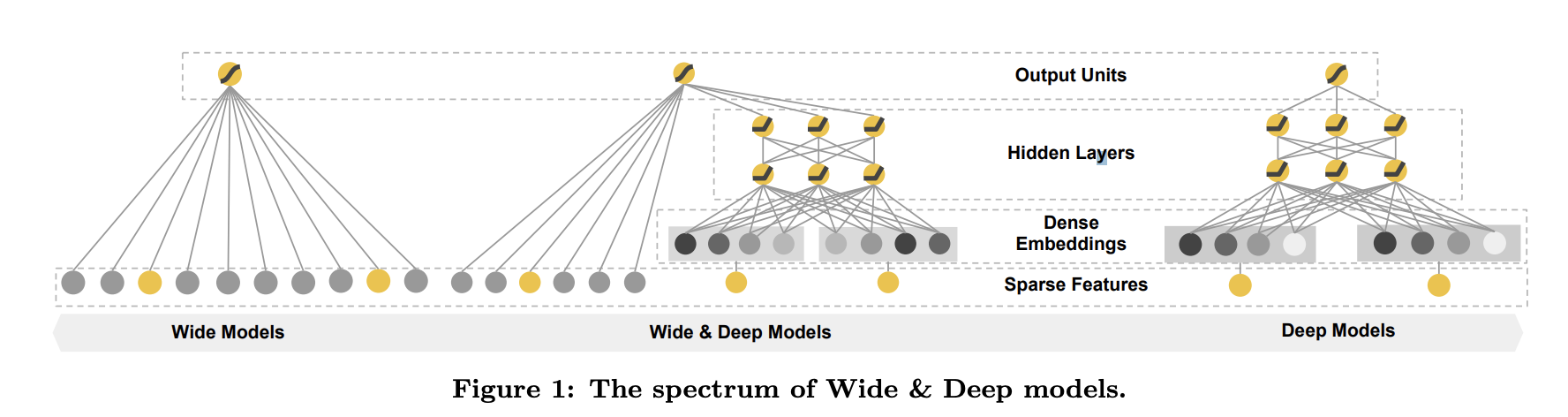
이 논문의 main contributions
- embedding을 통한 feed-forward neural network와 sparse input을 갖고 있는 generic recommender system을 위한 feature transformation을 가진 linear model을 joint training하기 위한 Wide & Deep learning framework.
- 10억명 이상의 active user와 100만개 이상의 앱을 보유한 모바일 앱스토어 Google Play에서 상품화되는 Wide & Deep 추천시스템의 구현 및 평가.
- Tensorflow에 high-level API를 통해 구현을 open-source화 했음.
아이디어는 단순하지만, Wide & Deep framework는 모바일 앱스토어의 app acquisition rate를 대폭 향상시키면서 training과 serving speed 요건을 충족한다는 것을 보여준다.
Recommender System Overview
Figure 2에 app recommender system의 overview가 있다. 사용자가 앱스토어를 방문하면 다양한 사용자 및 컨택스트 기능을 포함할 수 있는 쿼리가 생성된다. 추천 시스템은 사용자가 클릭 또는 구매와 같은 특정 작업을 수행할 수 있는 앱 목록(impression)을 반환한다. 이러한 사용자 행동은 query 및 impression과 함께 learner를 위한 training data로 log에 기록된다.
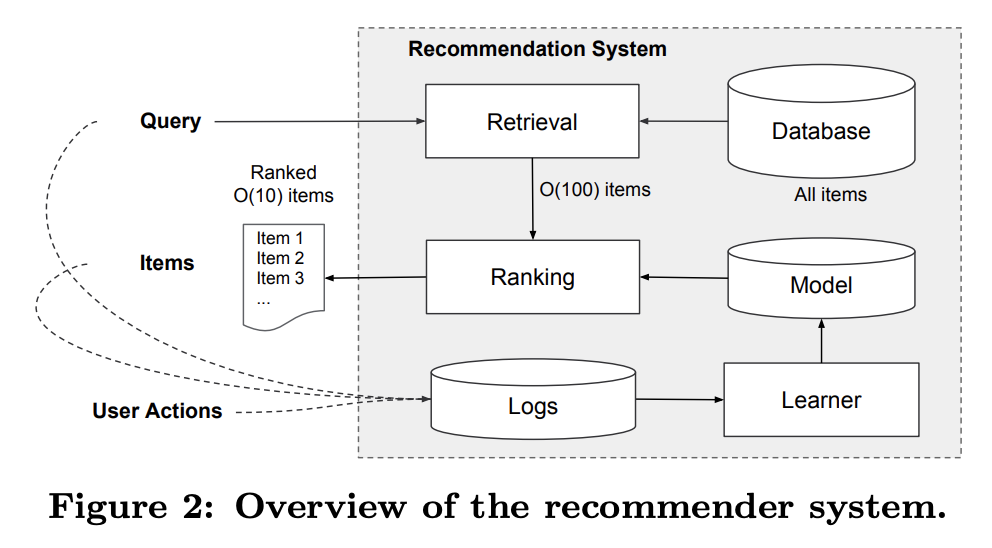
데이터베이스에는 100만개 이상의 앱이 있기 때문에 serving latency requirements(often O(10)밀리 세컨) 내에모든 query에 대해 모든 앱에 점수를 매기는 것은 어렵다. 따라서 query를 수신하는 첫번째 단계는 검색이다. 검색 시스템은 다양한 신호를 사용하여 query에 적합한 항목의 짧은 목록을 반환한다. 일반적으로 machine-learned model과 human-defined rules의 조합이다. 후보 풀을 줄인 후, 랭킹 시스템은 모든 항목을 점수로 순위를 매긴다. 점수는 보통 P(x|y)로 표시하고 이건 user feature(ex 국가, 언어, 인구통계), contextual feature(ex 장치, 시간, 요일) 및 impression feature(ex 앱 나이, 앱의 이력통계)를 포함한 feature x에 대한 사용자 action label y의 확률이다. 이 논문에서는 Wide & Deep learning framework를 사용한 ranking model에 초점을 맞춘다.
Wide & Deep learning
Wide component
wide component는 Figure 1의 왼쪽과 같이 y = +b 형태의 일반화된 linear model이다. y는 prediction이며 x=[, ..., ]는 d feature의 벡터이며, w=[, ..., ]는 model parameter 그리고 b는 bias이다. feature set에는 raw input feature와 transformed feature가 포함된다. 가장 중요한 transformation중 하나는 cross-product transformation으로 다음과 같이 정의된다.

- 는 boolean variable로 i번째 feature가 k번째 transformation 에 포함될 경우 1 아닐경우 0을 나타낸다. binary feature에 대해, cross-product transformation (ex "AND(gender=female, language=en)")은 gender=female이고 language=en인 경우에만 1이고 아닌경우는 0이다. 이것은 binary feature간의 상호작용이 캡쳐되고 일반화된 linear model에 nonlinearity를 추가한다.
Deep component
deep component는 Figure 1의 오른쪽과 같은 feed-forward neural network이다. categorical feature의 경우 original input은 feature string(ex language=en)이다. 이러한 sparse하고 고차원적인 categorical feature는 먼저 종종 embedding vector라고 불리는 저차원적이고 dense real-valued 벡터로 변환된다. 임베딩의 dimensionality는 보통 O(10)에서 O(100)의 순서로 되어 있다. embedding vector는 무작위로 초기화된 다음 모델 훈련중에 최종 loss function을 최소화하기 위해 훈련된다. 이러한 저차원 dense embedding vector는 forward pass를 통해 neural network의 hidden layer에 공급된다. 구체적으로는 각 hidden layer는 다음과 같은 연산을 수행한다.
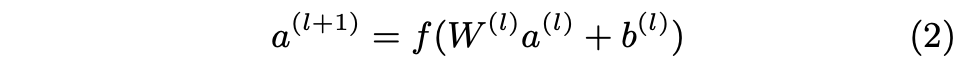
- 은 layer number
- 는 activation function이며 이는 종종 linear unit의 잘못된 것을 바로잡는다(ReLUs).
- 은 activations, bias, 번째 layer의 model weights.
Joint training of wide & deep model
wide component와 deep component는 그들의 output log odds의 weighted sum을 prediction으로 사용하여 결합되며, 그 다음 joint training을 위해 하나의 공동 logistic loss function에 공급된다.
Joint training과 ensemble 사이에는 차이가 있다. ensemble에서 개별 모델은 서로 알지 못한 채 개별적으로 훈련되며, 이들의 예측은 추론 시간에만 결합되고 훈련시간에는 결합되지 않는다. 반대로, joint training은 wide와 deep 부분 뿐만 아니라 훈련 시간에 합계의 가중치를 고려함으로써 모든 parameter를 최적화한다. 모델 사이즈에도 영향이 있다. ensemble의 경우 훈련이 분리되기 때문에 각각의 개별 모델 크기는 ensemble이 작동할 수 있는 합리적인 정확도를 달성하기 위해 일반적으로 더 커야 한다.(ex 더 많은 feature와 transformation이 있음) 이에 비해 joint training의 경우, wide 부분은 full-size wide model이 아니라 소수의 cross-product feature transformation으로 deep part의 약점을 보완하기만 하면 된다.
wide & deep model의 joint training은 mini-batch stochastic optimization을 사용하여 출력에서 모델의 wide와 deep 부분에 gradient를 동시에 backpropagating함으로써 이루어진다. 실험에서 모델의 wide 부분에 대한 optimizer로 FTRL 알고리즘을 deep 부분에 대한 optimizer로 AdaGrad를 사용했다.
결합된 모델은 Figure 1의 가운데에 나와있다.
logistic regression problem의 경우 model's prediction은 다음과 같다.
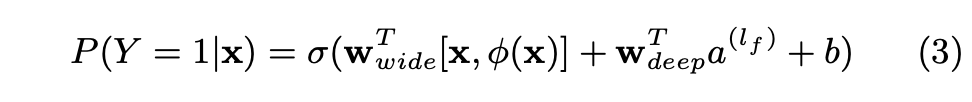
- - binary class label
- - sigmoid function
- - original feature x의 cross product transformations
- - bias
- ( = wide) - wide model weights 벡터
- ( = deep) - final activation 에 적용되는 weights
System Implementation
apps recommendation pipeline의 구현은 3개를 포함한다 - data generation, model training, model serving - Figure 3

Data generation
이 단계에서는 일정 기간내의 유저와 앱 impression data를 사용하여 training data를 생성한다. 각 example은 한개의 impression에 해당한다. label은 app aquisition이다. impressed app이 설치된 경우 1, 아닌 경우 0.
categorical feature를 string to integer ID에 맵핑하는 테이블인 Vocabularies도 이 단계에서 생성된다. 최소 회수 이상 발생한 모든 string feature의 ID space를 계산한다. Continuous한 real-valued feature는 feature value 를 의 분위수로 분할된 누적 분포 함수 로 맵핑함으로써 [0, 1]로 normalize된다. 번째 분위수에서 정규화된 값은 이다. 분위수 경계는 데이터 생성 중에 계산된다.
Model training
실험에서 사용된 모델 구조는 Figure 4와 같다.
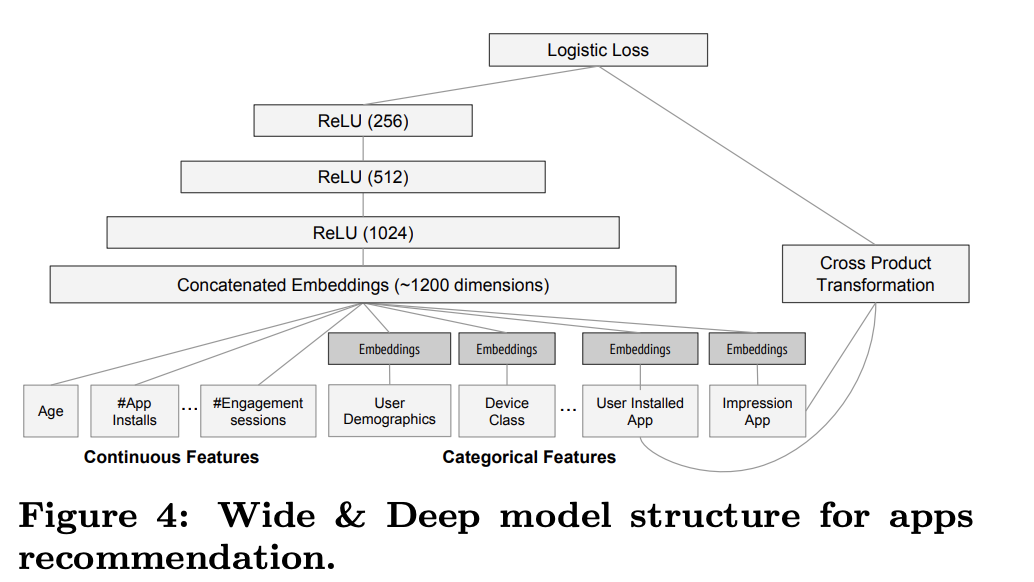
training 중에 입력 계층은 training data와 vocabularies를 사용하고 label과 함께 sparse 와 dense feature를 함께 생성한다. wide component는 사용자가 설치한 앱과 impression 앱의 cross-product transformation으로 구성된다. deep component는 32-dim embedding vector가 각 categorical feature를 학습한다. 모든 embedding을 dense feature와 함께 concat하여 약 1200 dim의 dense vector를 생성한다. concat된 vector는 3개의 ReLU 레이어에 공급되고 마지막으로 logistic output unit에 공급된다.
wide & deep model은 5,000억개 이상의 예에 대해 train하고 있다. 새로운 training data가 도착할때마다 모델을 re-train해야 한다. 그러나 매번 처음부터 다시 교육하는 것은 계산 비용이 많이 들고 데이터 도착에서 업데이트된 모델 제공까지 시간이 지연된다. 이 과제를 해결하기 위해 이전 모델의 embedding과 linear model weights로 새로운 모델을 초기화하는 warm-starting system을 구현했다.
모델을 모델 서버에 로드하기 전에 라이브트래픽 처리시 문제가 발생하지 않도록 모델을 dry run 한다. empirically validate(건전성 검사)로서 이전 모델에 대비 모델 품질을 실증적으로 검증한다.
Model serving
모델이 훈련되고 검증되면 모델 서버에 로드된다. 각 request에 대해 서버는 앱 검색 시스템으로 부터 앱후보를 받고 user feature를 통해 각 app에 점수를 매긴다. 그리고 app의 순위를 가장 높은 점수부터 가장 낮은 점수순으로 사용자에게 보여준다. 점수는 wide & deep model을 통한 foward inference pass를 실행함으로써 계산된다.
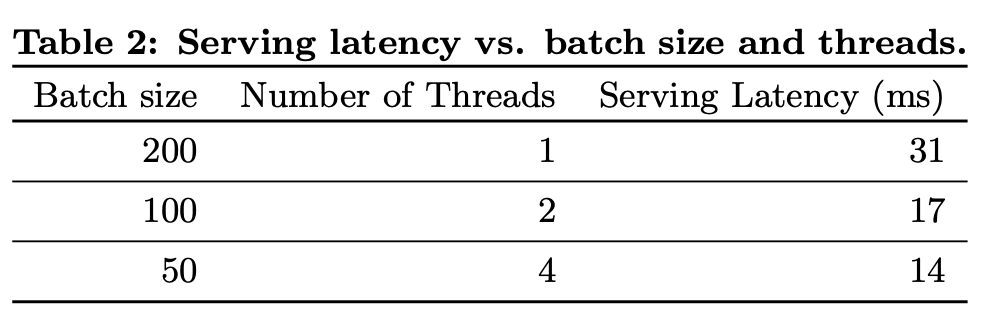
각 request를 10ms 단위로 처리하기 위해 single batch inference step에서 모든 후보앱을 채점하는 대신 소규모 batch를 parallel하게 실행하여 multithreading parallelism으로 성능을 최적화했다.
Experiments Results
App acquisitions
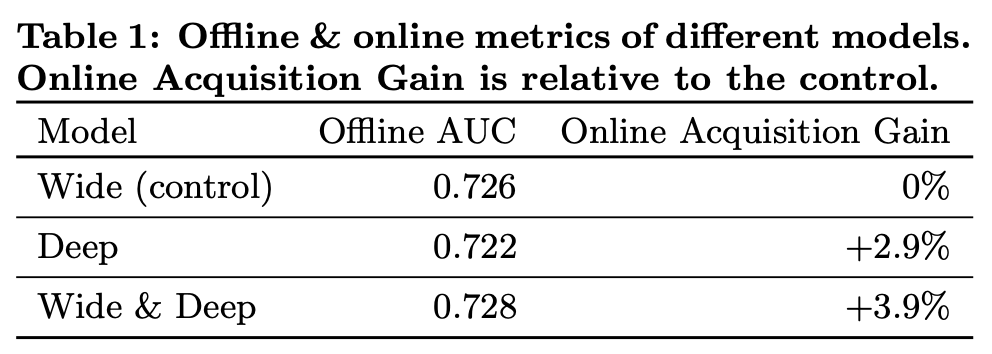
Serving performance
Related Work
cross product feature transformation의 wide linear model과 dense mebedding의 dnn을 결합한 아이디어는 두 변수간의 상호작용을 두 low-dim embedding vector 사이의 dot product로 인수분해하여 선형모델에 일반화를 추가하는 factorization machine와 같은 이전 작업에서 영감을 받았다. 이 논문에서는 dot product 대신 neural network를 통해 embedding간의 매우 비선형적인 상호작용을 학습하여 모델 용량을 확장하였다.
언어모델에서 입력과 출력 사이의 직접 가중치를 학습하여 RNN 복잡성(ex hidden layer sizes)를 줄이기 위해 n-gram feature를 가진 maximum entropy model과 RNN의 joint training이 제안되었다. computer vision에서는 deep residual learning이 하나 이상의 레이어를 건너뛰는 바로가기 연결을 통해 심층 모델 훈련의 어려움을 줄이고 정확도를 향상시키기 위해 사용되어 왔다. 그래픽 모델과의 neural network 공동 훈련은 영상의 인간 자세 추정에도 적용되었다. 이 연구에서 우리는 sparse input data의 일반적인 권장과 순위 부여 문제를 위해 sparse feature와 output unit 사이의 직접적인 연결을 통해 feed-forward neural network와 linear model의 joint training을 탐색했다.
recommender system 문헌에서는 콘텐츠 정보에 대한 딥러닝과 rating matrix에 대한 CF(collaborative filtering)을 결합하여 협업 딥러닝을 탐구했다. 사용자의 앱 사용 기록에 CF를 사용한 AppJoy와 같은 모바일 앱 추천 시스템에 대한 이전 작업도 있었다. 과거의 CF 기반 또는 컨텐츠 기반 접근방식과 달리, 앱 추천 시스템의 사용자 및 impression data에 대한 wide & deep model을 jointly train 하고 있다.
Conclusion
Memorization과 generallization은 recommender system에서 둘다 중요하다. Wide linear model은 cross-product feature transformations을 사용하여 sparse feature interaction을 효과적으로 memorize할 수 있고, dnn은 low-dim embedding을 통해 이전에 본적없는 feature interactions으로 일반화할 수 있다. 두 모델의 장점을 결합한 wide & deep learning framework를 제안했다. 대규모 상용 앱스토어인 Goggle Play의 recommender system에서 프레임워크를 제작하고 평가했다. 온라인 실험 결과에 따르면 wide & deep model은 wide-only and deep-only model에 비해 app acquisition이 크게 개선되었다.
