[22-1 학기에 들은 데이터마이닝 이론 및 응용 수업에서 배운 과정이다.]
[1주차]
Stroke 데이터를 이용해서 데이터 전처리 실습을 진행해보았다.
선정이유
데이터마이닝 수업과 실습시간에서 여러가지 전처리 기법들에대해 배웠다. 뇌졸중은 전세계에서 2초에 한명씩 발병하고 6초마다 한명이 죽는 질병으로 한국에서도 3대 사망원인 중 하나이며 사망률 1위를 차지한다. 특히 봄과 같은 환절기에서는 뇌졸증이 증가하며 건강보험심사평가원에 따르면 220년 뇌졸중 환자는 60만 7862명으로 2016년 57만 3379명 대비 6% 증가하였다.
따라서 뇌졸중을 예방하기위해 성별 나이,질병여부, bmi 등으로 뇌졸중 환자를 예측할 수 있는지 궁금했기에 이번 실습을 진행하였다.
캐글의 'Stroke Prediction Dataset'을 활용하였다. 범주형으로만 이루어진 변수, 불필요한 변수, 아웃라이어가 있는 변수 등이 있어서 예측을 하기 위해서는 데이터 전처리는 필수적으로 보였다. 또한 EDA를 사용하여 각 변수가 어떠한 형태를 띄고 있는지 어떻게 사용될 수 있는지 살펴보았다. 데이터를 전처리 함으로써 뇌졸중이 어떠한 변수에 크게 영향을 받는지 예측할 수 있는 발판을 마련할 수 있으며 이를 통해 일반인은 뇌졸증을 사전에 예방할 수 있으며, 뇌졸증 환자는 뇌졸증의 원인을 파악해 볼 수 있는 계기를 마련한다.
데이터 불러오기 & 변수 정의
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
%matplotlib inlineimport pandas as pd
stroke_data=pd.read_csv('/content/drive/MyDrive/DataMining/stroke_2.csv')
print(stroke_data)features=['age','gender','hypertension','heart_disease', 'ever_married',
'work_type', 'Residence_type' , 'avg_glucose_level','bmi']#데이터와 관련없는 id 제거
x=stroke_data[features]
y_before=stroke_data['stroke'] #feature를 x로, 예측하고자하는 target을 y로 나누기
y=pd.DataFrame(y_before)
y.columns=['target_y']
print(y)
print(y['target_y'].value_counts()) 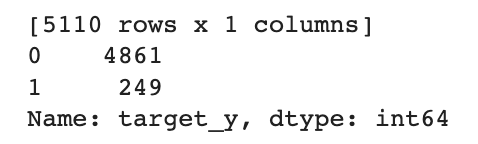
Y값의 분포가 imbalance 한 데이터셋이다.
변수
- age : Age of the patient in Years
- gender : Sex of the Patient
- Male
- Female - hypertension
- 0 = if the patient doesn't have hypertension
- 1 = if the patient has hypertension - avg_glucose_level :average glucose level in blood
- bmi: body mass index
- heart_disease
- 0 = if the patient doesn't have any heart diseases
- 1 = if the patient has a heart disease - work_type
- children
- Govt_jov
- Never_worked
- Private
- Self-employed - ever_married
- No
- Yes - id: unique identifier
- Residence_type
- Rural
- Urban
- smoking_status - formerly smoked
- never smoked
- smokes
- Unknown - stroke
- 0 = if the patient had not a stroke
- 1 = if the patient had a stroke
Imputation
데이터에 결측값이 있으며 결측값으로는 모델들을 사용하기 어렵다. 따라서 결측치를 평균갓, 중앙값등으로 대체 할 수 있다. 평균치는 아웃라이어의 영향을 중앙값보다 받기 쉬우므로 중앙값으로 대체하였다. x중 bmi 만 결측치가 있으므로, bmi의 결측치를 중앙값으로 대체하였다.
x.info()
x.fillna(x['bmi'].median(), inplace=True)
Data Sampling
뇌졸중 발생이 일어나지 않았을 때의 데이터가 4861로 발생했을 때의 데이터에 비하여 너무 많기 때문에 target 변수의 클래스가 불균형한 문제가 발생한다. 이를 해결하는 방법으로 undersampling과 oversampling이 있는데 undersampling은 정보손실을 유발하므로 oversampling을 사용하였다. 단순히 랜덤 오버샘플링을 하여 동일한 데이터를 반복시켜 과적합을 발생시키는 문제점이 있다. SMOTE는 k근접 이웃을 활용하여 가상의 데이터를 생성하는 오버샘플링 기법이다. 하지만 SMOTE는 연속형에서만 사용 가능하므로 연속형과 범주형 변수에서 모두 사용가능한 SMOTE-NC를 사용하였다.
from imblearn.over_sampling import SMOTENC
oversample = SMOTENC(random_state=312, categorical_features=[1,2,3,4,5,6])
x_over, y_over = oversample.fit_resample(x, y)
print(y_over.value_counts())
Data Partitioning
데이터를 모두 학습시킨 상태로 결과를 예측할경우 과도하게 학습되는 overfit이 발생한다. 따라서 이를 방지하기 위해 train과 test셋으로 나누어 train셋은 모델을 학습할때 사용하고 test셋으로 최종 모델의 성능을 측정하여 과적합을 방지하였다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_over, y_over, train_size=0.7, test_size=0.3, random_state=77)EDA
EDA를 사용하여 데이터를 분포를 파악하고 통계량과 시각화를 통해 통찰력을 얻고자 하였다.
범주형 변수들의 분포
범주형 변수들의 분포를 살펴보기 위해 막대그래프로 시각화하였다. 고혈압과 심장벙을 앓고 있지 않은 사람들이 많았으며, 결혼한 사람들이 두배정도 많았고, 사기업에서 일하는 직장인의 비율이 높았다.시골과 도시에 사는 사람의 비율은 거의 비슷했다. 담배를 폈던 사람, 피고 있는 사람, 피지 않는 사람의 비율이 1:1: 2로 담배 경험이 있었던 사람과 없었던 사람의 비율은 1:1로 비슷했다.
var = x.groupby('gender')['gender'].count()
plt.title('gender', fontsize=20)
plt.bar(var.index, var)
plt.xticks([0, 1, 2])
plt.show()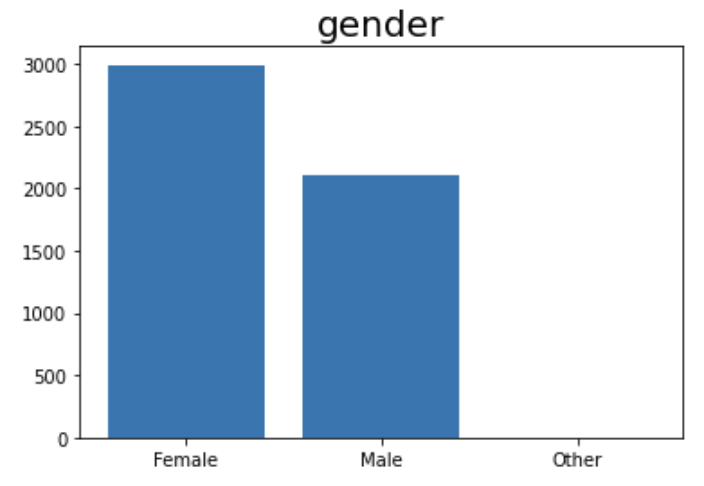
var = x.groupby('work_type')['work_type'].count()
plt.title('work_type', fontsize=20)
plt.bar(var.index, var)
plt.xticks([0, 1, 2, 3, 4])
plt.show()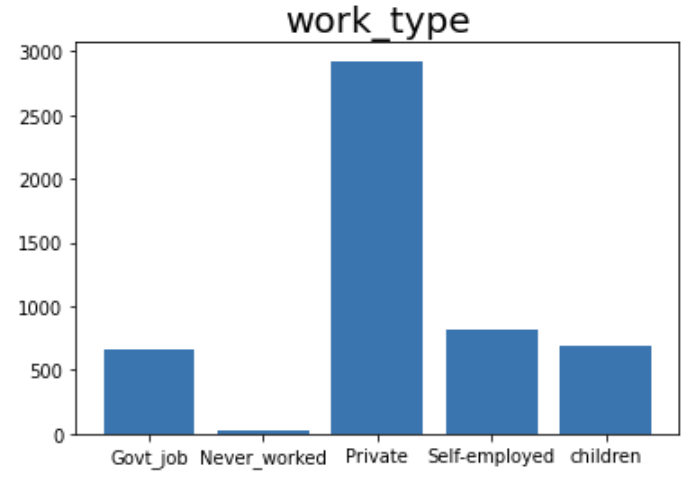
Pie Graph 형태로도 만들어보았다.
def pie_graph(df,title,values):
labels = df[values].value_counts().index
values = df[values].value_counts()
fig = go.Figure(data = [
go.Pie(
labels = labels,
values = values,
hole = .5)
])
fig.update_layout(title_text = title)
fig.show()pie_graph(x_train, 'Hypertension Distribution','hypertension')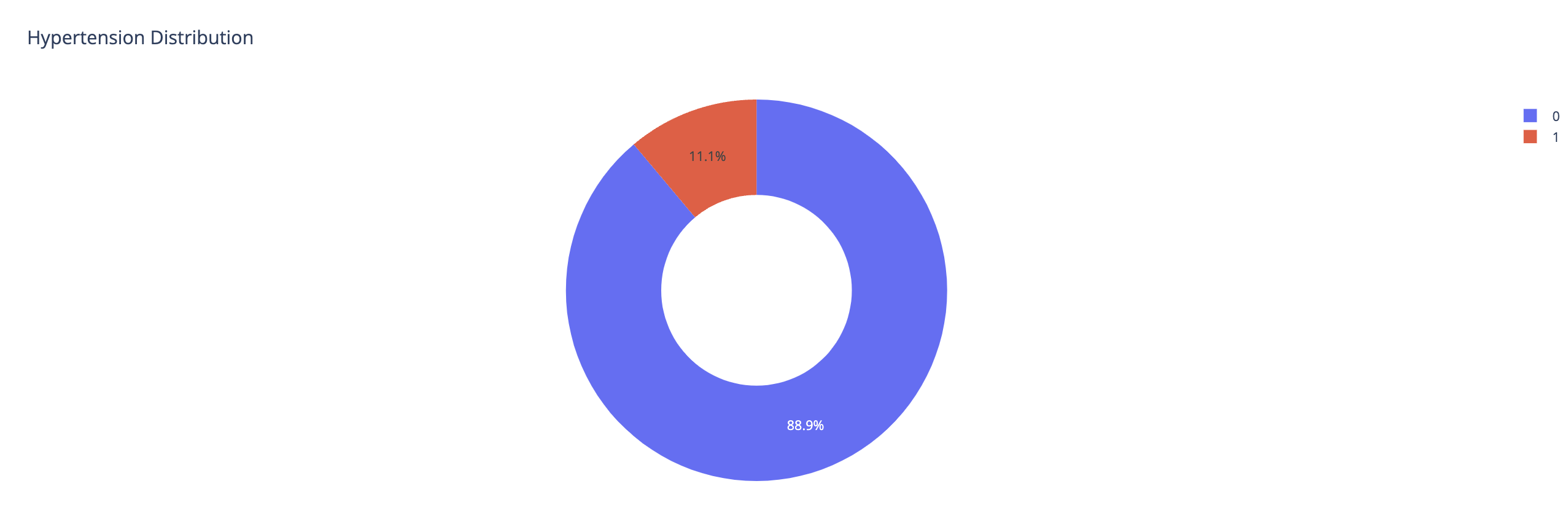
연속형 변수들의 분포
연령을 살펴보면 60-80대가 많은 것으로 나타났으며, 혈당의 경우에도 90정도의 정상 혈당과 200이 넘는 혈당이 많이 분포하는 것으로 나타났다. bmi역시 30을 평균으로 분포하는 것으로 파악되었다.
Reference

왜 1주뿐인가요?