정한 이유
이번에 Downstream Task 하나를 추가로 해보는 과정에서 NLI 데이터셋을 가지고 해볼까 하는데, NLI dataset 찾아보니 SNLI가 나와서 읽어보려 한다.
논문 pdf 링크
'A large annotated corpus for learning natural language inference'
리뷰
Abstract
- entailment, contradiction을 이해하는 것 → 자연어를 이해하는 데 기본적인 요소
- entailment, contradiction에 대한 추론 → semantic representation의 발전을 위한 중요한 실험 대상
→ 하지만, 이 분야의 ML 연구는 대규모 리소스의 부족으로 인해 제한 받았음. 이 문제를 해결하기 위해 SNLI(Standford Natural Language Inference)를 제안하려고 함.
- SNLI는 인간이 작성한 레이블 달린 57만 개 문장 쌍의 모음으로 구성된다.
→ 2배 가량이 커진 것으로, 이는 lexicalized classifier들이 일부 복잡한 entailment model보다 더 나은 성능을 발휘할 수 있게 하고 신경망 기반 모델이 처음으로 NLI에서 경쟁력 있는 결과를 낼 수 있게 함.
Introduction
-
entailment and contradiction의 의미적 개념 → 자연어의 모든 측면에 중요한 역할을 함
-
어휘 ~ 전체 텍스트 내용까지 이러한 의미적 개념 → 중심 역할을 함
-
symbolic logic, knowledge bases, neural networks 등 다양한 기술을 활용하여 NLI를 다뤄왔는데, NLI는 (2015년 기준) 최근 몇 년 동안 distributed words와 phrase representation을 이용하는 접근 방식에 있어 중요한 testing ground로 작용함
-
Distributed Representation(분산 표현)은 similarity(유사도)를 기반으로 한 relations를 파악하는 데 능하고, simple dimension of meaning을 모델링하는 데 효과적임이 입증됨. 하지만, 이러한 분산 표현이 NLI가 필요로 하는 범위의 논리 및 상식 추론을 지원할 수 있는지는 덜 명확함
ex. NLI에 대한 분산 표현의 성능을 평가하는 것이 목표였던 SemEval 2014 task에서 최고 성능을 낸 시스템들은 추가적인 feature와 reasoning capability(추론 능력)에 크게 의존적이었음 -
이 논문의 목표는 NLI에 대해 학습 중심 접근 방식의 경험적 평가를 제공해, NLI를 semantic representation에 대해 도메인-일반적인 평가 도구로 발전시키는 것이다.
-
하지만, 기존의 NLI 말뭉치는 다음과 같은 단점을 지님
- 현대의 집약적이고 광범위한 모델을 학습시키기에는 너무 작음
- 많은 말뭉치는 알고리즘적으로 생성된 문장을 포함함
- 주석 퀄리티에 상당한 영향을 주는 event-entity coreference의 불확실성에 종종 둘러싸임
→ 이러한 문제를 해결하기 위해 이 논문에서는 SNLI 말뭉치를 제안하고자 함
- SNLI는 다음과 같은 특징을 가짐
- 570,152 쌍의 문장으로 구성됨
- labels : entailment, contradiction, semantic independence
- 이와 유사한 기존 말뭉치보다 2배 정도 큼
- 다른 자료들과 달리, 모든 문장과 레이블이 실제 상황을 기반으로 한 자연스러운 맥락에서 인간에 의해 작성됨 (예제 중 56,941개에 대해 각 레이블에 대해 추가적으로 4명의 판단을 수집 → 이 중 98%는 3명의 판단이 일치, 58%는 모든 5명(기존 포함)의 판단이 일치함)
A new corpus for NLI
-
논문이 나오기 전까지 주석이 달린 NLI 말뭉치의 주요 출처는 RTE(Recognizing Textual Entailment) challenge 태스크였음
→ 고품질/수작업 레이블링된 데이터 세트였음
→ 하지만, 크기가 너무 작았음
→ 크기 측면에서 한 단계 더 나아간 SemEval 2014 작업인 SICK(Sentences Involving Compositional Knowledge)조차도 훈련 데이터로 4,500개만 존재했음
→ (sentence-level entailment) Denotation Graph entailment set, (outside of sentence-level entailment) Levy et al.(2014), second release of the Paraphrase Database도 비슷하게 뭔가 한계?가 있었음- Denotation Graph entailment set : entailment sentence 예제 수백만개를 가졌으나 모두 automatic-method로 라벨링되어 노이즈가 많아 오로지 supplementary training data로만 이용할 수 있었음
- Levy et al.(2014) : 반자동으로 주석이 달린 entailment 예시들(주어-동사-목적어 relation triples) 가짐
- second release of the Paraphrase Database : 단어와 짧은 구문들 쌍의 대규모 말뭉치에 대해 자동 생성된 주석 포함함
-
이렇게 기존에 존재하는 리소스들은 심지어 인간이 직접 제공한 주석들만 사용하는 프로젝트에도 영향을 끼치는 issue가 있었음
→ event와 entity coreference의 indeterminacies(불확실성) ⇉ correct semantic label의 불확실성으로 이어짐event coreference ex. "A boat sank in the Pacific Ocean" & "A boat sank in the Atlantic Ocean." → 접근 방식 1) 두 문장이 같은 하나의 event를 가리킨다고 가정 : contradiction으로 라벨링 → 접근 방식 2) 위와 같은 가정이 없다고 가정 : 합리적으로 생각했을 때 neutral로 라벨링 ⇉ 위와 같은 문제를 해결하기 위해 위 2가지 접근 방식 중 하나를 정하여 모든 접근 방식을 통일해야 하지만, 이는 문제가 존재한다. 접근 방식 통일 시 발생하는 문제 - opt not to assume that events are coreferent → broad universal assertioin을 만드는 문장들 사이에서 contradiction만을 발견할 것임 - opt to assume coreference → counterintuitive prediction이 나올 것임 ex. "Ruth Bader Ginsburg was appointed to the US Supreme Court" & "I had a sandwich for lunch today" coreference를 가정하면 위 쌍은 neutral이 아니라 contradiction으로 라벨링될 것임 entity coreference ex. "A tourist visited New York" & "A tourist visited the city" → New York과 the city 간 coreference를 가정하면 entailment 라벨링이 타당할 것임 → 하지만 그 가정이 없으면 the city가 특정한 unknown city를 가리킬 수 있으므로 neutral로 라벨링될 것임
👉🏻 라벨링 관련 indeterminacy(불확정성) 문제는 coreference question이 해결되어야지만 해결 가능함
- SNLI은 size, quality, indeterminacy 문제에 대응하려고 노력함
- 예제들은 특정 시나리오에 근거하여 만들어졌으며, 각 예제의 전제(premise)와 가설(hypothesis) 문장은 동일한 관점에서 해당 시나리오를 묘사하도록 제한되었음
→ event and entity coreference를 다루는 데 있어 큰 도움이 될 것임 - 참가자들에게 task setting 내에서 완전히 새로운 문장을 생성할 수 있는 자유를 부여하는 프롬프트를 제공
→ 일관성을 희생하지 않으면서 더 풍부한 예제를 얻을 수 있음 - result sentence의 subset은 validation task로 보내짐
→ 동일한 데이터에 대해 신뢰성 있는 주석 집합을 제공하기 위해
→ 추론적 불확실성 영역을 식별하기 위해
- 예제들은 특정 시나리오에 근거하여 만들어졌으며, 각 예제의 전제(premise)와 가설(hypothesis) 문장은 동일한 관점에서 해당 시나리오를 묘사하도록 제한되었음

Data collection
- 데이터 수집을 위해 Amazon Mechanical Turk을 사용함
- 각 HIT(개별 작업)에서 각 worker : 기존의 말뭉치로부터 가져온 premise scene descriptions을 제시받고 entailment, contradiction, neutral 이 3개의 레이블들 각각에 대한 hypothesis sentence를 제시하도록 요청받음(이는 데이터에서 3개의 클래스들이 서로 balance를 유지하는 데 도움을 줌) 아래 Figure 1이 worker들에게 제공되는 instruction임

- 약 2,500명의 worker가 참여함
- premise : Flickr30k 말뭉치에서의 caption 160,000개를 사용함
- 이 캡션은 30,000개 이미지로부터 논문의 접근 방식에 알맞게 구성한 캡션임
- 각 문장 쌍의 라벨이 가능한 텍스트에 기반해 recover될 수 있도록 하기 위해 말뭉치 수집 과정 중에 이미지는 전혀 사용하지 않음
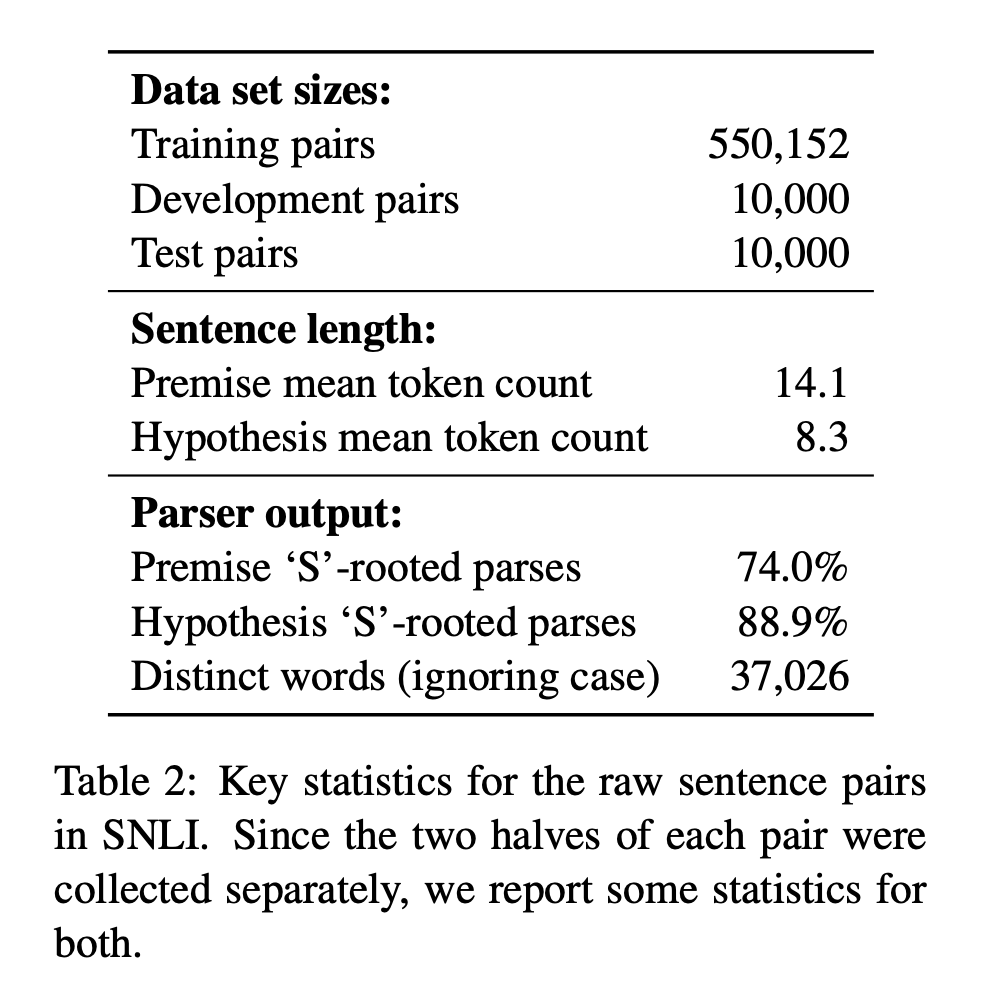
- Table 2는 수집된 corpus의 통계적 정보를 나타냄.
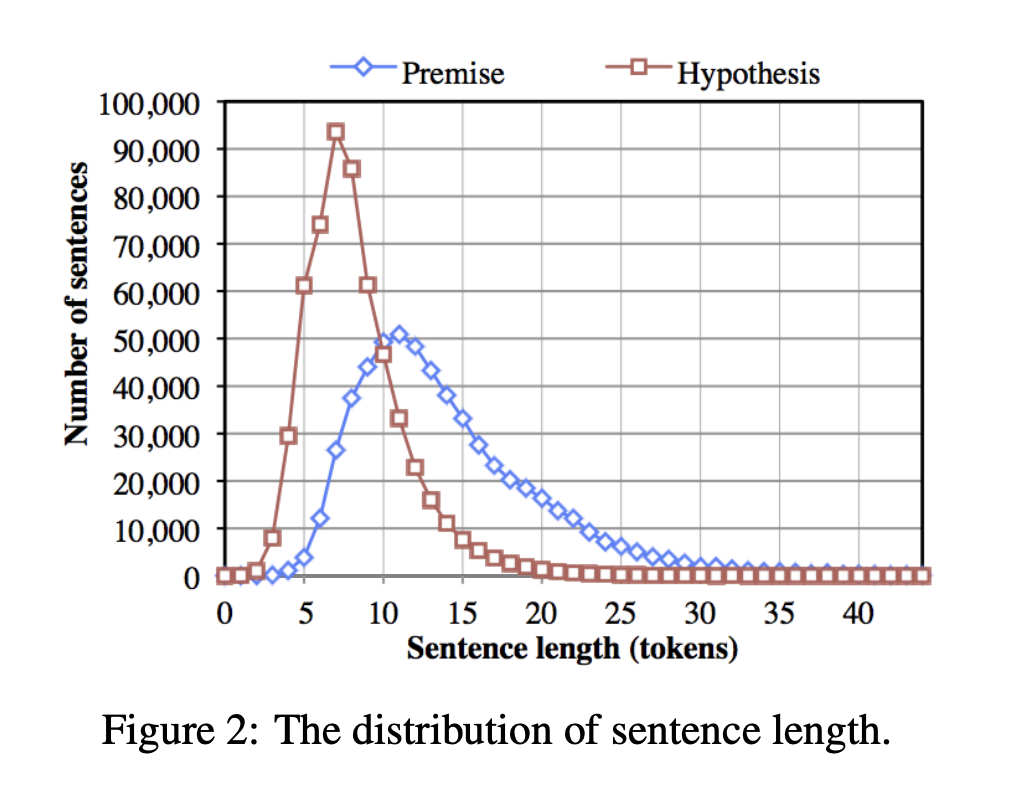
- Figure 2는 source hypothesis와 새롭게 수집된 premise들의 문장 길이 분포를 나타냄
- 발견한 것
- premise는 길이 측면에서 다양하지만, hypothesis는 명확한 판단을 내릴 수 있는 상태인 동시에 가능한 짧은 길이였음 (Figure 2를 보면 대략 7단어 정도에서 많이 모여있는 것을 볼 수 있음)
- sources의 sentence들은 모두 단편적인 것이 아니라 문법적으로 완전한 형태였음(Parser output을 보면 Premise, Hypothesis 모두 'S'-rooted parses 비율이 높음 ⇉ 파싱 트리 형태를 말하는 듯)
Data validation
- 데이터 10%에 대해 추가적인 validation phase를 진행함
- 말뭉치 quality를 측정하기 위함
- 유용한 testing, validation set을 구성하기 위함
- SICK에서 entailment sentence에 레이블링할 때 사용한 Mechanical Turk 라벨링 태스크와 동일한 방식을 따름
- 문장 쌍이 5개씩 묶여 있는 배치들을 worker에게 제시 → worker는 주어진 문장 쌍에 라벨링하도록 함 → 각 문장 쌍은 4명의 annotator에게 라벨링됨 → 원래 존재했던 라벨 1개를 포함해 총 5개의 라벨을 얻음(Figure 1.에 나온 형태와 비슷함)
- "gold label"을 정함 → gold label은 5개 라벨 중 최소 3개 이상이 일치한 경우를 가리킴
- 만약 그러한 일치가 없었다면(2%의 경우 이랬음) 라벨에 '-'를 마킹함(이러한 데이터는 도움이 되지 않을 것이라 판단해 training, evaluation 모두에 이용하지 않았음)
⇉ 이러한 검증 결과는 아래 Table 3에 나타남
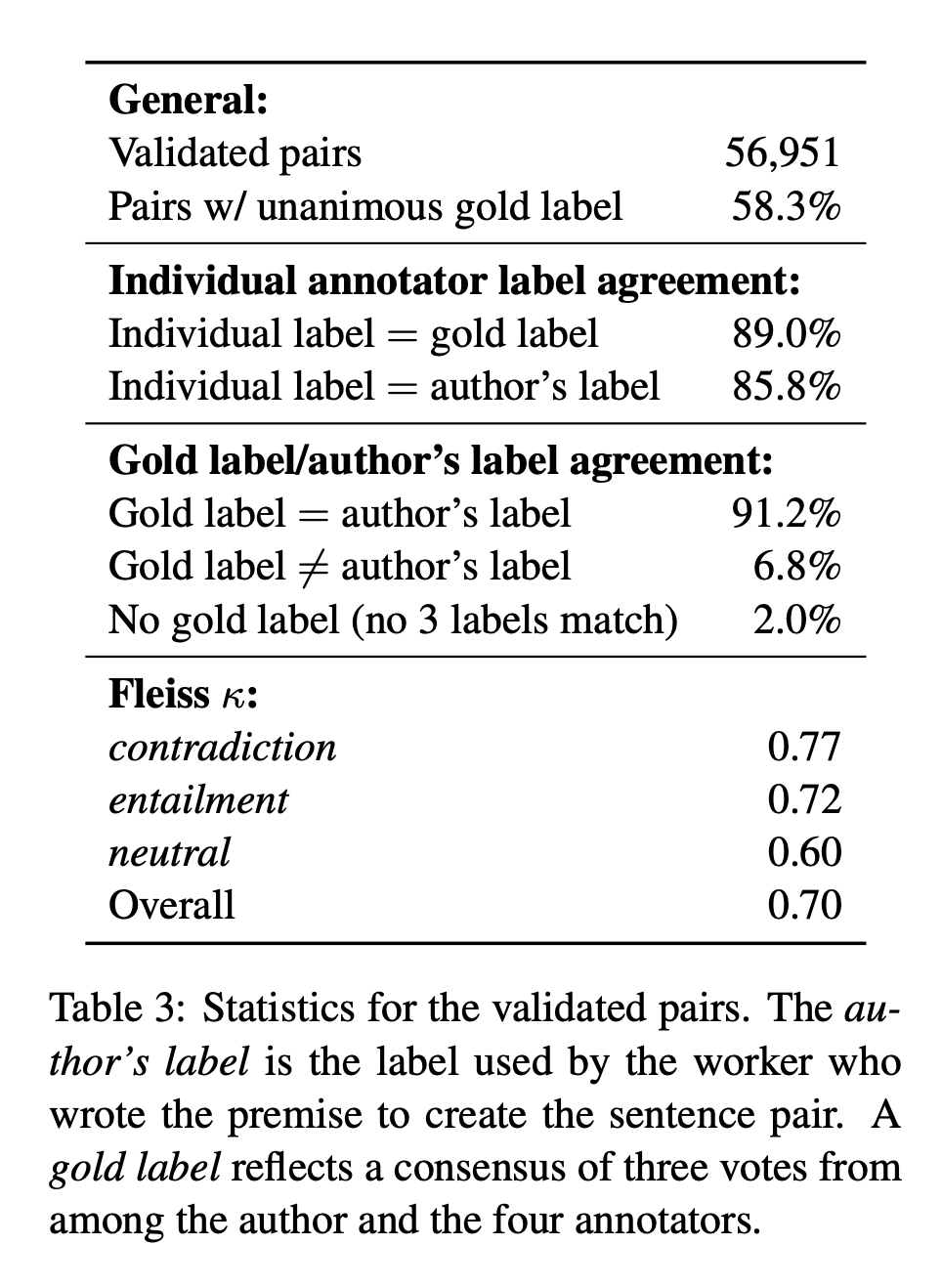
- Fliess 𝒦 점수는 아마 플라이스 카파 점수를 말하는 것 같음(겹치는 문서에서 여러 사용자 어노테이터가 얼마나 일관되게 동일한 어노테이션을 적용했는지 나타내는 수치로, 최고값은 1이고 최저값은 0임)
The distributed corpus
- distributed corpus는 Stanford PCFG 파서 3.5.2 (Klein and Manning, 2003)가 생성한 parse가 포함되어 있음(이는 표준 훈련 세트와 Brown Corpus (Francis and Kucera 1979)에서 훈련되었으며, 이를 통해 기술적 문장과 설명에 나타난 명사 구문의 parse 품질을 개선할 수 있었음)
Our Data as a platform for evaluation
- 위에서 만들어진 데이터셋은 가장 먼저 NLI task를 수행하는 모델을 개발하는 데 사용됨
- 데이터는 품질을 비교할 만한 기존의 데이터에 비해 크기가 컸음 → 이전에는 NLI task에 잘 사용되지 않았고 별로 성능이 좋지도 않았던 training paramter-rich model을 선택함 ex. 신경망 모델
- 다음 3가지 모델 성능 평가할 예정
- 잘 알려진 NLI 시스템인 Excitement Open Platform의 모델
- 강력하면서도 단순한, lexicalized & unlexicalized 특성을 모두 활용하는 classifier model의 변형
- baseline model & neural network sequence model을 포함하는 분산 표현 모델
Excitement Open Platform Model
- Excitement Open Platform: RTE research를 위한 오픈 소스 플랫폼
- EOP는 common lexical resources와 evaluation sets를 공유하며 NLI 시스템을 빠르게 개발할 수 있는 도구임
- 2가지 알고리즘을 평가할 예정
- edit-distance based algorithm(편집 거리 알고리즘)
- classifier-based algorithm
- 이 경우, 기본 형태와 EOP의 전체 어휘 집합으로 보강된 형태 모두 평가됨
cf) RTE(Recognizing Textual Entailment) : 텍스트 데이터에서는 같은 의미의 내용이 다른 표현으로 쓰여 있는 경우가 많은데, 다른 표현이 같은 의미라는 것을 인식하는 기술을 RTE라 한다.
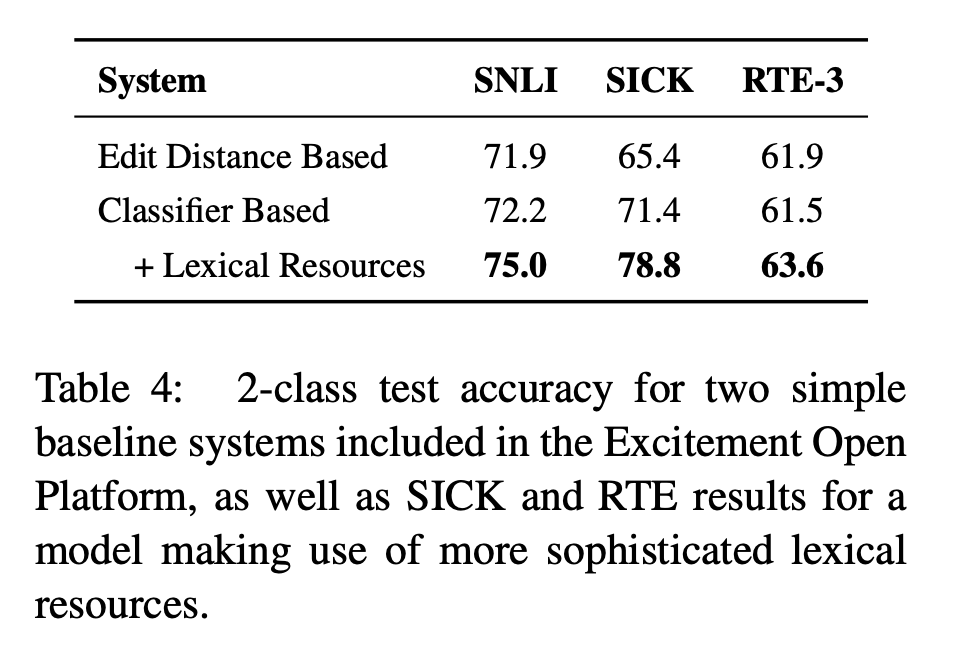
- 목표 : 최신 RTE 성능을 측정하기 보다는 먼저 classifying NLI corpus inference 태스크의 어려움을 이해해보고자 함 → 같은 시스템을 여러 데이터 세트에 적용함으로써 접근해보고자 함
- 사용한 데이터 세트 3개는 다음과 같음
- own test set(SNLI)
- SICK test data
- standard RTE-3 test set
- 결과는 Table 4에 나와있음
- 각 모델은 각 corpus의 training set을 이용해 개별적으로 학습됨
- 모든 모델은 2-class entailment에 기반해 평가됨 → SICK, SNLI와 같이 3가지 클래스 기반으로 하는 데이터셋은 contradiction과 neutral(unknown)이 non-entailment로 convert됨
- edit-distance based : stop words 제거 후 training set에서 대소문자를 구분하지 않는 edit-distance 연산의 가중치를 조정함
- 플랫폼에서 기본적으로 제공하는 classifier외에도 WordNet (Miller, 1995)과 VerbOcean (Chklovski and Pantel, 2004)의 정보를 포함하고, tree patterns and dependency tree skeletons에 기반을 둔 features를 활용한 많은 variants를 학습함
Lexicalized Classifier
-
a simple lexicalized classifier를 평가할 예정
- 복잡한 언어 이해 대신 non-specialized model이 rich lexicalized features를 활용하는 ability를 탐구
- classifier는 6가지 feature type들을 implement할 예정
-
6 feature types(3 lexicalized & 3 unlexicalized)
- BLEU(Bilingual Evaluation Understudy Score) score
: 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법
- N-gram에 기반한 측정 기준
- 값이 높을수록 좋음
- length difference from premise and hypothesis
: 실수값 feature에 해당됨 - overlap between words in the premise and hypothesis
: 모든 단어/명사/동사/형용사/부사에 대한 overlap, 그리고 발생 가능한 overlap의 absolute count와 percentage를 측정 - indicator for every unigram and bigram in the hypothesis
: bigram - 연속된 2개 단어를 하나의 단어로 사용하는 것 - Cross-unigrams
: POS tag(품사 태그)를 공유하는 premise, hypothesis 간 단어 쌍에 대해 구함
- two words의 indicator feature라 볼 수 있음
- Cross-bigrams
: premise, hypothesis 간 bigrams들중 두 번째 단어에서 POS tag를 공유하는 쌍들에 대해 구함
- two bigrams의 indicator feature라 볼 수 있음
- BLEU(Bilingual Evaluation Understudy Score) score
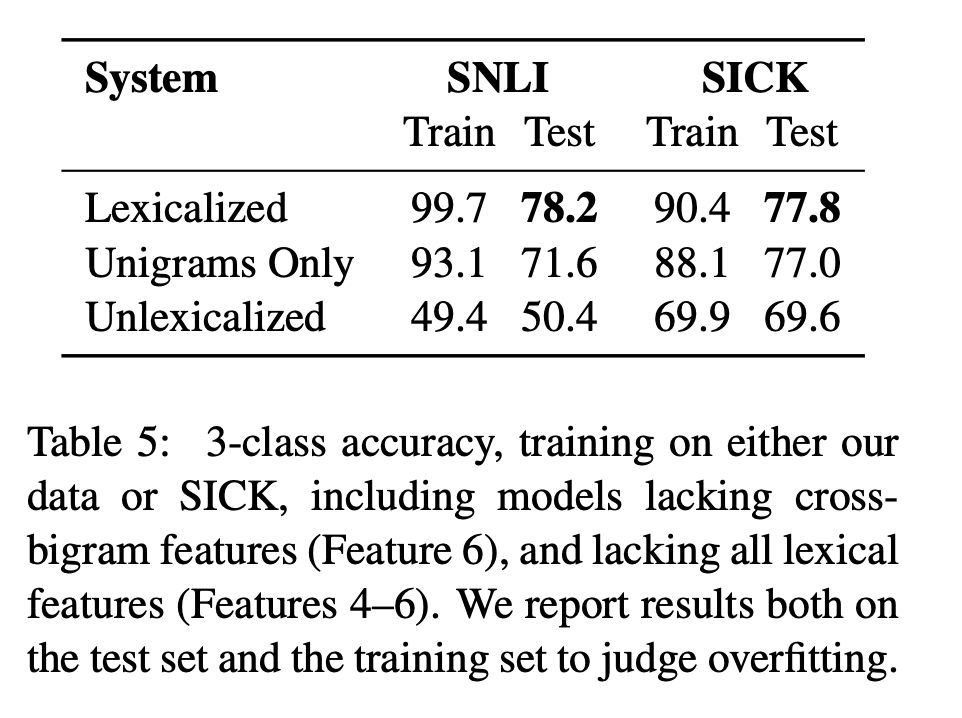
- Table 5에 결과가 보여짐
- cross-bigram feature를 제거하거나 모든 lexicalized feature를 제거하는 연구도 수행 후 결과 제시함
- 특히 논문에서 제시한 대규모 말뭉치 사용에서는 lexicalized feature를 사용하는 것만으로 상당한 정확도 향상을 확인할 수 있음
- sparse cross-bigram feature를 사용할 때도 마찬가지임 ⇉ classifier가 explicit negations와 adjective modification 같은 구조를 자동으로 인식하도록 학습하는 것에 가치가 있음을 알려주는 결과임
- classifier가 alignment나 tree transformation에 대한 개념 없이 이렇게 잘 동작하는 것은 놀라울 일임
👉🏻 물론 더 풍부한 모델이 더 나은 성능을 내겠지만, 이 결과들은 충분한 데이터가 주어진 경우 노이즈가 있는 part-of-speech(품사) overlap contraint를 가진 cross bigram이 효과적인 모델을 생성할 수 있다는 것을 의미함
cf) ablation study : 딥러닝 리서치 분야에서 사용되는 용어 → 제안한 요소가 모델에 어떠한 영향을 미치는지 확인하고 싶을 때, 이 요소를 포함한 모델과 포함하지 않은 모델을 비교하는 것을 말한다. 이는 system casuality(인과관계)를 간단히 알아볼 수 있어 연구에서 중요한 역할을 한다.
Sentence embeddings and NLI
- SNLI는 sentence meaning에 대한 distributed representation을 만드는 neural network model을 학습시킬 만큼 large & diverse함
- 이번 섹션 : 말뭉치에 대한 3가지 모델의 performance 비교 예정
- baseline sentence embedding model
- a plain RNN
- an LSTM RNN
- informative sentence representation을 만드는 부분에 집중하기 위해 NLI 분류 태스크의 중간 단계로써 sentence embedding을 사용할 것임
- 각 모델은 다른 문장의 context 등을 이용하지 않고 two senetences에서 각각에 대한 vector representation을 만든다.
- 만들어진 2개의 vectors는 해당 벡터를 받아서 쌍에 대한 label을 예측하는 model에 전달됨
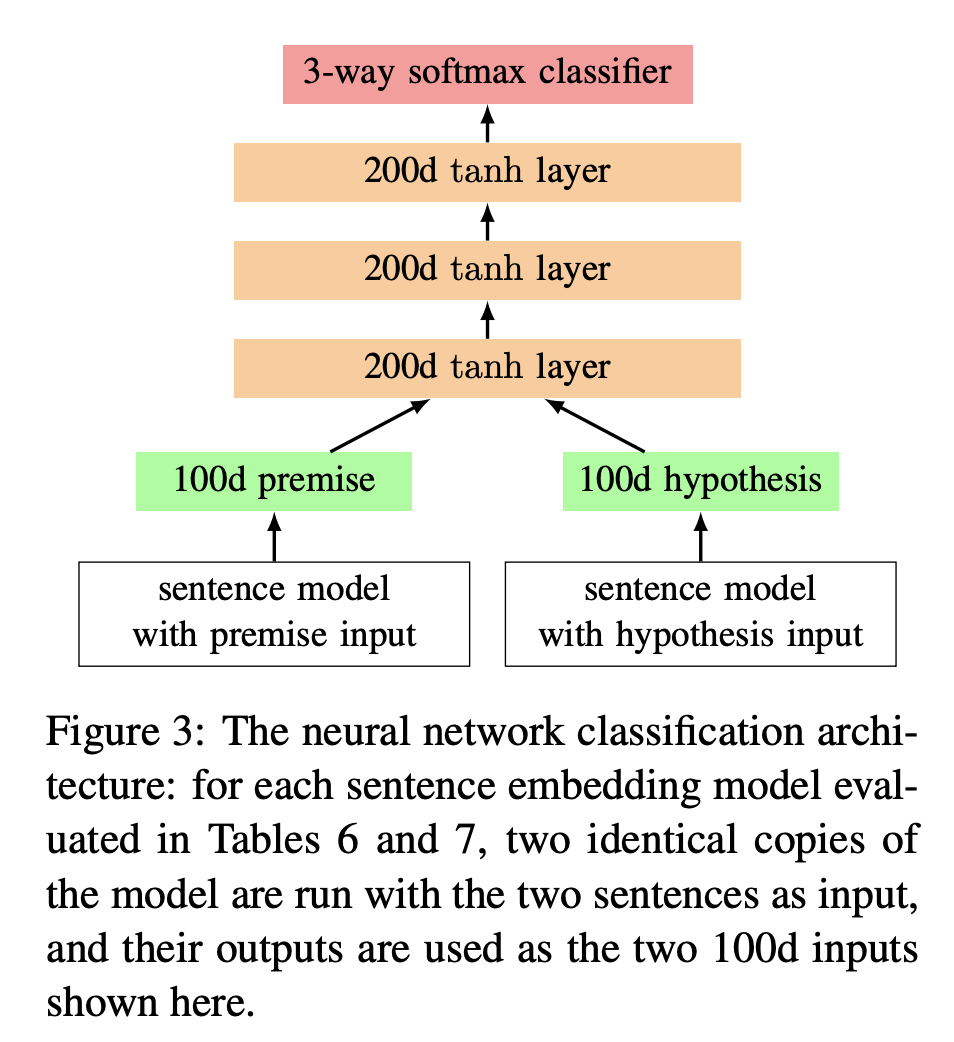
- neural network classifier 구조는 위 그림과 같음
- premise, hypothesis를 입력으로 받은 후 100 차원의 sentence representation을 출력으로 내보내는 모델을 활용해 나온 벡터를 합쳐 입력으로 전달함
- 200 차원 tanh 레이어 3개가 쌓여 있음
- 맨 위에는 3-way softmax classifier가 존재함
cf) 3-way softmax classifier : 3개의 클래스, 즉 3개의 뉴런이 존재하는 softmax classifier를 가리킴
- baseline sentence embedding model은 각 문장에 있는 모든 words embedding의 합(sum)을 사용함
- 모든 모델의 word embedding은 840B 토큰 버전의 300차원 GloVe vecotr들로 초기화됨 + 훈련의 일부로 fine-tuning됨
- 모든 모델은 300차원을 저차원으로 맵핑하기 위해 추가적인 tanh neural network layer를 가짐
- development set에서 더 이상 성능 향상이 없을 때까지 학습이 진행됨
- optimizer : AdaDelta, Regularization : L2
- dropout은 sentence embedding models의 input, output에만 적용함(내부에는 적용 X)
❉ fixed dropout rate
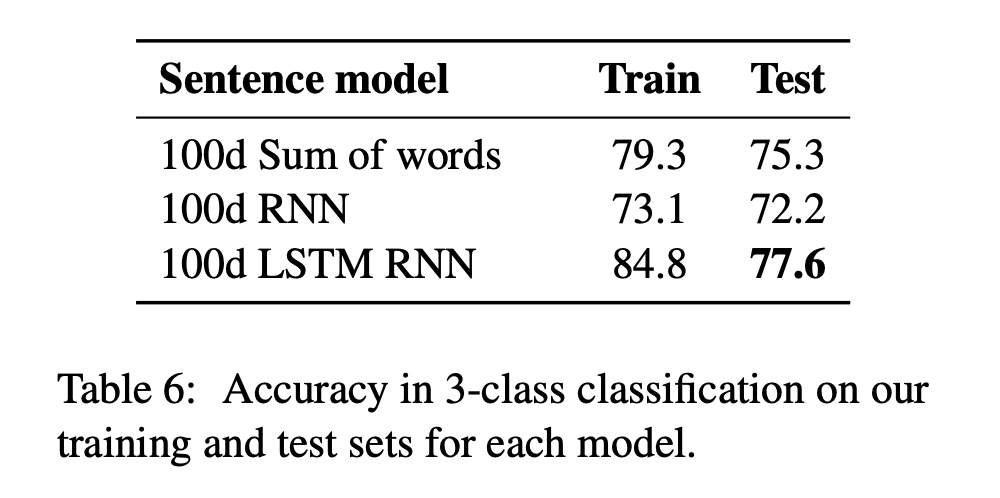
- Table 6 : accracy in 3-class classification
- 100d sum of words
: lexicalized classifier보다 성능이 떨어짐
- sum of words는 pre-trained word embedding을 사용해 드문 단어를 더 잘 처리할 수 있지만, lexicalized classifier의 bigram feature가 제공하는 word order sensitivity를 제공하지는 못함
- 100d RNN
: 제일 성능 좋지 X - 100d LSTM RNN
: test 성능이 lexicalized classifier과 비슷함
- LSTM RNN model은 iteration이 멈추는 부분 주변에서 0.5% 정도의 테스트 정확도 차이가 발생함
- 100d sum of words
→ Lexicalized model과 다르게 이번에 테스트한 3가지 모델은 훈련 ⟷ 테스트 간 정확도 차이가 크지 않다. (만약, 모델이 더 크면 연구가 상당히 의미있을 수 있음을 시사한다고 함)
Analysis and Discussion
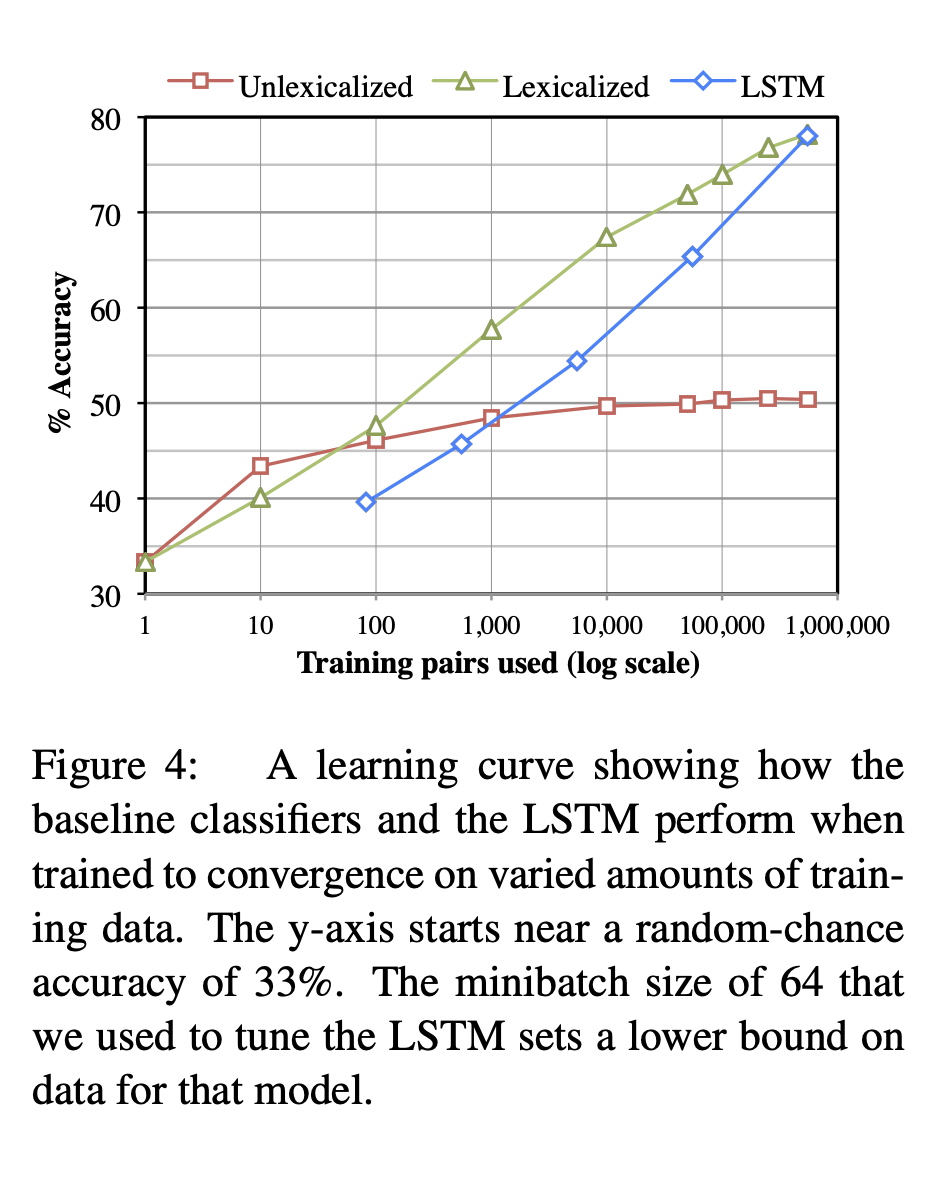
- Figure 4 : training data 양을 다르게 하여 학습했을 때의 learning curve임
- corpus의 large size가 lexicalized, lstm model 모두에게 중요함을 나타냄
- lstm의 가파른 학습 곡선 → 임의의 structured representations of sentence meaning을 학습하는 lstm의 능력은 lstm이 여전히 더 큰 데이터셋에서 constrained-lexicalized model보다 우위를 지닐 수 있음을 말함
- 놀라운 결과는 오직 training pairs 100개를 가지고 lexicalized model이 unlexicalized model 성능을 능가했다는 사실임
- 100개의 예제로 학습된 classifier의 top weighted features는 high precision entailments를 가짐
ex. playing → outsides(most scenes are outdoors), a banana → person eating
- 100개의 예제로 학습된 classifier의 top weighted features는 high precision entailments를 가짐
- 만약 상대적으로 작은 suprious한 entailments가 높은 가중치를 얻었다면 entailments를 식별하는 정확도가 높이 올라갈 수 있었을 것임
- 위에서 다뤄진 모든 모델에 대해서 공통적으로 나타나는 error에는 드러나는 패턴이 있음
- large corpus & GloVe initialized에 의한 distributed information에도 불구하고 여전히 많은 lexical information이 잘못 분석되고 있었고 이는 incorrect prediction으로 이어졌음
ex. training set에 흔한 surf/beach & runner/sprinter 단어에 대해 independent하다고 예측 - word가 아니라 phrase level → compositional semantics에 대한 관심이 이후 좋은 결과를 가져올 것임을 시사함
- 지속적으로 나타는 문제들 중 많은 것이 world knowledge & context-specific inferences에 의존하는 추론에 깊게 연관되어 있음
ex. A race car driver leaps from a burning car/A race car driver escaping danger → classifier & LSTM 모두 neutral로 예측(answer=entailment) - 아래 예시들과 같이 문장끼리 완전히 다른 의미인데 인과관계를 잘못 예측하는 경우도 많았음
ex1. A woman prepares ingredients for a bowl of soup/A soup bowl prepares a woman
ex2. A man wearing padded arm protection is being bitten by a German shepherd dog/A man bit a dog
- large corpus & GloVe initialized에 의한 distributed information에도 불구하고 여전히 많은 lexical information이 잘못 분석되고 있었고 이는 incorrect prediction으로 이어졌음
Transfer learning with SICK
❉ LSTM과 같은 신경망 모델을 SNLI에서 성공적으로 훈련시키려면 해당 모델은 영어로 된 장면 설명의 넓은 범위의 정확한 representation을 인코딩하고 그 관계들을 통해 entailment classifier를 구축해야 함
- 이번 section에서는 간단한 transfer learning method(Pratt et al., 1991)를 이용해 SICK entailment task를 수행함
- SNLI에서 훈련된 LSTM RNN 모델의 매개변수를 가져와서 새로운 모델을 초기화하고, 이 모델은 이후에 SICK의 훈련 부분만을 사용하여 훈련됨
- 새로 초기화되는 파라미터는 softmax layer의 파라미터와 SNLI에는 없지만 SICK에서 나오는 단어들에 대한 embedding(GloVe로 채워짐)이다.
- L2 Regularization 강도만 다시 조정하고 원래 모델을 훈련할 때 사용된 모델 하이퍼파라미터와 동일한 하이퍼파라미터를 사용함

- training on SICK alone
: SICK만을 훈련한 경우 성능이 좋지 않음 - model trained on SNLI
: SNLI에서 훈련한 모델은 SICK 데이터에서 테스트할 때 예측에 실패하는 경우가 많음
- neutral을 contradiction으로 잘못 분류하는 경우가 더 많음
- 이는 레이블링 작업이 어떻게 제시되었는지에 따른 미묘한 차이로 인한 것일 수 있음
- transferring SNLI representations
: 최고의 성능을 냄
- large high-quality corpus → sentence meaning 대한 representaion-learning model을 훈련하여 inference task에서 best hand-engineered된 모델과 경쟁할 수 있음을 시사함
Conclusion
- 자연어는 추론의 강력한 수단 & 언어의 의미에 대한 거의 모든 질문은 문맥에서의 entailment와 contradiction에 대한 질문으로 축소될 수 있음
- NLI = an ideal testing ground for theories of semantic representation → 현존하는 NLI resources의 본질적인 한계로 인해 쉽지 않음
- a new, largescale, naturalistic corpus of sentence pairs labeled
for entailment, contradiction, and independence를 이용해 논문에서는 이 문제를 해결하려 함 → corpus를 이용해 다양한 모델을 평가함- simple lexicalized models & neural network models 성능이 잘 나옴
- neural network model이 corpus에 대해 학습한 representations은 standard challenge dataset의 성능을 꽤 향상시킬 수 있음을 알게 됨
- SNLI = semantic representation에 ML을 계속 적용하는 데 유용한 훈련 데이터가 되길 바람
