소개
Spring Batch 목표
- 스프링 배치 프레임워크 기능을 사용하여 비즈니스 로직에 집중한다.
- 즉시 사용할 수 있는 (Out-of-box) 실행 인터페이스 제공
- 인프라 계층과 구분되어 있음
Spring Batch 특징
- 스프링 배치는 스케줄링 프레임워크가 아니다.
- Quarts, @Scheduled, Crontab, Jenkins - 스프링 프레임워크가 제공하는 기능들
- 트랜잭션 관리
- Chunk 단위 프로세싱
- Start/Stop/Restart
- Retry/Skip
- Job 처리 통계
- 웹 기반 관리자 인터페이스 (Spring Cloud Data Flow)
Architecture & Domain Language
Architecture
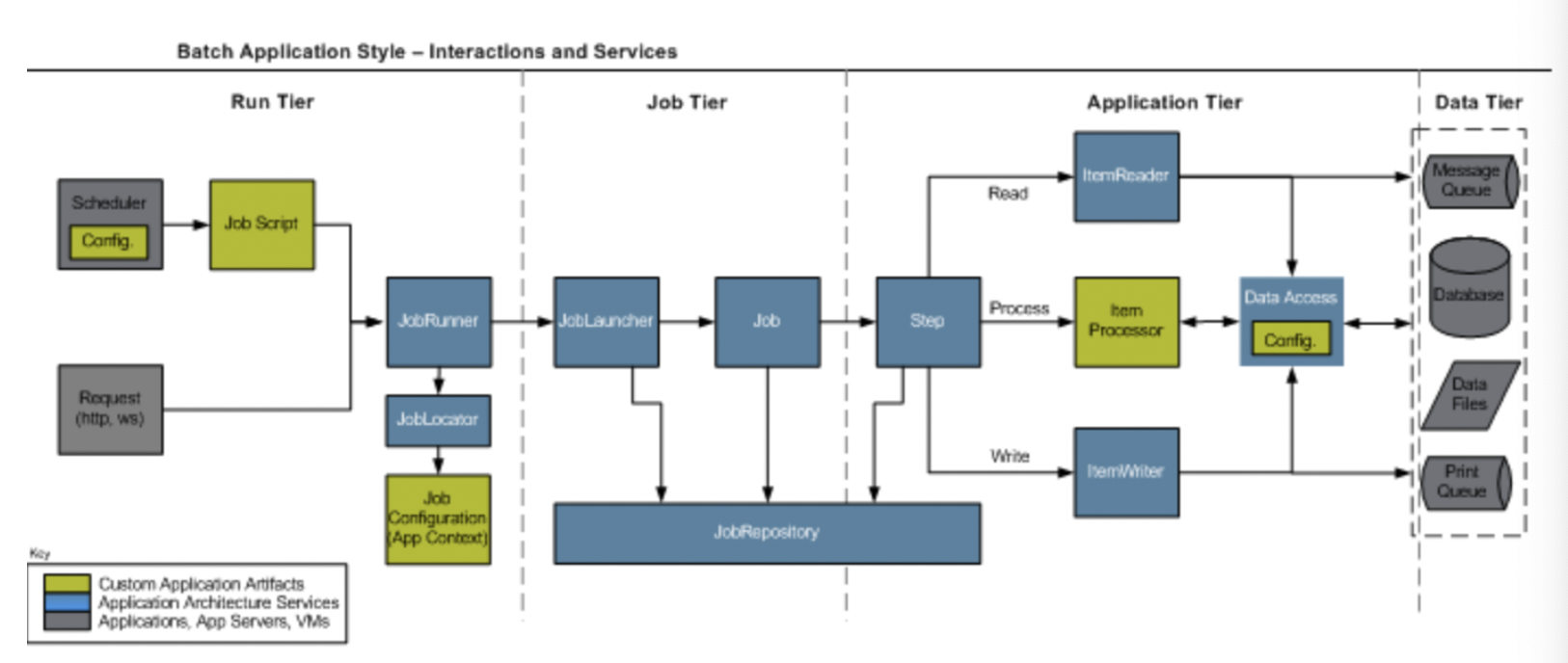
- Run Tier : 애플리케이션 시작과 관련된 계층
- HTTP 프로토콜을 사용하여 애플리케이션을 시작
- Scheduler를 사용하여 애플리케이션 시작 - Job Tier : 배치 프로세스를 담당
- Job, JobLauncher, JobRepository - Appication Tier : 배치 프로세스 구성요소들 및 비즈니스 로직 포함
- Step, ItemReader, ItemProcessor, ItemWriter, Tasket
Domain Language 소개
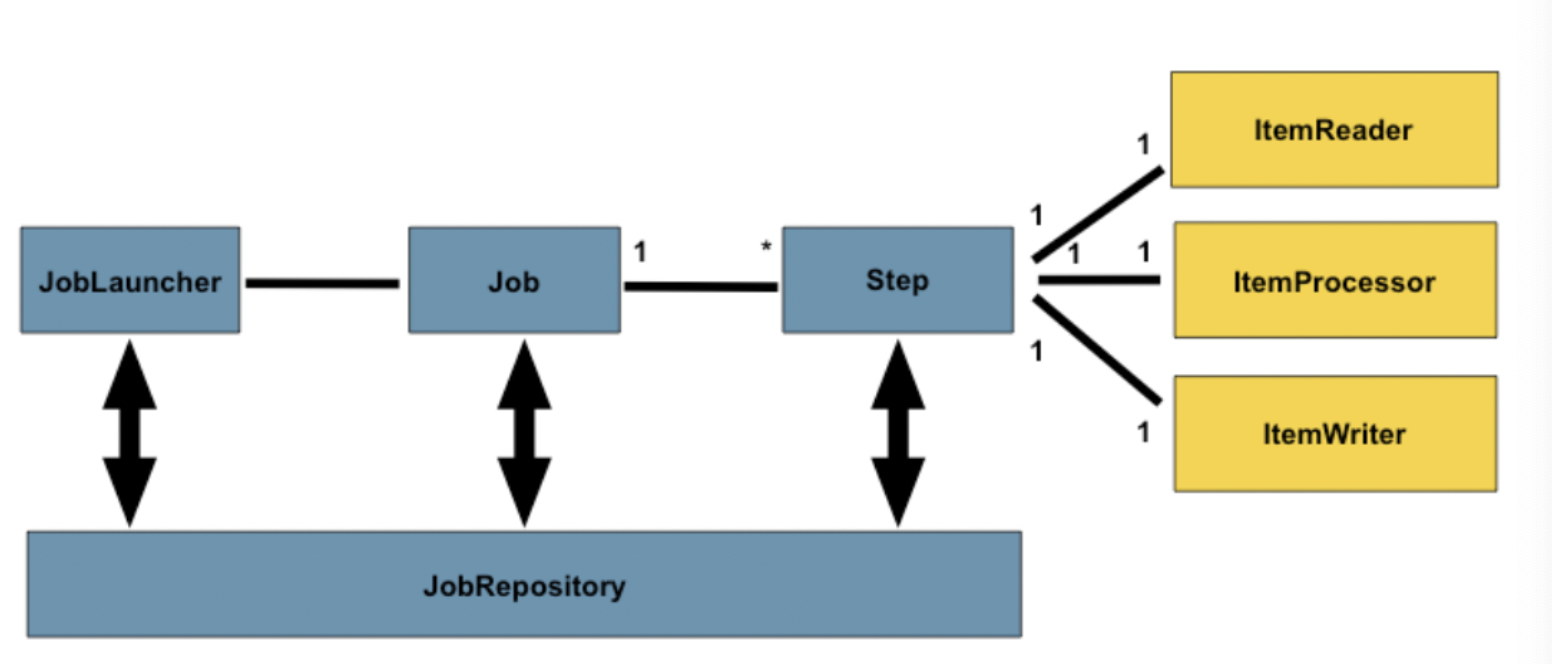
- 구성 요소들
- Job : 배치 처리 과정을 묶은 단위- Step : 배치 처리 과정
- Reader, Processor, Writer : Step을 구성하는 단계
- JobLauncher : 잡 실행
- JobRepository : 프로세스의 메타데이터 관리
스프링 배치 애플리케이션 코드
@EnableBatchProcessing
- 스프링 배치 프레임워크 기능 활성화
- 프레임워크에서 사용하는 기본 스프링 빈들을 생성
- 애플리케이션 내부에서 반드시 한번만 정의해야함
- JDBC 기반으로 사용하는 스프링 빈들을 구성
- 다음의 스프링 빈들 제공
- JobRepository, JobLauncher, JobRegistry, JobExplorer, JobOperator
- Spring Boot 3.0부터는
BatchAuthConfiguration.java에 의해 해당 어노테이션을 붙이면 중복 설정이 되므로 해당 어노테이션을 붙이지 않아도 된다.
DataSource, TransactionManager
@Configuration
public class DataSourceConfig {
@Bean
public DataSource dataSource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.url("jdbc:h2:tcp://localhost/~/batch")
.driverClassName("org.h2.Driver")
.username("sa")
.build();
}
}Job 구성
@Slf4j
@Configuration
@RequiredArgsConstructor
public class ItemJobConfig {
private final JobRepository jobRepository;
@Bean
public Job itemClickThroughRateJob() {
return new JobBuilder("itemClickThroughRateJob", jobRepository)
.preventRestart() // disable restartability
.start(itemClickStep()) // 시작 Step
.next(itemExposeStep()) // 다음 Step
.next(itemCtrProcessStep()) // 마지막 Step
.build();
}
//.....
}- batch.core.Job 스프링 빈을 생성해야 함.
- batch.core.job.builder.JobBuilder : Job을 생성하는 빌더 클래스
Step 구성
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
@Bean
public Step itemClickStep() {
return new StepBuilder("itemClickStep", jobRepository)
.chunk(3, transactionManager) // Chunk Oriented
.reader(accessLogReader()) // reader
.processor(clickLogFilterProcessor()) // processor
.writer(itemClickLogWriter()) // writer
.build();
}- batch.core.Step 스프링 빈을 생성해야함.
- batch.core.step.builder.StepBuilder : Step을 생성하는 빌더 클래스
Chunk Oriented Processing
- 트랜잭션의 효율을 높이기 위해서 Chunk 단위로 트랜잭션 처리
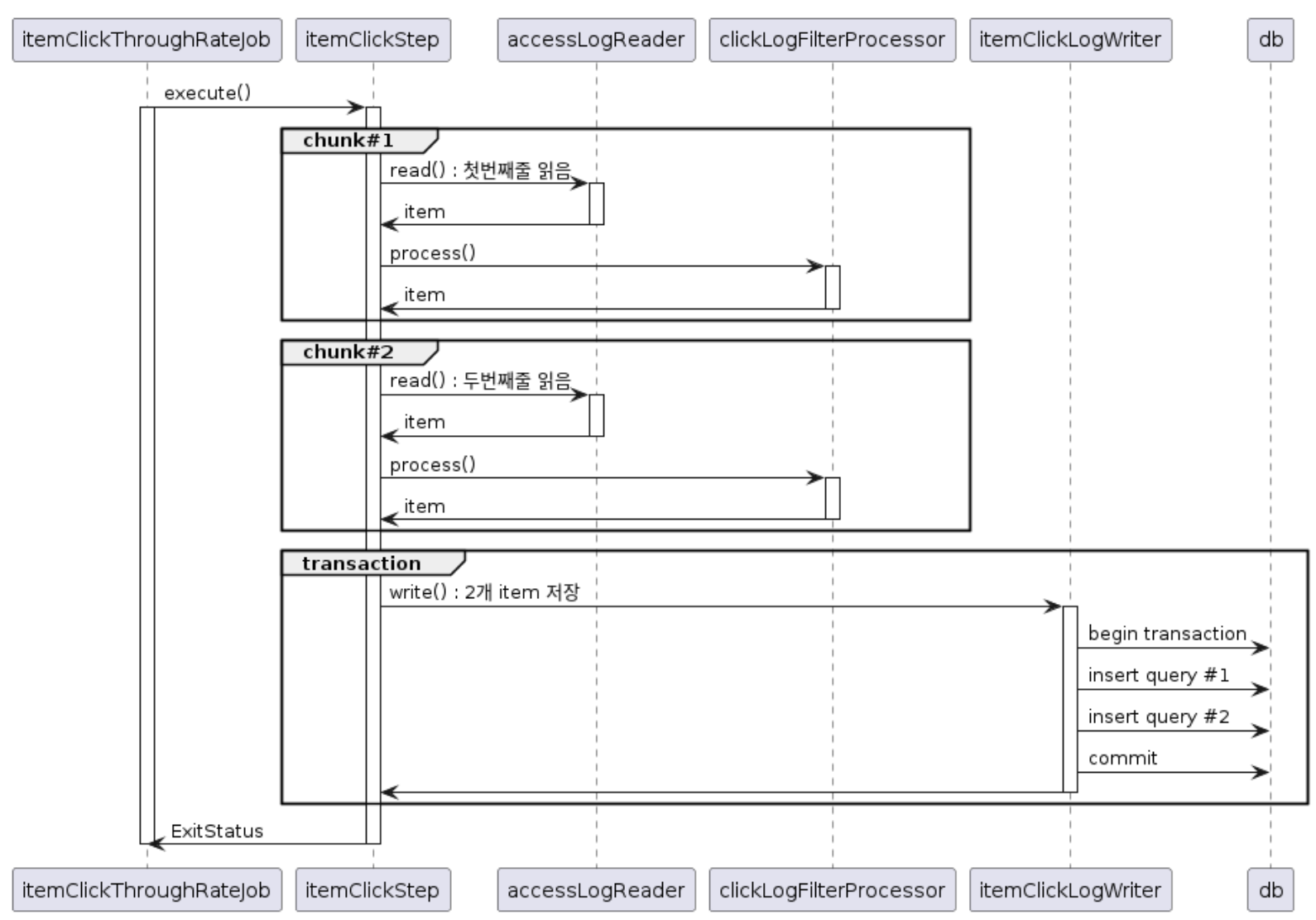
Reader, Processor, Writer 구성
@Bean
public ItemReader<AccessLog> accessLogReader() {
FlatFileItemReader<AccessLog> accessLogFileReader = new FlatFileItemReader<>();
accessLogFileReader.setResource(new ClassPathResource("/item/access.log"));
accessLogFileReader.setLineMapper(accessLogLineMapper);
return accessLogFileReader;
}
LineMapper<AccessLog> accessLogLineMapper = (line, lineNumber) -> {
try {
return new AccessLog(line);
} catch (Exception e) {
log.error("error processing line:{} = {},e", lineNumber, line, e);
throw e;
}
};
@Bean
public ItemProcessor clickLogFilterProcessor() {
return new ClickLogFilterProcessor();
}
@Bean
public ItemWriter<ItemClickLog> itemClickLogWriter() {
FlatFileItemWriter<ItemClickLog> writer = new FlatFileItemWriter<>();
writer.setName("itemClickLogWriter");
writer.setResource(new FileSystemResource("~/output/clickLog.json"));
writer.setLineAggregator(memberAggregator);
return writer;
}initialize-schema
spring.batch.jdbc.initialize-schema=always
- 로컬에서 위 설정을 application-properties에 넣지 않으면 에러가 발생한다.
- Job Tier와 Application Tier에 실행되는 모든 과정들이 JobRepositry에 저장되고 상태를 조회하는데 해당 작업을 위한 테이블이 존재해야 한다. (위 설정)
Spring Batch Meta-data
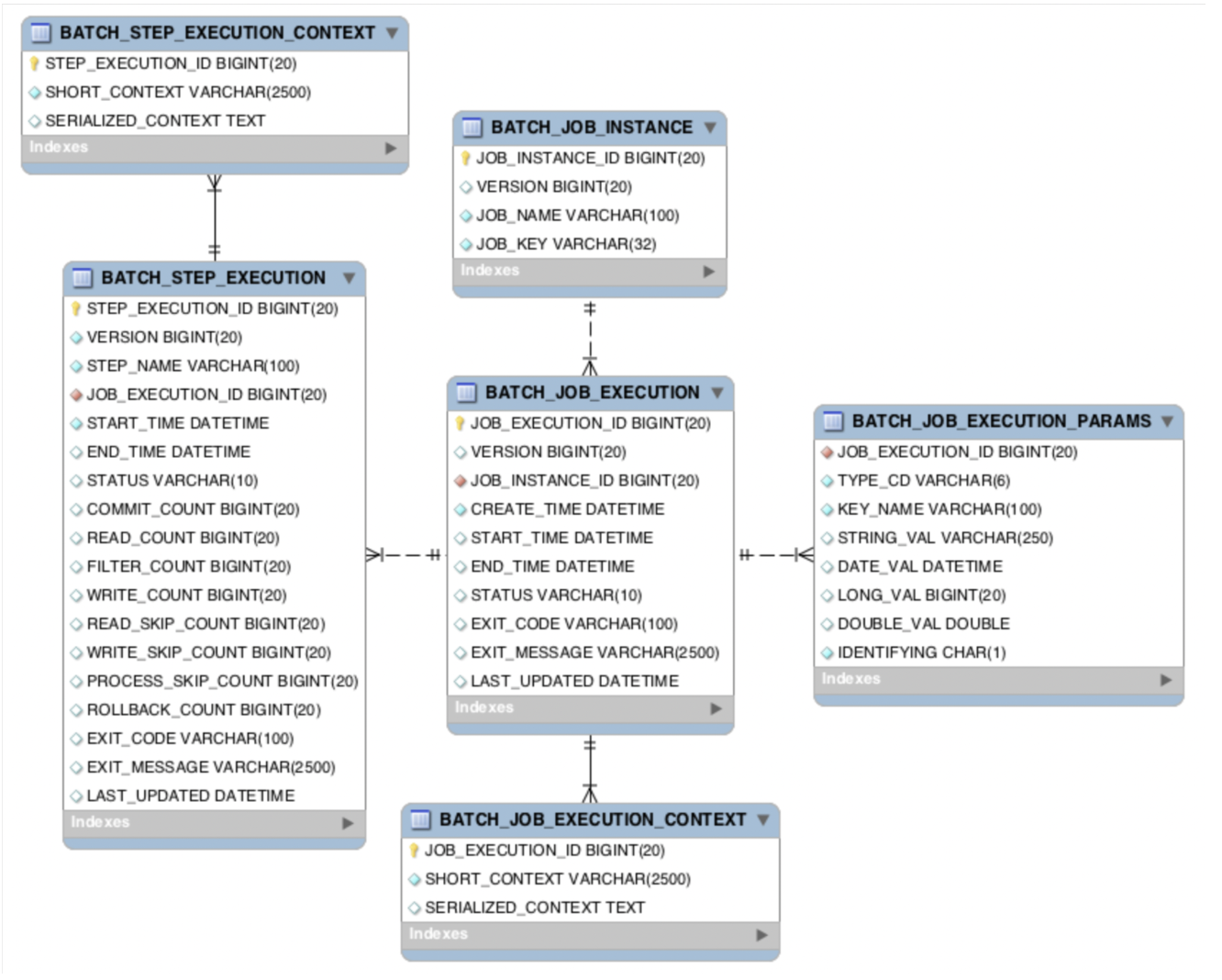
- 스프링 배치 애플리케이션 메타 정보들을 저장하기 위에 위와 같은 테이블들이 필요하다.
-spring.batch.jdbc.initialize-schema=always
- 계정에 DDL 권한이 있어야함.
- 따라서 보통 리얼에는 위 설정을none으로 두고 테이블을 미리 생성해줘야함.
JobRepository
- Spring Batch Core 프레임워크에서 제공
- JobRepository 인터페이스
- SimpleJobRepositry 클래스
datasource스프링 빈과transactionManager스프링 빈을 사용하여 처리
Job, Step, Tasklet, Reader, Writer
Job
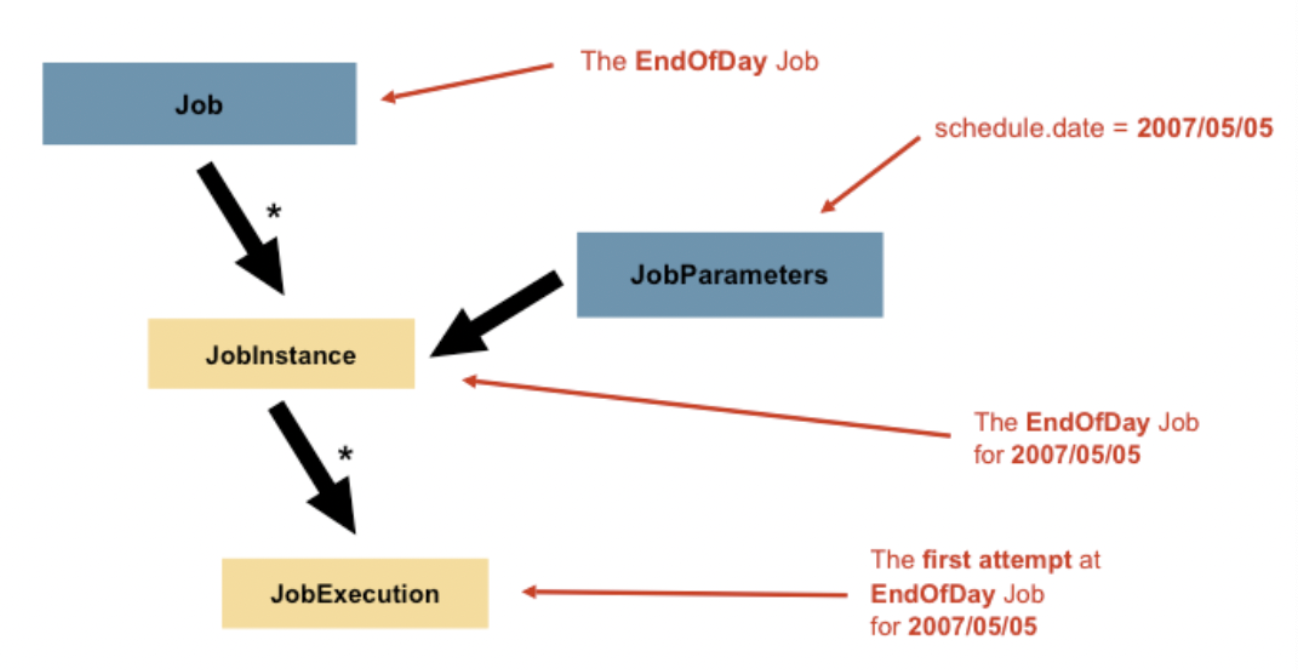
- 일반적으로 Job은 배치프로세스를 캡슐화한 엔티티를 의미
- 스프링 배치 프레임워크에서 Job은 Step 인스턴스들의 단순 컨테이너이다.
- Job 설정은 다음과 같이 구성된다.
- Job 이름, Step 인스턴스 순서 정의, 재시작 여부
JobInstance
- JobInstance : 논리적인 작업(Job) 실행을 의미
- JobExecution : JobInstance의 작업 실행을 의미
- JobInstance : JobExecution = 1 : N
- select * from BATCH_JOB_INSTANCE
JobParameters
- Job과 JobInstance의 차이 : JobParameters
- JobParameters는 배치 작업을 실행할 때 사용되는 파라미터의 집합을 저장한 객체
- JobInstance = Job + identifying JobParameters
JobExecution
- JobExecution은 Job을 실행하는 시도를 의미함
- JobExecution은 실행중에 발생한 일을 저장하는 메커니즘을 제공한다.
JobExecution Properties
Status: 시작, 실패, 완료startTime,endTime,exitStatus,createTime,lastUpdatedexecutionContext: 실행 간에 유지되어야 하는 사용자 데이터가 포함된 속성 모음failureExceptions: 실행 중 발생한 예외 목록
Step
- Job을 구성하는 하나 이상의 단계를 의미
- Step은 독립적이며, 연속해서 구성할 수 있다.
- Job은 하나 이상의 Step들로 구성한다.
- 실제 비즈니스 로직을 포함한다.
Step Execution
- org.springframework.batch.core.StepExecution.java
- Step을 실행하는 것을 표현하기 위한 클래스, Step이 실행되면 객체가 생성된다.
- SELECT * FROM BATCH_STEP_EXECUTION
StepExecution Properties
Status,startTime,endTime,exitStatusexecutionContext,readCount,writeCount,CommitCount,rollbackCountreadSkipCount,processSkipCount,writeSkipCount
ItemReader, ItemWriter
Reader
- batch.item.Reader
- 데이터 읽기 기능을 추상화한 인터페이스
- 데이터를 한건, 한건씩 읽는다.
- null을 리턴하면 읽기를 멈춘다. - 유용한 구현체
- AmqpItemReader : AMQP 메시지큐에서 메시지를 읽는다.- FlatFileItemReader : 파일에서 한 라인씩 데이터를 읽는다.
- JdbcPagingItemReader : JDBC를 사용해 데이터베이스에서 페이징 단위로 레코드를 읽는다.
Processor
- batch.item.Processor
- 데이터를 변환/처리하기 위해 제공하는 인터페이스
- null을 리턴하면 해당 데이터는 처리하지 않는다.
Writer
- batch.item.Writer
- 유용한 ItemWriter 구현체
- AmqpItemWriter
- FlatFileItemWriter
- KafkaItemWriter
- JpaItemWriter
- JdbcBatchItemWriter
JdbcPagingItemReader & JdbcBatchItemWriter
JdbcPagingItemReader
- 데이터 베이스 작업을 할 때 가장 많이 사용되는 구현체
- JdbcCursorItemReader
- 커서 기반으로 데이터 입력 (ResultSet.next())
- 커서 이동은 fetchSize 설정값을 사용하여 프레임워크가 자동 실행 - JdbcPagingItemReader
- 페이징 기반으로 데이터 입력
- 페이지 이동은 각 데이터베이스에 적합 형태로 프레임워크가 변환
- pageSize : 페이지 크기
- fetchSize : 페이지 결과 내에서 fetch할 갯수
- pageSize == chunkSize == fetchSize - Cursor 기반 ItemReader 구현체 단점
- DB Connection을 유지한 채로 ResultSet.next()를 사용
- SocketTimeout 발생 가능
- Paging 기반은 쿼리 실행 후 DB Connection을 반환한다.
//JdbcPagingItemReader
@Bean
public JdbcPagingItemReader<WeeklyStat> aggregatedWeeklyStatReader() throws Exception {
Map<String, Object> paramValues = Map.of(
"startDate", "20230101",
"beginDate", "20230101",
"endDate", "20230107");
return new JdbcPagingItemReaderBuilder<WeeklyStat>()
.pageSize(PAGE_SIZE)
.fetchSize(PAGE_SIZE)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(WeeklyStat.class))
.queryProvider(createQueryProvider())
.parameterValues(paramValues)
.name("dailyStatReader")
.build();
}
//JdbcCursorItemReader
@Bean
public JdbcCursorItemReader<WeeklyStat> weeklyStatReader() {
return new JdbcCursorItemReaderBuilder<WeeklyStat>()
.fetchSize(10)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(WeeklyStat.class))
.sql("SELECT STAT_DATE, ITEM_ID, CLICK_COUNT, EXPOSE_COUNT, CTR FROM STAT_WEEKLY")
.name("weeklyStatReader")
.build();
}JdbcBatchItemWriter
@Bean
public ItemWriter<WeeklyStat> weeklyStatWriter() {
String sql = "insert into STAT_WEEKLY(STAT_DATE, ITEM_ID, CLICK_COUNT,EXPOSE_COUNT, CTR) "
+ "values "
+ "(:statDate, :itemId, :clickCount, :exposeCount, :ctr)";
return new JdbcBatchItemWriterBuilder<WeeklyStat>()
.dataSource(dataSource)
.sql(sql)
.beanMapped()
.build();
}Job 설정
설정#1 - preventRestart()
- 여러 step을 연결해서 하나의 Job으로 구성하는 경우
- restartability
- 특정 JobInstance에 대한 JobExecution이 존재하면 해당 Job은 재시작된다.
- preventRestart() 설정 후, 재시작하면 JobRestartException 발생 - 완료된 스탭을 항상 다시 실행하고 싶다면?
- 데이터를 초기화하는 스탭
- StepBuilder의 allowStartIfComplete() 메서드를 사용한다.
설정#2 - Job 실행방법
1) applecation.properties에서 job 이름 설정
spring.batch.job.name={잡이름}spring.batch.job.enabled=true(default)
- applicationContext가 기동될 때 모든 Job을 실행한다.
2) program argument를 사용하여 실행
--spring.batch.job.name={잡이름}
3) JobLauncher를 사용하는 방법
spring.batch.job.enabled=false- JobLauncher Bean을 사용한다.
JobLauncher jobLauncher = ctxt.getBean(JobLauncher.class);
Job weeklyStatJob = ctxt.getBean("weeklyStatJob", Job.class);
jobLauncher.run(weeklyStatJob, new JobParametersBuilder().toJobParameters());4) @Scheduled를 사용하는 방법
- HA 구성을 하려면? redis를 사용한 Shared Lock
@Scheduled(cron = "0/10 * * * * *")
public void launchWeeklyStatJob() {
try {
System.out.println("Launch WeeklyStatJob --------------------------------------");
jobLauncher.run(weeklyStatJob(null), new JobParameters());
} catch (Exception e){
// Error Handling
}
}5) Rest API를 사용하는 방법
spring.main.web-application-type=servlet
@RestController
public class JobLaunchController {
@PostMapping("/v1/jobs/weeklyStat/execute")
public void launchWeeklyStatJob() {
try {
jobLauncher.run(weeklyStatJob(null), new JobParameters());
} catch (Exception e){
// Error Handling
}
}
}6) Crontab을 사용하는 방법
$ crontab -l
35 * * * * /home1/irteam/apps/job/weeklyStatJob.sh
$ cat /home1/irteam/apps/job/weeklyStatJob.sh
#!/bin/bash
/home1/irteam/apps/jdk/bin/java -Dspring.profiles.active=real -jar /home1/irteam/apps/job/JOB-SNAPSHOT.jar --spring.batch.job.name=weeklyStatJob > error.log 2>&1 &7) 외부 애플리케이션의 도움을 받는 방법
- Jenkins
- Spring Cloud DataFlow Scheduler
설정#3 - 파라미터 전달
- Parameter가 같은 Job은 다시 실행하지 않는다.
- Parameter를 추가하는 방법
- Program argument를 사용하여 실행하는 방법
- JobParameters 객체를 사용하는 방법
- JobParameter가 지원하는 데이터 타입
- JobParameterValidator를 사용하여 검증하는 방법
- JobParameter를 검증하는데 사용한다.
- JobParametersValidator 인터페이스 구현체를 생성한다.
- 생성한 구현체를 JobBuilder의 validator() 메서드를 사용하여 등록한다.
@Bean public Job weeklyStatJob(Step aggregateWeeklyStatStep) { return new JobBuilder("weeklyStatJob", jobRepository) .start(aggregateWeeklyStatStep) .validator(new WeeklyStatJobValidator()) .build(); }
설정#4 - 파라미터 사용
- @Value + SpEL을 사용하여 JobParameter 객체의 속성을 참고하여 주입할 수 있다.
@Bean
@StepScope
public JdbcPagingItemReader<WeeklyStat> aggregatedWeeklyStatReader(
@Value("#{jobParameters[beginDate]}") String beginDate,
@Value("#{jobParameters[endDate]}") String endDate
) throws Exception {
// .....
}@JobScope @StepScope
- Spring Framework의 기본 Scope는
SingleTon, Prototype스코프 존재 - Spring Batch에서 제공하는 추가 Scope
- @JobScope는 Step에서만 사용 가능
- @StepScope는 Step을 구성하는 Reader, processor, writer에서 사용 가능
- 각각의 시점에 지연되어 생성됨.
- 그러므로 singleton으로 생성한 객체는 Step에 주입될 수 없어서 반드시 @StepScope를 정의해야함.
설정#5 - Job 이벤트 사용
- 배치 Job 실행 전/후에 이벤트를 등록해서 특정 로직을 실행할 수 있다.
- JobExecutionListener 인터페이스를 구현하는 방법 (beforeJob, afterJob 메서드 구현)
- @BeforeJob, @AfterJob 애너테이션을 사용하는 방법
여러 이벤트들
- Job 실행 전/후 이벤트
- StepExecutionListener
- @BeforeStep, @AfterStep
- Chunk 실행 전/후/에러 이벤트
- ChunkListener
- @BeforeChunk, @AfterChunk, @AfterChunkError
- ItemReader의 read() 메서드 전/후/에러 이벤트
- ItemReadListener
- @BeforeRead, @AfterRead, @OnReadError
- ItemProcessor의 process() 메서드 전/후/에러 이벤트
- ItemProcessorListener
- @BeforeProcess, @AfterProcess, @OnProcessError
- ItemWriter의 write() 메서드 전/후/에러 이벤트
- ItemWriteListener
- @BeforeWrite, @AfterWrite, @OnWriteError
- SkipListener, RetryListener
인메모리 JobRepository 구성
-
데이터베이스를 사용하여 배치 Job의 정보를 저장할 필요가 없는 경우, In-Memory를 사용할 수 있다.
- 너무 많은 배치잡을 사용하여 메타데이터 테이블이 너무 커지는 경우
- 스프링 배치의 Restartability를 사용할 필요가 없는 경우
- 성능 향상
-
Spring Batch 5.0 이전 :
DefaultBatchConfiguere의createJobRepository()오버라이드하여 JobRepository를 MapJobRepositoryFactoryBean으로 교체 -
Spring Batch 5.0 이상 : JobRepositoryFactoryBean with an in-memory database 사용을 권장
Tasklet
- Reader, Processor, Writer 설정하는 것은 번거로움
- 간단한 작업이나 간단한 메서드들을 사용하면 하나의 스탭을 구성할 수 있을때 사용한다.
- 각 Tasklet은 트랜잭션으로 감싸짐
package org.springframework.batch.core.step.tasklet;
@FunctionalInterface
public interface Tasklet {
@Nullable
RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}RepeatStatus
- 끝내는 경우 RepeatStatus.FINISHED 리턴
- 반복 수행하는 경우 RepeatStatus.CONTINUABLE 리턴
ExecutionContext
- org.springframework.batch.item.ExecutionContext
- JobExecutionContext
- Step끼리 공유할 수 있는 데이터
- 이전 스탭과 다음 스탭 사이에 데이터를 공유
- StepExecutionContext
- Step 내부에서 공유할 수 있는 데이터
- 데이터베이스에 VARCHAR(2500)에 저장되기 때문에 너무 큰 데이터는 넣기 힘들다
