여러 개의 원소를 다루는 자료구조는 List, Array, Map 등 여러가지 종류가 존재한다.
이 컬렉션, 컨테이너, 어그리게이터 등으로 불리는데 각 종류별로 원소를 조작하는데 사용되는 명령이 다르다.
예를들어, ArrayList의 경우 데이터를 삽입하는데 add, 삭제하는데 remove를 사용하고
HashMap은 put과 remove, Array는 index를 이용한다.
Iterator 패턴은 이러한 원소의 조작방식을 통일화하여 사용하는데 그 목적을 두고 있다.
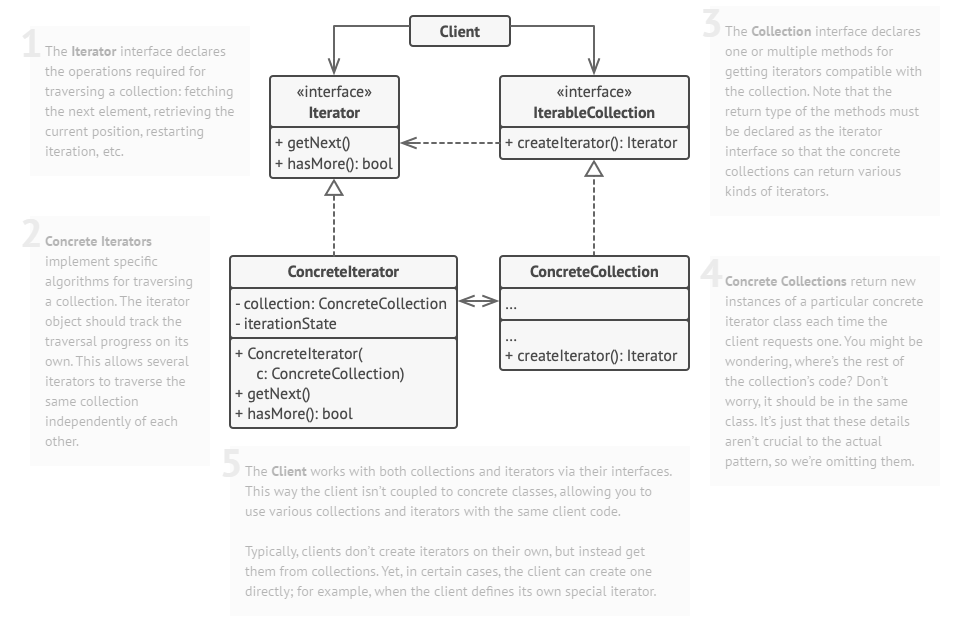
기본 개념은 컬렉션에 해당하는 Iterator 구현체를 사용하는 방식을 띈다.
Iterator 구현체에서 해당 컬렉션에 해당하는 메서드 구현을 getNext와 hasMore에 작성하는 방식이다.
컬렉션마다 원소를 조작하는 방법이 다르기때문에 각자의 Iterator 구현체에 적절한 방식의 구현을 작성한다.
예를들어, 트리구조의 경우 순회방법으로 DFS나 BFS를 사용할 수 있기 때문에 각각 DFS Iterator, BFS Iterator 를 작성하는 것이다.
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}실제 구현은 Iterable<E> 라는 상위 인터페이스를 상속함으로써 해당 패턴을 적용할 수 있다.
해당 인터페이스는 두 개의 default 메서드와 하나의 추상 메서드로 구성되어 있으며, 추상메서드의 반환타입인 Iterator를 상속하는 구현체를 생성하고 반환하면 된다.
이렇게 인터페이스로 따로 분리하여 관리함으로써 단일 책임 원칙을 준수할 수 있고,
손쉽게 확장할 수 있으면서 컬렉션에 대한 수정은 불가하므로 개방 폐쇄 원칙을 준수할 수 있다.
