
import numpy as np
import pandas as pd
import matplotlib as plt
from scipy import statsfile_name = '산업_규모별_임금_및_근로시간_20230315211235.csv'
np_data = pd.read_csv(file_name, encoding = 'cp949', header = None).to_numpy()
print(np_data[:10])
# [['규모별' '항목' '시점' 'C.제조업(10~34)' 'F.건설업(41~42)' 'G.도매 및 소매업(45~47)''J.정보통신업(58~63)' 'K.금융 및 보험업(64~66)']
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.01 168.3 136.6 160.2 159.2 157.8]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.02 169.8 132.0 159.9 160.3 158.4]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.03 185.0 144.3 170.8 174.6 173.2]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.04 169.9 136.1 159.2 159.1 157.7]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.05 157.4 130.3 154.6 150.6 149.3]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.06 177.7 143.3 171.3 174.2 172.5]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.07 184.2 145.5 177.3 179.3 178.7]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.08 160.3 132.6 158.2 156.9 153.9]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.09 176.4 137.5 166.0 165.3 164.0]
# ['전규모(1인이상)' '전체근로시간 (시간)' 2020.1 163.4 127.8 152.7 150.1 148.6]]🛻 각 업종별 근로시간 평균 비교 : t-test(정보통신과 금융보험), shapiro, levene 실행
np_data1 = np_data[1:, 2:].astype(np.float64)
print(np_data1[:5])
# [[2020.01 168.3 136.6 160.2 159.2 157.8 ]
# [2020.02 169.8 132. 159.9 160.3 158.4 ]
# [2020.03 185. 144.3 170.8 174.6 173.2 ]
# [2020.04 169.9 136.1 159.2 159.1 157.7 ]
# [2020.05 157.4 130.3 154.6 150.6 149.3 ]]
# 시점, 제조업, 건설업, 도매 및 소매업, 정보통신업, 금융 및 보험업- 각 업종별 평균
np.mean(np_data1[:, 1:], axis=0)
# array([172.43333333, 135.70555556, 163.30833333, 163.45277778, 161.28611111])⌨️ 정보통신업 vs 금융보험업 평균 차이 검정
- t-test
– 귀무가설 : 두 그룹의 평균은 차이가 없다.
stats.ttest_ind(np_data1[:,4], np_data[:,5])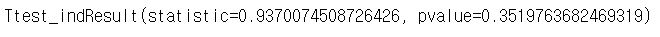
» p-value = 0.351 > 0.05 이므로 "귀무가설 채택"
즉, 두 그룹간 평균은 차이가 없다 고 볼 수 있다.
- shapiro
– 귀무가설 : 두 그룹의 샘플의 모집단은 정규분포를 따른다.
for i in range(1,6) :
print(stats.shapiro(np_data1[:,i])) » 다섯개 그룹을 모두 shapiro test 를 하니, 모두 p-value > 0.05 이므로 "귀무가설 채택" 이다.
» 다섯개 그룹을 모두 shapiro test 를 하니, 모두 p-value > 0.05 이므로 "귀무가설 채택" 이다.
» 즉, 모든 그룹의 샘플의 모집단은 정규분포를 따른다고 가정할 수 있다.
- levene
– 귀무가설 : 두 개 그룹의 분산은 같다.
stats.levene(np_data1[:, 4], np_data1[:, 5])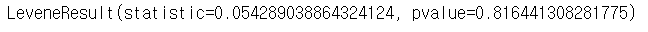 » p-value = 0.8360 > 0.05 이므로 "귀무가설 채택" 이다.
» p-value = 0.8360 > 0.05 이므로 "귀무가설 채택" 이다.
.
.
.
🛻 2022년 정보통신업과 제조업의 평균차이 검정
1. 2022년도 데이터 추출
filter = np_data1[:,0] >= 2022
np_data10 = np_data1[filter]
np_data10
# array([[2022.01, 169.1 , 135.3 , 159.9 , 160.1 , 156.5 ],
# [2022.02, 151.8 , 118.9 , 145.1 , 143.8 , 140.9 ],
# [2022.03, 174. , 135.6 , 164.4 , 164.6 , 161. ],
# [2022.04, 175.8 , 137.4 , 166.4 , 166.8 , 163.9 ],
# [2022.05, 175. , 136.5 , 165.2 , 166. , 163.3 ],
# [2022.06, 169.9 , 135. , 159.5 , 159.2 , 156.6 ],
# [2022.07, 174.5 , 136.5 , 164.9 , 166.2 , 162.7 ],
# [2022.08, 169.7 , 138.6 , 168.3 , 170.9 , 167.9 ],
# [2022.09, 166. , 131.1 , 157.8 , 158.2 , 156.2 ],
# [2022.1 , 164.1 , 128.7 , 154. , 152.1 , 148.6 ],
# [2022.11, 182.8 , 139. , 171.7 , 173.9 , 171.3 ],
# [2022.12, 180.2 , 139.1 , 170.5 , 169.4 , 169. ]])2. t-test
stats.ttest_ind(np_data10[:,1], np_data10[:,4])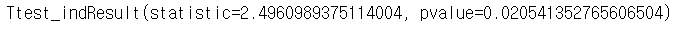 » p-value = 0.0205 < 0.05 이므로 "귀무가설 기각" 이다.
» p-value = 0.0205 < 0.05 이므로 "귀무가설 기각" 이다.
» 즉, 두 정보통신업과 제조업의 평균은 차이가 있다 고 볼 수 있다.
3. shapiro
위에서 진행한 결과, 모든 집단의 샘플의 모집단은 정규분포라고 가정할 수 있다.
3. levene
stats.levene(np_data10[:,1], np_data10[:,4])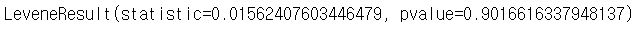 » p-value = 0.90166 < 0.05 이므로 "귀무가설 채택" 이다.
» p-value = 0.90166 < 0.05 이므로 "귀무가설 채택" 이다.
즉, 두 집단의 분산은 동일하다고 볼 수 있다.

데이터 분석 / 데이터 사이언티스트 / AI 딥러닝