소개글
면접 대비겸 여러 블로그들을 참고하면서 정리해본 CS 지식들을 포스팅하고 있습니다.
만약 틀린 내용이 있다면 피드백은 언제나 환영합니다.
제 나름대로 요약한 내용이기 때문에 자세한 내용은 제일 아래쪽 참고 사이트에서 확인하면 좋을 것 같습니다!
말투는 편한 말투로 작성하니 양해 부탁드립니다.
인덱스
정의
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기위한 자료구조
관리
- 항상 최신 정렬 상태를 유지해야 빠르게 탐색 가능
- 특정 연산에 대해 추가 작업을 해줘야함
- INSERT - 새로운 데이터에 대한 인덱스를 추가
- DELETE - 삭제하는 데이터의 인덱스는 사용하지 않는다고 표시 (인덱스 자체를 삭제하지는 않음)
- UPDATE - 기존 인덱스는 사용하지 않는다고 표시 + 갱신된 데이터에 대한 인덱스 추가
장점
- 데이터의 위치를 알려주는 자료구조를 생성하여 빠르게 조회할 수 있도록 함
- SELECT 외에도 UPDATE 및 DELETE 도 빨라짐 (어쨋든 일단 조회를 해야 뭘 할 수 있으니)
- Index를 사용하지 않는다면 → Full Scan → 오래 걸림
단점
- 인덱스를 위한 추가 저장공간 필요
- 인덱스를 관리하기 위한 추가 작업 필요
- 잘못 사용하면 오히려 성능 떨어질 수도 있음 (UPDATE, DELETE 로 사용하지 않는 인덱스가 계속 쌓임)
- 데이터가 적다면 B+Tree에서 리프노드까지 가는 시간때문에 Full Scan이 더 빠를 수도 있음
사용하면 좋은 경우
- 데이터의 조회가 자주 일어나는 컬럼
- 데이터 조작이 자주 일어나지 않는 컬럼
- 데이터의 중복도가 낮은 컬럼 (카디널리티가 높은 컬럼)
→ 최대한 많은 데이터를 필터링하기 위해
→ 선택하는 데이터가 많을 수록 Full Scan에 가까워져버림
자료구조
해시 테이블
- 매우 빠른 검색
- 등호(=) 연산에만 특화되어있고 부등호(>, <) 연산은 못하기 때문에, 잘 안쓰임
B+Tree
- BTree를 발전시킨 형태
- 리프노드만 인덱스와 함께 데이터를 갖고 있고, 나머지 노드들은 인덱스만 갖고 있음
- 리프노드들은 LinkedList로 서로 연결되어있음 → 순차 검색에 용이함
- BTree에 비해 데이터를 찾으려면 무조건 리프노드까지 가긴 해야함
- 인덱스 자료구조로 적합
- 리프 노드를 <key,data record>, <key,rid>, <key,rids> 등으로 할 수 있음
BTree
- 데이터가 정렬된 상태로 있음
- 균형 트리 (모든 리프노드가 같은 레벨에 있음)
- 2개 이상의 자식을 가짐
Clustered VS Non-clustered
Clustered
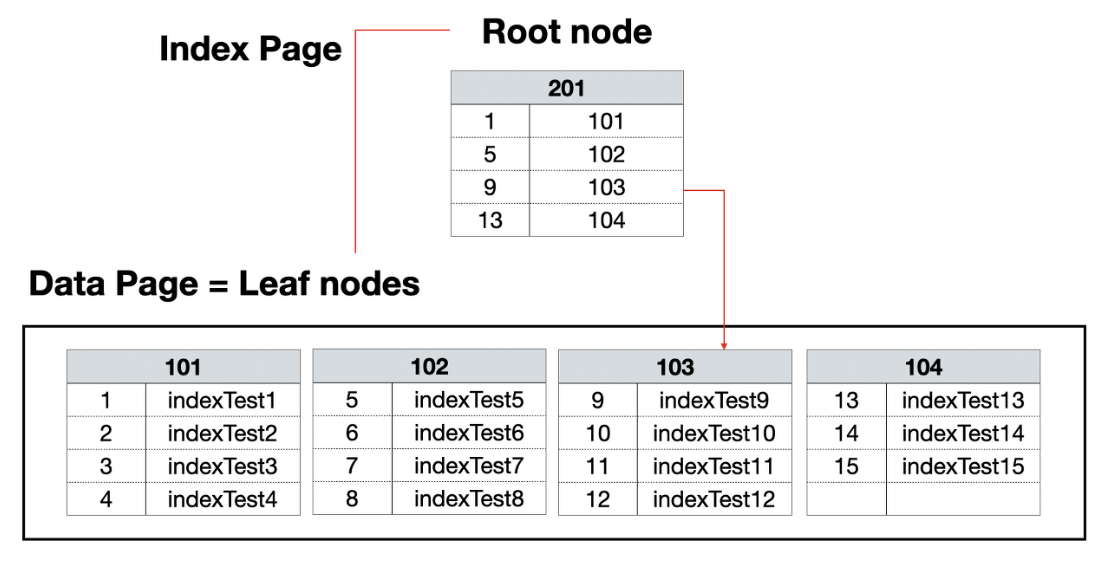
- 물리적으로 정렬되어있음
- 데이터와 인덱스의 리프 페이지가 같음 → 테이블 자체가 인덱스 → 따로 인덱스 페이지를 만들지 않음
- 한 테이블당 하나만 존재
- 검색 속도는 빠르지만 입력, 수정, 삭제 성능이 별로임
Non-clustered
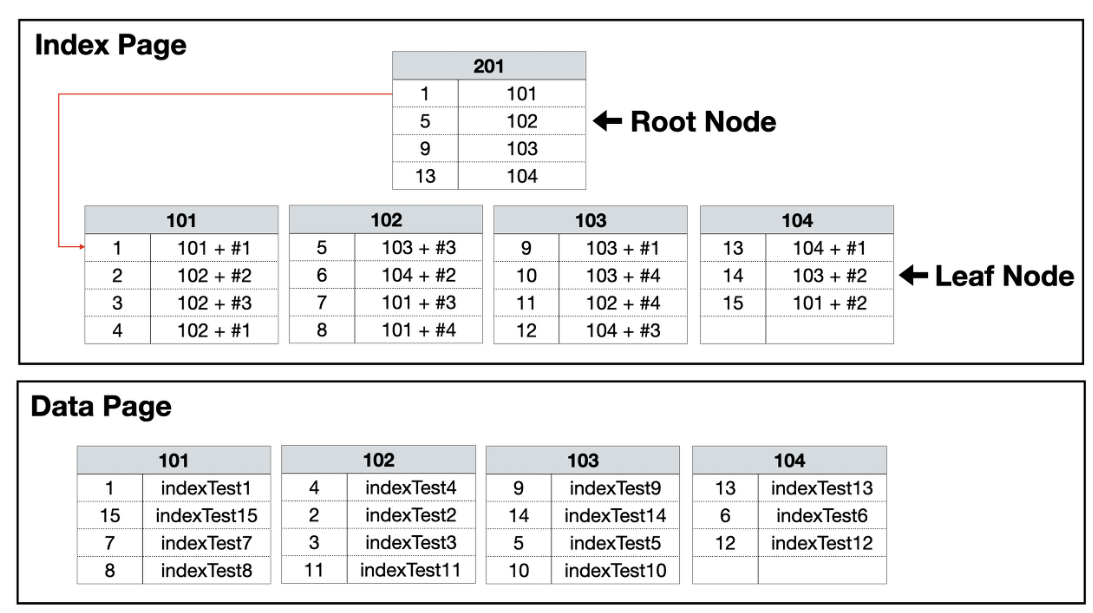
- 원본은 정렬되지 않고, 인덱스 페이지만 정렬됨
- 별도의 장소에 인덱스 페이지를 생성
- 리프 페이지에서 데이터가 아닌, 데이터가 위치하는 포인터(RID)를 알 수 있음
- 한 테이블에 여러개 생성 가능
- 검색 속도는 느리지만 입력, 수정, 삭제 성능이 좋음
참고 사이트
https://mangkyu.tistory.com/96
https://velog.io/@soyeon207/인덱스란
https://junghn.tistory.com/entry/DB-클러스터-인덱스와-넌클러스터-인덱스-개념-총정리https://simsimjae.tistory.com/241
https://jungwoong.tistory.com/34

개발을 하며 경험한 것들을 이것저것 작성해보고 있습니다!