시세 정보
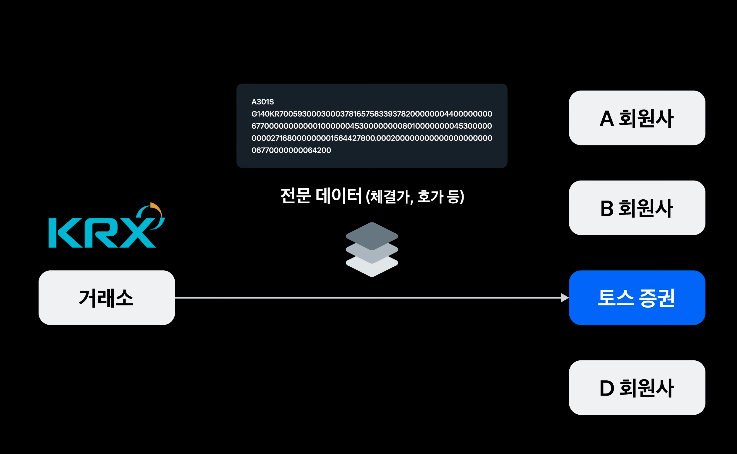
시세 정보는 거래소로부터 실시간으로 정보를 받는다.
아무래도 시세 정보를 다루려면 실시간으로 다루어야 하기 때문에,
낮은 지연시간, 빠른 장애 복구
를 우선시 해야한다.
토스의 시세정보 처리 과정을 살펴보겠다.
-
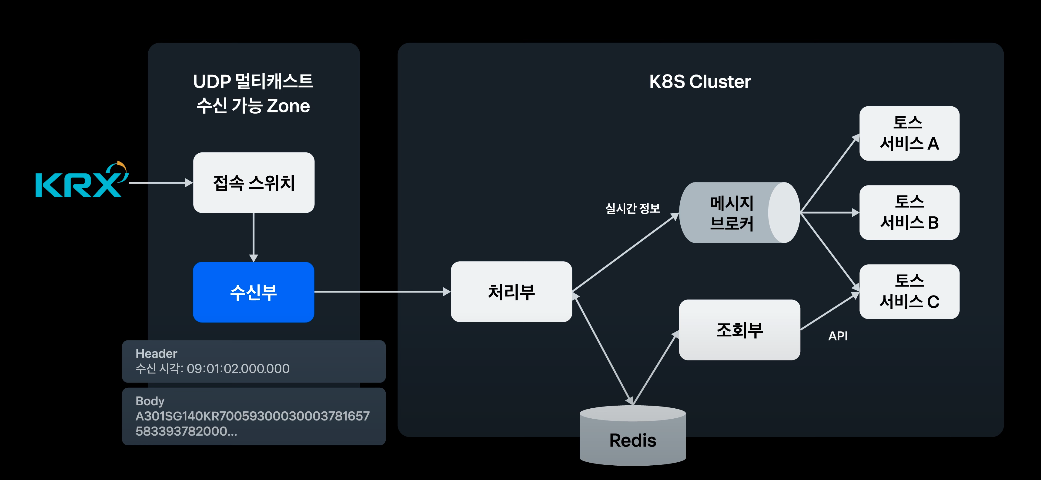
거래소로부터 받아오는 시세 정보를 UDP 멀티캐스트 그룹에 접속해서 읽어온다.
빠른 통신을 위해서 UDP를 사용하는 것 같다.
이 때, 헤더에 수신 시각을 포함하여 처리부에서 총 처리 시간을 측정한다. -
처리부가 Redis에 저장하고, REST API를 제공한다.
처리부가 비지니스 로직이 가장 많기 때문에 장애 발생 확률이 가장 높다.
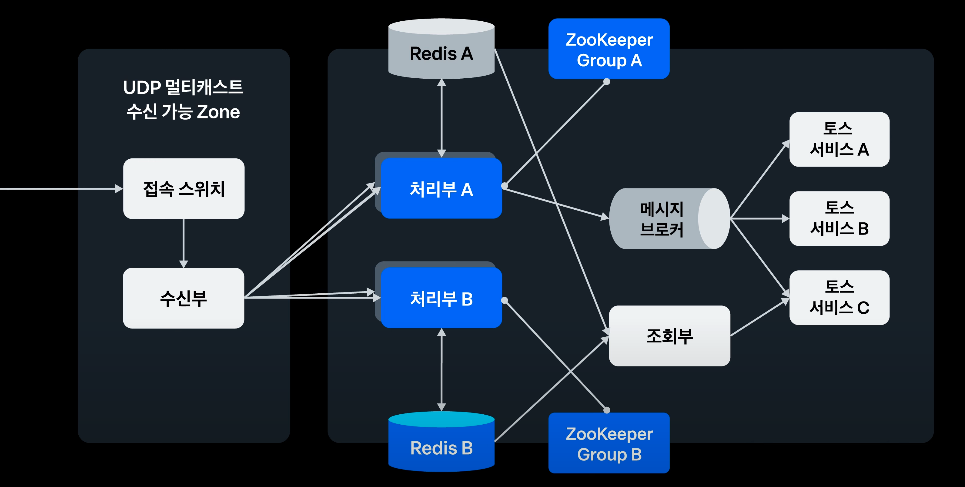
따라서, 처리부를 여러개로 늘리는 방법을 선택했다.
평소에는 한 처리부(처리부 A)를 가동하다가, 장애가 발생하면 빠르게 처리부 B로 전환할 수 있다.
ZooKeeper를 통해 리더를 선출하고, 각 리더만 DB접근을 허용해 데이터 중복을 막을 수 있다.
이 방법은 배포 부담감도 줄일 수 있으며, 장애 발생을 대비할 수 있다.
하지만, 처리부가 늘어나면서 수신부가 보내야 하는 데이터의 부담감이 늘어났다.
처리부의 개수만큼 보내주어야 하기 때문이다.
이를 해결하기 위해 메시지 브로커를 사용한다.
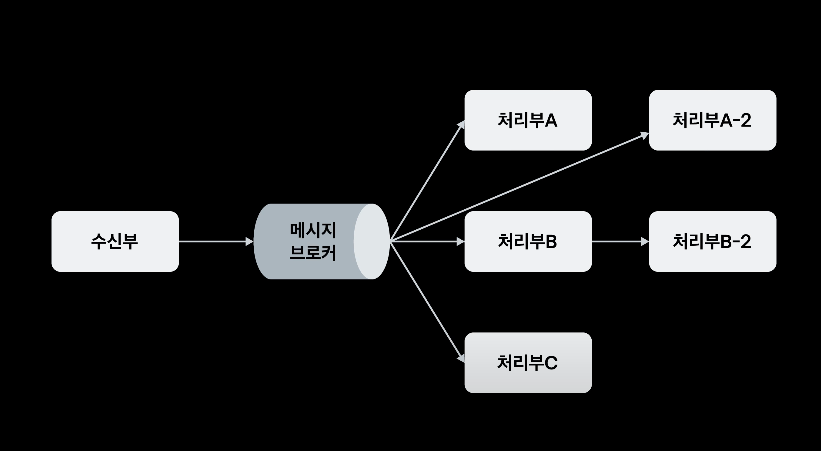
메시지 브로커를 통해 수신부와 처리부를 독립화하고, 수신부는 데이터를 한 번만 전송해도 된다.
그렇다면, 메시지 브로커가 지연시간을 줄이기 위해 선택할 목록을 살펴보자.
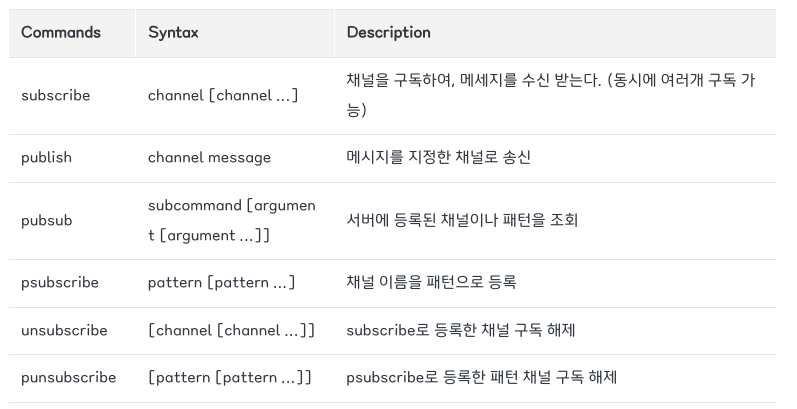
- UDP 멀티캐스트
보통 비디오 스트리밍, 게임 등 실시간 데이터를 사용하는 서비스에 많이 이용된다. 라우터 설정, 배포 설정이 필요하다. - Kafka
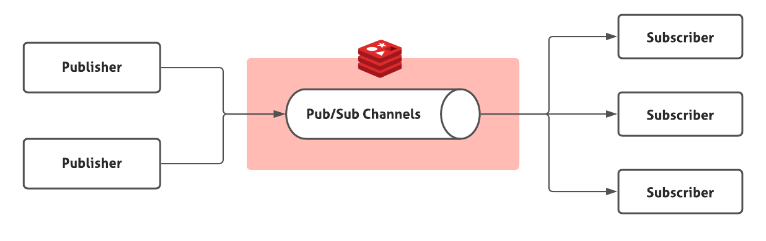
현업에서 많이 사용하는 분산형 데이터 스트리밍 플랫폼. - Redis Pub/Sub
Redis Publish/ Subscribe. 말 그대로, 특정한 주제를 구독한 수신자들에게 메시지를 발행하는 통신 방법이다.
3번의 지연시간이 가장 낮아서 선택하게 됐다고 한다.
Redis Pub/Sub
Redis Publish/Subcribe
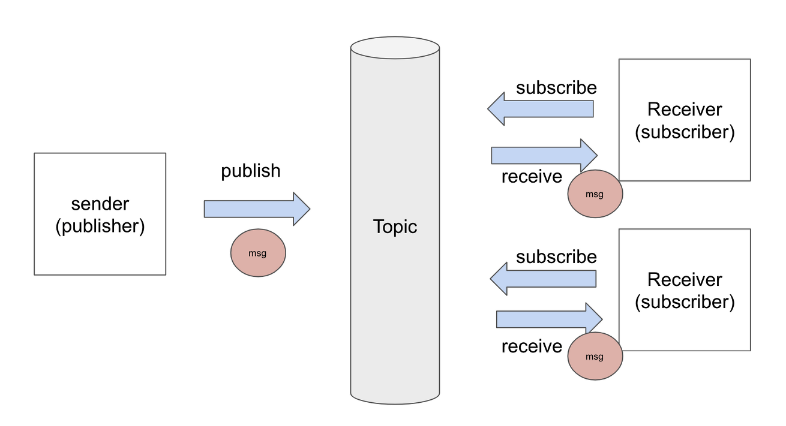
Publish/Subscribe 구조에서 사용되는 Queue를 일반적으로 Topic이라고 한다.
주제라고 생각하면 될 것 같다.
보통은 채팅 기능이나, 푸시 알림 등에 많이 이용된다. 단순하게 sender가 특정 데이터를 publish하면, sender를 subscribe한 receiver가 데이터를 받으면 되기 때문이다.
이러한 pub/sub 시스템은 매우 단순한 구조로 되어있다.
메시지를 따로 보관하지 않으며, 상대가 메시지를 받았지를 확인하지도 않는다.
Redis는 In-Memeory 기반이기 때문에 웹 소켓을 이용한 시스템보다 훨씬 빠르다.
Event Loop
처리부에서는 Reid Pub/Sub과 TCP 연결을 맺으면서 TCP Flow Control을 수행함에 따라 많은 지연시간을 고려할 수밖에 없다.
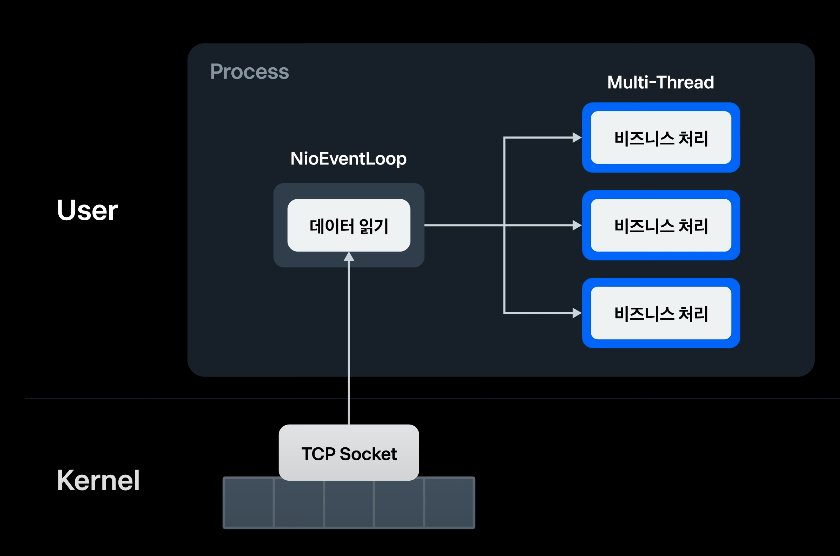
그렇기 때문에, 비지니스 로직을 포함하는 처리부와 데이터를 읽어오는 처리부에게 별도 스레드를 위임하는 것이 좋다.
그런데 이렇게 멀티 스레딩을 사용한다면, 시간 상 처리되어야 할 로직이 역전될 수 있다.
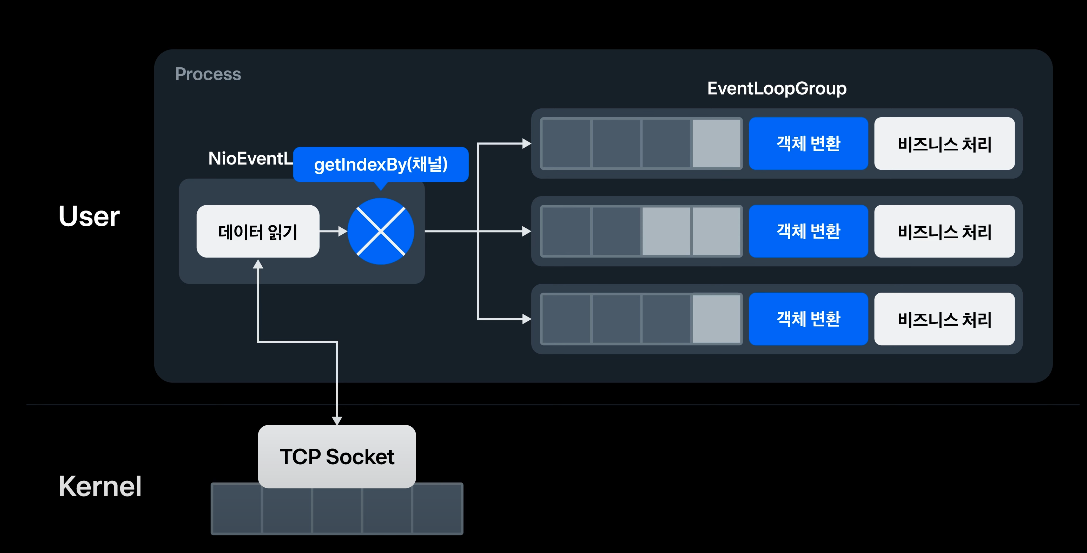
그래서 EventLoopGroup을 사용하여 Queue를 이용해 순서를 보장한 모습이다.
Event Loop 구현
이 EventLoop는 Spring의 ThreadPoolTaskExecutor를 사용하고,
corePoolSize = 1
maxPoolSize = 1
를 설정하여 만들 수 있다.
실시간성을 고려해서, Queue가 꽉 찰 경우 DiscardOldestPolicy을 채택하여 오래된 작업을 지우는 방식을 사용하는게 유리하다고 볼 수 있다.
QueueCapacity는 너무 크면 실시간성이 떨어질 수 있고, 너무 작으면 데이터가 몰리는 시간에 지연이 많아질 수 있다. 이에 따라 적당하게 조절해야 한다.
List<ThreadPoolTaskExecutor>ThreadPoolTaskExecutor를 List 형태로 만든다.
여기서 List의 개수 = EventLoop 개수 를 뜻한다.
EventLoop의 개수가
늘어날 수록 : 많은 Context Switch 성능 떨어짐
너무 작으면 : EventLoop에 BackPressure 발생, 지연 시간 늘어남
-> 목표 트래픽을 발생시키며 모니터링 하여 적절한 수를 찾았다고 한다.
Lettuce
Spring Data Redis가 제공하는 Redis Client 라이브러리
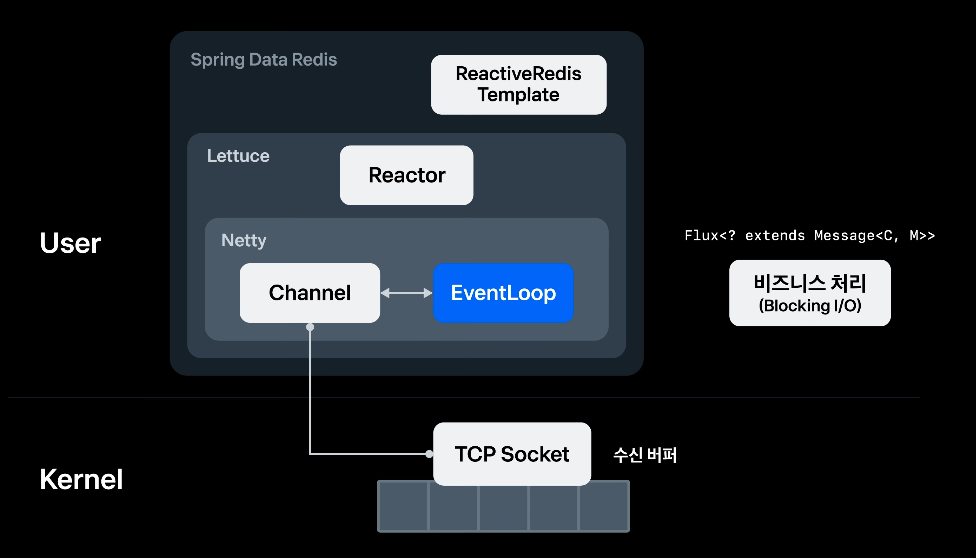
네트워크 라이브러리인 Netty를 사용하고, Netty의 Channel은 Socket을 추상화한 레이어이다.
커넥션이 맺어진 이후 EventLoop에 등록 된다.
Event Loop가 무한 루프를 돌면서 수신 버퍼의 데이터를 읽는다.
