
🌞selenium이란 ?
• 사용하는 이유
1. 자바스크립트가 동적으로 만든 데이터를 크롤링 하기 위해 ( beautifulsoup은 불가! )
2. 사이트의 다양한 HTML 요소에 클릭, 키보드 입력 등 이벤트를 주기 위해
3. 자동화
자동로그인 / 자동 메일보내기 / 브로그 이웃새글 자동 좋아요 누르기 / 인스타그램 자동으로 좋아요, 댓글 작성하기 등 등
.
.
.
.
🛻 selenium 설치
!pip install seleniumfrom selenium import webdriver
from selenium.webdriver.common.by import By # By.XPATH쓰기 위해 import 해줘야함.
from selenium.webdriver.common.keys import Keys # Keys.ENTER 쓰기 위해 import 해줘야함.
from selenium.webdriver.support.wait import WebDriverWait # 로딩 시간이 일정시간 넘으면 에러뜨도록 하기..
.
.
.
🛻 selenium으로 네이버 음원차트 가져오기
① chrome 창에 "현재 음원차트" 창 띄우기
driver = webdriver.Chrome()
url = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query=%EC%9D%8C%EC%9B%90%EC%B0%A8%ED%8A%B8&oquery=%EB%84%A4%EC%9D%B4%EB%B2%84+%EC%88%9C%EC%9C%84&tqi=ivSMhlprvTossFYiYWNssssssDV-044770'
driver.get(url)webdriver.Chrome( ) 으로 크롬 웹드라이버 객체를 얻은 후,
get 메소드에 원하는 url 경로를 넣어주면 된다.
( 네이버 음원차트 페이지 경로를 넣어주겠다.)
그러면 자동으로 Chrome 창이 뜬다. Chrome 창 상단에 "Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다." 라고 뜨는 것이, 셀레니움에 의해 띄어졌다는 것을 의미한다.
② 현재 음원차트 순위 목록
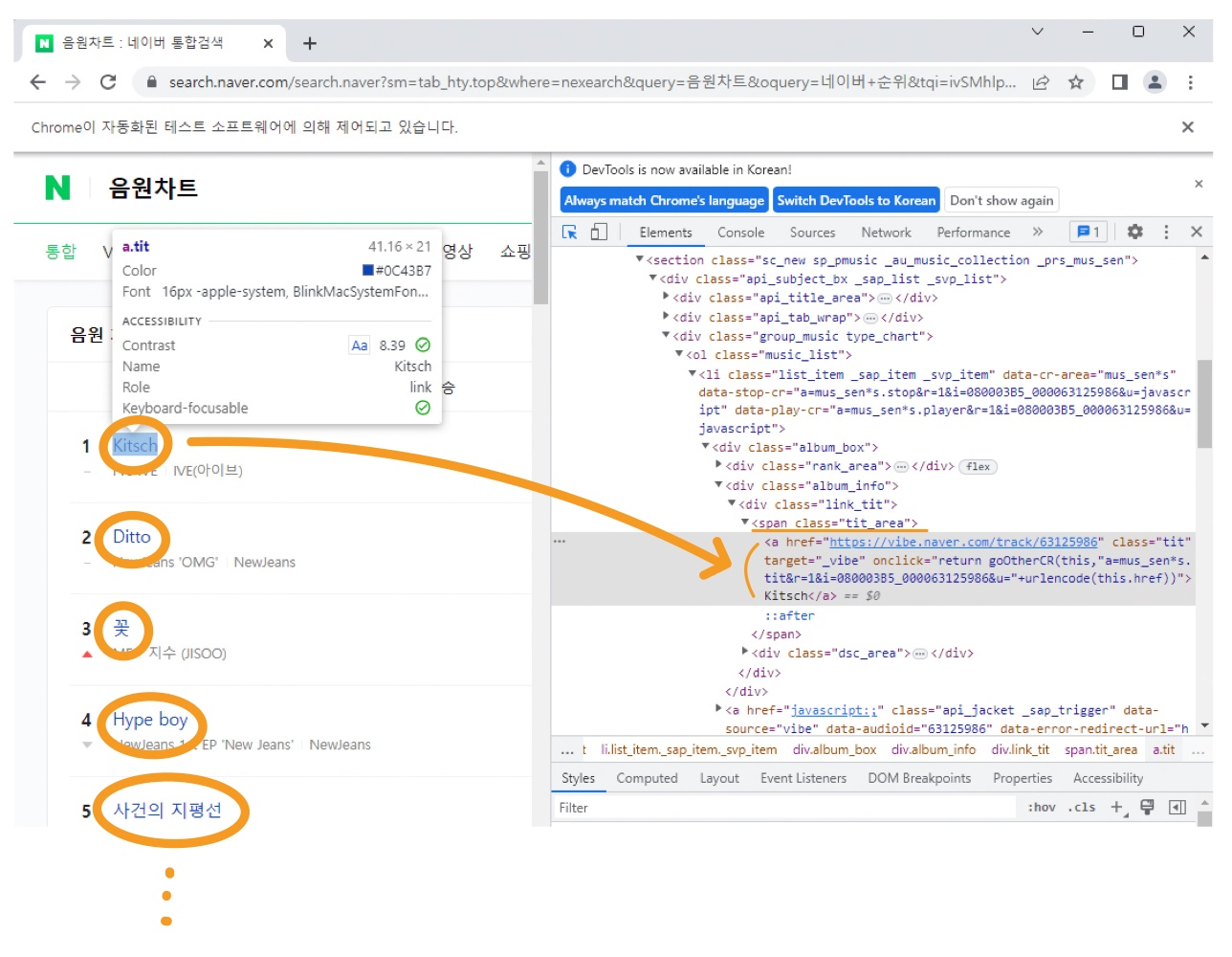
r = driver.find_elements(By.XPATH,'//span[@class = "tit_area"]/a')
for i in r :
print(i.text)
③ 가수 목록
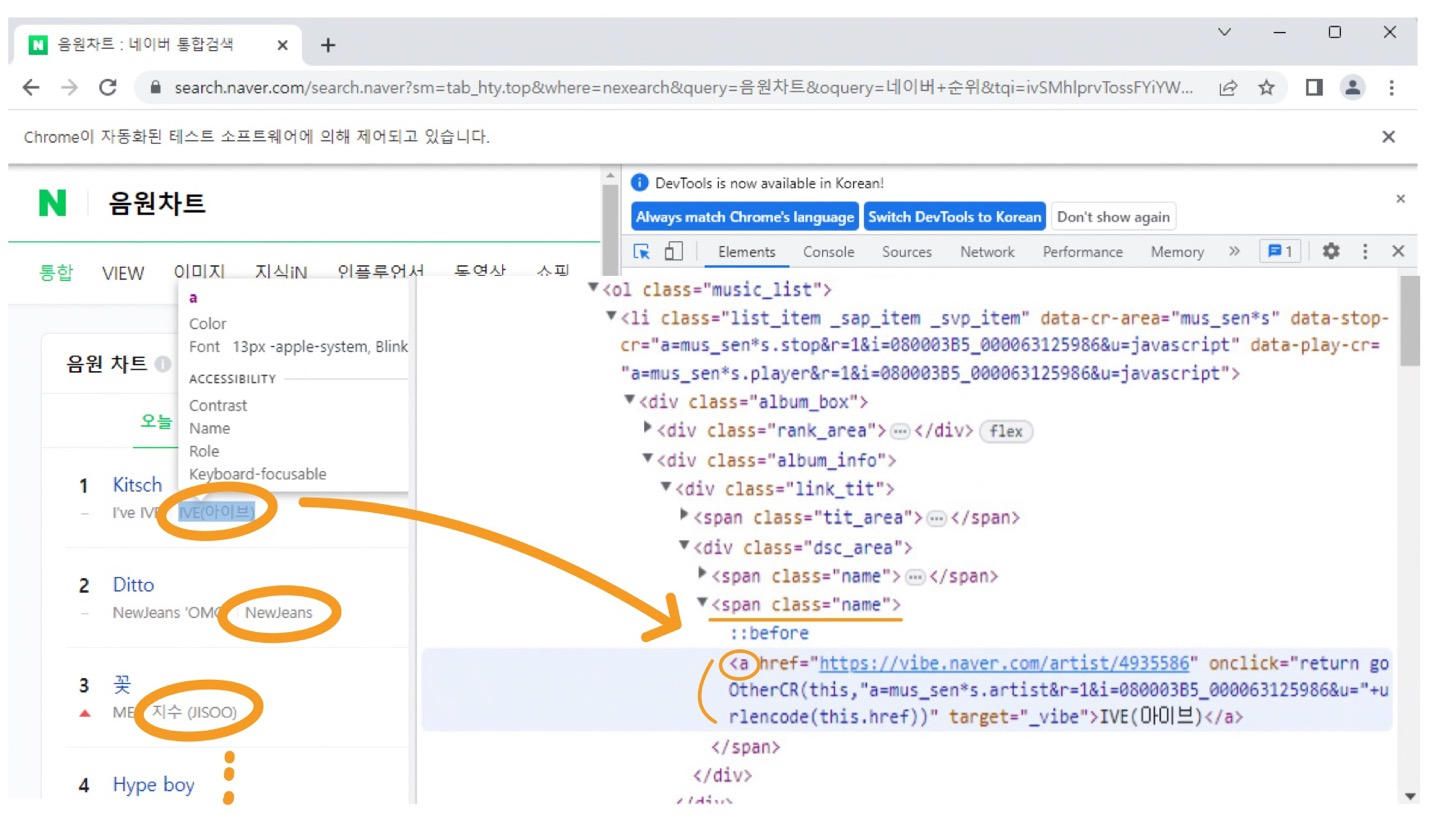
r = driver.find_elements(By.XPATH,'//span[@class="name"]/a')
singer_list = []
for i in r:
singer_list.append(i.text)
singer_list = singer_list[1::2]
print(singer_list)
④ Chrome 창 닫기
driver.quit().
.
.
.
🛻 selenium 으로 네이버 검색창에 키 입력하기
- 키 입력 : send_keys
- ENTER : Keys.ENTER / .click( )
.
.
.
.
① Chrome창에 "날씨" 입력 + ENTER키 누르기
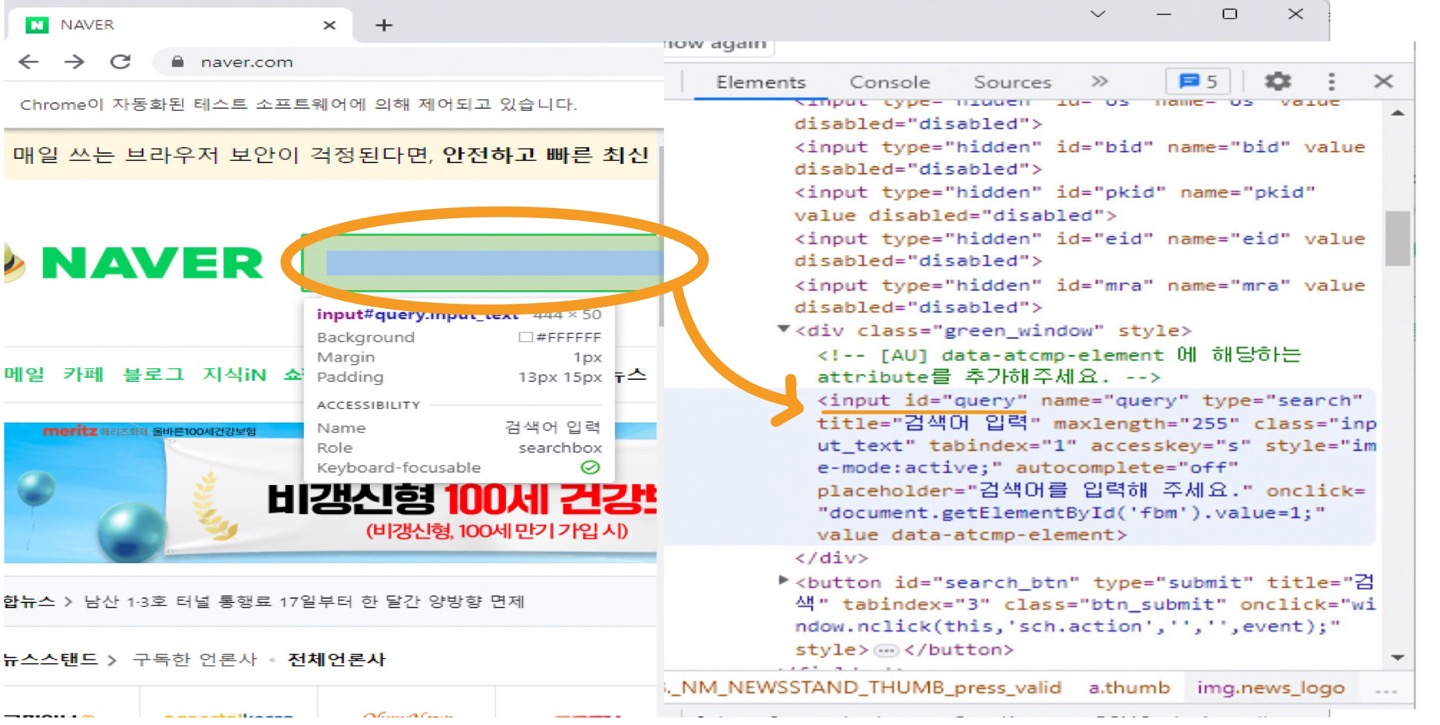
driver = webdriver.Chrome()
driver.get('http://www.naver.com')
search_box = driver.find_elements(By.XPATH,'//input[@id="query"]')
len(search_box) # 1
search_box[0].send_keys("날씨"+Keys.ENTER) selenium으로 크롬 네이버 창을 띄운 뒤,
검색창(search_box)의 태그를 잡아,
send_keys("검색하려는 것" + Keys.ENTER) 로 엔터키를 입력해준다.
② '날씨 더보기' 클릭
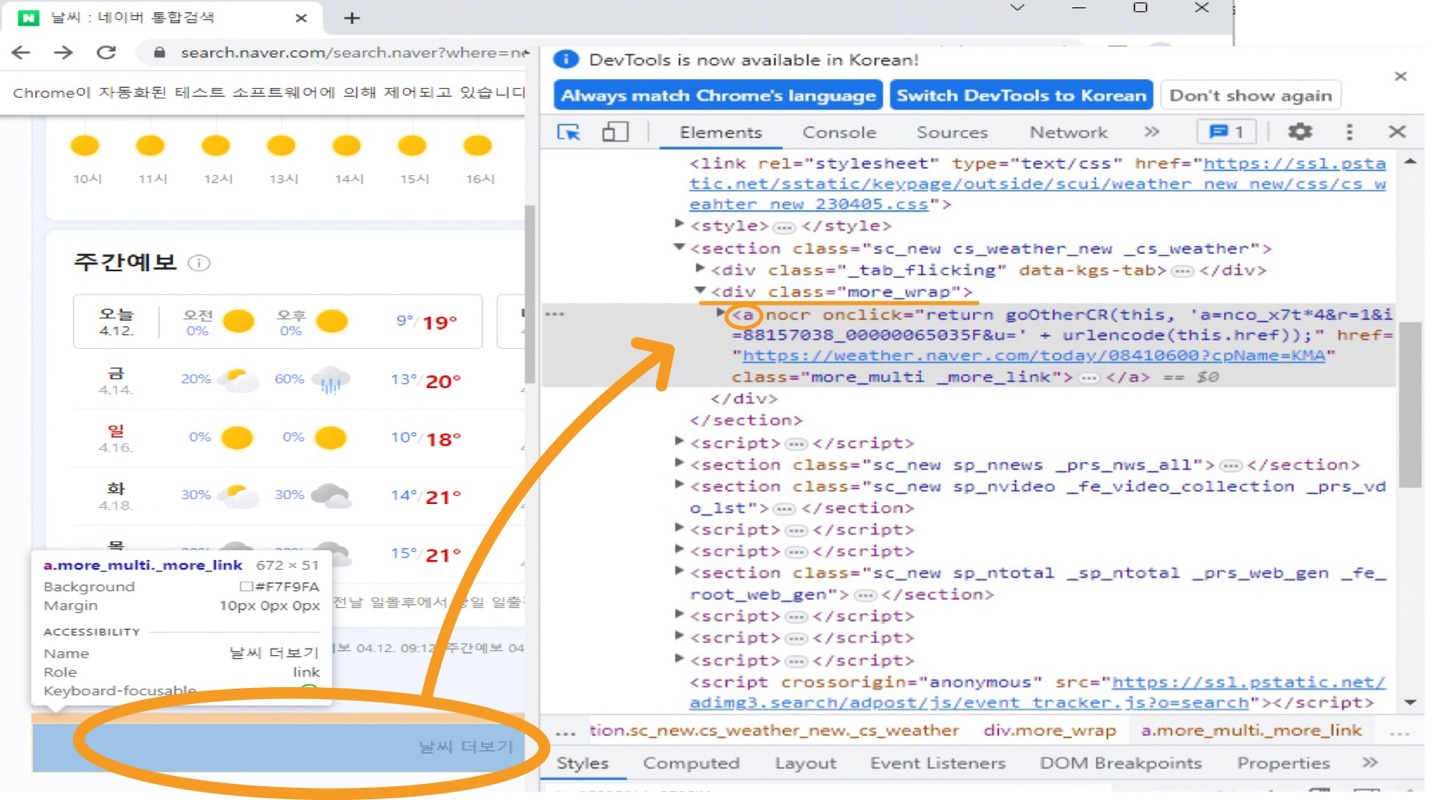
more = driver.find_elements(By.XPATH,'//div[@class="more_wrap"]/a')
len(more) # 1
more[0].click().click( ) 이라는 메소드를 사용해도 Keys.ENTER와 동일하게 클릭이 된다.
③ 일주일 최고기온 가져오기
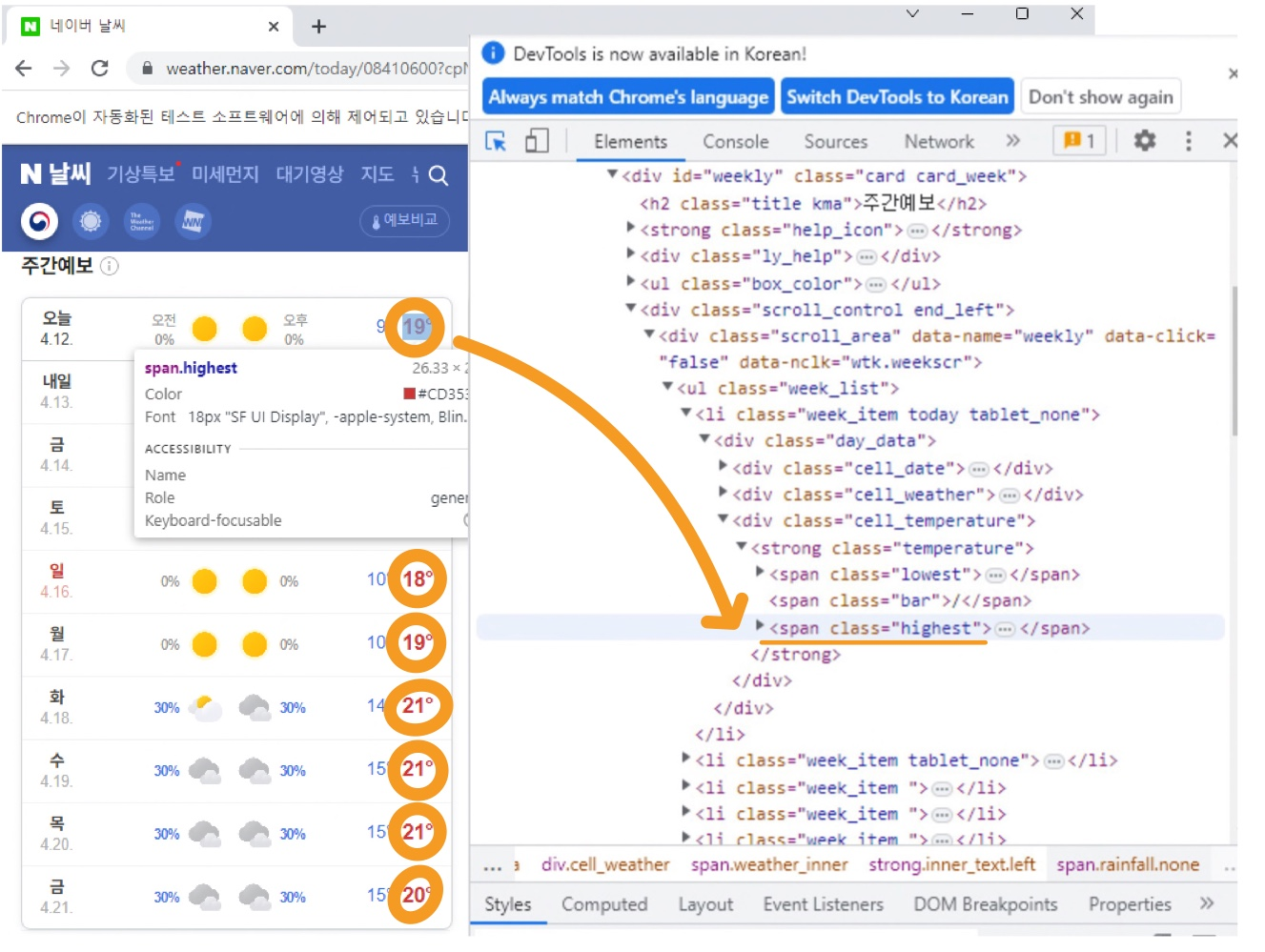
weather_week = driver.find_elements(By.XPATH,'//span[@class="highest"]')
for i in weather_week :
print(i.text)- 결과

왜 최고기온이 뜨나 봤더니, 저 태그에 온도만 잡혀있는 줄 알았는데 '최고기온'도 같이 다 적혀있다.
list 에 담아서 홀수만 출력하도록 하면 온도만 가져올 수 있을 것 같다.
.
.
.
.
🛻 iframe
🌞 iframe 이란 ?
광고와 같이 다른 소스의 콘텐츠를 웹 페이지에 삽입할 때 자주 사용되는 것으로,
다른 웹페이지 또는 다른 HTML 문서에 포함된 HTML문서에 삽입된 웹 페이지이다.
🌞 iframe 전환
driver.switch_to.frame( )
.
.
.
처음에는 네이버에서 쿠팡쇼핑을 클릭하려고 했다.
driver = webdriver.Chrome()
driver.get('http://www.naver.com')
mall_links = driver.find_elements(By.XPATH, '//div[@class="mall_area"]//strong[contains(text(),"쿠팡")]')
len(mall_links) # 0하지만 아무리 자세하게 쿠팡 태크를 잡으려 해보았지만, len 함수를 쓰면 나오는 건 0 ,,,
봤더니, 쿠팡태그가 iframe 안에 들어가 있었다.
따라서 iframe으로 전환하여 쿠팡 태그를 잡겠다.
사용되는 코드는 "driver.switch_to.frame"
shopping_iframes = driver.find_elements(By.XPATH,'//iframe[@id="shopcast_iframe"]')
print(shopping_iframes)
무슨 말인지 모르겠지만, iframe 태그를 잡고 print 하면 요렇게 나온다 !
driver.switch_to.frame(shopping_iframes[0])이 코드를 실행시키면, 이제 iframe으로 전환되어, iframe 안에서 find_elements를 할 수 있게 된다.
mall_links = driver.find_elements(By.XPATH,'//div[@class="mall_area"]//strong[contains(text(),"쿠팡")]')
len(mall_links) #1 드디어 한 개가 잡혔다. 아마 쿠팡이 맞을 것이다.
클릭해보겠다.
mall_links[0].click()쿠팡 클릭 성공이다.
.
.
.
.
🛻 window_handle
위의 경우 iframe으로 전환하게 되면 탭이 2개가 생긴다. 2개의 탭은 "window_handle"이라는 이름의 list로 관리되어진다.
.
.
window_handles를 print해보면 2개의 탭이 나온다. 1개는 위에서 전환했던 iframe 탭이고, 1개는 원래있었던 탭이다.
print(driver.window_handles)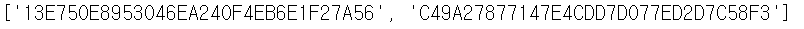
⌨️ 둘 중 무엇이 현재 탭일까 ?
print(driver.current_window_handle)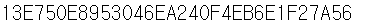
⌨️ 탭 전환
driver.switch_to.window(driver.window_handles[1])
print(driver.current_window_handle)
print(driver.title)⌨️ Chrome 창 닫기
driver.quit( )