쿼리 메서드
Spring Data JPA에서는 메서드 명칭에서 쿼리를 도출해내거나, 수동으로 작성한 쿼리를 사용한다.
이 중에서 메서드 명칭은 주어와 술어로 구분된다.
주어는 find..By, exists..By 와 같이 최종적으로 해낼 작업을 명시하며,
술어는 IsStartingWith, StartingWith, StartsWith 처럼 조건에 해당되는 내용이 작성된다.
쿼리 메서드에는 술어의 조건에 해당하는 인수를 작성하게 되는데,
이 인수는 문자열이나 패턴일 수 있으며 LIKE연산에서 와일드카드로 인식하는 문자가 포함되어있다면 이스케이프 처리되어 문자 그 자체로 인식된다.
메서드 이름에서 쿼리를 도출해내는 것은 조건이 복잡해질수록 메서드 명칭또한 복잡해지는 문제를 야기한다.
Page<Member> findAllByNicknameContainingAndUserTypeIsNot(String nickname, UserType userType, Pageable pageable);이러한 상황에서는 임의로 작성한 쿼리를 적용시켜주는 것이 적절하다.
XML( orm.xml )을 이용하여 쿼리를 직접 작성해주거나, @Query 를 이용하여 쿼리 메서드에 적용될 쿼리를 작성해줄 수 있다.
쿼리 생성
JPA에서 쿼리 메서드에 지원하는 키워드 목록은 아래와 같다.
| 키워드 | 예시 |
|---|---|
Distinct | findDistinctByLastnameAndFirstname |
And | findByLastnameAndFirstname |
Or | findByLastnameOrFirstname |
Is, Equals | findByFirstname, findByFirstnameIs, findByFirstnameEquals |
Between | findByStartDateBetween |
LessThan | findByAgeLessThan |
LessThanEqual | findByAgeLessThanEqual |
GreaterThan | findByAgeGreaterThan |
GreaterThanEqual | findByAgeGreaterThanEqual |
After | findByStartDateAfter |
Before | findByStartDateBefore |
IsNull, Null | findByAge(Is)Null |
IsNotNull, NotNull | findByAge(Is)NotNull |
Like | findByFirstnameLike |
NotLike | findByFirstnameNotLike |
StartingWith | findByFirstnameStartingWith |
EndingWith | findByFirstnameEndingWith |
Containing | findByFirstnameContaining |
OrderBy | findByAgeOrderByLastnameDesc |
Not | findByLastnameNot |
In | findByAgeIn(Collection<Age> ages) |
NotIn | findByAgeNotIn(Collection<Age> ages) |
True | findByActiveTrue() |
False | findByActiveFalse() |
IgnoreCase | findByFirstnameIgnoreCase |
Distinct의 경우, 원하는 대로 결과가 반환되지 않을 수 있음에 주의해야한다.예를들어,
countDistinctByLastname(String lastname)를 작성했다고 가정해보자.
메서드에서 도출되는 쿼리는select count(distinct u.id) from User u where u.lastname = ?1다.이는
lastname이 조건에 맞는 모든 결과의 수를 반환하기 때문에countByLastname(String lastname)메서드와 차이가 없다.
이러한 상황에서는@Query를 이용해 직접 쿼리를 작성하는게 더 효율적일 수 있다.
Entity 클래스에 애노테이션으로 직접 쿼리를 작성할 수도 있다.
@Entity @NamedQuery(name = "User.findByEmailAddress", query = "select u from User u where u.emailAddress = ?1") public class User { }다만, 컴파일 과정에서 추가적인 비용이 발생한다는 점을 인지해야한다.
@Query 사용
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.emailAddress = ?1")
User findByEmailAddress(String emailAddress);
}@NamedQuery가 Entity 클래스에 쿼리를 직접 작성한다면,
@Query는 Repository 인터페이스의 쿼리 메서드에 쿼리를 직접 작성한다.
이는 @NamedQuery나 orm.xml에 작성된 쿼리보다 우선시 되며, 도메인 클래스에서 쿼리정보를 분리할 수 있는 이점이 있다.
QueryRewriter
쿼리가 EntityManager로 전송되기 이전에 일괄적인 쿼리 수정이 필요한 상황이라면 QueryRewriter를 사용할 수 있다.
public interface MyRepository extends JpaRepository<User, Long> {
@Query(value = "select original_user_alias.* from SD_USER original_user_alias",
nativeQuery = true,
queryRewriter = MyQueryRewriter.class)
List<User> findByNativeQuery(String param);
@Query(value = "select original_user_alias from User original_user_alias",
queryRewriter = MyQueryRewriter.class)
List<User> findByNonNativeQuery(String param);
}
@Component
public class MyQueryRewriter implements QueryRewriter {
@Override
public String rewrite(String query, Sort sort) {
return query.replaceAll("original_user_alias", "rewritten_user_alias");
}
}위 코드와 같이 Bean으로 등록된 클래스를 @Query의 queryRewriter 속성으로 전달하여 EntityManager에 쿼리가 전달되기 전에 일괄적인 수정이 가능하다.
public interface MyRepository extends JpaRepository<User, Long>, QueryRewriter {
@Query(value = "select original_user_alias.* from SD_USER original_user_alias",
nativeQuery = true,
queryRewriter = MyRepository.class)
List<User> findByNativeQuery(String param);
@Query(value = "select original_user_alias from User original_user_alias",
queryRewriter = MyRepository.class)
List<User> findByNonNativeQuery(String param);
@Override
default String rewrite(String query, Sort sort) {
return query.replaceAll("original_user_alias", "rewritten_user_alias");
}
}또는 Repository 인터페이스에 직접 재정의를 하는 방식도 존재한다.
Native Query
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT * FROM USERS WHERE EMAIL_ADDRESS = ?1", nativeQuery = true)
User findByEmailAddress(String emailAddress);
}JPQL이 아닌 순수 쿼리를 이용하고 싶다면 nativeQuery 옵션을 설정할 수 있다.
하지만 이는 특정 DB에 종속되는 결과를 낳을 수 있으며, Spring Data JPA에선 nativeQuery에 동적 정렬을 지원하지 않는다는 문제도 있다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT * FROM USERS WHERE LASTNAME = ?1",
countQuery = "SELECT count(*) FROM USERS WHERE LASTNAME = ?1",
nativeQuery = true)
Page<User> findByLastname(String lastname, Pageable pageable);
}동적 정렬과 관련된 문제는 위 코드 방식으로 어느정도 해결이 가능하다.
파라미터 이름 작성
기본적으로 Spring Data JPA는 위치기반의 파라미터 바인딩을 지원한다.
이 방법 대신에 @Param 을 이용하면 파라미터에 해당하는 alias를 부여할 수 있다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.firstname = :firstname or u.lastname = :lastname")
User findByLastnameOrFirstname(@Param("lastname") String lastname,
@Param("firstname") String firstname);
}SpEL 표현식 사용
Spring Data JPA 1.4 이후로는 @Query에 제한된 SpEL 표현식을 지원한다.
entityName를 지원하는데, 이는 select x from #{#entityName} x와 같은 형식으로 사용된다.
이는 Entity 클래스의 @Entity 애노테이션의 name속성에 해당하는 값을 의미한다.
만약
name속성이 없다면 클래스 명칭이 사용된다.
이를 이용하면 쿼리에 실제 Entity 명칭이 작성되지 않으므로, 적용되는 테이블을 유연하게 변경할 수 있다는 장점이 있다.
좀 더 자세한 내용은 문서를 참고하자.
@Modifying
UPDATE나 DELETE 쿼리에서 @Query를 사용한다면 @Modifying를 함께 사용해야한다.
이는 Spring Data JPA에게 DB 상태를 변경하는 작업을 한다는 것을 명시한다.
만약, 이 애노테이션이 설정되지 않았다면 읽기 쿼리로 간주한다.
@Modifying
@Query("update User u set u.firstname = ?1 where u.lastname = ?2")
int setFixedFirstnameFor(String firstname, String lastname);쿼리가 수행되고 난 다음에는 EntityManager에 구식 Entity가 남아있을 수 있는데, 자동으로 영속성 컨텍스트를 비우게 되면 아직 변경사항이 적용되지 않은 데이터까지 함께 삭제될 수 있기 때문이다.
만약, 쿼리 수행이후 자동으로 EntityManager를 비우고 싶다면 @Modifying의 clearAutomatically 속성을 true로 설정하면 된다.
삭제 쿼리
interface UserRepository extends Repository<User, Long> {
void deleteByRoleId(long roleId);
@Modifying
@Query("delete from User u where u.role.id = ?1")
void deleteInBulkByRoleId(long roleId);
}두 쿼리 메서드는 동일한 작업을 수행할 것으로 보이지만 실행방식 측면에서 중요한 차이가 있다. 후자의 경우, 실행 결과에 의해 가져온 User 인스턴스의 라이프사이클 메서드가 실행되지 않는다.
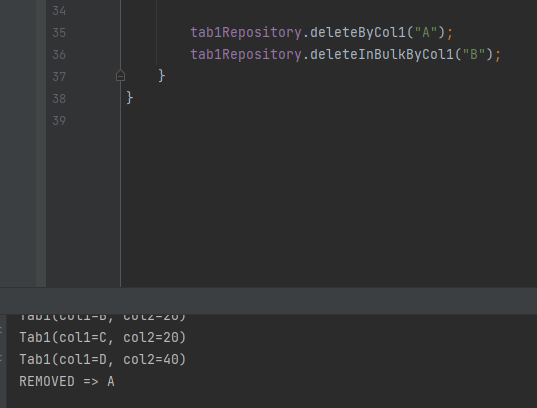
실제로 B를 삭제한 경우, 메시지가 출력되지 않는 것을 확인할 수 있다.
즉, @Query 없이 파생된 삭제 쿼리를 사용하는 경우에는 영속성 컨텍스트와의 동기화를 위해 엔티티를 조회하고 삭제하므로 성능상으로 대량의 데이터 삭제 시 성능에 영향을 줄 수 있다.
정렬
PageRequest나 Sort를 직접 제공함으로써 정렬된 결과를 얻어올 수 있다.
이때, Sort 내의 Order 인스턴스는 도메인 모델과 일치해야한다.
@Query와 Sort를 함께 사용하는 경우에는 복잡한 정렬식을 적용시킬 수도 있다.
기본적으로 Spring Data JPA는 함수호출이 포함된 Sort를 거부하지만, JpaSort.unsafe를 이용하면 함수호출이 포함된 정렬식을 적용할 수도 있다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.lastname like ?1%")
List<User> findByAndSort(String lastname, Sort sort);
@Query("select u.id, LENGTH(u.firstname) as fn_len from User u where u.lastname like ?1%")
List<Object[]> findByAsArrayAndSort(String lastname, Sort sort);
}
repo.findByAndSort("lannister", Sort.by("firstname"));
repo.findByAndSort("stark", Sort.by("LENGTH(firstname)"));
repo.findByAndSort("targaryen", JpaSort.unsafe("LENGTH(firstname)"));
repo.findByAsArrayAndSort("bolton", Sort.by("fn_len"));위 예시에서 2번째 findByAndSort 호출은 예외가 발생하지만, 3번째는 발생하지 않는다.
PageRequest는 내부적으로Sort를 포함하고 있으며, 추가적으로 페이지 정보를 가진다.
대규모 쿼리 결과 처리
대규모 쿼리 결과를 모두 메모리에 적재하는 것은 낭비가 심하기 때문에 부분적인 결과를 가져오는 방법이 필요하다.
이 과정에서 사용할 수 있는 방법은 크게 3가지가 있다.
Pageable과PageReqeust를 이용한 페이징
PageRequest는Pageable의 구현클래스다- Offset 기반의 스크롤링
전체 결과 수를 포함하지 않기때문에 페이징보다 가볍다- Keyset 기반의 스크롤링
offset 기반 검색의 단점( 성능저하, 인덱스 활용 등 )을 보완할 수 있다
스크롤링
스크롤링은 대량의 데이터를 순차적으로 접근할 때 유용한 데이터 접근 방식이다.
Window<User> users = repository.findFirst10ByLastnameOrderByFirstname("Doe", ScrollPosition.offset());
do {
for (User u : users) {
// consume the user
}
// obtain the next Scroll
users = repository.findFirst10ByLastnameOrderByFirstname("Doe", users.positionAt(users.size() - 1));
} while (!users.isEmpty() && users.hasNext());이와 같이 Top이나 First 키워드를 이용하여 결과값의 개수를 제한할 수 있으며,
Window 인터페이스 타입의 결과값이 반환된다.
WindowIterator<User> users = WindowIterator.of(position -> repository.findFirst10ByLastnameOrderByFirstname("Doe", position))
.startingAt(ScrollPosition.offset());
while (users.hasNext()) {
User u = users.next();
// consume the user
}위 방식처럼 WindowIterator를 이용하여 데이터를 받아오는 접근 방식도 존재한다.
스크롤링은 크게 offset 기반의 스크롤링과 keyset-filterring 방식의 스크롤링이 존재한다.
interface UserRepository extends Repository<User, Long> { Window<User> findFirst10ByLastnameOrderByFirstname(String lastname, OffsetScrollPosition position); } WindowIterator<User> users = WindowIterator.of(position -> repository.findFirst10ByLastnameOrderByFirstname("Doe", position)) .startingAt(OffsetScrollPosition.initial());offset 기반의 스크롤링은 페이지네이션과 유사하게 특정 offset 이후로부터 데이터를 읽어오는 방식으로 동작한다.
offset 위치파악을 위해 데이터베이스에서 전체 결과를 읽어온 뒤, 정해진 크기만큼 건너뛰는 작업이 들어가므로 성능상의 문제점이 있다.interface UserRepository extends Repository<User, Long> { Window<User> findFirst10ByLastnameOrderByFirstname(String lastname, KeysetScrollPosition position); } WindowIterator<User> users = WindowIterator.of(position -> repository.findFirst10ByLastnameOrderByFirstname("Doe", position)) .startingAt(ScrollPosition.keyset());keyset-filterring 방식의 스크롤링은 DB index와 같이 정렬된 순서와 현재 데이터의 위치를 파악하여, 이를 기반으로 데이터를 읽어온다.
즉, 현재 읽어온 데이터의 키값을 기준으로 이후의 데이터를 조회하는 방식이기에 성능이 더 뛰어나다.
( 정렬순서에 사용된 속성이 쿼리 결과에 포함되어있어야 한다 )결과적으로 이미 정렬된 값을 기준으로 다수의 데이터를 읽어야하는 상황에서는 keyset-filterring 방식의 스크롤링이 더 유용하다고 볼 수 있다.
