개요
힙(Heap)
힙이란 이진트리의 한 종류인데, 루트노드가 언제나 최대값 또는 최솟값을 가지는 완전이진트리를 뜻한다.
트리
그렇다면 이진트리는 무엇일까? 우선 트리는 다음과 같이 정의할 수 있다.
트리:
정점(Node)과 간선(Edge)를 이용하여 데이트의 배치형태를 추상화한 추상자료구조위의 그림에서 볼 수 있듯, 데이터를 담고있는 개체(Node)가 선(Edge)으로 이어진 형태를 취한다.
이는 나무를 뒤집어 놓은 형태이기 때문에 트리라고 불리우며, 뿌리가 되는 하나의 루트노드(Root Node)에서 잎파리 부분(Leaf Node)까지 발전해 내려가는 형태이다. 트리는 다음과 같은 요소를 갖는다.
- 루트 노드: 가장 위에 위치한 트리 자료구조의 뿌리가 되는 노드
- 잎 노드: 가장 아래에 위치한 가장 깊은 깊이의 노드
- 부모 노드와 자식 노드: 간선으로 이어진 두 노드가 있다면, 루트 노드에 가까운 쪽의 노드를 부모 노드라고 하며, 잎 노드에 가까운 쪽의 노드를 자식 노드 라고 한다. 위의 예시에서 "A는 B와 C 노드의 부모" 라고 할 수 있다. 루트 노드를 제외한 모든 노드는 오직 1개의 부모 노드만 가질 수 있다.
- 높이(또는 깊이 *Depth, 레밸 *Level) : 트리가 몇 단계의 구조로 구성되어있는지를 표현하는 요소로, 루트노드를 0으로 하여 하나의 간선으로 자식노드와 이어질 때 마다 1의 값을 추가하게 된다. 위의 예시 트리의 높이는 3이다.
- 서브 트리: 트리의 구조를 살펴보면 트리 안에 트리가 있는 구조를 발견할 수 있다. 위의 예시 트리에서는 A를 루트 노드로 하는 트리 안에, B를 루트 노드로 하는 트리, C를 루트 노드로 하는 트리, E를 루트 노드로 하는 개별 트리를 발견할 수 있다. 이러한 메인 트리 안의 또 다른 트리들을 "서브 트리"라고 부른다.
- 차수(Degree): 자식 노드의 갯수를 뜻한다. 위의 예시 트리에서 루트 노드 A의 차수는 2이다. B와 C 두개의 자식 노드를 가지고있기 때문이다.
이진트리 (Binary Tree)
위에서 힙(Heap)은 이진트리의 한 종류라고 했다. 트리에 대해서는 살펴보았는데, 그럼 이진트리는 어떤 것일까? 이진트리는 모든 노드의 차수(Degree)가 2 이하인 트리를 뜻한다. 위의 트리 예시를 살펴보면, 모든 노드들은 2개 이하의 자식 노드를 가지고 있다. (즉 모든 노드의 차수가 2 이하이다)
다시 힙의 개념으로 돌아가보면 힙은 이진트리 중에서도 "완전이진트리"라고 하였다. 이진트리의 차수(Degree) 구성에 따른 종류에 대해 살펴보도록 하자.
포화 이진트리
포화 이진트리는 모든 높이에서 노드들이 다 채워져있는 이진트리를 뜻한다. 즉, 높이가 h 인 이진트리가 포화 이진트리가 되려면, 높이 h-1 까지의 노드들이 모두 2의 차수를 가져야 하는 것이다.
완전 이진트리
포화 이진트리의 조건보다는 덜 엄격한 조건을 갖추고있다. 높이가 h라면, h-2의 높이까지의 노드들이 2개의 자식을 가져야하는 h-1 까지는 포화 이진트리의 조건을 만족하며, 높이 h의 노드들이 왼쪽에서부터 채워진 이진트리를 뜻한다.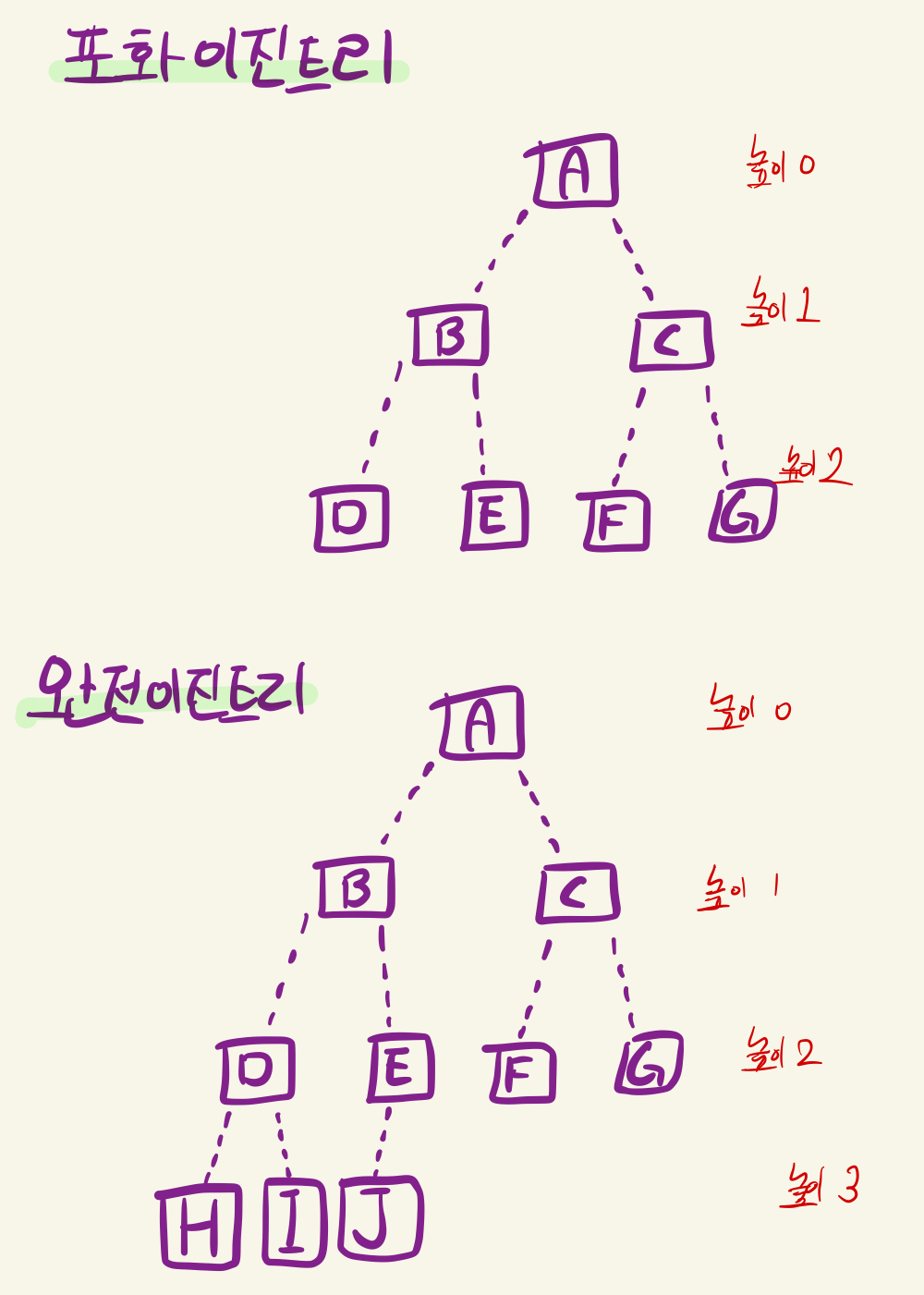
힙(Heap) 상세 설명
예시
힙을 이해하기 위한 모든 개념들에 대해 설명이 끝났다. 힙은 아래의 조건을 만족해야 한다.
- 잎 노드(Leaf Node)를 제외한 모든 노드들은 2의 차수를 가져야 한다.
- 잎 노드(Leaf Node)는 왼쪽에서부터 채워져야 한다 (=완전 이진트리여야 한다.)
- 루트 노드의 값이 항상 2개의 자식 노드 보다 크거나(최대 힙) // 작아야(최소 힙)한다.
그렇다면 힙은 정확히 어떤 모습일까?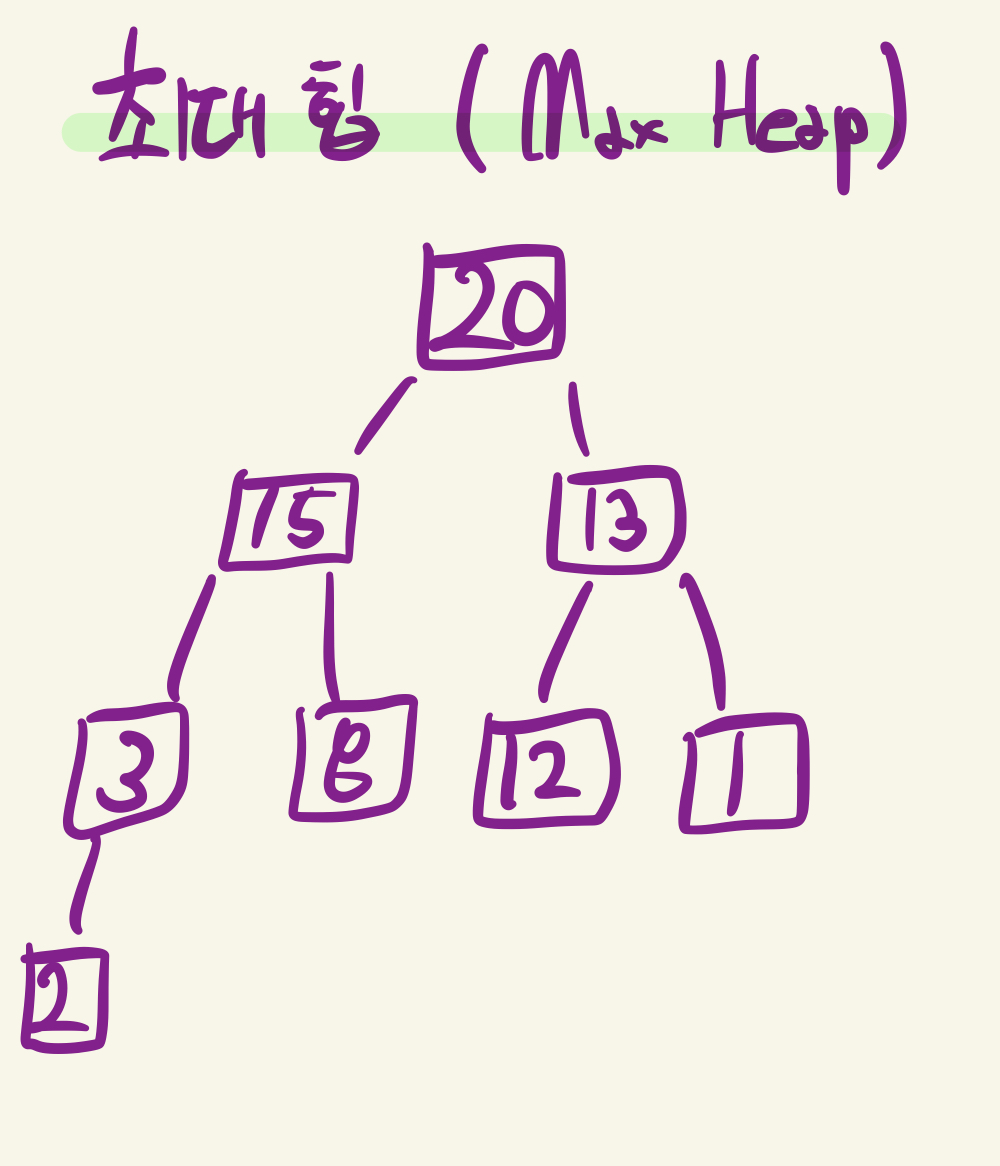
그림의 트리는 "완전 이진트리"의 구조를 따른다. 또한 모든 부모 노드는 2개의 자식 노드 각각 보다 더 큰 값을 갖고있다. 20의 값을 가진 루트 노드의 2개의 자식 노드들은 20보다 작은 15와 13의 값을 갖고 있는 것을 확인할 수 있다.
파이썬 코드로의 힙 구현
리스트를 활용한 힙 구현
파이썬의 Built-in 자료구조인 list를 활용해 이러한 힙을 쉽게 구현해볼 수 있다. 힙은 "완전 이진트리"의 구조를 따르기 때문에, 루트 노드 부터 시작하여 각 노드에 빠짐없이 인덱스 번호를 붙일 수 있다. 그리고 쉽게 자식노드와 부모노드의 인덱스 값을 찾을 수 있다. 아래의 예시를 확인해보자.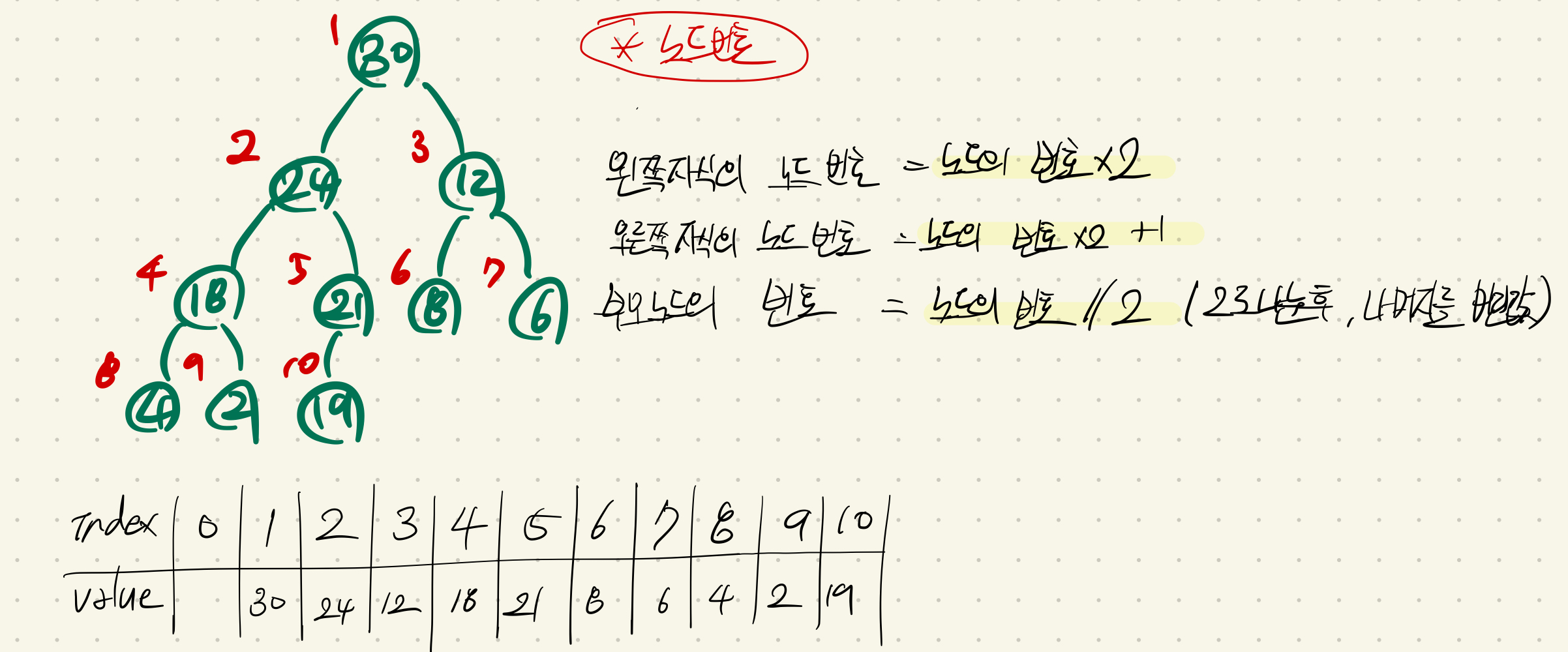
힙을 배열 형태로 구현할때 0번 인덱스는 비워놓아야 한다. 0번 인덱스부터 값이 차있을 특정 노드의 인덱스로 해당 노드의 자식/부모 노드를 찾는 계산이 불가능해지기 때문이다.
힙 자료구조의 메서드들
일반적으로 힙은 다음의 2가지 메서드를 제공하게 된다.
1) 값 추가 insert(item) : 추가한 값이 "힙" 구조를 해치지 않게 적절한 위치를 찾아가도록 구현해야함
2) 값 빼오기 remove() : 무조건 가장 큰 값을 가질 수 밖에 없는 "루트 노드"를 빼오는 기능만 수행하며, 루트 노드를 빼오기 때문에 자식 노드를 땡겨와 "힙"의 구조를 재조정 해야함
힙(Heap) 구현 (최대 힙)
insert 메서드
최대힙에 원소를 추가하는 메서드를 구현하기 위해서 아래의 절차를 유념해야한다.
1. 트리 마지막 자리에 추가하려는 값을 임시로 저장 (이때의 값은 부모 노드보다 클수도 있다.)
2. 부모 노드와 비교해서 클 경우 부모 노드와 자리 교체
코드로 구현하면 다음과 같다.
class MaxHeap:
def __init__(self):
self.data = [None]
def insert(self, item):
self.data.append(item) # 임시로 삽입
i = len(self.data) - 1 # 임시로 넣은 놈의 인덱스 구해서
while i != 1: # 임시로 넣은 놈을 1번 인덱스까지 비교
parent_i = i//2 # 임시로 넣은 놈의 부모 노드 인덱스 구하고
if self.data[parent_i] < self.data[i]: # 임시로 넣은 놈이 부모 보다 클 경우 > 값 변경해야함
self.data[parent_i], self.data[i] = self.data[i], self.data[parent_i]
i = parent_i
else:
break부모노드와의 대소 비교 최대 횟수는 logN이다.
따라서 힙에서의 원소 추가 연산에 대한 Big O Notation은 O(logN)이라고 할 수 있다.
remove 메서드
* 힙에서의 원소 삭제는 최대값(루트노드)를 꺼내는 pop의 개념이다.
최대힙에서 원소를 삭제하는 메서드를 구현하기 위해서 아래의 내용을 유념하자.
- 최대값은 항상 "루트 노드"에 있다.
- 루트 노드가 비어있는 트리는 정상적인 트리가 아니기 때문에 삭제 후 이를 재조정해야한다.
루트노드를 삭제한 트리의 구조 재조정은 아래의 절차로 진행할 수 있다.
-
트리의 마지막 노드를 빈 루트노드의 자리에 배치 (최대값인 루트노드를 이미 꺼냈기 때문에 이 때 루트노드는 비어있고, 그 빈 루트노드에 가장 마지막 노드를 넣는 것)
-
루트 노드에 임시로 배정된 마지막 노드와, 루트 노드의 2개 자식노드 값을 비교해서 구조를 재조정한다.
- 이때 자식노드가 없을 수도 (총 노드가 2개 뿐인 힙)
- 자식이 1개일수도,
- 자식이 2개일수도 있다.
따라서 자식노드(들)의 값과 임시로 배정된 값이 들어간 루트노드의 값을 비교해서 구조를 재조정 해야한다. 아래의 그림을 참고하자.
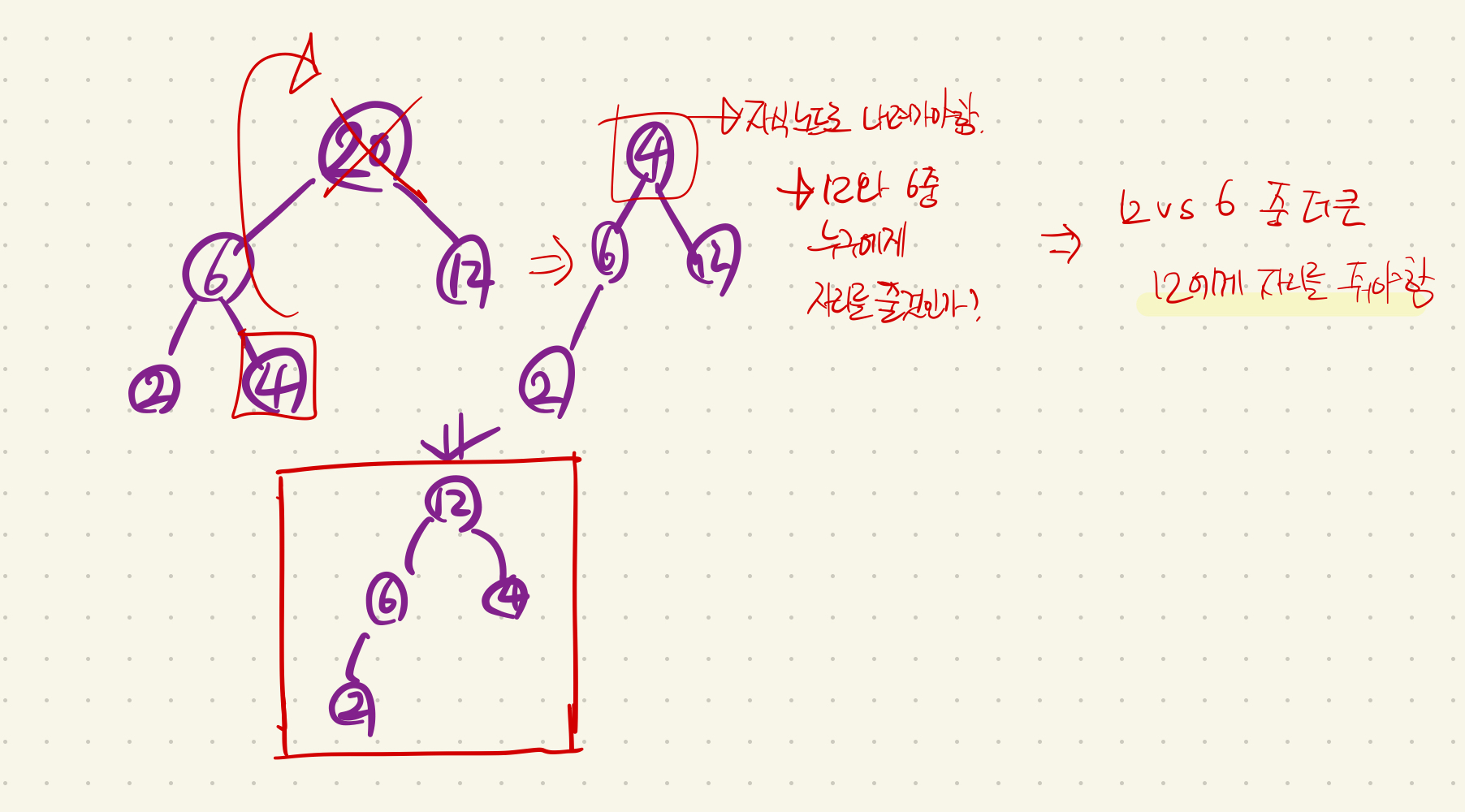
구조를 재조정하는 과정이 복잡하기 때문에, 별도의 함수로 빼서 구현하였다.
자세한 내용은 코드 내 주석에 적어놓았다.
class MaxHeap:
def __init__(self):
self.data = [None]
def remove(self):
if len(self.data) > 1:
self.data[1], self.data[-1] = self.data[-1], self.data[1] # 맨 마지막 노드와, 루트 노드 위치 교환
data = self.data.pop(-1) # 맨 마지막 노드 삭제 후 반환
self.max_heapify(i=1) # 1번 인덱스부터 구조 적합도를 확인해 내려가는 힙 구조 재조정 함수 실행
else:
data = None
return data
def max_heapify(self, i):
left = i * 2 # 루트 노드의 왼쪽 자식
right = i * 2 + 1 # 루트 노드의 오른쪽 자식
biggest = i # 특정 범위 서브 트리의 최대값을 담을 변수
# 왼쪽 자식 노드가 있으며, 그 자식 노드가 현 서브 트리의 루트 노드보다 클 때
if len(self.data)-1 >= left and self.data[left] > self.data[biggest]:
# 그 서브 트리의 최대값을 "루트 노드" -> "왼쪽 자식 노드" 로 변경한다.
biggest = left
# 그 후, 오른쪽 노드도 같은 방식으로 확인하며, 오른쪽 노드가 왼쪽 노드보다 클 때,
if len(self.data)-1 >= right and self.data[right] > self.data[left]:
# 그 서브 트리의 최대값을 "루트노드(바로 위의 if절을 안탔을경우)"나, "왼쪽 자식 노드(바로 위의 if절을 탔을경우)"가 아닌
# -> "오른쪽 자식 노드" 로 변경한다.
biggest = right
# 가장 큰 값(biggest)이 루트노드(i)의 위치에 올 때 까지 이 함수를 재귀적으로 호출한다.
if biggest != i:
self.data[biggest], self.data[i] = self.data[i], self.data[biggest]
self.max_heapify(biggest)위와 같은 힙의 원소 삭제 연산은, 삭제 후 재조정을 위해 2개의 자식 노드를 비교하여야 하기 때문에 2*logN의 시간이 소요된다.
이를 Big O Notation으로 표현하면 다음과 같다. O(logN)
쉽게 구현하는 방법
꽤나 복잡해보이는 위의 추상 자료 구조를 파이썬에서는 이미 자체적으로 구현해두었다.
https://docs.python.org/ko/3/library/heapq.html
사실은 위에서 소개한 내장 모듈을 통해 heap 자료구조를 쉽게 import해서 사용할 수 있다.
힙(Heap)의 활용
우선순위 큐 에서의 활용
원소를 넣을 때, 값이 가장 큰 원소를 가장 앞에 배치하고,
원소를 뺄 때, 값이 가장 큰 원소를 꺼내온다는 특성상
힙은 우선순위 큐를 구현하기 가장 적합한 자료 구조이다.
힙을 이용한 우선순위 큐 연산은 아래와 같은 시간 복잡도를 갖는다.
| 연산 | 시간복잡도 | 설명 |
|---|---|---|
| insert | O(logN) | 정렬에 맞게 최대값을 루트 노드에 넣어야 한다. |
| remove | O(logN) | 루트 노드를 삭제한 후 트리 구조를 재조정해야한다. |
정렬에서의 활용
값을 꺼내고 뺄 때 항상 루트 노드에 최대값(혹은 최소값)이 위치하는 특성을 활용하여 정렬에 사용할 수 있다.
1. 정렬되지 않은 원소들을 최대 힙에 삽입: O(logN)
2. 삽입이 끝나면 힙이 빌 때까지 하나씩 꺼내서 리스트에 담음: O(logN)
3. 꺼낸 순서대로 정렬되어 있다.
이 경우 시간 복잡도는 다음과 같다. O(logN)
