소개글
각종 컨퍼런스에 나온 강연들을 정리해보면서 공부해보고 있습니다.
이번 포스팅은 if(kakao) 2022에서 이다니엘님께서 강연해주신 내용을 정리했습니다.
제목은 "딥(Deep)하게 오타 교정하기"이며 기존 오타 교정에 대한 문제와 딥러닝으로 이를 해결한 방법에 대한 내용입니다.
말투는 편한 말투로 작성하니 양해 부탁드립니다.
발표내용
오타 교정을 아시나요?
오타란?
- 타자기나 컴퓨터 따위로 글자를 칠 때 잘못 치는 일
- 의도와 다른 입력
- 올바르게 입력된 경우는 정타라고 함
검색에서 오타는?
- 일반적인 맞춤법 오류와는 다름
- 검색을 이용하는 사용자의 목적이 중요
- 맞춤법에 맞지 않는 검색어라도 오타가 아닐 수 있음 (예: 블럭)
블럭은 비표준어고 블록이 실제 맞는 말이지만, 블럭으로도 많이 사용하기 때문에 검색에서는 오타가 아니라고 합니다.
검색어 오타 교정이란?
- 스펠러(Speller) 라고도 함
- 검색어에 대해 오타인지 판별하고, 오타인 경우 적절한 정타로 교정하는 것
- 잘못 입력된 검색어라도 적절한 검색 결과 제공을 위해 검색어 오타 교정은 꼭 필요한 서비스
오타 유형 정리
- 단순 입력 오류
- 규칙성이 없는 단순한 입력 오류
- 카톡 / 까톡, 카턱
- 문자 변환 오류
- 한글이 영어로, 또는 영어가 한글로 변환된 오류
- 카카오 / zkzkdh
- 맞춤법 오류
- 맞춤법 표기법에 어긋난 오류
- 육개장 / 육계장
- 외래어 표기 오류
- 외래어 표기법과 관련된 오류
- 문화센터 / 문화센타
- 잘못된 배경 지식으로 인한 오류
- 잘못된 정보로 발생한 오류
- 광교 갤러리아 백화점 / 판교 갤러리아 백화점
잘못된 배경 지식으로 인한 오류는 데이터가 적고, 컨텍스트를 학습하기 어렵기 때문에 이를 제외한 나머지 오류 유형을 해결하고자 함
기존 서비스의 문제
스펠러는 다음 검색, 카카오톡, 멜론, 다음 지도 등 다양한 곳에 적용되어 있음
기존 스펠러 구조
- 노이즈 채널을 이용한 통계 기반 오타 교정 모델
- 노이즈 채널 모델이란?
- 오류 모델, 언어 모델의 곱 결과에서 가장 큰 확률값을 가지는 결과를 정타 후보로 예측
- 오류 모델은 오타에 대한 정타 후보들의 교정 확률을 계산
- 언어 모델은 정타 후보들의 단어 시퀀스 확률을 계산

기존 스펠러 단점
교정 커버리지가 낮음
- 교정 대상 중 교정한 비율
- 높은 교정 정확률을 위해 제한된 편집 거리 사용
교정 정확률
- 교정 결과가 정답인 비율
- 오교정이 치명적인 스펠러 특성상 매우 중요
편집 거리
- 한 문자열에서 다른 문자열로 변환시 연산 횟수
- <abc, abd>의 편집 거리는 1
개선 방법
- 기존 서비스의 단점들을 딥러닝 모델을 이용해 해결해보고자 함
- 오타 교정: 오타로부터 정타를 생성하는 문제로 정의
- 디노이징 Seq2seq 모델을 사용
- 기존 모델의 한계를 여러 도메인에서 좋은 성능을 내는 딥러닝 모델을 통해 극복하고자 함
오타 교정을 단순히 오타를 정타로 바꾸는 것이 아니라, 오타에서 정타를 생성해낸다고 정의내린 것이 참신하다고 느껴졌습니다.
기대 효과
- 복잡한 서비스 구조를 단순한 구조로 변경
- 데이터 추가시 지속적인 성능 개선 가능
- 학습 데이터에 따라 도메인에 특화된 모델 제공 가능
- 예: 음악, 쇼핑, 로컬 등
- 디노이징 모델을 위한 노이즈 생성 함수 개발
- 확장이 용이하고, 여러 도메인에 적용 가능한 오타 생성 방법 개발 가능
- 학습 데이터: <오타, 정타> 쌍 데이터
딥 스펠러 소개
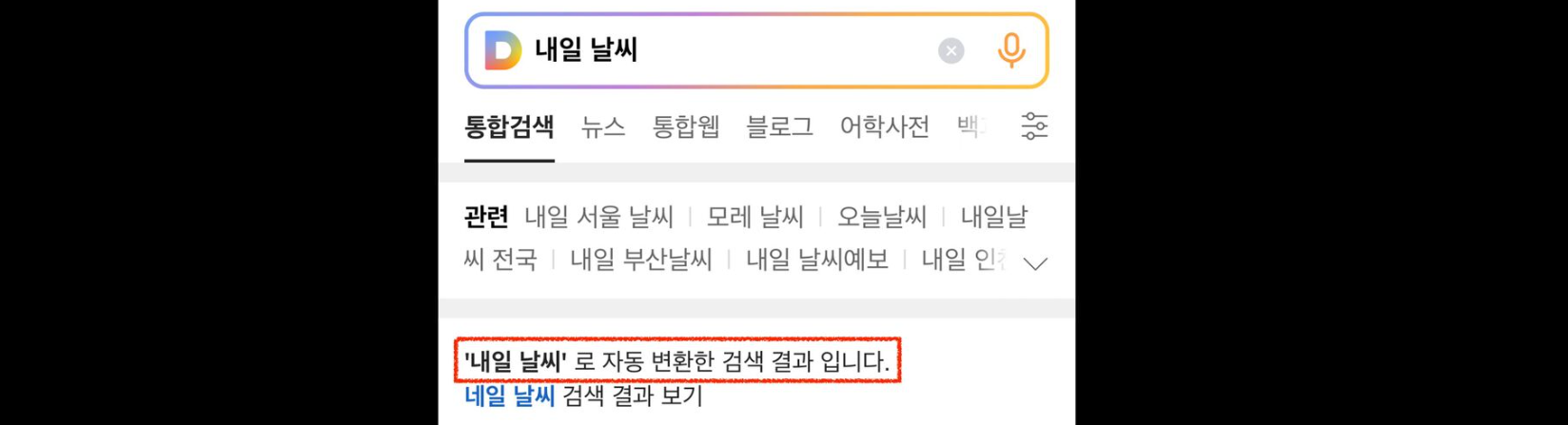
Seq2seq 모델
- 딥 스펠러는 seq2seq 모델을 기본으로 함
- 인코더의 입력이 디코더의 출력이 되는 과정을 학습
- 입력으로는 오타를, 출력으로는 정타를 사용
Seq2seq 모델의 학습 데이터
- Seq2seq 모델 학습에는 쌍을 가지는 데이터가 필요 (오타 / 정타 데이터)
- 기존 검색어 로그 데이터 활용
- 기존 서비스에서 사용중인 데이터 활용
- 오타 생성 모델을 이용
- 정타 데이터를 입력하여 임의의 <오타, 정타> 쌍을 생성
- 데이터 양이 적을 때 효과적
학습 데이터를 잘 보충하기

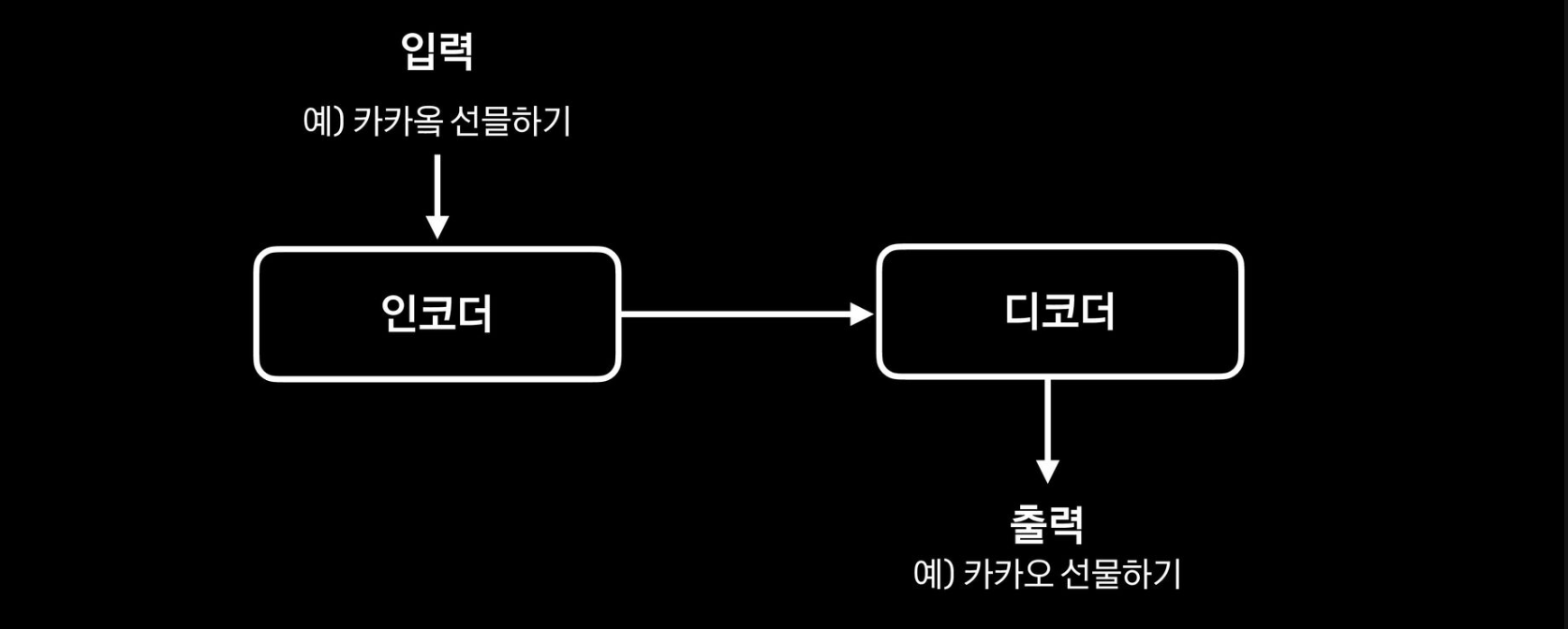
디노이징 모델을 사용
- 입력을 노이즈 함수를 통해 변형하고, 변형된 결과를 다시 입력으로 복원하는 것을 학습하는 모델
- 부족한 <오타, 정타> 쌍 데이터를 노이즈 함수를 통해 보충
- 검색 로그, 정타 데이터 등 보유한 리소스를 최대한 활용할 수 있고, 다양한 실험이 가능
- 참고로 MS, Hubspot 등 다양한 곳에서도 디노이징 모델을 오타 교정에 활용
머신 러닝 분야에서는 학습시키기 위해 많은 데이터가 필요한데, 찾기가 어려울 때가 있습니다.
특정 분야에서는 이와 같이 직접 데이터를 생성해내는 방법을 사용할 수 있을 것 같습니다.
딥 스펠러 구조
노이즈 함수

- 노이즈가 적용된 학습 데이터(<오타, 정타> 쌍)를 생성하는 부분
- 정타를 입력하여 오타를 생성
- 정타는 관리 도구 데이터와 검색 로그를 활용
다양한 노이즈 함수
입력으로 "이프 카카오"가 입력된 경우
- keystroke를 변환
- 입력을 keystroke로 변환
- dlvm zkzkdh
- 오류 모델 기반 오타 생성
- 기존 서비스의 오류 모델을 활용
- 이프 키카오, 이푸 카카오, 니프 카카오
- 패턴 기반 오타 생성
- 관리 도구 데이터, 세션 로그를 이용하여 <정타, 오타> 패턴으로 오타 생성
- 이프 카캉, 이프 카코오, 이프 ㅋk카오
- 번역 모델 기반 오타 생성
- 관리 도구 데이터, 세션 로그를 이용하여 <정타, 오타> 오타 생성 모델 학습
- 이푸 카카오, 아프 카카오, 이프 카카어
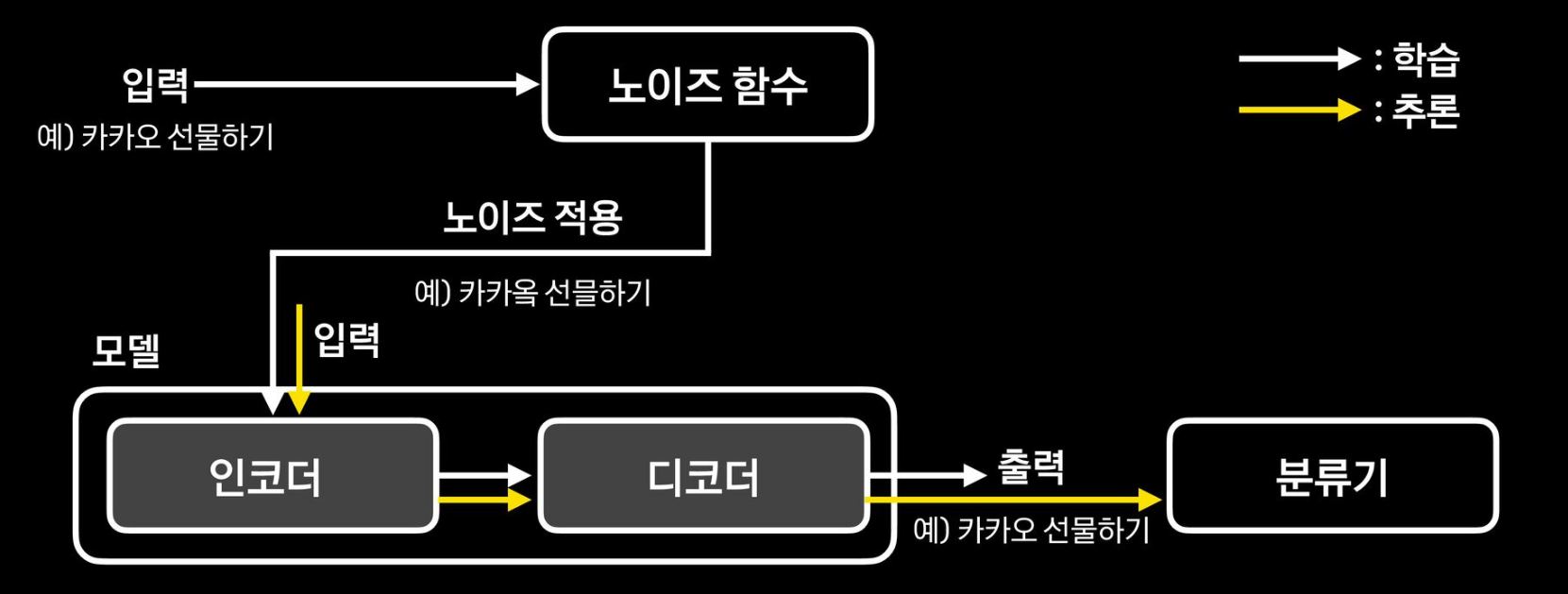
전체적인 구조
Seq2seq 모델
- 오타를 정타로 교정하도록 학습
- 학습 데이터로 <오타, 정타> 쌍을 사용
- 인코더, 디코더 레이어를 각각 3개씩 사용
- 빠른 처리 시간을 위해 모델 사이즈를 최소화
- 토큰 단위는 문자
학습 데이터
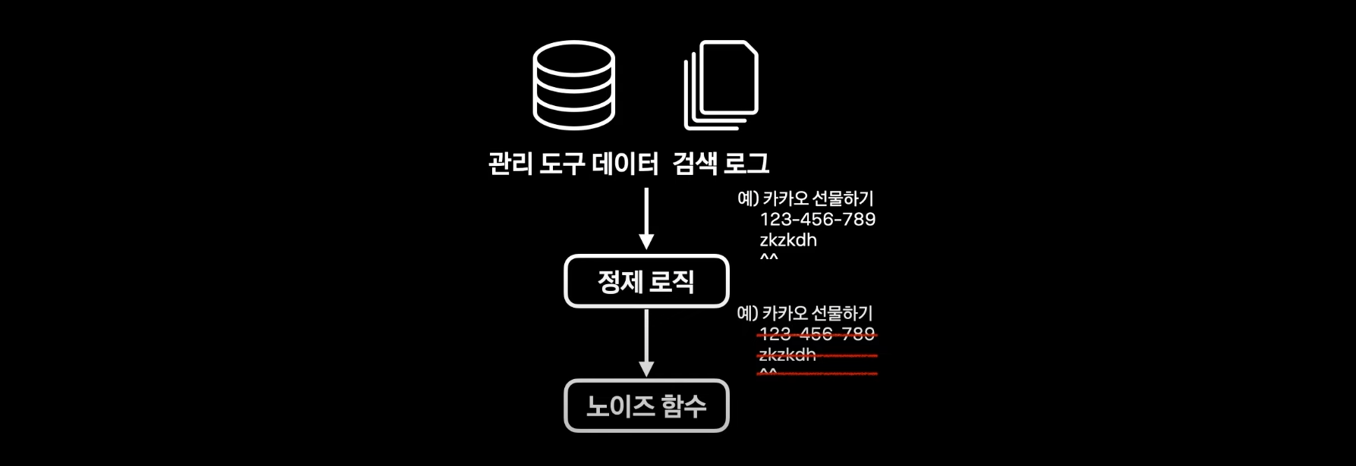
- 관리 도구 데이터, 검색 로그를 정제 후 사용
- 정제 기준
- 숫자, 기호, 자모, url만 있는 경우
- 오타 패턴이 포함되어 있는 경우
분류기
- 교정 결과의 신뢰도를 높이는 과정
- <입력, 출력> 쌍에 대해 출력의 언어 모델 확률이 더 높을 때 교정 결과를 사용
- 여러가지 실험을 통해 언어 모델을 이용한 분류기를 사용
개선 결과
평가 방법
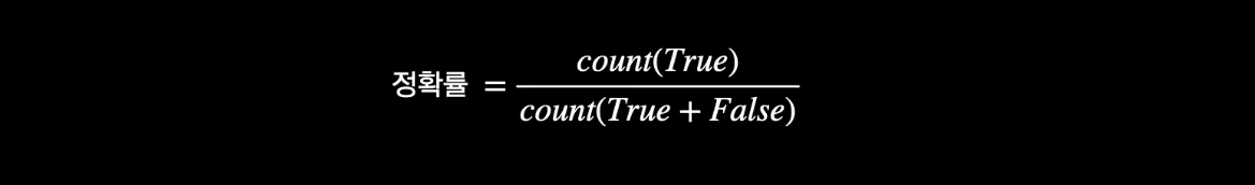
- 입력 데이터 종류에 따라 나눠 평가
- 오타 정확률
- True: 오타를 바르게 교정한 경우
- False: 오타를 교정하지 않거나, 잘못 교정한 경우
- 정타 정확률
- True: 정타를 교정하지 않은 경우
- False: 정타를 잘못 교정한 경우
평가 데이터
- 검색 로그를 활용하여 구축
- 모수를 잘 반영할 수 있도록 층화 샘플링
구축 방법
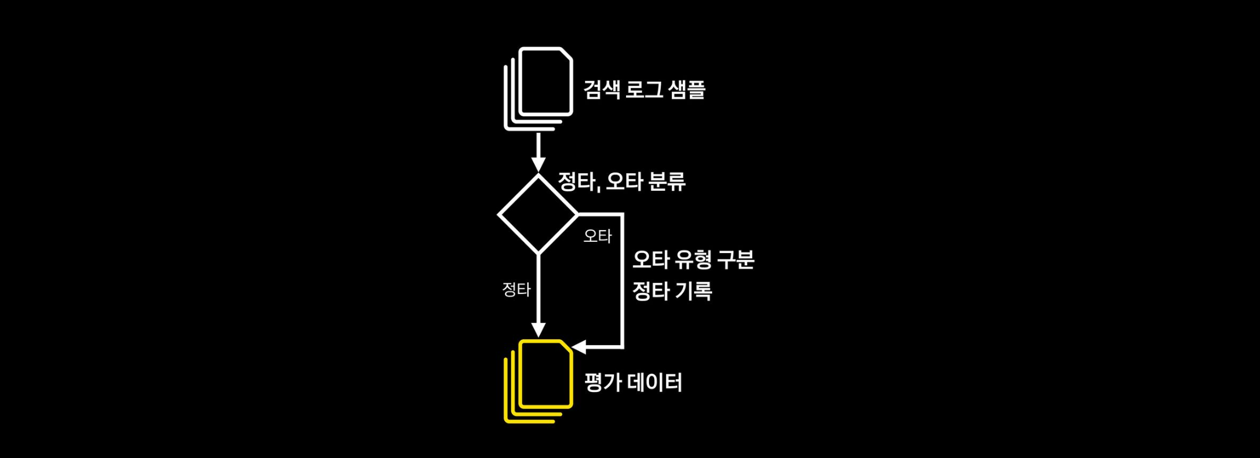
- 입력이 정타인지 오타인지 분류
- 오타인 경우 오타 유형을 구분하고 정타를 기록
- 2명의 리뷰어가 교차 검증을 통해 데이터를 구축
- 데이터 규모는 약 10만개이며 오타는 약 5%
전체적인 성능 비교
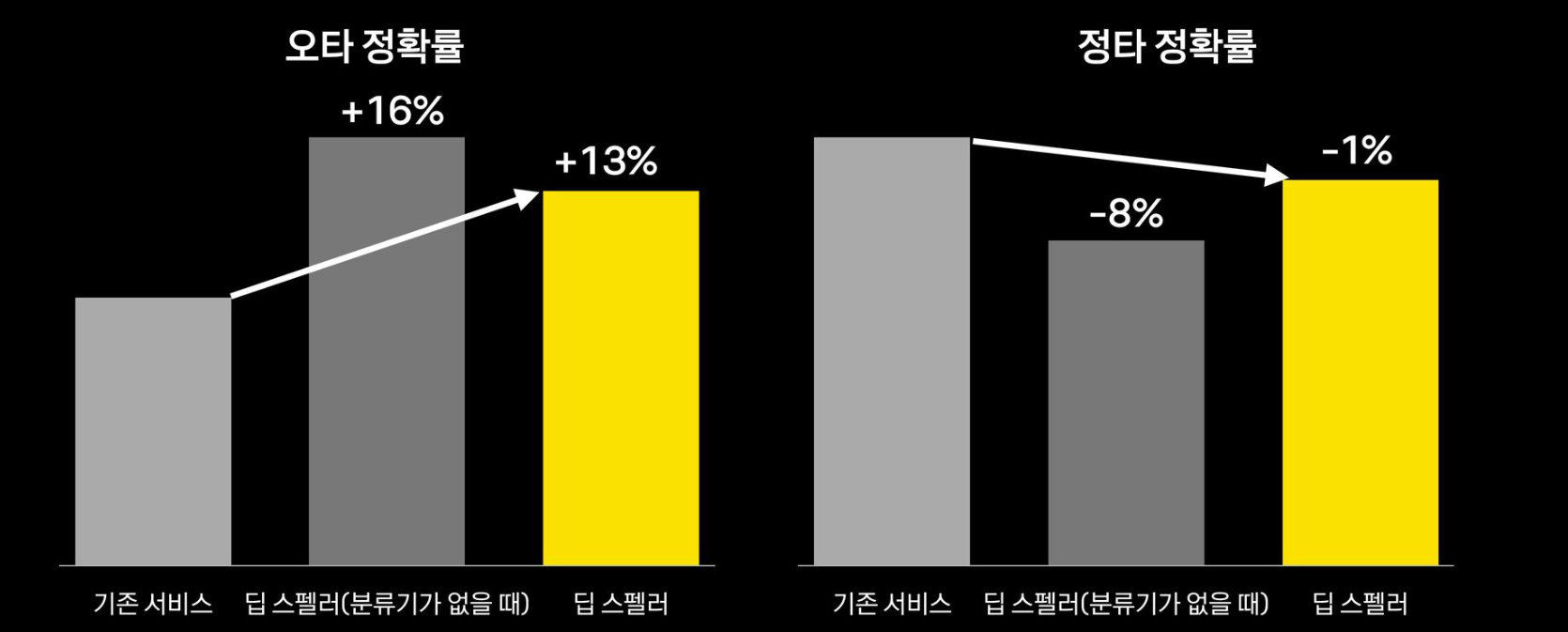
오류 유형별 비율과 성능 비교
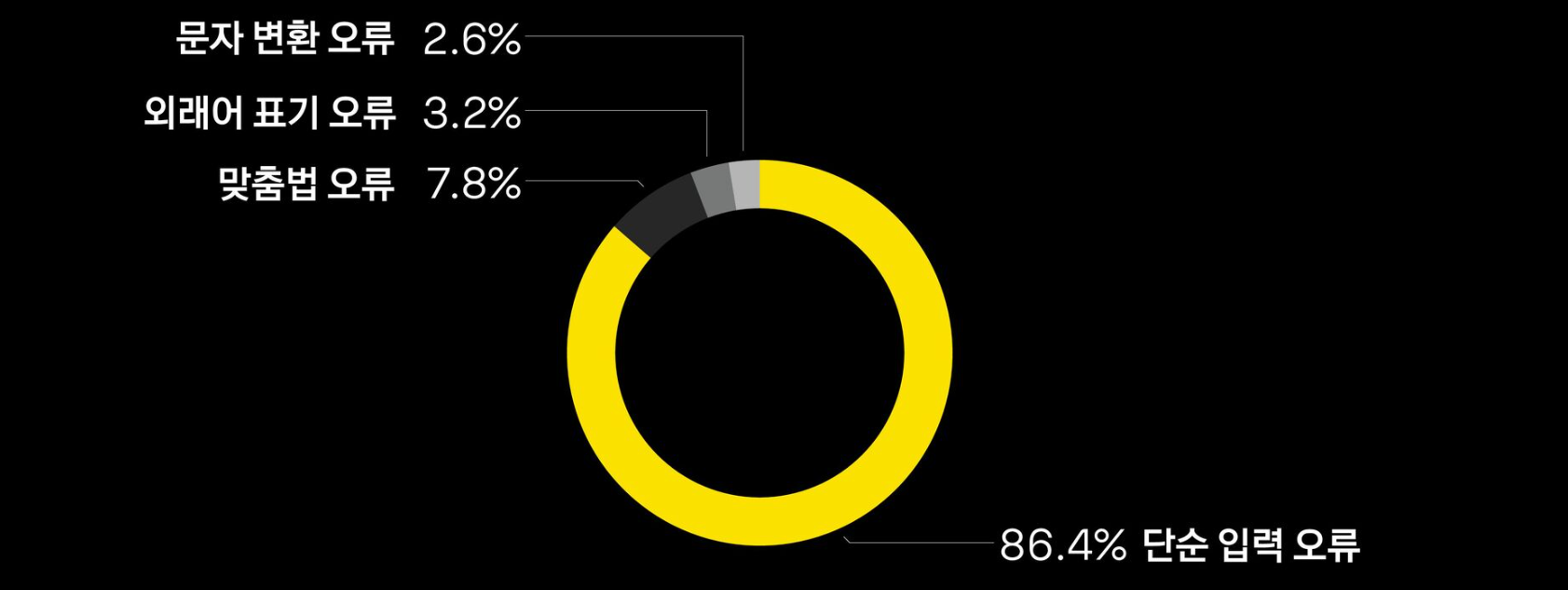
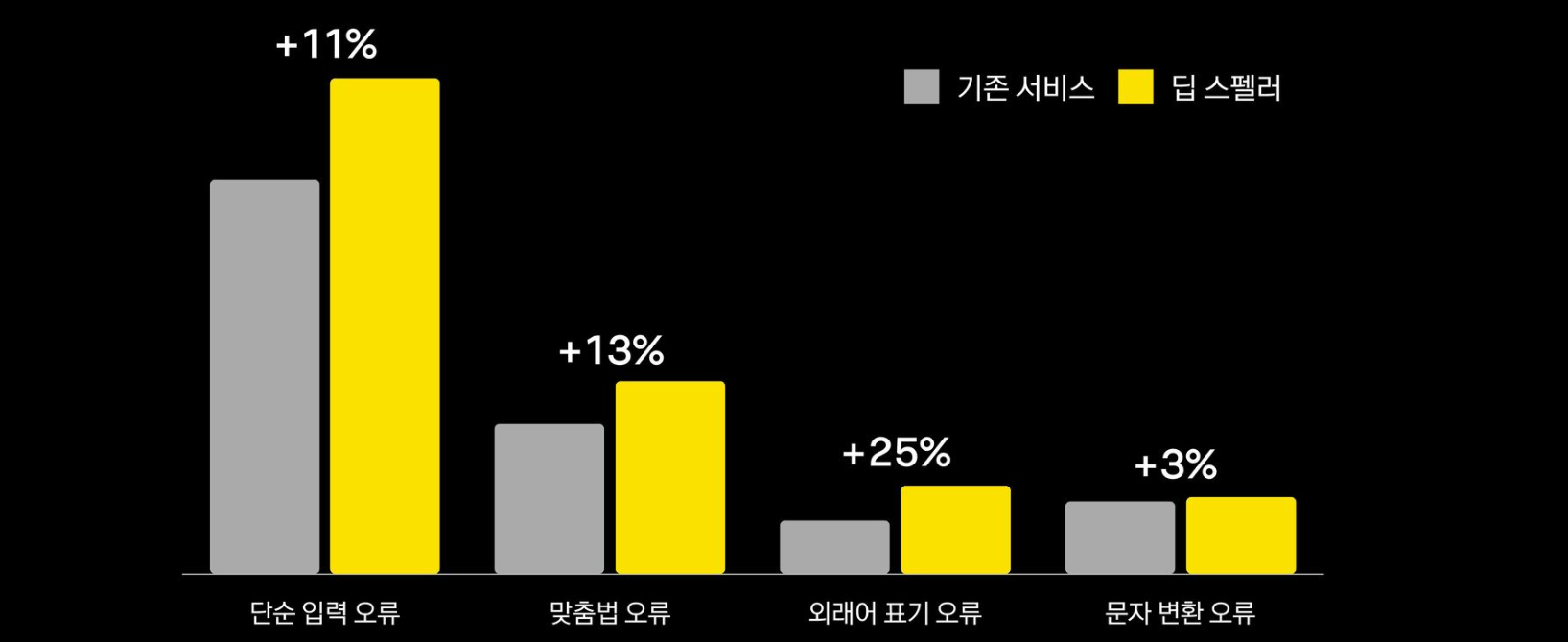
향후 계획
- 모델 개선
- 노이즈 함수 추가 개발
- 웹문서 키워드 추출을 통한 학습 데이터 보강
- 시스템 개선
- 모델 최적화
- 유저의 피드백(클릭 유무) 활용

개발을 하며 경험한 것들을 이것저것 작성해보고 있습니다!