생활코딩 linux
디렉토리와 파일
ls
현재 디렉토리의 파일 목록을 출력하는 명령어. 'ls -l'은 자세히 보기, 'ls -a'은 모든 파일 보기. 'ls -al'은 모든 파일 자세히 보기.
숨김 파일은 파일 이름 앞에 '.'이 붙는다. -l 했을 때 제일 앞에 d가 있으면 directory라는 뜻.
pwd
현재 위치하고 있는 디렉토리를 알려주는 명령어
명령을 내릴 때에는 내가 어디에 있는지 확인을 한 후 명령을 내려야한다
mkdir
mkdir 새로 생성할 디렉토리명
-p 를 하면 디렉토리 안의 디렉토리를 만들 수 있음. 예) mkdir -p dir1/dir2/dir3/dir4
cd
cd 이동할 디렉토리의 경로명
상대경로와 절대경로
상대경로는 현재 디렉토리의 위치를 기준으로 다른 디렉토리의 위치를 표현하는 것으로 ..은 부모 디렉토리를 의미한다.
cd ..은 현재 디렉토리의 부모 디렉토리로 이동하는 명령이다. 현재 디렉토리는 . 이다.
절대경로는 최상위 디렉토리를 기준으로 경로를 표현하는 것을 의미합니다. 최상위 디렉토리는 루트(root) 디렉토리라고 하고 / 이다. cd /는 최상위 디렉토리로 이동한다는 뜻이다. cd /home/유저이름은 현재 디렉토리가 무엇이건 언제나 /home/유저이름을 의미하는데 이런 식의 경로 표현을 절대경로라고 합니다.
rm
rm 파일명
rm -r 디렉토리명
-r은 recursive로 디렉토리 안의 contents까지 다 지우는 것이다.
cp
copy이다. 파일을 복사할 수 있다.
mv
파일 이동이다. move이다. 파일 이름을 바꿀 때에도 쓴다.
--help
명령어 뒤에 --help를 붙이면 명령의 사용설명서가 출력된다.
ls --help
rm --help
mkdir --help
pwd --help--help와 man
명령어를 쓰고
--help를 쓰면 간단한 설명이 나온다.
Usage 는 사용법을 나타낸다.
rm --help
ls --help
man을 쓰고 명령어를 쓰면 명령어에 대한 상세한 사용 설명서가 나타난다.
help와 man의 차이는 help는 보는 화면을 빠져나가지 않고 간단한 매뉴얼 출력
man의 경우 전용 페이지에서 상세한 매뉴얼을 보여준다.
help나 man이 동작 하는 것과 안 하는 것이 있다.
내용이 같을 수도 있고 man이 더 상세할 수도 있다.
man 내부에서
/단어
입력하면 단어가 포함된 내용이 나타난다.
단어 기준 스크롤을 건너뛰고 싶으면 m키를 누르면 된다.
그럼 m 키를 누를 때 마다 단어를 찾아준다.
매뉴얼을 빠져나갈 때는 q를 누르면 빠져나가진다.
sudo
sudo : super user do. 슈퍼 유저가 하는 일
unix 계열의 특징은 다중 사용자 시스템이다. 하나의 운영체제를 여러 사람이 사용하다보니 권한(permission)을 고안해 사람마다 할 수 있는 일, 없는 일을 나눌 수 있게 하였다.
super user, root user라는 다 관리할 수 있는 존재가 있다.
rm -rf / 하면 루트 디렉토리의 모든 파일을 삭제하게 된다. root 계정은 이렇게 위험하기 때문에 보통 일반 사용자로 사용을 하다 필요한 경우에 sudo를 써서 권한을 받아 사용한다.
임시로 슈퍼 유저의 권한으로 그 명령어만 실행하도록 하는 것이 sudo라는 명령어이다.
파일 편집 (nano)
파일에 정보를 저장하는 방법이다. nano, vi 등은 memo와 같은 편집기이다.
nano와 vi는 유닉스 계열에 들어가 있기 때문에 사용법을 안다면 어디서든 사용 가능.
nano 입력 후 enter
텍스트 파일을 편집 할 수 있는 편집기 화면이다.
원하는 텍스트 입력 후 밑의 명령어들 중 선택
^는 ctrl 키를 의미
^O를 입력하면 write out, 쓰기가 된다.
File name to wrie: 에 파일 이름을 작성하면 된다.
그럼 아래의 명령어들이 현재 사용할 수 있는 명령으로 바뀐다.
^X를 통해 빠져나간다.
그럼 새로운 파일이 생긴 것을 확인할 수 있다.
파일을 다시 편집하기 위해선
nano 파일이름.확장자
하면 다시 편집할 수 있다.
명령어 자체는 밑에 나와있는 대로 하면 된다. (Cut Text 등)
글자 단위로 cut 하고 싶다면 ctrl + 6 후 블록 설정을 하고 ctrl + K를 하면 cut 된다.
vi 사용을 추천한다.
패키지 매니저
ls, mkdir과 같이 유닉스 기본 내장 프로세스도 패키지다.
오늘날의 유닉스들은 package manager를 기본으로 제공한다. 앱스토어와 같은 역할이다. 필요한 프로그램을 찾을 수 있고, 다운받고 설치, 삭제를 해 준다. command line에서의 app store이다.
리눅스 대표는 apt와 yum이 있다.
패키지 매니저로 설치할 수 있는 목록을 최신 상태로 갱신할 필요가 있다.
sudo apt-get update
인터넷을 통해 apt 서버에 접속해 최신 업데이트 목록을 다운 받는다.
그리고나면 검색한다.
sudo apt-cache search 프로그램
그럼 프로그램과 관련된 목록을 보여준다.
sudo apt-get install 프로그램
프로그램을 설치한다.
설치된 프로그램에 대해서 업데이트를 하고 싶다면
sudo apt-get upgrade 프로그램
하면 프로그램에 대한 업그레이드를 진행하게 된다.
sudo apt-get upgrade
하면 모든 프로그램이 업그레이드 된다.
설치된 프로그램을 삭제하는 명령
sudo apt-get remove 프로그램
하면 삭제할 것인지 물어보고 y를 입력하면 삭제된다.
다운로드 방법 (wget, git)
wget을 이용한 다운로드
wget을 이용해 url로 다운로드 받을 수 있다.
wget 링크주소
하면 다운로드가 된다.
wget -O를 사용하면 output 파일의 이름을 바꿀 수 있다,
wget -O 저장하고싶은파일이름.jpeg http://~~~~.com
하면 파일 이름을 다르게 저장할 수 있다.
git을 이용한 다운로드
github의 clone or download를 누르면 opensource의 소스코드 URL이 나온다.
해당 URL을 복사한 후 설치를 진행해보아야 한다.
git 설치가 필요하다.
sudo apt-get install git
git clone 아까복사한URL
이렇게 하면 해당 주소의 오픈소스 프로젝트를 복제한다.
git clone 복사한URL 디렉토리명
하면 디렉토리에 이 주소가 가리키는 오픈소스 프로젝트가 다운로드 된다.
거기 안에 모든 소스코드가 다운로드 된 상태이다.
왜 CLI인가?
GUI vs CLI
컴퓨터의 에너지를 많이 쓰는 방식은 GUI이다. CLI는 훨씬 절약하게 된다.
일반인이 사용하는 컴퓨터 시스템은 그래피컬한 컴퓨터 제어를 하기 떄문에 많은 에너지가 사용성을 높이는 데 사용된다.
서버 컴퓨터나 데이터 분석 시스템은 일반인이 사용하는 컴퓨터가 아니므로 그래피컬하지 않은 명령어로 컴퓨터를 제어하는 기능만 갖고 있으면 용량도 덜 차지하고 메모리도 사용하는 효과가 있다.
GUI 쉽지만 많은 노동이 필요하다. 어떤 일을 한 후 일이 끝날 떄 까지 기다려야한다. 배우기는 쉽지만 그걸 이용해 순차적으로 진행되는 일을 자동화 하기는 힘들다. 반면 CLI는 여러 일의 자동화 하기 편하다.
순차적으로 실행
쉘, 쉘 스크립팅과 관련이 있다.
예시로 진행
1. 디렉토리 생성
2. 디렉토리로 들어간다
두 개의 명령을 한 번에 실행하고자 한다면?
mkdir why; cd why
이러면 why라는 디렉토리 생성 후 why로 들어가진다.
한 번에 두 개, 세 개, 네 개 ... 실행 가능.
명령(프로그램)을 실행했을 때 끝나는 걸 확인하고 실행하는 게 아니라 쭉 적어 놓으면 컴퓨터가 순서대로 명령을 실행하고 최종 결과를 알려준다. 우리는 중간 과정에서 컴퓨터를 지켜 볼 필요가 없다.
하나의 명령이 오랜 기간 실행되어서 언제 끝날 지 모르는 명령들이 100개, 1000개 실행 할 때 하나 하나 실행하지 않고 순차적인 실행을 통해 끝난 결과만 볼 수 있다는 것의 차이가 엄청나다.
파이프라인
하나의 명령의 실행 결과를 다른 명령의 입력으로 준다.
하나의 프로그램의 결과를 다른 프로그램의 입력으로 준다.
하나의 프로세스의 출력을 다른 프로세스의 입력으로 준다.
grep
한 정보에서 포함되어있는 행을 찾는 기능
cat 파일이름.확장자
파일의 내용을 cat이 화면에 출력해준다.
grep linux linux.txt
하면 linux가 포함되어있는 행 만 화면에 표시해 준다.
예를 들면
ls --help | grep sort
이러면 help 안에서 grep하게 된다.
이게 파이프라인. ls의 출력을 입력으로 받아 grep하게 된다
결과에서 file을 또 grep하고 싶다면
ls --help | grep sort | grep file
하면 sort와 file이 들어간 내용만 출력된다.
현재 실행되고 있는 걸 확인하기 위해선
ps aux
하면 된다. 프로세스를 의미.
ps aux | grep apache 하면 apache라는 텍스트가 포함되어 있는 것만 화면에 가져온다.
IO Redirection
Input / Output (입출력) Redirection (방향을 바꾼다)
모니터로 출력하는 것이 아닌 파일에 저장하는 법
ls -l > result.txt
하면 아무런 결과도 출력되지 않고 출력될 결과가 result.txt 파일에 저장된다.
cat result.txt 하면 내용을 볼 수 있다.
이것이 Output을 화면으로 출력되는 것이 기본이지만 그 방향을 다른 곳으로 돌려서 파일에 저장을 시킨 것이다.
이런걸 redirection이라고 한다.
ls가 가운데 동그라미라고 생각하면 된다. Unix Process
apt-get, ps, mkdir 역시 가운데의 프로세스에 해당된다.
프로세스는 크게 입력과 출력을 갖고 있는데 가장 기본적인 입력은 command-line arguments이다.
-a, -l, -F 등이 command-line arguments이다.
이걸 입력하면 나오는 것 --> Standard Output --> 실행 된 결과가 모니터에 나타난다.
이걸 redirection 시켜서 다른 곳으로 출력되게 할 수 있다. 대표적인 것이 파일.
ls -l > result.txt
> 가 redirection을 의미한다.
화면에 출력되는 대신 txt 파일로 출력이 된다.
프로세스가 실행된 후에 Standard Error가 나올 수도 있다.
프로세스 실행 후 나오는 것 두개. Standard Output, Standard Error
없는 파일을 다시 없애는 등의 행동을 하면 에러가 나타난다
그럼 에러가 출력된다
rm rename.txt > result.txt
하면 명령을 실행한 결과인 에러가 파일로 저장되는 것이 아닌 모니터에 출력이 된다.
Output이 redirection 되지 않는다.
그 이유는 Standard Output을 리다이렉션하는 게 >이다. Standard Error를 리다이렉션 하는게 아니기 때문이다.
> 앞에는 사실 1이 생략되어 있다. 1>는 스탠다드 아웃풋 표준 출력을 말하는 것
rm rename.txt 2> error.log하게 되면 2라는 숫자가 스탠다드 아웃풋이 아닌 스탠다드 에러에 대한 출력의 리다이렉션이란 뜻이다.
그래서 error.log라는 파일로 redirection 된다.
cat error.log하면 나타난다.
이 결과를 하이브리드 시켜 rm rename2.txt 1> result.txt 2> error.log
하게 되면 첫 번쨰 것에 에러가 포함되어 있다면 error.log 파일에 저장, 그리고 잘 된다면 standard output을 result.txt에 redirection 가능하다.
input
process는 standard output과 standard error라고 하는 두 가지 출력 형태를 가지고 있음. 하나의 input과 두 개의 아웃풋이었다.
cat 하면 사용자가 입력하는 정보를 standard input으로 받는다. ctrl + d로 빠져나옴
standard input의 방향을 redirection해서 파일에 있는 값을 cat의 입력 값으로 줄 수 있다.
cat < hello.txt
이렇게 되면 cat은 hello.txt의 내용을 입력으로 받는다.
cat hello.txt는 인자로 전달 한 것. 즉, command-line argument로 전달한 것.
cat < hello.txt 는 standard input으로 입력한 값이 되는 것. 표준 입력, standard input으로 cat에 입력 한 것이다.
앞 쪽의 일부만 출력하는 기능 head
head -n1 linux.txt
하면 한 줄만 출력 된다.
-n1은 command-line argument 를 준 것이다.
standard input을 주고싶다면
head -n1 < linux.txt
하면 -n1은 standard input을 준 것이다.
출력된 표준 출력을 one.txt에 저장하고 싶다면
head -n1 < linux.txt > one.txt
하면 one.txt에 한 줄만 들어가게 된다.
이건 표준 입력에 대한 redirection과 표준 출력에 대한 redirectiond이 다 된다
linux.txt가 리다이렉션 돼서 head의 입력이 되고 그 결과를 리다이렉션 돼서 one.txt로 나온 것이다.
Unix 계열의 프로세스는 standard input이 있고 standard output 이 있다. 화면에 output이 출력되는 것, error가 출력 되는 것
IO 스트림이라고도 한다.
stream은 개울, 시내, 흘러나오다 이런 뜻이다.
데이터가 흘러들어가서 흘러나온다.
출력의 결과를 추가하고 싶다면? append하고 싶다면?
ls -al >> result.txt
와 같이 >>를 사용하면 된다.
꺽새가 두 개이면 redirection 한 결과를 덧댄다. 추가한다.
>> 더한다.
방향이 바뀐다면?
<< 이면 여러 개의 입력을 하나로 합친다.
<<문자
다음에 이 문자가 등장하면 입력이 끝나는 것이다.
실행한 결과를 출력하지 않고 날리고 싶다면?
ls -al > /dev/null
/dev/null은 휴지통과 같은 것
그럼 화면, 파일에도 출력되지 않는다.
쉘과 커널
SHELL VS KERNEL
하드웨어 - 커널 - 쉘 - 애플리케이션
우리가 입력한 명령이 쉘에 명령을 입력하는 것이다.
명령을 해석해서 커널이 이해할 수 있는 방식으로 커널로 전달
커널은 하드웨어로 처리할 수 있도록 한다
하드웨어는 처리 결과를 커널로, 커널은 쉘로 보내서 우리가 확인할 수 있는 것이다.
쉘이라는 것은 커널을 직접 제어하는 것은 어려운 일이고 제어할 수 없기 때문에 이해하기 쉬운 형태의 명령어를 입력하면 명령어를 쉘이 해석해서 커널에게 전달
유닉스 계열의 시스템을 만든 사람은 왜 커널과 쉘을 이렇게 분리한 것일까?
쉘이라는 것은 사용자가 입력한 명령을 해석하는 프로그램. 분리하면 여러가지의 쉘이 생길 수 있다.
사용자인 우리는 우리가 편하게 느껴지는 쉘 프로그램을 선택해 사용하면 편리하고 취향에 맞게 커널을 제어할 수 있기 때문에 구분한 것일 것이다.
echo "hello"
echo는 뒤의 문자를 화면에 출력하는 것이다.
echo $0
~bash쉘 중에서 구체적인 제품중의 하나인 bash를 쓰고 있는 것이다
zsh
~bash: no such file or directory --> 설치가 안 되어 있는 것이다.
sudo apt-get install zsh
zsh 를 입력한다
그 후
echo $0
하면 zsh로 나온다
zsh을 쓰고 있는 것.
bash vs zsh
bash의 경우 cd 후 tab을 두 번 누르면 숨김 디렉토리까지 나온다
zsh의 경우 cd 후 tab을 한 번 누르면 디렉토리가 나오는데 숨김 디렉토리까지는 나오지 않는다.
bash의 경우 pwd를 누르면 현재 디렉토리를 알 수 있다.
zsh 역시 마찬가지.
bash의 경우 cd /home/ubuntu 해야한다
zsh의 경우 cd /h/u 입력 후 tab을 누르면 자동으로 완성해준다
zsh가 편의성이 더 높다
디렉토리로 들어갈 때
bash는 cd /home/ubuntu/why
zsh은 cd /h/u/w 후 탭키로도 됨
이 상태에서 dir1으로 디렉토리를 바꾸고 싶다면?
zsh의 경우 cd why dir1
하면 dir1으로 간다
bash는 이런 기능이 없다.
명령어들의 편의성이 쉘마다 다르다.
커널과 쉘이 분리되어있기 때문에 선호하는 shell을 깔아서 사용하면 맞는 환경을 구성할 수 있다,
하나의 컴퓨터에 여러 사용자가 각자 다른 SHELL을 통해 접근 가능
쉘에 standard input을 넣고 standard ouput을 받는 상호작용을 하게 된다.
쉘 스크립트
Shell Script
순차대로 실행되어야 하는 명령의 순서를 저장해 놓고 재사용하자는 의미에서 사용.
확장자가 log로 끝나는 파일을 정기적으로 백업하고 싶을 경우
touch a.log b.log c.log 를 통해 로그 파일 생성
mkdir bak 을 통해 저장할 디렉토리 생성
cp *.log bak 를 통해 확장자가 log인 모든 파일 copy해서 bak에 넣는다
mkdir bak 하면 에러가 난다. bak 디렉토리가 이미 존재하기 때문.
cp *.log bak을 통해 확장자 log 파일을 다시 붙여넣기
bash는
ls /bin 안에 있다. 유닉스 계열에 탑재되어있는 기본적인 프로세스들이 들어있다.
nano backup을 통해 스크립트를 만들어보자.
#!/bin/bash
이 프로그램을 실행시켰을 때 운영체제는 #! 이 기호를 보게 된다. 그리고 그 뒤의 directory를 보고 어디에 있는 프로그램을 통해 실행되는지를 나타낸다.
현재 디렉토리에 bak 디렉토리가 없다면 만들고, 있다면 만들지 않는다. 그리고 현재 디렉토리에 있는 모든 파일 중 .log로 끝나는 파일을 bak로 복사한다는 코드를 작성한다.
#!/bin/bash
if ! [ -d bak ]; then - 현재 디렉토리에 bak라는 디렉토리가 존재하지 않는다면
mkdir bak - 디렉토리가 없다면 만든다
fi - 조건문의 종료
cp \*.log bak - log로 끝나는 모든 파일을 bak로 복사한다.이것이 backup이라는 파일이다. 이 파일을 실행시키기 위해선
./backup
을 실행한다. 하지만 permission denied가 나타난다. 누군가 저 프로그램을 실행할 권한이 없기 때문이다.
실행할 수 있는 파일임을 알려주어야 한다.
chmod +x backup
ls -l을 통해 본다면 -rwxrwxr-x로 바뀌어있다.
x가 포함되어있다. executable로 바뀌었다는 뜻. 실행 가능한 파일로 바뀐 것이다.
chmod +x backup은 backup에 x를 추가해 준 것이다. 실행 가능한 모드를 추가한 것이다.
./backup
실행하면 bak라는 디렉토리가 생성되고 세 개의 log가 저장된 것을 확인할 수 있다.
쉘 스크립트라는 것은 쉘이 실행되어야 할 명령어를 작성해 놓는 것이다.
디렉토리의 구조
운영체제의 디렉토리 구조
명령어 시스템에서 디렉토리는 시스템의 프로그램의 정리정돈 수단.
특히 유닉스 계열에서는 데이터와 실행 프로그램의 성격에 따라 정해진 이름에 위치한는 규칙을 가지고 있다.
유닉스 계열의 디렉토리 구조

/: 최상위 디렉토리. 데이터 저장장치의 최상위 디렉토리. root./bin- User Binariesbash, nano, pwd, ps, rm, ls등 여러 프로세스가/bin디렉토리에 있다.- 실행 가능한 프로그램을 binary라고도 부른다, 그 bin이다.
/sbin- System Binaries- binary. 즉, 실행 프로그램인데 시스템 실행 프로그램이다.
reboot, shutdown, halt등의 프로그램이 있다. - 즉, 일반 사용자가 쓸 일은 많이 없고 관리자, 루트 사용자가 사용할 프로그램들이 있는 곳이
sbin
- binary. 즉, 실행 프로그램인데 시스템 실행 프로그램이다.
/etc- Configuration Files- 설정 파일들. 설정을 바꿀 때 파일을 바꿔서 사용한다.
wgetrc등의 파일이 있다.
/dev- Device Files/proc- Process Information/var- Variable Files- 바뀔 수 있는 파일들. 내용, 용량이 바뀔 수 있다.
- 내용이 바뀔 수 있는 특성을 가지는 파일들. 프로그램은 바뀌지 않고 etc 역시 설정을 바꾸기 전까지는 바뀌지 않는다.
- var 안의 log 등의 파일들은 프로그램의 동작 과정에서 특정 파일에 적힌다. 고정된 것이 아니라 바뀌고 증가되며 어떻게 바뀔지 모른다
/tmp- Temporary Files- 임시 파일들이 저장된다. 컴퓨터를 껐다가 키면 자동으로 파일들이 삭제된다.
/home- Home Directory- 사용자들의 디렉토리. 사용자의 파일들이 저장되는 디렉토리.
- 어디에 있건 홈 디렉토리로 빨리 가야할 경우
cd /home/사용자이름도 가능하지만 cd ~- 사용시 사용자의 홈 디렉토리로 바로 이동한다.
/boot- Boot Loader Files/lib- System Libraries/bin과/sbin이 사용하는 libraries의 저장
/opt- Optional add-on Applications- 프로그램을 install 하면 자동으로 적당한 디렉토리에 저장하게 된다.
- 특정 디렉토리를 특정해서 설치해야 할 경우 이 디렉토리를 사용하는 것이 좋다.
/mnt- Mount Directory/media- removable Media Devices/srv- Service Data/usr- User Programs/usr안에는bin, sbin, lib, local이라는 디렉토리가 들어있다.root의bin, sbin, lib, local과 다른 디렉토리임을 알아야 한다.- 우리가 설치하는 프로그램은
/usr밑에 적당히 설치된다. - 유닉스에 설치되어서 번들 형태로 제공되는 것은
root밑의bin, sbin, lib, local에 설치된다.
프로세스
컴퓨터의 구조
Storage (SSD, HDD 등), Memory (RAM 등), Processor (CPU 등)
Storage - 가격이 저렴하다 : 용량이 크다, 속도가 느리다
Memory - 가격이 비싸다 : 용량이 작다, 속도가 빠르다
Processor가 동작 할 때 빠르게 동작한다. Storage의 속도로 CPU의 처리 속도를 따라올 수 없다.
Storage에 깔려 있는 프로그램을 읽어서 Memory에 적재한다. 실행되지 않는 프로그램을 메모리에 올라오지 않는다.
Memory에 올라온 프로그램을 CPU가 읽어서 처리한다.
Process - command : mkdir, top, rm 등
명령어는 /bin, /sbin 디렉토리 안에 파일의 형태로 저장되어 있다.
파일은 스토리지에 파일이 저장되어있다.
그것을 program이라고 한다. 프로그램을 실행하면 메모리에 적재된다. 메모리에 적재되어 Processor에 의해 실행되는 상태에 있는 프로그램들을 Process라고 하는 것이다. 그걸 처리하는 것이 Processor이다. 명령어가 존재하는 방식은 프로그램이고 스토리지에 저장되어 있다.
즉, Process란 Processor 위에 올라와 실행되고있는 program을 말한다.
프로세스 모니터링 (ps, top, htop)
ps : 프로세스 리스트를 보여주는 명령이다.
ps aux : 백그라운드의 모든 프로그램을 다 보고싶다면 사용하는 명령이다.
ps aux \| grep 원하는단어 : ps aux 가 출력한 결과를 grep이 받아 단어를 찾아준다. 해당 text를 포함하는 process만을 출력해 준다.
PID : Process ID 식별자이다.
sudo kill PID값 : 해당 프로세스를 강제로 정지하는 명령이다.
top : 프로세스의 리스트가 나타난다.
htop : 시각적으로 보기 좋은 top이다.
위의 column을 클릭 시 해당 column기준 정렬
MEM% : 메모리 퍼센트 사용량
CPU% : CPU 퍼센트 사용량
TIME : 프로그램이 실행된 시간
Command : 어떤 명령으로 실행되었는가
RSS : 물리적인 메모리의 크기. 물리적으로 얼마나 메모리를 쓰고 있는가
위의 숫자 1, 2, 3, 4는 CPU의 코어 수이다.
Load average : Load는 부하를 뜻한다. average는 CPU의 점유율과 관련된 평균이다. 첫번째 자리는 1분간의 CPU 점유율, 두번째 자리는 5분, 세번째 자리는 15분간의 얼마나 바쁜지 평균을 낸 것이다.
core가 하나라고 치고 숫자가 8이라면 하나의 process를 처리할 수 있는데 7개의 프로세스가 대기를 하고 있다는 뜻이다.
앞의 프로세스가 처리될 때 까지 7개의 프로세스가 기다리고 있다는 뜻이다. 즉, 700%의 부하가 걸린다 라는 것이다.
앞은 현재 상태, 뒤의 두 개는 긴 시간의 컴퓨터의 부하를 측정하는 수치이다.
코어가 4개인 경우 첫 번째 자리가 4일 경우 자원을 잘 쓰는 상태이다.
코어가 4개인데 숫자가 1이라면 코어 4개 중에서 하나만 일을 하고 있다는 뜻이다.
파일을 찾는 법
locate와 find
파일을 간편하게 찾을 수 있는 방법
locate 파일이름
locate \*.log
확장자가 log인 파일을 다 찾아준다.
locate의 특징은 검색 작업을 수행할 때 디렉토리를 찾는 것이 아니라 데이터베이스를 찾는다. 컴퓨터 안에 저장되어있는 파일들에 대한 데이터베이스가 있다. 이를 통해 훨씬 더 빨리 파일을 찾을 수 있다.
locate가 사용하는 데이터베이스를 mlocate라고 부른다.
sudo updatedb를 통해 mlocate에 파일의 여러 정보를 update한다. 하루에 한 번씩 리눅스 시스템이 알아서 한다.
locate를 통해 파일을 검색하면 정돈된 곳에서 파일을 찾기 때문에 더 빨리 파일을 찾을 수 있다.
find는 디렉토리를 직접 찾는다.
성능은 떨어지지만 현재 상태를 가져올 수 있고 굉장히 다양한 사용법이 있다.
Find Files Using Name in Current Directory
현재 디렉토리 아래의 모든 디렉토리에 대해 찾는 명령
find [Path] 로 사용
find / : 루트디렉토리부터 찾겠다
find . : 현재 디렉토리부터 하위 디렉토리를 찾겠다
find /usr : usr 아래 디렉토리를 찾겠다.
find / -name : 이름으로 찾겠다
find / -name \*.log : log라는 이름이 있는 파일을 찾겠다.
find . -type f -name 파일이름 : 파일 형식만 찾겠다
find . -type f -name "tecmint.txt" -exec rm -f {} \;
-exec 실행한다 rm 삭제한다 -f 강제로 {} 명령으로 검색된 파일이 위치하게 된다. : 검색한 파일을 삭제하는 명령
whereis : 원하는 실행 파일을 찾아주는 명령
whereis 는 the binary, source and manual file를 명령어 이름을 통해 이름에 해당되는 실행파일, 소스 매뉴얼을 찾아준다.
$PATH, $MANPATH에서 찾는다.
어디서든 명령어를 사용할 수 있는 이유는 $PATH라는 변수 덕분이다.
echo $PATH
$PATH 에 담긴 정보를 확인할 수 있다. :을 통해 정보가 구분되어 있고 각각의 :을 기준으로 나와있는 정보는 경로이다.
$PATH라는 변수는 기본적으로 가지고 있다. $PATH에 담긴 값들은 $PATH라는 변수에 담긴 디렉토리를 검색해 실행 파일이 존재하는지 차례대로 찾아 명령어가 발견되면 그 명령어를 실행한다. 즉, ls를 실행하면 컴퓨터가 검색을 하다가 /bin 밑에 ls가 있는 걸 확인하고 실행한다.
$PATH 밑에 디렉토리 값이 있으면 해당하는 디렉토리 밑의 파일을 사용할 수 있다는 장점이 있다.
이런 변수를 환경변수라고 한다.
백그라운드 실행
멀티 태스킹. 여러 개의 작업을 하나의 화면에서 할 수 있다.
뒤의 프로그램이 앞으로 오면 포그라운드가 되어 내가 작업, 프로그램이 뒤에 있으면 백그라운드.
이런 작업을 유닉스에서도 할 수 있다.
이 프로그램을 종료하지 않고 다른 작업을 하는 방법은
Ctrl + z
를 누른다면 실행중인 프로그램을 백그라운드로 보내는 것이다.
fg
를 입력하면 foreground로, 백그라운드로 보낸 프로그램이 포그라운드로 나오며 다시 켜진다
jobs
를 입력하면 백그라운드에 있는 프로그램을 볼 수 있다.
+는 fg를 했을 떄 foreground로 나오는 프로그램이다. -는 그 다음순서가 된다.
다른 숫자를 실행하고 싶다면
fg %숫자
를 입력하면 다른 백그라운드 프로그램을 실행 가능하다.
강제로 종료하고 싶다면
kill %숫자
를 입력하면 강제 종료가 된다.
강력한 강제 종료를 원한다면
kill -9 %숫자
를 입력한다.
실행하는데 걸리는 시간이 오래 걸리는 명령의 경우 백그라운드로 보낼 수 있다.
실행할 때 부터 백그라운드로 보내는 방법은 명령의 마지막에 &을 붙이는 것이다.
백그라운드 명령이 끝나게 되면 Exit 1 이 출력되며 끝났음을 알려준다.
jobs를 통해 Running 상태임을 확인할 수 있다.
항상 실행 (daemon, service)
daemon의 개념
daemon은 항상 실행되고 있다는 특성을 가진다.
우리가 사용하는 프로세스는 필요할 때 키고 필요 없을 때 끈다. 하지만 데몬은 항상 실행된다.
우리가 사용하던 프로세스들은 필요할 때 켜고 필요 없을 때 끄는 것이다.
server에 해당하는 프로그램들이 데몬에 해당한다. 언제 웹 브라우저가 접속할지 알 수 없기 때문에 항상 실행해야한다.
데몬의 사례로 웹서버 예시
sudo apt-get install apache2
로 아파치 설치
cd /etc/init.d/
에 아파치가 설치 됐음을 확인 가능
/etc/init.d 디렉토리는 데몬 프로그램들이 설치되는 위치이다.
데몬들이 설치되는 장소.
이 안의 파일을 키고 끄는 방법은 일반적인 프로세스와 다르다.
service를 사용
sudo service apache2 start
이러면 apache가 켜진 것이다.
ps aux \| grep apache2 를 통해 확인 가능
sudo service apache2 stop
을 통해 끄기 가능하다
데몬은 service를 이용해 start, stop 한다.
데몬은 자동으로 켜지고 있어야 할 필요성이 있다.
/etc/rc3.d 디렉토리는 운영체제를 cli로 구동하고 있을 경우
/etc/rc5.d gui로 구동하는 경우
ls -l 하여 파일을 확인 해 보면 ../init.d/apache2라는 걸 볼 수있다. 그 옆에는 S02apache2라고 쓰여있다. 이건 링크를 건 것이다. 바로가기 같은 것.
바로가기의 이름 앞에 S02라고 되어있는 것은 S로 시작되면 이 이름에 해당하는 이 프로그램은 rc3.d 디렉토리에 있으면 콘솔을 통해 cli로 부팅된 컴퓨터의 경우 컴퓨터가 시작될 때 이 프로그램이 자동을 실행된다는 뜻이다.
K로 시작되는 것은 kill로, K로 시작되는 프로그램은 시작되지 않는 다는 것이다.
01, 02는 우선순위를 나타낸다.
특정 데몬을 콘솔로 부팅될 때 자동으로 데몬이 실행되게 하고 싶다면 rc3.d에 이러한 이름으로 링크를 걸면 된다.
./S02apache2 를 실행하면 링크를 걸었기 떄문에 아파치가 있는 것처럼 쓸 수 있다.
정기적으로 실행 (cron)
CRON
정기적으로 명령을 실행시켜주는 도구, 소프트웨어.
데이터를 정기적으로 백업한다던지, 누군가에게 전송한다던지, 정기적으로 인터넷을 통해 시간을 조정한다던지
등의 작업을 실행해야 할 떄 CRON을 사용한다.
crontab -e 하면 하고자 하는 일을 정의할 수 있다.
정기적으로 실행시키고 싶은 작업이 있을 때 적어주면 CRON이 동작해 실행시켜준다.
m : 첫 번째는 실행되는 분의 주기. 분 당 몇 번 실행할 것인가
10 : 매 시간 10분
\*/1 : 1분에 한 번
h : 시간
* : 시간과는 상관 없이 실행
1 : 1시에 실행
10 1 : 1시 10분에 실행
dom : day of month. 한 달에서 몇 일인지
24 : 매달 24일에 실행
* : 일과 상관 없이 실행
mon : month. 몇 월
dow : 요일
crontab expression
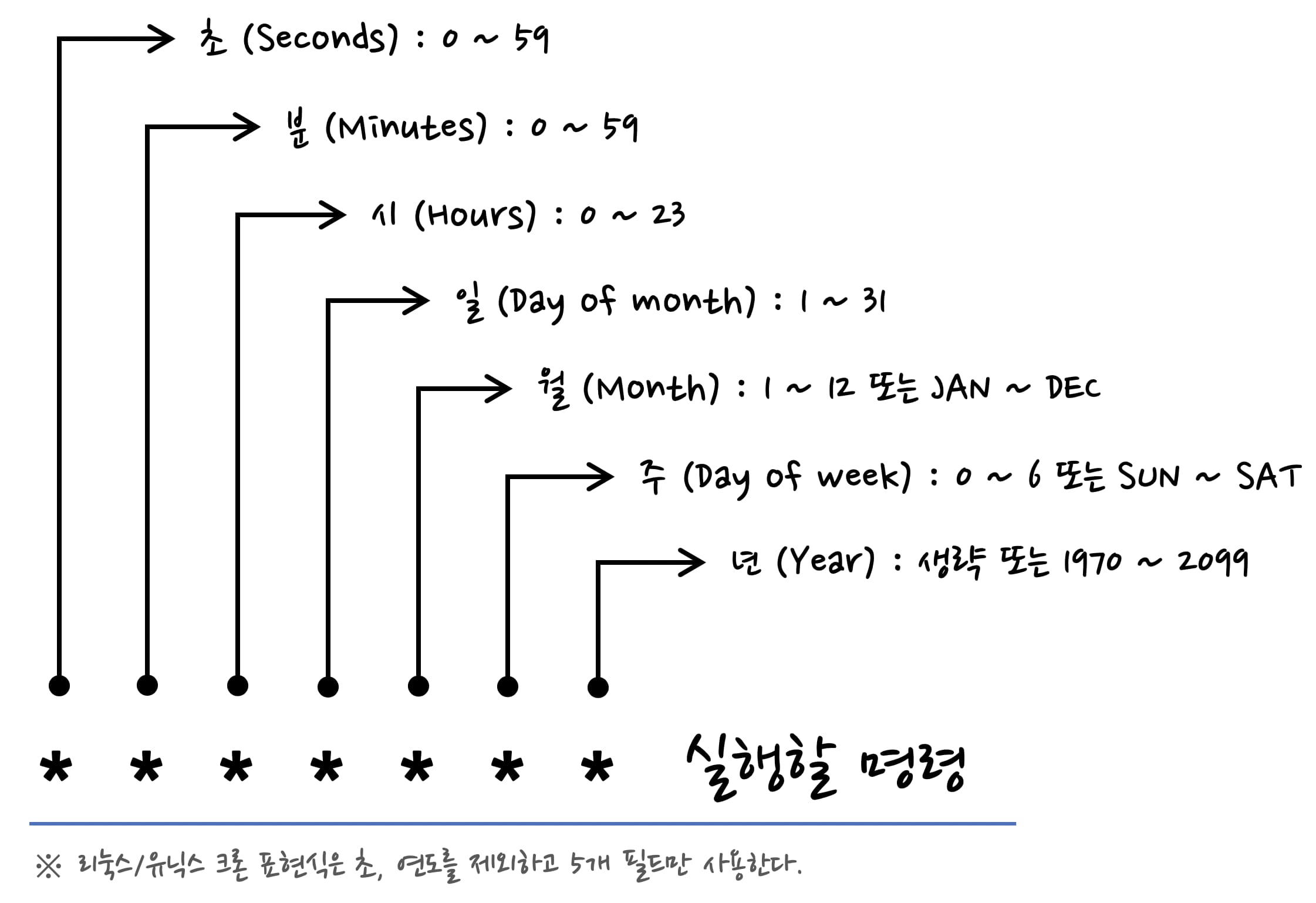
command : 1분에 한 번씩 실행하고 싶은 명령을 입력
date > date.log 하면 현재 시각이 date.log에 실행결과가 들어가게 된다.
date >> date.log 하면 뒤에 실행 결과가 추가되게 된다.
*/1 * * * * date >> date.log
이렇게 입력한다.
crontab -l 을 통해 만든 크론 명령을 확인한다
date.log가 잘 업데이트 되는지 확인한다.
tail date.log 하면 뒤쪽의 텍스트를 출력해 준다.
-f 를 주면 뒤에 무언가 추가되면 자동으로 화면에 보여준다
tail -f date.log
제대로 동작하고 있다면 cron을 통해 항목이 자동으로 추가가 되고, tail에 의해 화면이 refresh 될 것이다.
crontab -e 를 통해 수정
*/1 * * * * date >> date.log 2>&1 하면 표준 에러를 표준 출력으로 redirection 하는 것이다. 표준 에러를 표준 출력화 하는 것이다.
에러가 있을 때 date.log에 함께 저장이 된다.
CRON의 사용 사례
서버는 사용자가 전송한 정보를 받아 글이 등록되었다고10만 명에게 email을 발송한다고 하자.
10만명에게 메일을 보내는데 한 사람당 0.1s가 걸린다고 하자.
그럼 전송 작업은 끝나지 않고 계속 켜져 있다. 그리고 10만명의 동작이 끝나고 전송 완료됐다고 다른 작업을 할 수 있으면 좋은 작업이 아니다.
서버에는 저장이 되었다라는 saved를 어딘가에 기록하고 작업을 끝내준다. 글을 작성한 사람은 금방 결과를 받았으니 글을 잘 작성했습니다라는 것을 빠른 속도로 보여줄 수 있다. 그리고 서버에 설치된 cron이 saved라는 정보를 확인해 추가가 되었다면 추가된 정보에 대해서 background로 10만개의 이메일을 보내는 작업을 진행한다.
글을 쓴 후 사용자는 자신이 하던 일을 하면 되는 것이다.
쉘을 시작할 때 실행
Startup script
쉘이 시작됐을 때 특정 명령어가 자동으로 실행되게 하는 방법
특정 명령어가 실행되기를 바랄 때 어떻게 하는가
alias는 별명이란 뜻.
alias l='ls -al'
l 을 입력하면 ls -al 에 해당하는 명령어가 실행된다.
alias ..='cd ..'
..을 누르면 cd ..이 된다
alias c='clear'
c를 누르면 clear 된다
이 명령들을 쉘을 열었을 때 이런 명령들을 실행하면 그 다음부턴 alias들을 사용할 수 있다.
echo $SHELL
하면 사용중인 shell을 알 수 있다.
bash는 사용자가 bash를 처음 실행했을 때 특정 파일을 실행하도록 약속되어있다.
home directory에 .bashrc 파일을 만들게 되면 shell이 실행될 때 .bashrc 안의 파일을 실행하도록 약속되어있다.
echo 'Hi, bash' 를 추가하여 저장을 해 보자.
그러면 다시 접속 했을 때 Hi, bash를 확인하 수 있다.
bash를 입력해보면 알 수 있다.
$PATH의 값을 변경하는 등을 startup script 안에 관련 코드를 바꿔주는 코드를 넣으면 시작할 때 실행되면서 영향을 받게 된다.
다중 사용자
다중 사용자 시스템이 되는 순간 시스템의 복잡도가 매우 높아진다.
어떤 행위에 대해 누군가는 해도 되고 안되는 것을 조정하기 위해서는 그 사람의 모든 행위에 대해 권한에 대한 체크가 들어가게 된다.
운영체제를 배우고 사용하는 입장에서도 힘든 일이다.
여러 사람들이 쓰고 권한을 갖고 있기 때문에 권한에 대해 잘 모르는 사람이 썼다가는 낭패를 당할 수 있다.
다중 사용자라는 관점의 측면이 투영되기 때문에 다중 사용자를 사용할 때 어떤 문제점이 있는지 알 필요가 있다.
여러 명이 운영체제를 같이 사용하는 방법. 거기서 파생하는 복잡성과 위험성을 알아보자.
id
입력 시에 uid(유저 아이디)와 gid(그룹 아이디) 등의 정보가 나타난다.
앞에 누구인지 보여주는 정보가 자신의 아이디인 경우가 많지만 커스터마이징이 가능해 달라질 수 있다.
who
입력 시에 현재 이 시스템에 누가 접속해 있는지를 볼 수 있다.
exit
로 컴퓨터 접속을 끊을 수 있다
관리자와 일반 사용자
super(root) user VS user
super user는 시스템의 강력한 사용자
user는 일반 사용자
현재 사용하는 컴퓨터에서 명령을 할 때 관리자의 명령을 사용할 때는 sudo를 사용한다.
super user가 되는 방법?
우선은 내가 super user인지 아닌지 확인해야한다.
앞에 $ 표시는 사용자가 일반 사용자라는 뜻이다. #이면 슈퍼 유저이다.
super 유저가 되기 위한 방법
명령어 입력
su - root
패스워드 입력 후 슈퍼 유저가 된다.
exit
하면 logout이 된다. 그리고 이전 계정으로 돌아간다.
root 사용자의 lock을 푸는 방법
sudo passwd -u root
-u는 unlock이다.
위의 명령어를 실행하면 lock이 풀린다.
root 사용자를 다시 lock을 걸고 싶다?
sudo passwd -l root
이러면 root는 lock이 걸린다.
su - root 해도 락이 걸려 안된다.
슈퍼 유저 상태에서 pwd를 하면 /root가 나온다
이는 최상위 디렉토리 밑의 root 디렉토리가 root라는 사용자의 홈디렉토리이다.
일반 사용자의 home directory는 /home/유저 에 있다.
root 사용자는 /root 를 사용한다.
cd / : 루트 디렉토리
cd /root : 최상위 디렉토리 밑의 루트 홈 디렉토리
사용자의 추가
useradd -m 유저이름
유저 추가 및 home directory 추가
sudo passwd 유저이름
유저가 사용할 패스워드 입력
이 새로운 사용자가 sudo 명령을 사용 가능하게 하는 법
sudo usermode -a -G sudo 유저이름
-a : append 추가하는 것
-G : groups, 그룹을 뜻한다. -a -G면 그룹에 추가하는 것.
sudo라는 그룹에 유저를 추가한 것
권한 (permission)
권한
User가 File & Directory에 대해 어떤 일을 할 수 있게 하거나 없게 하는 걸 '권한을 지정한다'라고 한다.
Read & Write & Excute 에 대한 권한을 지정한다.
두 계정을 놓고 한 컴퓨터를 쓴다고 가정.
e 계정이 새로운 txt 파일을 만들었다. 그럼 해당 txt파일은 앞의 User name을 보고 누구의 것인지 알 수 있다.
다른 유저 k가 e의 txt 파일을 쓰기를 했을 때 Permission denied가 나타난다
txt 파일의 구체적인 부분을 보자
-rw-rw-r-- 1 egoing egoing 0 Dec 4 23:19 perm.txt
- : type이다. -는 파일, 디렉토리라면 d라고 적혀있다.
rw-rw-r-- : access mode. 액세스 모드이다.
첫 번째 rw- : owner의 권한
두 번째 rw- : group의 권한
세 번째 r-- : other의 권한. 불특정의 권한
r : read라는 뜻
w : write라는 뜻
x : 실행을 뜻
- : 권한이 없다.
egoing(유저 이름) : owner. 누구의 것인가. e라는 사용자의 것이다.
두 번째 egoing(유저 이름) : group
권한을 변경하는 방법(chmod)
access mode를 변경하는 법
chmod : change mode 를 통해 mode를 바꾼다
chmod o-r perm.txt
perm.txt의 o(other)의 -(뺀다)r(read 권한)을
chmod o+r perm.txt
read 권한 추가
chmod o+w perm.txt
write 권한 추가
chmod u-r perm.txt
perm.txt의 u(user)의 read 권한을 뺀다
chmod u+r permtxt
유저에게 read 권한 부여
x : execute
어떤 파일에 대해서 실행 가능한 파일로 할 것인가 막을 것인가에 대한 것.
#!/bin/bash
이 프로그램을 실행할 때는 bash를 이용해라
hi-machine.sh 라는 파일이 있다고 하자.
./hi-machine.sh는 안 되지만 /bin/bash hi-machine.sh 는 된다
어떤 특정 프로그램(해석기, 파서 등)을 통해서 실행시키는 것은 아무 문제 없지만 해당 파일을 컴퓨터에서 실행하고 싶다면 파일에게 실행 권한을 주어야 한다. 이 때 사용하는 것이 execute이다.
chmode u+x hi-machine.sh
-rwxrw-r-- 가 된다.
./hi-machine.sh 하게 되면 실행 된다.
첫 줄을 해석해 이 파일이 실행 가능한지 본다. 이걸 구동시키면서 이 파일을 출력하게 된다.
chmode o+x hi-machine.sh
하면 다른 계정에서도 실행 되는 것을 볼 수 있다.
directory의 권한
drwxrwxr-x 2 egoing egoing 4096 Dec 5 00:42 perm
읽기와 쓰기 권한이 있다. 여기서 읽기 권한을 없애 본다
chmod o-r perm
이 상태에서 other가 디렉토리 안의 내용을 조회하려 하면 permission denied가 된다.
디렉토리의 r은 디렉토리 안의 파일을 열람할 수 있느냐 없느냐를 나타낸다.
chmod o-w perm
디렉토리에서 w 권한이 없을 경우 perm이라는 디렉토리 안에 파일을 생성할 수 없다.
mv, rm perm.txt 역시 불가능 하다.
chmod o+w perm
디렉토리에 w 권한이 있을 경우 파일 생성, mv, rm 다 가능하다.
chmod o-x perm
실행 권한을 뺀 directory의 경우 안에 들어가는 것도 불가능 하다. cd 명령을 통해 들어갈 수 있느냐 없느냐와 관련된 기능이다.
디렉토리에 대해 디렉토리 하위의 모든 파일과 모든 디렉토리를 한꺼번에 mod 변경을 하고싶을 경우
chmod -R o+w perm
-R은 recursive로 재귀적으로 다 실행하는 것이다.
그럼 perm 내부의 모든 파일, 디렉토리의 권한이 바뀐다.
chmod 사용법
chmod [option] mode[ ,mode] file1 [file2 ...]
o,u, +, - 등의 방식의 단점 : 한 번에 여러 permission 부여가 안된다
8진수로 대신해서 사용 가능
0 : none,1 : execute, 2 : write, 3 : write and execute, 4 : read, 5 : read and execute,
6: read and write, 7 : read, write, and execute다 execute를 주고싶다?
chmod 111 perm.txt
이 경우 다 xxx가 된다. ---x--x--x
chmod 110 perm.txt
이 경우 xx-가 된다. ---x--x---
perm에 대해 모든 사용자가 쓸 수 있게 하고싶다면?
chmod 222 perm.txt
모든 사용자가 w가 된다.
chmod 444 perm.txt
모든 사용자가 r이 된다.
쓰기와 실행을 하고싶다? 쓰기는 2, 실행은 1이다 더하면 3. 그래서 3을 입력한다
chmod 333 perm.txt
이는 모든 사용자에 대해 쓰기와 실행 기능을 가진다.
읽기와 쓰기를 원한다면 4 + 1로 5로 한다
chmod 555 perm.txt
이는 모든 사용자에 대해 read와 execute 기능을 가진다
모든 기능을 다 가지게 하고 싶다면 7을 사용한다
chmod 777 perm.txt
-rwxrwxrwx가 된다.
u : owner
g : group
o : other
a : all
+ : add
- : removes
= : specified
chmod a=rwx perm.txt
모든 사용자에 rwx가 지정된다.
chmod a=r perm.txt
모든 사용자에 대해 read만 지정된다.
그룹
file에 대해 만든 사람을 user라고 한다. 파일의 user 권한을 r은 read, w는 write, x는 execute 할 수 있다,
file을 만들지 않은 사람을 other라고 한다. 즉, user 외의 전부 이다.
file을 공유하고 싶은 경유 o의 권한을 r, w, x를 줄 수 있다.
user 또는 other가 아닌 여러 사람에 대해 파일에 권한을 주고 싶을 경우. 특정 사용자 그룹에 대해 permission을 주고 싶은 사람들을 GROUP으로 묶는다.
GROUP의 이름을 준다. 이 파일에 그룹을 부여한다. 그리고 그룹 권한을 r, w, x를 주는 것을 통해 그룹에 속하는 사람이 읽고, 쓰고, 실행할 수 있게 된다.
cd /var
이 디렉토리는 변화가 많은 파일들이 있다. 개발자가 공용으로 사용할 디렉토리 생성
.에 대한 권한을 보면 현재 디렉토리의 권한을 살펴볼 수 있다.
sudo mkdir developer
그 후 ls -al을 통해 확인하면 그룹이 root로 되어있다.
그룹을 바꿔보자.
존재하지 않는 사용자를 생성할 때 그룹에 속하게 할 경우
useradd -G {group-name} username
그룹을 추가하는 방법
sudo groupadd developer
!! : 직전에 입력했던 명령어
nano /etc/group
확인하면 가장 끝에 새로운 그룹이 추가되어있다.
/etc/group은 그룹에 대한 정보가 쓰여있다.
그룹을 추가 했으면 그 그룹에 유저를 추가한다.
usermod -a -G 그룹이름 유저이름
usermod : 유저를 수정한다. user modify
-a : append. 그룹에 사용자를 추가한다. -G와 함께 사용
-G : groups. 그룹이다.
이걸로 유저가 그룹에 추가된다.
그 후 shell에 다시 접속해야 적용된다.
directory의 그룹을 바꾸어주자.
chown {-R} [user]{:group} [file|dierectory]
chown : change file owner and group
현재 디렉토리의 owner와 group을 바꿀 수 있다.
sudo chown root:developer .
실행하면 현재 디렉토리의 group이 developer가 된다.
그럼 해당 디렉토리의 작업에 대해 group이 권한을 가지게 된다.
인터넷, 네트워크 그리고 서버
internet, network, server
내 컴퓨터에 웹 브라우저가 있다고 하자.
웹 브라우저에 google.com입력. google.com에 해당하는 컴퓨터로 접속이 일어난다.
google.com에서 찾아서 내 컴퓨터로 다시 접속한다.
그 신호가 이 화면에 다시 표시된다.
내 컴퓨터는 구글에게 요청(request)을 한 것이다.
구글이 정보를 나에게 보내주는데 응답(response)한 것이다.
request 한 나의 컴퓨터가 client
request를 받아서 response 해 주는 컴퓨터가 server이다.
client는 요청, server는 응답한다.
서버에 접속하는 google.com같은 것을 domain name이라고 한다.
이 서버에 접속하는 다른 방법은 ip(internet protocol) address로 접속하는 것이다.
google.com의 ip address는 무엇일까?
ping google.com
하면 172.217.25.78 이 나온다.
이 ip address를 copy paste 하면 구글로 접속된다. 이게 구글의 서버에 접근할 수 있는 주소인 ip address이다.
구글에 접속하기 위해 둘 다 사용할 수 있는 것이다.
domain name, ip address는 왜 둘 다 사용할 수 있을까?
두 주소 체계의 관계?
google.com을 입력하면 google.com으로 request가 가는 것이 아닌 ip address로 변환되어 ip address로 접속이 들어가고 response가 오는 것이다.
google.com의 ip address를 어떻게 알 수 있는 걸까?
DNS라는 서버가 있다. 이 세상의 모든 domain이 각각 어떤 ip인지 아는 거대한 서버이다.
우리의 컴퓨터는 google.com을 입력하면 DNS 서버로 접속이 이루어지고 google.com의 ip address를 알아내 접속을 하고 응답을 받는다.
서버로 사용할 컴퓨터가 있다면 누군가 이 컴퓨터에 접속할 수 있도록 해야한다. 그러려면 이 컴퓨터의 주소를 알아야한다.
ip addr
ifconfig를 통해서도 확인할 수 있다.
이 중 inet을 찾는다. 10.0.2.15 가 자신 컴퓨터의 ip address이다.
이 컴퓨터에 접속하기 위해서는 10.0.2.15이라고 하는 ip address로 접속하면 되는 것이다.
다른 방법으로 웹 브라우저에 ipinfo.io/ip 로 입력하면 해당 서비스가 어디서 접속했는지 분석 후 나의 ip를 알려주게 된다.
curl google.com
구글에 접속해 html 파일을 다운받아 화면을 보여준다
그럼
curl ipinfo.io/ip
입력시 자신의 ip를 알려준다
그런데 ip addr 로 입력한 것과 curl ipinfo.io/ip 가 다른 경우가 있다.
ip addr은 컴퓨터가 실질적으로 가지고 있는 ip를 알아내는 것이다. 컴퓨터에 부여된 실제 ip이다.
curl ipinfo,io/ip는 접속했을 때 어떤 ip로 접속했는지를 알아내는 것이다. 접속의 결과적인 ip가 무엇인지 확인하는 것이다.
그 결과가 다를 수 있는 것이다. 두 값이 같다면 컴퓨터의 실제 ip와 외부에 접속할 때 사용하는 ip가 같은 것이다.
같은 ip를 가지고 서비스를 운영할 수 있는 경우인 것이다.
하지만 많은 경우 두 가지가 다르다.
집에서 컴퓨터를 쓸 때는 통신사와 계약을 맺어 통신사 회선에 연결이 되면 컴퓨터는 인터넷이 사용 가능하다.
통신사는 이 회선에 대해 ip를 할당한다. 이 컴퓨터의 ip는 이 할당된 ip가 된다.
할당된 ip는 원래 다른 장비마다 별도의 계약을 채결해 다른 ip를 받아야 하지만 비싸다.
그래서 Router(공유기)를 하나의 회선에 붙인 후 다양한 기기를 Router에 붙여 사용한다.
이렇게 되면 통신사가 제공하는 IP는 Router 장치의 ip가 된다.
각각의 컴퓨터는 사설 ip라는 private ip가 등장한다.
이를 통해 각각의 Device를 식별 가능한 것
라우터에 연결된 ip가 외부에 공개된 ip로 public address라고 한다.
각각의 device에 연결된 ip가 private address 라고 한다.
curl로 ip를 알아냈을 때와 ip addr로 알아냈을 때의 차이점을 이제 알 수 있다.
curl을 통해 알아내는 것은 외부에서는 router가 가진 ip를 알 수 있다.
그런데 ip addr로 알아내는 것은 이 컴퓨터에 실질적으로 어떤 ip를 가진 것인가를 아는 것이기 때문에 private ip가 나온다.
만약 router 없이 컴퓨터에 접속중이라면 같게 나올 것이고 router가 있다면 다르게 나올 것이다.
public ip와 private ip가 같다면 컴퓨터를 그대로 서버로 사용 가능하다.
하지만 공유기로 묶여있는 상황이라면 그대로 서버로 쓸 수는 없다.
router들 간에 묶여있는 device끼리는 접속 가능하다.
router를 쓰는 컴퓨터라고 할 지라도 세팅을 한다면 공인 ip를 통해 들어와도 특정 컴퓨터로 접속해 서버 활동을 할 수도 있다.
웹서버 (아파치)
web server를 linux에 설치하는 방법
인터넷은 client와 server로 이루어져있다.
client는 server에게 request를 하고 server는 client에게 response를 한다.
client로 사용하기 위해서는 web browser가 있어야한다.
주소란에 google.com/index.html 을 입력하면
google.com에 request를 보낸다. 그럼 웹 서버는 요청이 들어오면 요청을 분석한다.
웹 서버는 스토리지에 있는 index.html을 읽어서 가져온 후 response 해 준다.
웹 브라우저에 해당하는 제품 : firefox, ie, chrome 등
웹 서버에 속하는 제품 : Apache, nginx, IIS 등
웹 서버 역시 설치해서 사용하면 된다.
우리는 domain name, ip address 가 필요하다. 우리는 ip address를 통해 접속 가능하게 해볼 것이다.
apache를 설치한다.
sudo apt-get update
sudo apt-get apache2sudo service apache2 start
를 통해 웹 서버를 켜 준다. stop, restart 등의 명령어도 사용할 수 있다.
웹 브라우저로 웹 서버를 접속해본다.
쉘에서 웹브라우징 할수 있는 프로그램이 있다.
sudo apt-get install elinks
elinks
입력시 url을 물어보는 화면이 나타난다.
그럼 쉘 환경에서 웹 브라우징을 할 수 있게 된다.
나의 컴퓨터에 접속해보자.
elinks https://10.0.2.15
apache로 잘 접속 됐음을 확인할 수 있다.
이렇게 화면에 표시가 된다는 것은 성공적으로 웹 서버를 실행시켰으며 자신의 ip로 접속하는 것도 성공했다는 뜻이다.
웹 서버가 설치되어있는 서버 컴퓨터의 ip address 10.0.2.15을 주소창에 입력해 접속하니 ip에 해당하는 서버 컴퓨터의 웹 서버가 동작하여 요청에 대한 응답을 해 준 것이다.
그 결과 웹브라우저 화면에 apache의 시작 화면이 나타난 것이다.
자신의 컴퓨터에 접속하는 다른 방법으로 localhost가 있다. 한 대의 컴퓨터 안에서 서버에 req를 보내고 res를 보내는 방식이라면 같은 컴퓨터로 보내는 경우 localhost를 사용하면 된다. localhost 와 127.0.0.1은 같은 것이다.
127.0.0.1은 자기 자신을 나타내는 ip로 바뀌지 않는다. 자기 자신을 의미하기 때문이다.
elinks에 입력하면 10.0.2.15와 같은 화면이 나타난다.
127.0.0.1의 domain name이 localhost가 된다.
웹브라우저로 request를 보내면 서버 컴퓨터에 설치되어서 실행되고 있는 프로그램 웹서버가 그것을 받게 된다.
웹 서버는 요청을 받아 웹 서버의 storage에 어딘가에 저장되어 있는 요청한 파일을 읽는다.
브라우저에 ip address를 입력하면 ip address에 해당하는 서버 컴퓨터에 접속이 들어가고 서버 컴퓨터에 웹 브라우저가 접속했으니 서버의 여러 프로그램중 웹 서버가 응답을 받는다.
그 후 index.html에 대한 요청이 들어왔으니 웹 서버는 어떤 특정한 디렉토리에서 index.html을 읽는다. 그리고 그 파일을 읽어온 다음에 그것을 웹 브라우저에게 응답하면 웹 브라우저는 index.html 안에 저장된 html을 해석해 웹 브라우저에 출력하게 된다.
웹 서버는 index.html을 어디에서 읽어오는 것일까?
unix 계열에서의 설정에 대한 것은 /etc에 저장되어 있다.
cd /etc/apache2
에 아파치에 대한 설정 파일이 있다.
그 중 apache2.conf를 확인해야 한다.
IncludeOptional sites-enabled/\*.conf
sites-enabled라는 디렉토리 안의 모든 .conf 파일을 읽고 사용한다는 것이다.
디렉토리 안에 sites-enabled가 있다.
cd sites-enabled
000-default.conf 가 있고 그걸 수정할 수 있다.
DocumentRoot /var/www/html
이라고 적혀있다.
cd /var/www/html
그 안에 index.html 파일이 있다.
이 파일의 이름을 바꾼다
sudo mv index.html index.html.bak
그 후 elinks http://127.0.0.1/index.html
을 실행하면 not found가 나타난다.
현재 디렉토리에 sudo nano index.html 입력 후 새로운 html 문서를 만들어보자.
<html>
<body>Hello web server!</body>
</html>그 후 elinks로 접속해 보면 잘 나타나는 걸 볼 수 있다.
웹 브라우저가 접속할 때 웹 서버는
/etc/apache2
아래의 여러 설정 파일을 참고해 사용자의 접속이 들어왔을 때 서버 컴퓨터의 어느 스토리지의 어디에서 사용자가 요청한 파일을 찾을 것인가를 확인한다. 그리고 웹 브라우저로 response를 보낸다.
설정이 존재하고 설정을 어떻게 하느냐에 따라 프로그램이 동작되는 방식을 바꿀 수도 있다.
웹 서버가 사용자가 요청한 파일을 찾는 디렉토리는 설정을 바꾸면 다른 곳으로 언제든 이동 가능하다.
사용자가 요청한 파일을 찾는 최상위 디렉토리를 Document root 라고 부른다.
/var/www/html 을 사용하는 이유는 /etc/apache2/sites-enabled/000-default.conf 에 설정이 /var/www/html로 되어있기 때문이다.
어떤 서버를 설치하건 /etc 밑에 설정 파일이 있고 그 곳의 설정 파일을 바꾸면 동작하는 방식이 달라진다.
/etc/apache2/sites-enabled/000-default.conf 를 확인하면
ErrorLog ${APACHE\_LOG\_DIR}/error.log
CustomLog ${APACHE\_LOG\_DIR}/access.log combined가 적혀있다. ${APACHE\_LOG\_DIR} 는 아파치 웹 서버가 동작할 때 로그를 확인하기 위해 특정 디렉토리 아래의 error.log 파일과 access.log 파일에 기록하겠다 라는 것이다.
${APACHE\_LOG\_DIR} 는 /var/log/apache2/ 이다.
해당 디렉토리를 보면 access.log와 error.log가 존재한다.
access.log의 내용을 확인
cat access.log
누군가 웹 서버에 접속할 때 마다 끝에 접속한 사람의 정보가 추가가 된다.
실시간으로 확인하기 위해서는 tail을 사용한다.
tail -f /var/log/apache2/access.log
이 명령은 실시간으로 이 파일의 끝에 있는 정보가 나타난다.
elinks를 통해 들어가면 위의 tail이 작동해 access 로그가 찍힌다.
curl 역시 마찬가지로 접속해도 새로운 access 로그가 찍힌다. (200)
없는 파일에 접속하면 접속은 확인이 되지만 상태(404)도 같이 나타난다.
이것이 로그를 찾는 것이다. 대부분의 서버 프로그램이 가지는 동작이다.
서버의 로그가 어디에 있을까에 대해 알아야한다.
error.log를 보자.
tail -f /var/log/apache2/error.log
아파치를 동작시킬 때 에러가 나면 로그가 찍힌다.
원격제어 (ssh)
자신의 client를 통해 서버 컴퓨터를 원격 제어를 해야할 경우 SSH를 사용한다.
원격 제어를 쓰게 되면 멀리 있는 컴퓨터를 내 앞에 있는 것 처럼 다룰 수 있다.
Server에는 SSH Server를 설치한다.
Client에는 SSH Client를 설치한다.
SSH Client에 명령어를 입력하면 SSH Server가 설치된 컴퓨터를 제어한다.
SSH Server라는 프로그램이 그 명령어를 전달하게 된다.
SSH Server는 그 결과를 SSH Client 화면에 표시하게 된다.
대부분의 unix는 SSH가 기본적으로 설치되어있다.
sudo apt-get remove 프로그램
프로그램 삭제
sudo apt-get purge 프로그램
환경설정을 포함한 강력한 삭제
ssh 설치
sudo apt-get install openssh-server
다른 컴퓨터가 내 컴퓨터에 접속할 때 사용
openssh : ssh와 관련된 여러 프로그램을 제공하는 프로젝트
sudo aptget install openssh-client
다른 컴퓨터로 원격 접속 할 때 사용
sudo service ssh start
sudo ps aux | grep sshsshd가 실행되고 있다는 걸 확인할 수 있다.
우리의 컴퓨터는 ssh server가 설치된 상태이며 계속 실행되는 상태이다.
ssh client의 접속을 기다리는 중이다.
ip addr
를 통해 ip address를 확인한다. (예: 192.168.0.65)
원격 접속할 시
ssh egoing@192.168.0.65
다른 컴퓨터임에도 불구하고 원격으로 다른 컴퓨터에 접속할 수 있다.
이 컴퓨터로 명령을 내리면 ssh로 접속한 컴퓨터를 대상으로 실행되게 된다.
포트 (port)
:80 이것이 포트
ssh -p 22 egoing@192.168.0.65
-p : port
하면 접속이 된다. 다른 포트는 접근이 안 된다.
ssh는 22번 포트를 사용한다.
web : 80
ssh : 22
모든 컴퓨터에는 port가 존재한다. port는 일종의 구멍이다.
ssh server를 설치하면 22번 포트에 연결되도록 약속되어있다.
web server를 설치하면 80번 포트에 접속하도록 약속되어있다.
client 컴퓨터를 통해 웹 브라우저가 깔려있고 서버 주소를 입력하면 서버 컴퓨터의 80번 포트를 찾아간다.
왜냐하면 웹 서버는 80번 포트에 연결되어있기 때문이다.
그래서 웹 브라우저에 주소에 :80을 안 붙여도 되는 것이다. 알아서 80번 포트로 찾아가고 80번 포트에서 대기하던 웹 서버가 동작하기로 약속된 대로 동작한 후 웹 브라우저에게 돌려주게 된다.
ssh client는 22번 포트를 쓰도록 약속되어있기 때문에 포트 번호를 따로 적지 않는다면 22번에 listen 상태이던 ssh server가 받아서 처리 후 ssh client에게 보내준다.
네트워크는 0에서 1023번 port까지는 well known port로 표준처럼 사용하는 통신 시스템을 고정해 놓는다. 명시하지 않아도 가능하도록.
1024~65535 까지는 아무 프로그램을 쓰면 된다.
1023까지는 중요한 인프라와 같은 것을 쓴다
그 외에는 표준이라 할 수 없는 것들이 존재한다.
/etc/ssh/sshd\_config
sudo service ssh restartssd_config를 열어보면 이 파일에는 Port 22라고 적혀있다.
이 값을 수정하면 ssh의 설정을 바꾸는 것이다.
config 파일대로 바뀌어 바꾼 port로 접속해야한다.
포트를 바꾸는 이유는 22번은 너무 잘 알려져 있기 때문에 다른 사람의 접속을 막고자 port번호를 바꾸기도 한다.
포트 포워딩이란?
ISP(internet service provider) 회사들이 집에 회선 하나를 계약 후 여러 대의 컴퓨터가 하나의 회선을 공유할 때 사용하는 기기가 router(공유기)이다.
public ip가 211.46.24.37 이라고 가정하면 이 ip는 router의 ip가 된다.
router는 ISP가 제공하는 회선을 꼽을 수 있고 컴퓨터들과 연결되는 부분이 있다.
각각의 컴퓨터는 192.168.02, 192.168.03, 192.168.04 이런 식의 ip를 갖는다.
router에 붙은 ip가 public ip address, device에 붙은 ip는 private ip address
public은 외부의 사람이 public ip를 통해 접속이 가능하다.
그런데 하나의 디바이스로 가고싶다면 기본적으로는 존재하지 않는다. 사설 ip이기 때문이다.
192.168.04에 서버를 설치하고 외부의 사용자가 접근하게 하는 방법이 없을까?
그것이 port fowarding이다.
router 역시 네트워크 기능이 있고 port라는 것이 있다.
192.168.04 역시 port가 존재한다. router에 존재하는 포트를 활용해 사용자가 접속이 들어왔을 때 특정 포트로 접속이 들어오면 그 접속을 특정 컴퓨터로 전달한다라는 것이 포트 포워딩이다.
router의 9000번 포트로 접근한다면 접근하게 만든다면
211.46.24.37:9000으로 들어가면 라우터로 들어가게 되고 라우터의 65535개의 포트 중에 9000번 포트로 들어왔다는 것이다.
그 때 라우터의 설정을 열어 라우터에 9000번 포트는 192.168.04:80 으로 가라고 설정을 지정하는 것이다.
그러면 9000번으로 접속하면 192.168.04:80으로 보내게 된다.
그럼 웹 서버가 받아서 요청한 사용자에게 돌아가면 사용자의 컴퓨터는 컴퓨터에 저장되어있는 웹 페이지를 해석해서 보여주게 된다.
공유기의 환경설정을 보면서 포트포워딩을 하면 된다.
공유기의 서버에 접근하여야한다.
공유기에는 기본적으로 웹 서버가 깔려있다.
공유기에 접속하기 위해서는 내부적으로 통용되는 ip를 가지고 있어야한다.
공유기의 안쪽에서만 통용되는 ip를 default gateway라고 한다.
default gateway를 확인하는 방법은 ip route를 입력하면 된다.
default via 192.168.0.1 dev enp0s3
에서 192.168.0.1 이 default gateway가 된다.
192.168.0.1을 브라우저에 입력하면 라우터의 관리자화면이 나타난다. 여기부터는 공유기마다 다르다.
관리도구 - 고급 설정 - nat 라우터 관리 - 포트포워드 설정
내부 IP주소 : 서버를 설치하고자 하는 컴퓨터의 IP를 입력하는 것이다.
192.168.0.65를 입력한다. (컴퓨터의 ip 주소)
규칙이름은 세팅을 위해 나중에 설정할 때 사용한다. 임의의 이름 입력
외부포트 : 라우터에 접근할 포트의 번호를 말한다. 여기서는 9000이다.
내부포트 : 컴퓨터상의 포트를 말한다. 몇 번째 포트에서 listen을 하고 있는가에 관한 것이다. 여기서는 80이다.
추가를 누르면 규칙이름, 내부IP, 프로토콜, 외부 포트, 내부 포트가 나타난다.
서버에 접근할 사용자들에게 알려줄 ip는 외부ip와 포트 번호가 된다. 즉 211.46.24.37:9000 으로 접속할 것을 알려주면 된다.
curl ipinfo.io/ip
이것이 라우터의 ip이다.
사용자들은 나타난 ip를 입력 후 :9000을 입력하면 컴퓨터의 web server가 나타난다.
정리하면
사용자가 public ip 뒤에 :9000을 입력함으로써 라우터의 9000번 포트로 진입하게 되고
우리가 9000번 포트는 192.168.0.65의 80 포트로 포워딩 하도록 정책을 세워놨으므로
해당 접속은 192.168.0.65의 80번 포트에서 대기하고있는 웹 서버에 접속하고 결과를 공유기로 전달하면 공유기가 요청한 사용자에게 보내주게 된다.
이 때 사용하는 것이 포트 포워딩이다.
도메인 (domain)
Domain과 DNS(Domain Name System)
컴퓨터가 서버에 접속할 때 서버의 주소가 google.com이라면 브라우저에 google.com이라고 쓴다.
실제로는 google.com이 아닌 IPA(ip address)로 접속이 이루어진다.
DNS가 존재하고 컴퓨터는 이 DNS의 IP를 알고 있다.
사용자가 google.com이라고 입력하면 DNS 서버의 IP로 접속한다. 그 후 google.com의 IP Address를 알려준다. (예:216.58.197.174)
그 때 IP address를 통해 접속해서 google.com에 커넥션을 맺을 수 있다.
서버에 google.com과 같이 도메인을 서버에 부여해 도메인의 ip로 누군가가 접속하면 이 서버의 ip가 무엇인지 알려주어 그 사람이 내가 가진 서버에 접속할 수 있게 해보자.
Domain Name Server 이전에 hosts라는 파일이 있었다.
도메인이 어떤 ip다 라는 정보를 갖고있는 파일이다.
인터넷을 사용하는 컴퓨터마다 hosts라는 파일을 가지고 있어 DNS에 물어보는 것이 아닌 hosts 파일에 적힌 ip를 보고 그 ip로 접속했던 시절이 있었다,
google.com에 접속했을 때 내 컴퓨터의 웹 서버 내용이 나오도록 바꿀 수 있다.
도메인 네임을 변조하려면 hosts 파일을 바꾸면 된다.
sudo nano /etc/hosts
이 파일 안에
127.0.0.1 google.com
을 입력하게 되면 google.com으로 입력했을 때 나의 웹 서버가 나타나게 된다.
이는 hosts file을 바꿈으로써 google.com이 127.0.0.1로 바꿨기 때문이다.
우선 google.com을 입력하면 hosts 파일을 먼저 찾게 된다. hosts 파일에 존재한다면 DNS를 찾지 않는다.
hosts에 없을 경우에 DNS를 접속하기 때문에 google.com을 입력했을 때 127.0.0.1이 나타나게 된 것이다.
client는 요청하는 쪽, server는 응답하는 쪽이다.
인터넷에 참여하는 각각의 컴퓨터 한대를 host라고 부른다.
host들을 묶어서 network라고 한다. 그리고 network들이 모인 전체 집단을 internet이라고 한다.
etc 밑의 hosts 파일은 host들의 ip를 적어놓은 것이다.
host들의 이름이 각각 어떤 ip를 갖는가를 적어놓는 파일이 hosts이다.
DNS가 존재하기 이전부터 hosts 파일을 만들고 적어놓은 것이다.
인터넷의 발전 과정에서 hosts에 적는걸로 관리가 안 되는 상황이 왔다.
전 지구적 규모의 거대한 이름을 관리하기 위해 본질적인 해결책이 필요했고 그것이 DNS이다.
/etc/hosts 의 활용법
운영하고있는 서버가 있고 도메인에 등록이 되어있다.
서버의 결함에 의해 바꾸었다면 서버 쪽에 수정한 내용을 바로 반영하기 전 etc의 hosts를 자기 컴퓨터로 수정하게 되면 자신을 가리킬 수 있다.
그럼 다른 사람들은 원래 서버에 접속, 나는 내것만을 변조해서 볼 수 있게 된다. 그런 경우 편리하게 작용할 수 있다.
그래서 cracker의 공격 대상이 되기도 한다. google.com을 공격자의 server의 ip로 바꾸게 되고 google.com과 디자인이 똑같은 사이트로 만든다. 그리고 google.com이라고 입력 하게 되면 공격자의 웹사이트로 가게 되고 로그인을 시도하게 된다.
그럼 그 ID와 PW를 기록했다가 자동화하여 나쁜 일을 하게 되면 공격이 된다.
hosts 파일은 잘 관리해야한다. 백신 파일의 역할 중 하나이다.
우리가 운영하는 서버가 존재하고 서버의 domain을 구해 사용한다면 DNS 서버가 IP를 알려주어 접속할 수 있게 하는 방법을 알려주자.
cat /etc/resolv.conf
nameserver 168.126.63.1
nameserver 168.126.63.2
이런 것이 나온다. 이는 Korea republic의 ktrc 라고 나와있다. 이는 kt와 계약했고 kt에서 제공하는 케이블이나 와이파이에 접속하면
/etc/resolv.conf 파일의 내용이 kt에서 서비스로 제공하는 DNS서버로 IP가 바뀐다.
자신이 모르는 도메인에 접속하고자 하면 이 nameserver IP로 접속을 한다. 부하분산, 백업으로 두 개 존재.
이 DNS 서버에 나의 도메인 정보를 알려주어야 한다. 누군가가 물어보면 나의 IP를 알려주어 접속할 수 있게 해 주어야 한다.
그러기 위해선 도메인을 구입하여야 한다.
도메인은 전세계의 민간 기구에 의해 관리된다.
ICANN이라는 민간 단체에 의해 도메인이 관리가 되고 있다. 도메인의 끝이 어떻게 끝나냐에 따라 관리하는 기관이 다르다.
이 이름을 독점적으로 사용하고싶다면 구매하여야한다. 다음은 예시이다.
free domain 검색시 freenom이 나타난다. 도메인을 조회해 볼 수 있다. check availability를 하여 get it now로 간다.
check out을 통해 구매할 수 있고 구매 방법에 12개월 까지는 무료이다. 로그인 후에 complete order하면 무료 도메인을 얻을 수 있다. services의 my domains를 클릭하면 나타난다. 그곳의 manage로 들어가 target에 ip를 작성한다. 공용 ip를 사용한다. save changes를 통해 목록이 추가가 된다.
그럼 DNS에 우리가 구매한 도메인이 이러한 ip를 가지고 있다는 것을 전 세계에 선언한 것이다.
이제 전 세계의 모든 DNS는 그 도메인의 ip를 알기 때문에 인터넷에 접속해 도메인의 이름을 통해 IP에 접속할 수 있다.
host google.com
하면 ip 주소를 확인할 수 있다.
host 구매한도메인.com
하면 구매한 ip를 확인할 수 있다.
구매해도 바로 적용하는 것은 아니고 전 세계에 전파되는 데에 시간이 조금 걸릴 수 있다.
지금까지는 하나의 도메인이 하나의 서버에 매칭이 되는 것이다.
여러 서버에 매칭하고 싶으면 이 도메인을 재사용할 방법이 있다.
admin.egoing.ga라고 적으면 두 번째 서버로
blog.egoing.ga라고 적으면 세 번째 서버로
news.egoing.ga라고 적으면 네 번째 서버로
각각의 도메인 앞에 prefix로 서브 도메인을 붙여 다른 ip를 가리키게 한다면 하나의 도메인을 구입해 여러 개의 사이트를 운영하는 효과를 가질 수 있다.
도메인 구매 사이트로 가서 management로 가
record에 admin이라고 적은 후 다른 ip, blog에 다른 ip, news에 다른 ip를 넣게 된다면 다른 ip를 할당할 수 있다.
DNS의 동작 원리
dig +trace 도메인이름
DNS에게 도메인의 ip를 의뢰하는 것으로 그 결과 ip를 알려주게 된다.
이걸 알아내기 위해 여러 서버를 거치게 된다.
서버의 도메인을 조회했을 때 우리의 DNS와 연결된다.
도메인의 마지막에는 . 이 생략되어있다.
한 대의 컴퓨터가 많은 도메인을 다 알고 서비스하는 것은 어려운 일이다.
domain을 여러 컴퓨터가 분산해서 저장하는 방식을 고안하였다.
우리의 컴퓨터에 연결된 우리의 DNS는 root DNS Server의 주소를 알고있다.
root DNS Server는 10대가 넘는 DNS 서버가 있고 전 세계에 흩어져있다.
우리가 아까 dig +trace 도메인 했을 때 나오는 위의 root-servers.net이 root DNS List 이다.
우리의 DNS 서버는 반드시 root DNS list를 알고 있다.
사용자가 도메인으로 들어왔을 때 그 ip를 DNS 서버로 물어볼 것이다.
우리의 DNS 서버는 root DNS Server에게 물어볼 것이다.
.com을 담당하는 DNS서버가 무엇인지 목록을 물어볼 것이다.
root DNS Server는 .com, .net 등을 누가 담당하는 지 알고있다.
root DNS Server는 그 결과를 돌려준다.
그 결과가 아래 나오는 com. 등으로 나오는 .com을 담당하는 도메인 메인 서버들의 목록이다. 여러 컴퓨터가 부하를 분산하고 있다.
우리의 DNS 서버는 여기 있는 com을 관장하는 서버의 목록 중 하나를 선택하게 된다. 그리고 com의 DNS 서버에게 내 도메인.com의 DNS 서버를 또 물어본다. 그거에 대해 응답해 주는 것이 그 아래 나타나는 것이다. 도매인구매사이트.com으로 나타난다.
그럼 DNS Server에게 ip를 물어보게 된다. 내 도메인의 DNS 서버가 ip를 알려주게 된다.
name은 이름, address는 주소로 address가 나올 때 까지 찾게 된다. 그럼 우리의 클라이언트는 ip로 접속하게 된다.
도메인을 구매하는 것은 관리비용을 내는 걸로 DNS 서버를 관리하는 비용인 것이다.
우리의 실제 ip를 담는 정보도 DNS에 들어가게 되고 그게 접속 가능한 ip가 되는 것이다.
sub domain들은 DNS 서버에 IP를 등록하는 과정이다. 그리고 domain을 구입할 때 도메인의 ip 정보를 저장할 DNS 서버가 자동으로 세팅된 것이지만 도메인을 구입할 때 다른 DNS 서버를 지정할 수 있다. 도메인 네임 서버를 바꿔주면 된다.
인터넷을 통한 서버간 동기화 (rsync)
sync : 어떤 특정 컴퓨터에 있는 내용을 다른 컴퓨터에 올려서 한 쪽의 변경사항이 다른 쪽에 변경사항이 반영되도록 하는 것.
r(remote)sync 이다. 원격으로 독립되어있는 컴퓨터끼리 인터넷을 통해 sync할 수 있게 해 주는 것이다.
네트워크를 통해 파일들을 카피할 때, 백업 할 때에도 사용할 수 있다. 파일 복사가 가능하다.
mkdir rsync
cd rsync
mkdir src
mkdir dest디렉토리 생성
src에 파일을 생성 그 후 파일을 dest에 동기화 시킬 것이다.
cd src
touch test{1..10}테스트가 1~10까지 생성
cd ..
rsync -a src/ dest/가 없으면 dest 안에 src가 만들어져버린다. /를 붙여야 그 안의 내용이 그대로 들어가게 된다.
-a : archive. 아카이브 모드로 동작. 특정 디렉토리가 있으면 그걸 전체 다 복사. 변경사항만 전송하는 모드로 동작. 파일의 현재 속성까지 같이 전송하는 강력한 기능.
-v : 다 출력해라. 진행 상태를 보여줘라.
rsync는 증분 copy를 한다.
dest 디렉토리에 하나가 없으면 없는 것만 복사가 된다.
rsync -av src/ dest
하면 자세한 내용도 나타난다.
원본과 오리지널 파일이 완전히 같은 상황이라면 아무 일도 일어나지 않는다.
삭제된 것만 전송이 된다.
원본에서 touch test11로 추가하게 되면
rsync하면 추가된 11만 전송이 된다.
반복해서 실행을 해도 전송할 대상이 있을 때만 전송하기 때문에 굉장히 효율적이다.
컴퓨터가 두 개 있다고 할 때 sync를 해 보자.
rsync -azP ~/rsync/src/ 사용자이름@192.168.0.65:~rsync/dest
~rsync/dest는 받을 컴퓨터의 디렉토리이다.
-z : 압축하고 전송
-P : 전송 상황을 progress bar로 보여준다
이렇게 컴퓨터간에 원격으로 동기화 할 수 있다.
백업시에 사용된다.
로그인 없이 로그인 하기 (ssh key)
ssh 공개키, 비공개키를 이용한 로그인
linux1, linux2의 두 컴퓨터를 준비
ssh-keygen
key generation이다.
/home/유저이름/.ssh/id_rsa
자신의 홈 디렉토리의 /.ssh 디렉토리에 파일이 생성된다.
id_rsa : ssh private key
id_rsa.pub : ssh public key
위는 절대 누군가에게 노출되면 안 된다. 아래는 노출되어도 괜찮다.
디렉토리에 대해 소유자만이 rwx의 기능이 있다. 다른 사람은 접근이 불가능하다.
로그인하고자하는 컴퓨터에 공개키를 저장시키면 공개키가 저장된 컴퓨터에 로그인 없이 로그인이 가능해진다..
linux2 컴퓨터에서 진행
cd ~/.ssh
확인하면 authorized_keys 존재. 이 파일 안에 id_rsa.pub를 authorized_keys 끝에 붙이면 된다.
linux1에서 진행
ssh-copy-id egoing@192.168.0.67
하게 되면 linux2의 PW를 물어보고 입력하면 복사 붙여넣기를 해준다.
linux2에서 진행
cat authorized_keys
하면 linux1에 있던 id_rsa.pub의 내용이 그대로 linux2의 authorized_keys에 저장이 되었다.
linux1에서 진행
ssh egoing@192.168.0.67
할 경우 로그인 없이 로그인이 진행된다.
정리
ssh-keygen
공개키, 비공개키 생성
ssh-copy-id egoing@192.168.0.67
로그인하고자하는 컴퓨터의 authorized_keys에 public key가 추가된다.
이는 private key를 가지고있는 사람이 로그인하는 것을 허용한다는 것이 된다.
로그인 없이 로그인 할 경우 편리한 기능
rsync를 위해선 기본적으로 로그인이 필요하다. 하지만 ssh 키를 이용해 자동으로 로그인하게 해 주면 로그인 없이 동기화가 가능하다.
rsync -avz . egoing@192.168.0.67~/rsync_welcome
이 디렉토리의 모든 내용이 다 넘어간다. public key를 추가했기 때문에 로그인 없이 가능한 것.
이는 cron을 이용해 자동으로 명령을 실행시킬 때 좋다. 백업 등을 자동화 시킬 수 있다.
SSH의 공개키와 비공개키가 어떻게 작동하는지 원리
자동으로 로그인 되는데 암호화되는 기법이 있는데, 그것이 RSA이다.
텍스트를 암호화하는 것이다. encrypt. 원래대로 돌리는 것이 복호화 하는 것이다. decrypt.
암호화 방식에 따라 key를 쓸 수 있다.
key를 이용해 암호화를 하고 이 키를 이용해서 복호화를 할 수 있다.
저 키를 가진 사람만이 암호를 읽을 수 있다.
이런 방식은 암호화를 할 때와 복호화를 할 때 같은 키를 쓴다. 대칭적인 방식이다.
private key와 public key가 있다면 어떤 정보를 암호화 할 때 private key를 통해 암호화를 한다. 복호화를 할 때는 public key가 필요하다.
이렇게 암호화 할 때와 복호화 할 때 키가 달라지는 방식을 비대칭 방식이라고 한다.
public key와 private key는 짝을 이루는 것이다.
어떤 정보를 암호화 할 때 private key를 썼다면 복호화 할 때는 반드시 public key만 쓸 수 있다.
이렇게 비대칭 방식인게 RSA이다. 이러한 특성을 잘 활용하여 응용하고 잘 응용한 덕분에 빠르게 성장한 중요한 기술이다.
ssh를 통해 인증을 하면 어떤 과정을 거치는가?
SSH Client와 접속하는 대상이 되는 컴퓨터는 SSH Server가 서치되어 있어야 한다.
id_rsa : private key
id_rsa.pub : public key
이 public key는 authorized_keys에 포함되어 있다
public key를 가진 사람은 이 컴퓨터에 접속하는 것을 허용하겠다 라는 뜻이다.
ssh 클라이언트가 서버에 접속하면 서버는 이 컴퓨터에게 특별한 key를 준다. (Random Key)
SSH 클라이언트 프로그램은 SSH라는 디렉토리 안에서 id_rsa 파일이 있는지 없는지 찾아본다.
그런 파일이 있으면 random key를 암호화 시킨다.
그 암호화된 결과를 ssh 서버에게 다시 전송한다.
ssh서버는 random key를 암호화된 정보로 받는다. 그걸 authorized_keys에 저장된 공개 키로 복호화 한다.
복호화 된 결과가 전송했던 random key와 같다면 ssh client는 authorized_keys를 만든 사람이라는 걸 확신할 수 있으므로 로그인을 해 주는 것이다.
이 방식이 직접 비밀번호를 입력하는 것 보다 안전하다.
이 과정에서 암호화 복호화를 비대칭성이라는 특성을 가진 RSA가 이렇게 동작한다.
연속적으로 명령 실행시키기 (;과 &와 &&의 차이)
;- 앞의 명령어가 실패해도 다음 명령어가 실행&&- 앞의 명령어가 성공했을 때 다음 명령어가 실행&- 앞의 명령어를 백그라운드로 돌리고 동시에 뒤의 명령어를 실행
echo $? : 이전 명령어가 반환한 값을 알아내는 명령어. 결과는 0, 에러가 나면 1, 존재하지 않는 명령어는 127이 나타난다.
리눅스에서 0이 아닌 값은 실패(false)를 의미한다.
명령의 그룹핑 {}
mkdir test3 && { cd test3; touch abc; echo 'success!!' } || echo 'There is no dir';
mkdir test3가 성공했을 때cd test2; touch abc를 실행하고success!!를 출력한다.- 실패했을 때
echo 'There is no dir'를 실행한다. - 이때 실행되는 명령들은 현재 쉘의 컨텍스트에서 실행된다. 만약 서브 컨텍스트에서 실행하고 싶다면 '('와 ')'를 사용하면 된다.
