소규모 애플리케이션이나 학습목적의 프로젝트에서는 단일 데이터베이스를 사용해 데이터를 관리한다.
하나의 데이터베이스만 사용하는 방식은 데이터베이스에 문제가 발생했을 때, 모든 데이터가 손상될 위험성이 존재한다.
또한, 대부분의 애플리케이션에서 읽기연산의 발생빈도가 높고, 인덱스가 있더라도 데이터베이스를 탐색하는데 소모되는 시간이 긴 편이기에 분산하여 관리할 필요가 생긴다.
애플리케이션에서 데이터베이스 하나만을 사용하는 구조를 standalone 이라 부르며,
메인 DB의 복사본을 읽기작업에 사용하는 구조를을 Primary/Replica,
메인 DB의 이상상태를 감시하고 유사시 복사본을 메인 DB로 대체( failover )하는 구조을 Sentinel,
다수의 메인 DB에 데이터들을 분산하여 관리하는 구조을 Cluster 라고 부른다.
이번 포스팅에서는 Redis에서 제공하는 Cluster 방식과 Spring 에서의 동작방법을 알아보려한다.
Redis Cluster
Redis 공식문서에서 Cluster 관련 내용은 이 곳에서 확인할 수 있다.
여기선 특징적인 부분만 설명할 예정이다
클러스터를 생성하고 상호작용하는 예시는 문서의
Create and use a Redis Cluster부분을 확인하자
이런 식으로 테스트 환경을 구축하고 학습할 수 있다
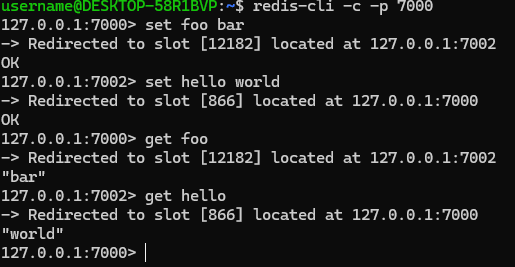
Redis 클러스터를 위해 각 노드들은 두 개의 개방된 TCP 포트를 필요로한다.
- 클라이언트에게 서비스 목적으로 사용하는 포트( ex : 6379 )
- 클러스터 버스 포트( ex : 16379, 일반적으로 노드포트 + 10000 )
클러스터 버스는 바이너리 프로토콜을 사용하는 노드간 통신채널을 의미한다.
클라이언트는 클러스터 버스 포트를 사용해서는 안되며, Redis 명령 포트를 사용해야한다.
또한, 각 포트는 방화벽에서 열려있어야 한다.
클러스터의 각 노드들은 각자의 Replica 노드를 보유한다.
예를들어, A, B, C 노드가 클러스터에 존재한다면 각각 A1, B1, C1을 지니고 있다.
이 Replica 노드들은 마스터 노드에 문제가 발생하면 failover 된다.
만약, Master와 Replica 노드에 모두 문제가 생긴다면 클러스터의 동작이 중지된다.
Sharding
Redis 클러스터는 해싱을 사용하지 않고, 모든 Key가 해시 슬롯이라 부르는 형태의 샤딩을 사용한다.
총 16384개의 해시슬롯( Hash Slot )이 존재하며, 클러스터의 각 노드는 해시슬롯의 하위집합을 담당한다.
예를들어, 3개의 노드가 있는 클러스터라 가정한다면 각 노드에 존재하는 해시슬롯은 아래와 같다
- 노드 A : 0 ~ 5500
- 노드 B : 5501 ~ 11000
- 노드 C : 11001 ~ 16383
특정 키의 CRC-16 값을 16384로 나머지하는 연산을 통해 해시슬롯을 알아낼 수 있다.
만약, 노드가 추가되거나 삭제된다면 이 해시슬롯을 노드 수에 맞게 분배하는 동작이 이뤄진다.
사용자는 단일 명령에 사용되는 데이터를 hash tags 라는 기능을 사용하여 동일한 해시슬롯에 포함되도록 설정할 수 있다.
해시태그는 보통
{}사이에 문자열이 있는 경우, 해당 문자열 내부에 있는 것만 해시된다.즉,
user:{123}:profile와user:{123}:account는 동일한 해시태그를 공유하므로 동일한 해시슬롯에 있는 것이 보장된다.
일관성 문제
Redis 클러스터는 강력한 일관성을 보장하지 않는다. 즉, 특정 상황에서 쓰기작업이 소실될 수 있다.
일관성을 보장하지 않는 이유는 아래와 같다.
-
비동기 복제
Redis 클러스터는 쓰기 작업에 의한 변경사항이 Replica 노드에 반영되기 이전에 클라이언트에게 OK 응답을 보낸다.
따라서, 클라이언트가 OK 사인을 보고 읽기작업을 수행하더라도 아직 Replica 노드에 반영되지 않았을 수 있다.심지어 Replica에 반영하기 이전에 장애가 발생하여 Replica가 failover되면 쓰기작업의 결과가 소실될 수도 있다.
Redis 클러스터는 이러한 단점을 감안하고도 성능상의 이점을 위해 비동기 복제를 사용한다
-
노드 타임아웃
3개의 master 노드( A, B, C )와 3개의 replica 노드( A1, B1, C1 )로 구성된 클러스터와 클라이언트 Z를 가정해보자.
이때, 네트워크 파티셔닝으로 인해A, C, A1, B1, C1 / B, Z로 분할된다클라이언트는 여전히 B 노드에 쓰기작업을 수행할 수 있지만,
B1이 마스터로 승격될만큼 파티션이 오래 유지된다면 그동안 B 노드에 쓰여진 쓰기작업이 소실된다.
이를 판별하는 시간을 노드 타임아웃이라 부른다.노드 타임아웃이 경과한 후, 마스터 노드는 실패한 것으로 간주되며 Replica가 이를 대체한다.
Spring과 Redis Cluster
Redis 클러스터는 각 노드들에 해시슬롯이 분배되고 키가 저장된다.
따라서, 한 명령에서 둘 이상의 키를 포함한다면 모든 키를 정확한 해시슬롯에 매핑해야한다.
Spring Data Redis에서 클러스터와 관련된 동작은 RedisClusterConnection 에서 제공한다.
예를들어, 클러스터 환경에 keys(pattern) 명령을 수행하면 모든 노드들에 keys 명령이 수행된다.
하지만, RedisClusterConnection의 keys(node, pattern)을 사용하면 특정 노드를 대상으로 동작이 수행되게 할 수 있다.
이 과정에서 매개변수로 사용되는 RedisClusterNode는 RedisClusterConnection.clusterGetNodes을 이용하거나, 호스트와 포트, 또는 노드 ID를 사용하여 구성할 수 있다.
만일, 명령내의 둘 이상의 키가 동일한 슬롯에 매핑된다면 MGET 같은 다수의 데이터를 조회하는 명령이 실행된다.
반면 다른 슬롯에 매핑된 경우에는 각 슬롯에 GET 명령이 수행된다.
이는 성능면에서 떨어지기 때문에 해시태그를 사용하여 명확하게 같은 슬롯에 데이터가 저장되도록 작성하자.
RedisTemplate과 클러스터
ClusterOperations clusterOps = redisTemplate.opsForCluster();
clusterOps.shutdown(NODE_7379);RedisTemplate의 opsForCluster()를 이용하면 클러스터 연산에 사용되는 ClusterOperations 객체를 얻을 수 있다.
해당 객체는 템플릿의 직렬화/역직렬화 기능을 유지하면서 클러스터 내의 단일 노드에서 명령을 수행할 수 있다.
직렬화기로 JSON을 사용하는 경우, 해시슬롯 연산에 영향을 주므로 주의하자
