1. 풀 텍스트 쿼리 - Full Test Query
match_all
match_all은 별다른 조건 없이 해당 인덱스의 모든 도큐먼트를 검색하는 쿼리이다.
검색시 쿼리를 넣지 않으면 자동으로 match_all이 적용된다.
match
match는 풀 텍스트 검색에 사용되는 가장 일반적인 쿼리이다.
GET my_index/_search
{
"query": {
"match" : {
"message": "quick dog"
}
}
}match 필드에 여러 검색어를 띄어쓰기로 입력하면 자동으로 OR 조건으로 검색된다.
검색어가 여럿일 때 조건을 디폴트 OR에서 다른 연산자로 바꾸려면 operator 필드를 넣어주면 된다.
GET my_index/_search
{
"query": {
"match" : {
"message": {
"query": "quick dog",
"operator": "and"
}
}
}
}match_phrase
AND는 무조건 특정 검색어들이 포함되어 있기만 하면 된다.
match_phrase는 포함은 물론 순서까지 같아야 검색이 된다.
특히 slop 옵션을 1로 하면 지정된 값 만큼 단어 사이에 다른 검색어가 끼어드는 것을 허용할 수 있다.
GET my_index/_search
{
"query": {
"match_phrase" : {
"message": {
"query": "lazy dog",
"slop": 1
}
}
}
}query_string
기본적으로 ESsms URL에 q 파라미터를 이용하여 검색이 가능하다.
URL 검색에 사용하는 루씬 검색 문법을 사용하고 싶을 때 query_string 쿼리를 사용할 수 있다.
GET my_index/_search
{
"query": {
"query_string": {
"default_field": "message",
"query": "(jumping AND lazy) OR \"quick dog\""
}
}
}2. Bool 복합 쿼리 - Bool Query
본문 검색에서 여러 쿼리를 조합하기 위해서는 상위에 Bool 쿼리를 사용하고 그 안에 다른 쿼리들을 넣는 식으로 사용이 가능하다. bool 쿼리는 다음 4개 인자를 가지고 있으며 그 인자 안에 다른 쿼리들을 배열로 넣는 방식으로 동작한다.
- must : 쿼리가 참인 도큐먼트들을 검색한다.
- must_not : 쿼리가 거짓인 도큐먼트들을 검색한다.
- should : 검색 결과 중 이 쿼리에 해당하는 도큐먼트의 점수를 높인다.
- filter : 쿼리가 참인 도큐먼트를 검색하지만 스코어 계산은 하지 않는다. must보다 빠르고 캐싱 가능
사용 방법은 다음과 같다.
GET <인덱스명>/_search
{
"query": {
"bool": {
"must": [
{ <쿼리> }, …
],
"must_not": [
{ <쿼리> }, …
],
"should": [
{ <쿼리> }, …
],
"filter": [
{ <쿼리> }, …
]
}
}
}bool 쿼리를 이용해서 복합적인 검색 기능을 구현할 수 있다. 특히 bool 쿼리는 이후에 정확도(Relevancy)를 위해서도 필요하다.
표준 SQL의 AND, OR 조건들은 2개의 조건값에 대한 이항 연산자이다.
하지만 ES의 must, must_not, should 등은 내부에 있는 각각 쿼리들에 대해 쿼리의 참 거짓을 적용하는 단항 연산자라고 생각하면 조금 더 이해하기 쉽다.
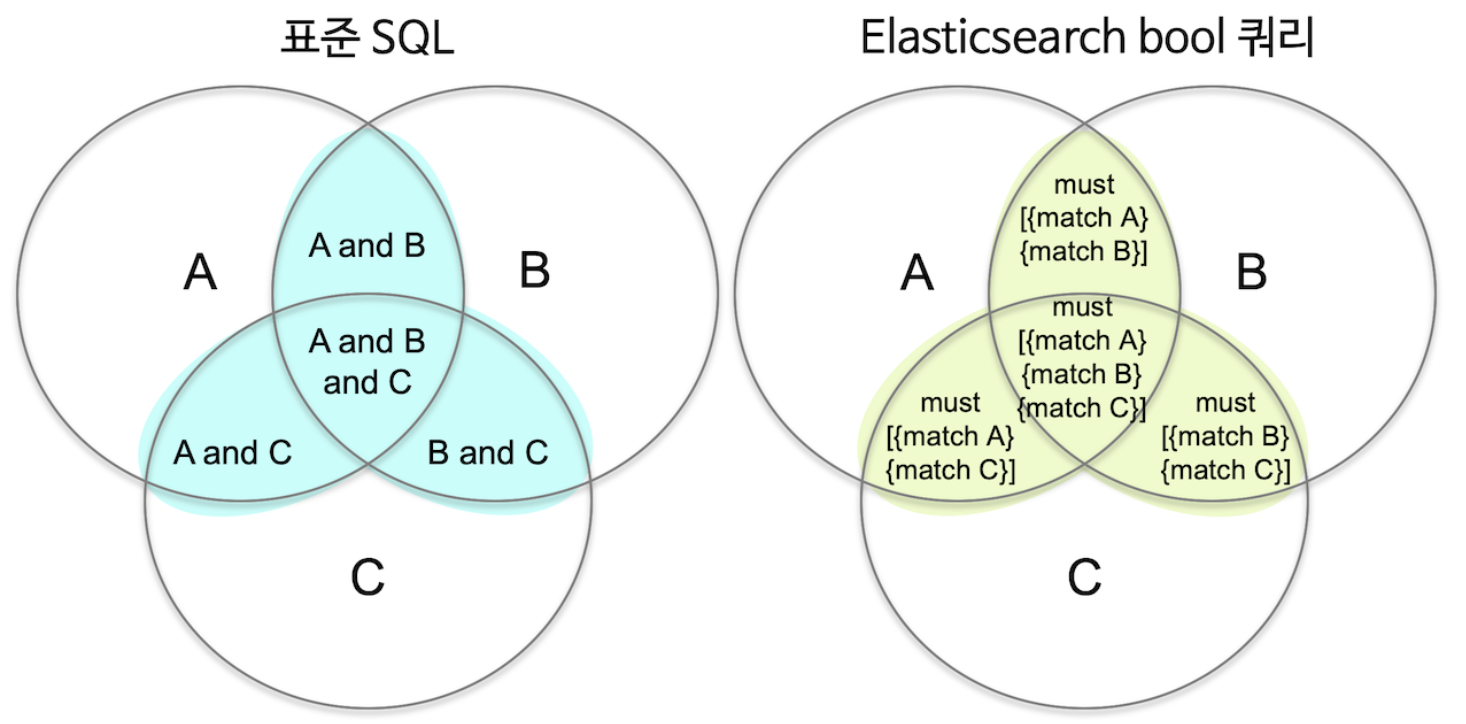
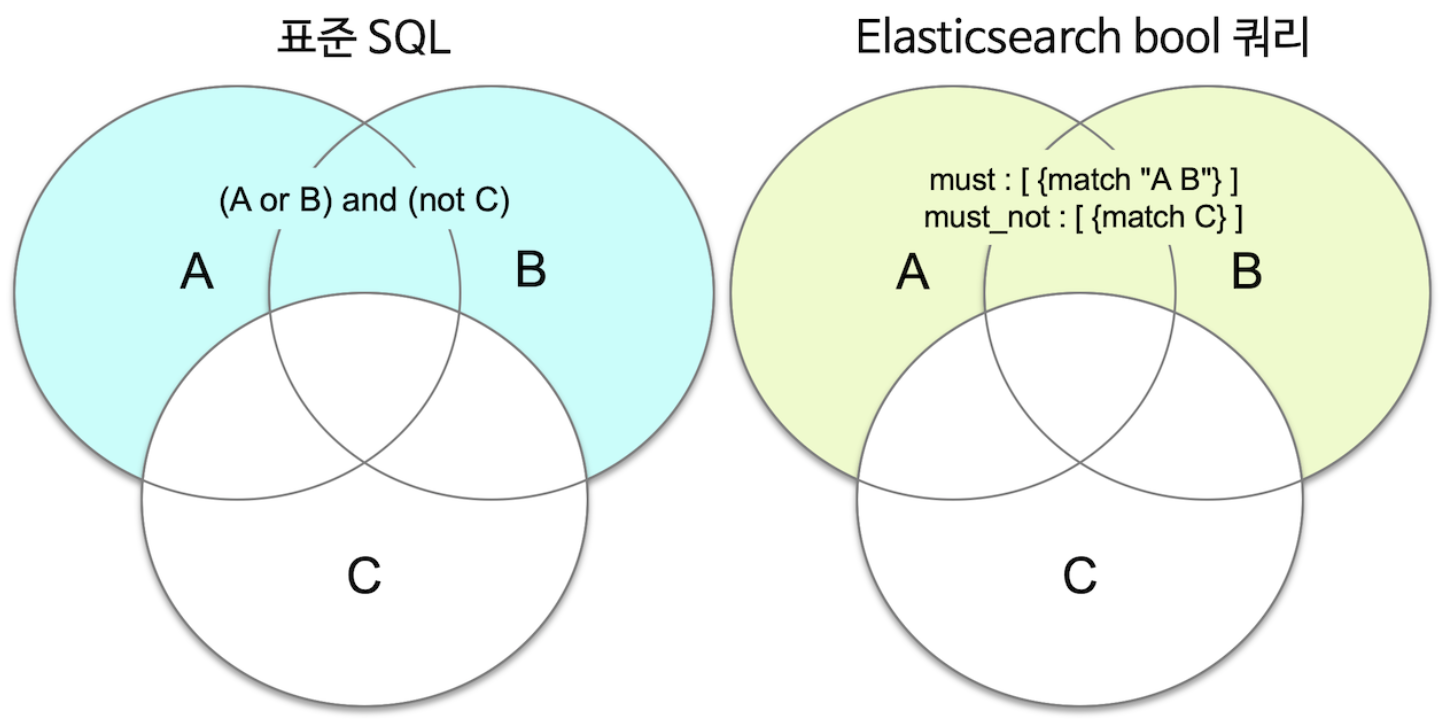
3. 정확도 - Relevancy
RDBMS 같은 시스템에서는 쿼리 조건에 부합하는지만 판단하여 결과를 가져올 뿐 각 결과가 얼마나 정확한지에 대한 판단은 보통 불가능하다. ES와 같은 풀 텍스트 검색엔진은 검색 결과가 입력된 검색 조건과 얼마나 정확하게 일치하는 지를 계산하는 알고리즘을 가지고 있어 이 정확도를 기반으로 사용자가 가장 원하는 결과를 먼저 보여 줄 수 있다.
이 정확한 정도를 Relevancy라고 한다.
스코어(Score) 점수
ES 검색 결과에는 스코어가 표시된다. 이는 검색된 결과가 얼마나 조건과 일치하는지를 나타내며 점수가 높은 순으로 결과를 보여준다. 각 검색 결과는 _score 필드에 점수가 표시되고 _max_score에는 가장 높은 점수가 표시된다.
ES에서는 이를 계산하기 위해 BM25라는 알고리즘을 이용한다. (Best Matching)
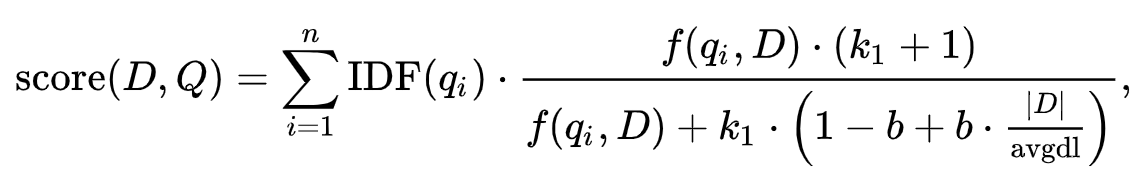
이 계산식에는 3가지 중요한 지표가 사용된다.
TF (Term Frequency)
TF는 검색어가 도큐먼트 내에 얼마나 많이 존재하는지 여부이다. TF가 높으면 점수가 높으며 최대25까지만 증가하게 된다.
IDF (Inverse Document Frequency)
특정 검색어가 여러 도큐먼트에 포함되면 그만큼 희소성은 감소하여 필터 성능이 떨어진다. 따라서 희소성에 따라 텀의 점수가 높아지는 것을 IDF라고 한다.
예를 들어 'quick'이 들어간 도큐먼트가 3개, 'dog'가 들어간 도큐먼트가 5개라고하면 'quick'이 들어가 있는 결과가 점수가 더 높다.
Filed Length
도큐먼트에서 필드 길이가 큰 필드보다는 짧은 필드에 있는 텀의 비중이 더 크다.
예를 들어 게시글의 경우 길이가 짧은 제목 필드가 길이가 긴 내용 필드에 검색어를 포함하고 있는 게시글이 더 점수가 높게 나타난다.
