
‣ 데이터 : 월별 도시별 대기오염도
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
import statsmodels.api as smfile_name = '미세먼지_PM10__월별_도시별_대기오염도_20230322214120.csv'
np_data = pd.read_csv(file_name, encoding = 'cp949').to_numpy()
print(np_data[:5])
# result
# [['시점' '서울특별시' '부산광역시' '대전광역시' '제주특별자치도']
# ['2011.01' '44' '38' '39' '29']
# ['2011.02' '75' '57' '63' '52']
# ['2011.03' '65' '58' '59' '48']
# ['2011.04' '56' '56' '52' '50']]🛻 검정 내용
1. 2021년 시도별 평균 미세먼지 농도에 차이가 있는가 ?
2. 2011 ~ 2021년 봄 (3,4,5월) 과 겨울 (10,11,12월) 의 평균 미세먼지 농도에 차이가 있는가 ?
1. 2021년 시도별 평균 미세먼지 농도에 차이가 있는가 ?
‣ ( 귀무가설 ) : 시도별로 평균 미세먼지 농도에는 차이가 없다.
- 2021년도 데이터 추출하기
(오류)
data_2021 = np_data[-12:].astype(np.float64)
print(data_2021)2021년 데이터를 추출하여 float으로 데이터 형태를 바꾸려고 했으나, 오류 ! !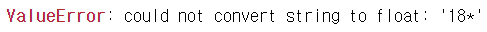
미세먼지 농도 숫자 뒤에 *가 붙어져있어서 float 형태로 데이터변환이 안되는 것.
따라서, 먼저 숫자 뒤에 있는 * 를 뗴주는 작업을 해주겠다.
# 예시 )
test_str_a = '123*'
test_str_b = '123**'
print('*' in test_str_a) # True
print(test_str_b.find('*') # 3
print(test_str_b[ :3]) # 123‖ 첫번째 방법
np_data1 = np_data[1:, 1:]
np_data_flat = np_data1.flatten()flatten 은 말 그대로 '평평하게 해주는 기능'을 한다. 비슷한 기능으로 ravel 과 다르게, flatten은 다른 메모리를 사용하여 처리한다. 즉, 복사본을 만들어 처리한다고 생각하면 쉽다.
for i, value in enumerate(np_data_flat) :
# print(i, value)
if '*' in value :
np_data_flat[i] = value[ :value.find('*')]
# print(np_data_flat)np_data_flat_re = np_data_flat.reshape(132,4)
np_data2 = np_data_flat_re.astype(np.int64)
# print(np_data2)‖ 두번째 방법 ( 다시! )
row_count, col_count = np_data.shape
print(row_count, col_count) # 135 5
for row_index in range(row_count) :
for col_index in range(col_count) :
str_value = np_data[row_index, col_index]
#print(str_value)
if '*' in str_value :
np_data[row_index, col_index] = str_value[:str_value.find('*')]
#print(np_data)
np_data = np_data[1:,1:].astype(np.int64)# 21년도 데이터 추출
data_2021 = np_data2[-12:, :]
print(data_2021)
# [[38 36 39 34]
# [48 37 42 36]
# [67 60 63 76]
# [42 37 41 37]
# [61 36 56 44]
# [33 26 31 27]
# [24 18 16 17]
# [22 19 18 16]
# [15 17 15 19]
# [27 23 27 24]
# [45 34 38 38]
# [39 31 40 30]] - 시도별 평균 미세먼지농도 구하기
mean_2021 = np.mean(data_2021, axis=0)
print(mean_2021)
# [38.41666667 31.16666667 35.5 33.16666667]
# 서울 부산 대전 제주2021년도 시도별로 평균 미세먼지 농도가 차이가 있는지 ANOVA test 시행.
- ANOVA
lista = [data_2021[:,x] for x in range(4)]
# print(lista)
stats.f_oneway(*lista)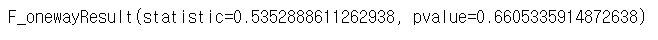 » p-value = 0.6605 > 0.05 : 귀무가설 채택
» p-value = 0.6605 > 0.05 : 귀무가설 채택
» 즉, 시도별로 평균 미세먼지 농도에는 차이가 없다.
2. 2011 - 2021년 봄(3,4,5월) 과 겨울(10,11,12월)의 평균 미세먼지 농도에 차이가 있는가 ?
‣ ( 귀무가설 ) : 봄과 겨울의 평균 미세먼지 농도에는 차이가 없다.
먼저, np_data에서 시점(연/월)을 추출해온 뒤, 월 만 추출한다.
date = np_data[1:, 0]
print(date)
# ['2011.01' '2011.02' '2011.03' '2011.04' '2011.05' '2011.06' '2011.07'
# '2011.08' '2011.09' '2011.10' '2011.11' '2011.12' '2012.01' '2012.02'
# '2012.03' '2012.04' '2012.05' '2012.06' '2012.07' '2012.08' '2012.09'
# '2012.10' '2012.11' '2012.12' '2013.01' '2013.02' '2013.03' '2013.04'
# '2013.05' '2013.06' '2013.07' '2013.08' '2013.09' '2013.10' '2013.11'
# '2013.12' '2014.01' '2014.02' '2014.03' '2014.04' '2014.05' '2014.06'
# '2014.07' '2014.08' '2014.09' '2014.10' '2014.11' '2014.12' '2015.01'
# '2015.02' '2015.03' '2015.04' '2015.05' '2015.06' '2015.07' '2015.08'
# '2015.09' '2015.10' '2015.11' '2015.12' '2016.01' '2016.02' '2016.03'
# '2016.04' '2016.05' '2016.06' '2016.07' '2016.08' '2016.09' '2016.10'
# '2016.11' '2016.12' '2017.01' '2017.02' '2017.03' '2017.04' '2017.05'
# '2017.06' '2017.07' '2017.08' '2017.09' '2017.10' '2017.11' '2017.12'
# '2018.01' '2018.02' '2018.03' '2018.04' '2018.05' '2018.06' '2018.07'
# '2018.08' '2018.09' '2018.10' '2018.11' '2018.12' '2019.01' '2019.02'
# '2019.03' '2019.04' '2019.05' '2019.06' '2019.07' '2019.08' '2019.09'
# '2019.10' '2019.11' '2019.12' '2020.01' '2020.02' '2020.03' '2020.04'
# '2020.05' '2020.06' '2020.07' '2020.08' '2020.09' '2020.10' '2020.11'
# '2020.12' '2021.01' '2021.02' '2021.03' '2021.04' '2021.05' '2021.06'
# '2021.07' '2021.08' '2021.09' '2021.10' '2021.11' '2021.12']
date_float = date.astype(np.float64)
month = (date_float%1.0)*100
print(month)
# [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 1. 2. 3. 4. 5. 6.
# 7. 8. 9. 10. 11. 12. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12.
# 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 1. 2. 3. 4. 5. 6.
# 7. 8. 9. 10. 11. 12. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12.
# 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 1. 2. 3. 4. 5. 6.
# 7. 8. 9. 10. 11. 12. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12.
# 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 1. 2. 3. 4. 5. 6.
# 7. 8. 9. 10. 11. 12.]filter_spring = (month>2) & (month <=5)
filter_winter = (month>9) & (month <=12)
print(filter_spring)
# [False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False
# False False True True True False False False False False False False]
print(filter_winter)
# [False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True
# False False False False False False False False False True True True]np_data2 에 filter_spring 과 filter_winter 을 해준다.
spring_data = np_data2[filter_spring]
winter_data = np_data2[filter_winter]
print(np.mean(spring_data), np.mean(winter_data))
# 52.67424242424242 39.46969696969697stats.ttest_ind(spring_data, winter_data)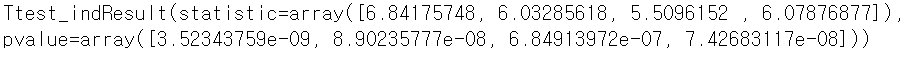 ttest를 해보니, 검정통계량과 검정값이 4개로 나온다.
ttest를 해보니, 검정통계량과 검정값이 4개로 나온다.
위의 과정에서 filter를 씌워서 spring_data 와 winter_data를 만들어줄 때, flatten() 을 해주지 않으면, 열이 4개이기 때문에 4개가 나오는 것이다.
print(spring_data[:5])
# [[65 58 59 48]
# [56 56 52 50]
# [72 76 67 76]
# [46 47 46 45]
# [51 53 49 41]flatten()을 한 후에, ttest를 다시 해보자.
spring_data = np_data2[filter_spring].flatten()
winter_data = np_data2[filter_winter].flatten()
stats.ttest_ind(spring_data, winter_data)
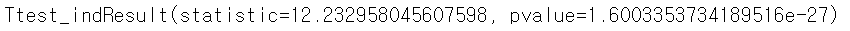 p-value < 0.05 이므로, 귀무가설 기각.
p-value < 0.05 이므로, 귀무가설 기각.
즉, 봄과 겨울에는 평균미세먼지농도에 차이가 있다.
