1. 일반적인 페이징 쿼리의 문제점
일반적인 웹 서비스에서 페이징은 매우 흔하게 사용되는 기능이다.
근래까지는 페이징 성능 최적화의 필요성을 그다지 느끼지 못하였는데,
최근 5000만 row에 달하는 전체 회원을 대상으로 하는 배치를 작성하는 업무를 수행하며 페이징 최적화의 필요성을 느끼게 되었다.
기존에 사용하는 페이징 쿼리는 일반적으로 다음과 같은 형태였다.
select *
FROM members
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지 번호
LIMIT 페이지 사이즈 이와 같은 페이징 쿼리의 가장 큰 문제점은 다음과 같다.
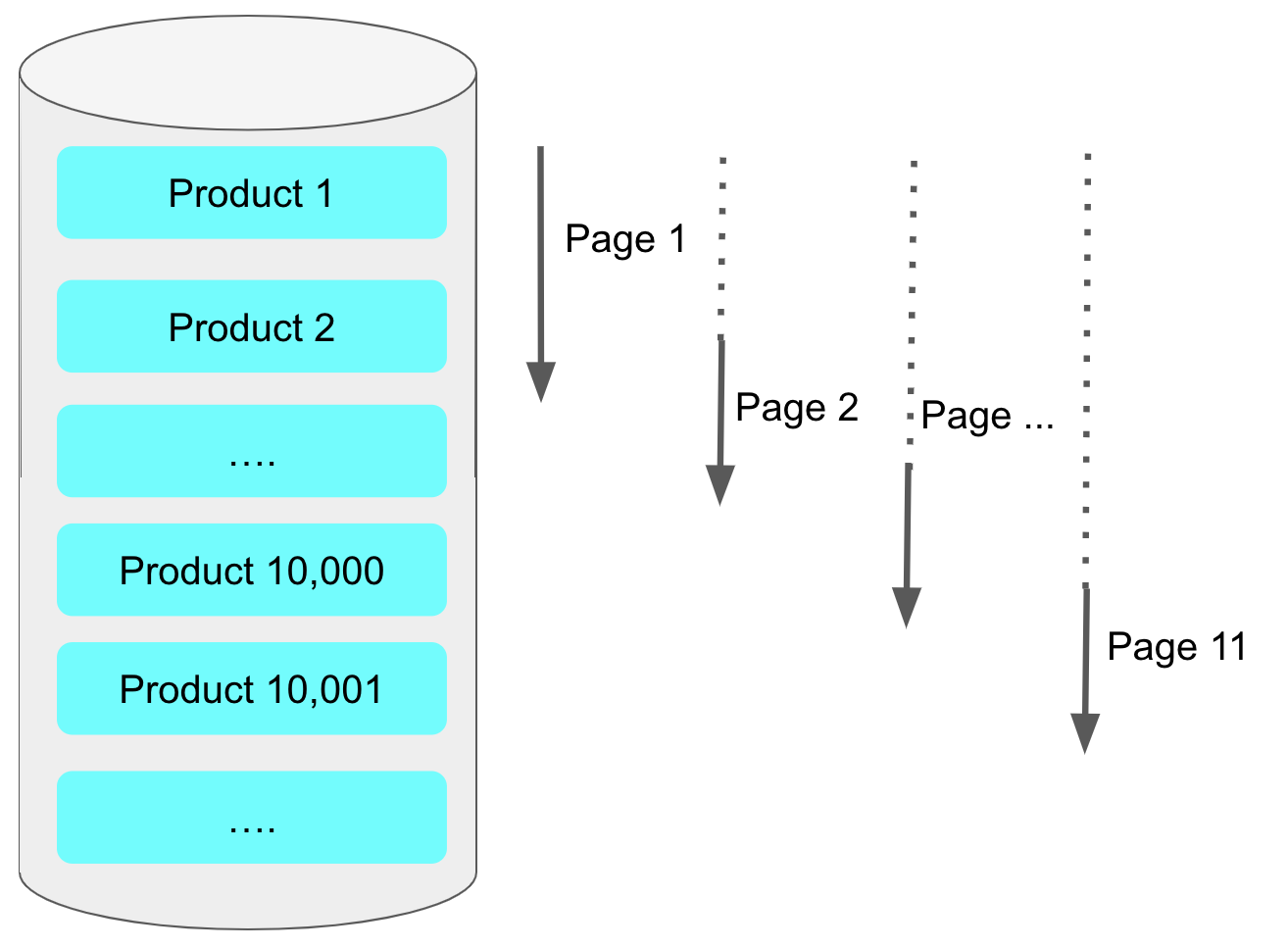
OFFSET 번호가 뒤로 갈수록 느려진다는 점인데, 이유는 뒷페이지를 읽더라도 앞에서 읽었던 행을 버리지만 다시 읽어야하기 때문이다.
예를 들어 offset 10000, limit 20이라 하면 최종적으로 10,020개의 행을 읽어야 한다.
2. (방안1) NoOffset 방식
첫번째 해결 방안은 기존 페이징 방식에서 No Offset으로 구조를 변경하는 것이다.
기존의 페이징 방식이 아래와 같이 번호(offset)와 페이지 사이즈(limit)을 기반으로 한다면.

NoOffset은 아래와 같이 페이지 번호(Offset)가 없는 더보기 (More) 방식을 사용한다.

그렇다면 NoOffset은 무엇이며 왜 빠른 것인가?
NoOffset 방식은 조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만 읽도록 하는 방식이다. (보통 클러스터 인덱스인 PK를 이용하여 조회 시작 부분 찾음)
SELECT *
FROM members
WHERE 조건문
AND id < 마지막조회 ID #직전 조회 결과의 마지막 id
ORDER BY id DESC
LIMIT 페이지 사이즈 위 쿼리와 같이 직전 조회 결과의 마지막 id를 기억하거나 입력으로 받아서 매번 이전 페이지 전체를 건너 뛸 수 있다.
즉, 아무리 페이지가 뒤로 가더라도 처음 페이지를 읽은 것과 동일한 성능을 가지게 되어 문제가 해결된다.
3. (방안2) 커버링 인덱스
이러한 페이징 성능 문제를 해결하다보면 NoOffset 방식을 항상 적용할 수는 없다. (UI상 페이징 버튼이 필요한 경우, 마지막 조회 ID를 알 수 없는 경우..등등)
이런 상황이라면 커버링 인덱스를 이용하여 성능을 개선할 수 있다.
커버링 인덱스란, 쿼리를 충족시키는데 필요한 모든 데이터를 인덱스에서만 추출할 수 있는 인덱스를 이야기한다.
즉, SELECT, WHERE, ORDER BY, LIMIT, GROUP BY 등에서 사용되는 모든 칼럼이 인덱스 칼럼인 경우인데,
보통 SELECT절까지 포함하는 경우 너무 많은 칼럼을 인덱스로 포함시켜야하므로 조인을 통해 사용한다.
예를 들어 아래와 같은 페이징 쿼리를
SELECT *
FROM members
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈아래처럼 처리한 코드를 이야기한다.
SELECT *
FROM members as m
JOIN (
SELECT id
FROM members
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈
) as temp
ON temp.id = m.id위 쿼리에서 커버링 인덱스가 사용된 부분이 JOIN에 있는 쿼리가 된다.
그렇다면 커버링인덱스는 왜 빠르게 처리가 가능할까?
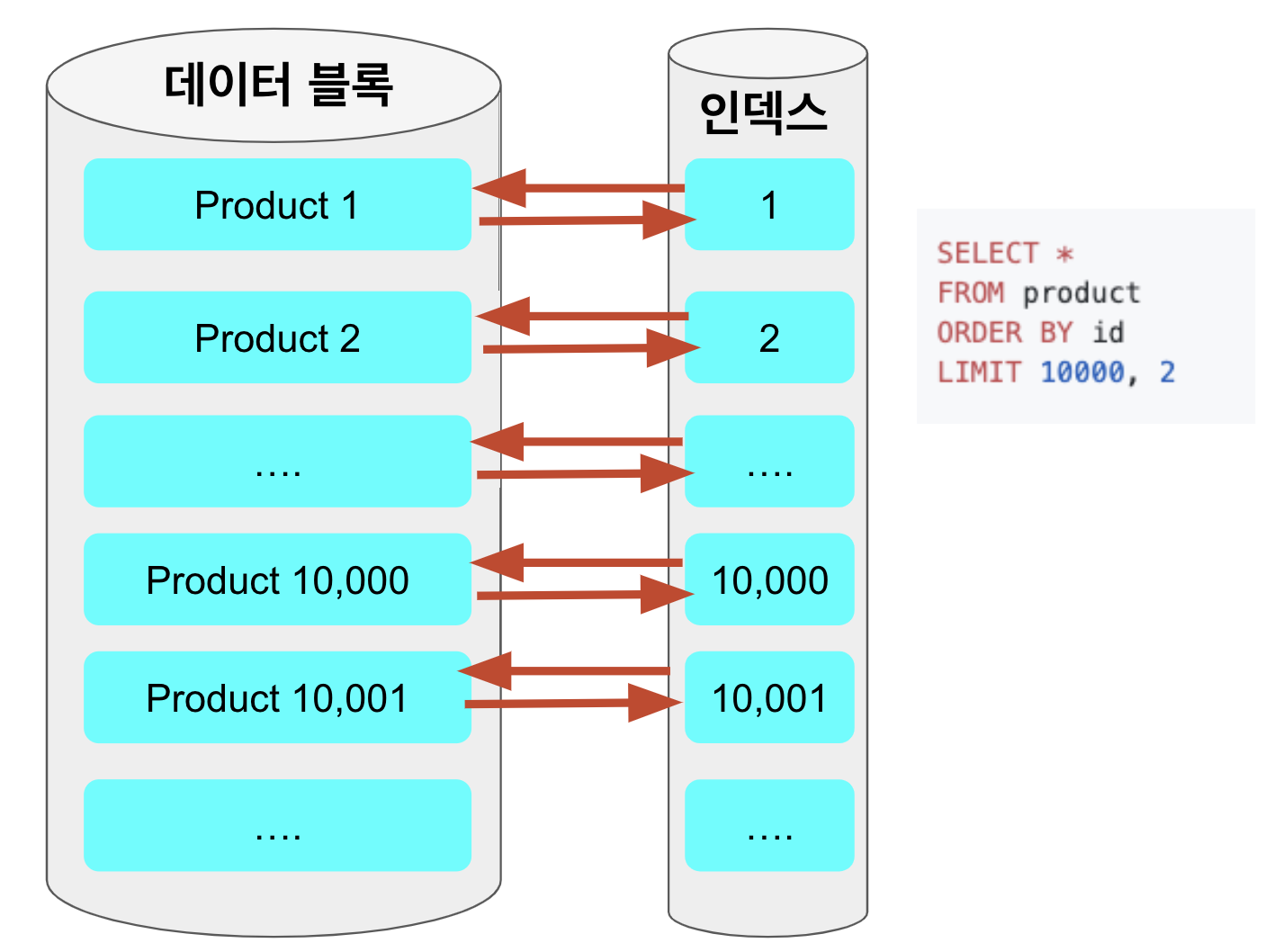
일반적으로 인덱스를 이용해 조회되는 쿼리에서 가장 큰 성능 저하를 일으키는 부분은 인덱스를 검색하고 대상이 되는 row의 나머지 칼럼값을 읽기 위해 데이터 블록에 접근하는 시간 때문이다.
우리 페이징 쿼리의 상황에서에 빗대면 커버링 인덱스를 태우지 않은 쿼리에서는 아래처럼 offset, offset ~limit을 수행할 때도 데이터 블록으로 접근을 하게 된다.
하지만 커버링 인덱스 방식을 이용하면, WHERE, ORDER BY, OFFSET ~ LIMIT과 같은 검색을 데이터 블록 접근 없이 인덱스 검색으로 빠르게 처리하고, 걸러진 ROW들에 대해서만 데이터 블록에 접근하기 때문에 성능의 이점을 얻게 된다.
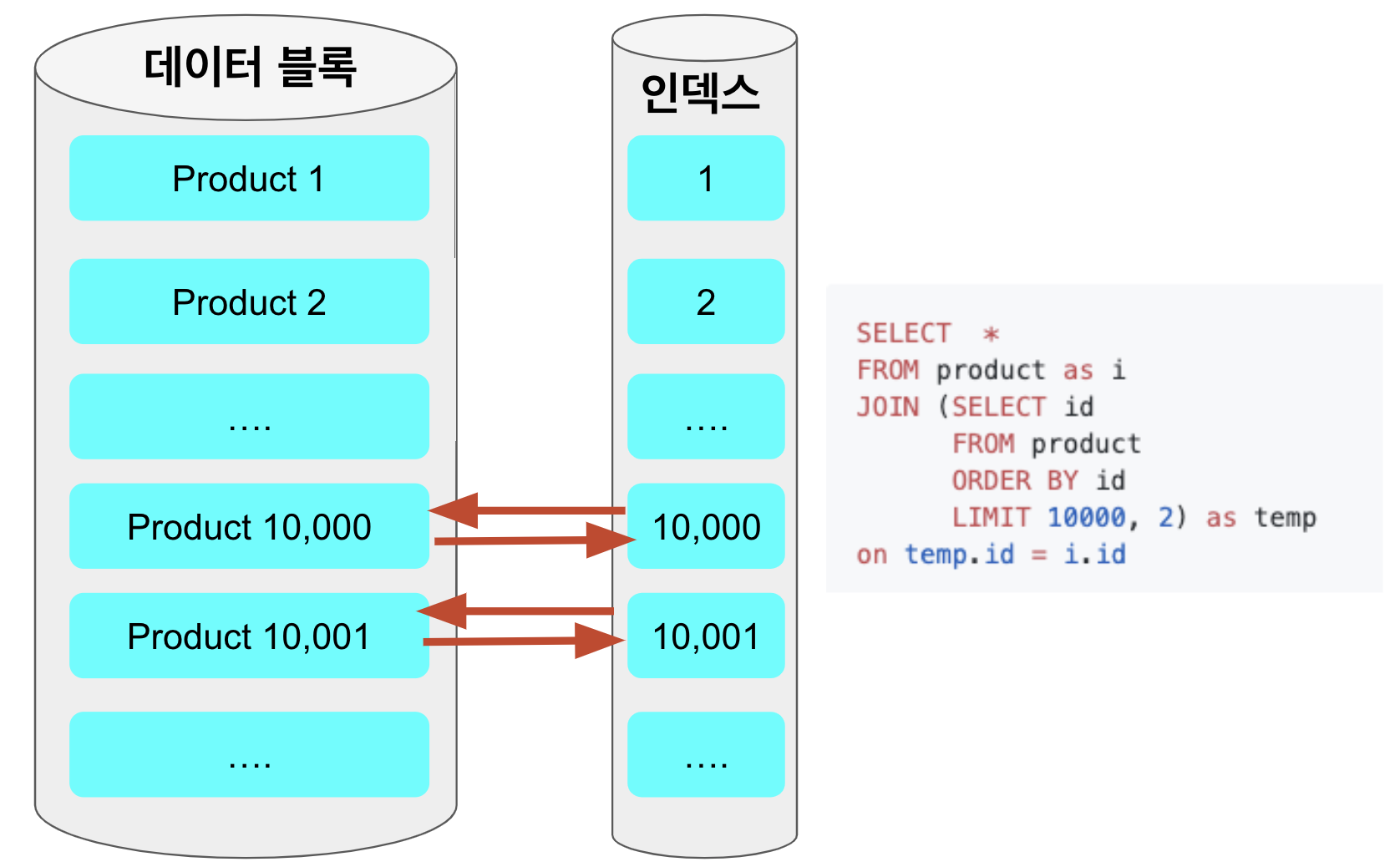
따라서 페이징 작업까지는 커버링 인덱스로 빠르게 처리후, 마지막 필요한 칼럼들만 별도로 가져오는 형태를 사용하면 문제를 해결할 수 있다.
