소개글
각종 컨퍼런스에 나온 강연들을 정리해보면서 공부해보고 있습니다.
이번 포스팅은 if(kakao) 2022에서 정성희님께서 강연해주신 내용을 정리했습니다.
제목은 "커스텀 음성 합성: 1문장 녹음으로 1초만에 커스텀 음성 합성기 만들기"이며 제목 그대로 음성 합성을 쉽게 할 수 있는 모델에 대한 내용입니다.
말투는 편한 말투로 작성하니 양해 부탁드립니다.
발표내용
커스텀 음성 합성이란?
- 합성기가 새로운 목소리를 지원하기 위해 소량의 데이터만 사용하도록 하는 기술
- 녹음해야 하는 문장 수가 적기 때문에 일반인도 합성기를 쉽게 만들 수 있음
- 성우의 목소리를 추가할 때도 기간이 짧게 들고 비용이 줄어들음
기존 음성 합성기에 목소리 추가하기 어려웠던 이유
일반 합성기

동작
- 스크립트를 입력으로 받아 음성을 출력
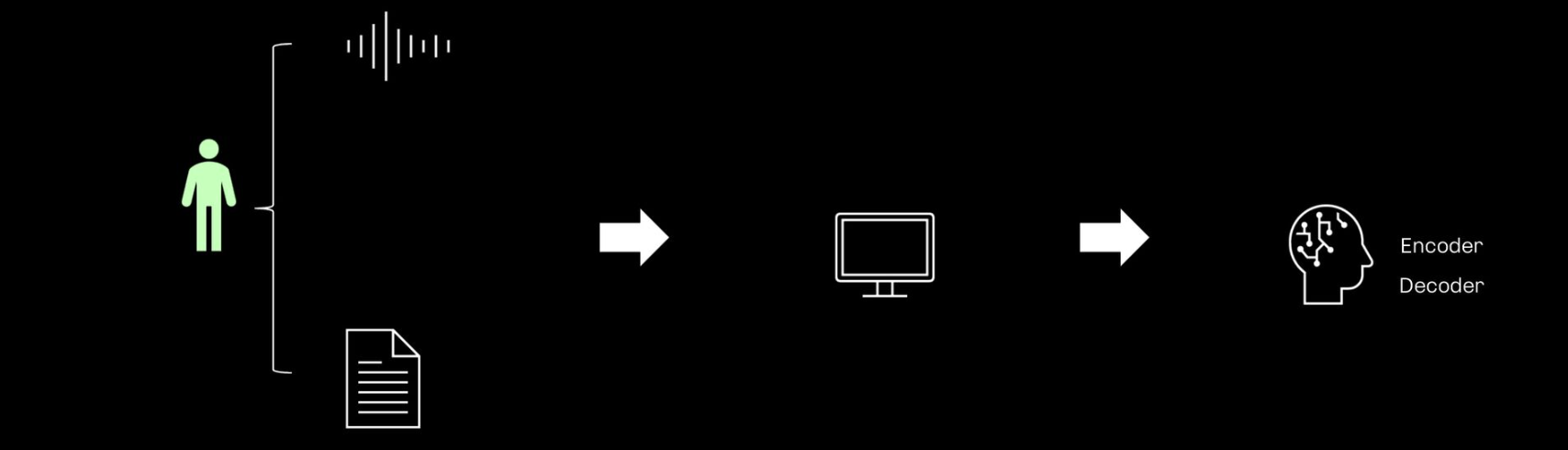
훈련
- 화자의 스크립트와 음성 데이터가 짝으로 GPU에 입력되어, 그 관계를 학습한 결과, 합성기 (encoder + decoder) 가 훈련됨
- encoder: 텍스트를 이해하는 모듈
- decoder: 소리를 생성하는 모듈

화자 추가
- 새로운 화자의 데이터로 encoder, decoder를 훈련하는 것이 필요
- 추가된 화자만큼 모델 수 증가 및 유지 관리 포인트 증가
- 단일 모델을 훈련할만큼의 신규 화자 음성 녹음 필요 (수만 문장)
다화자 합성기
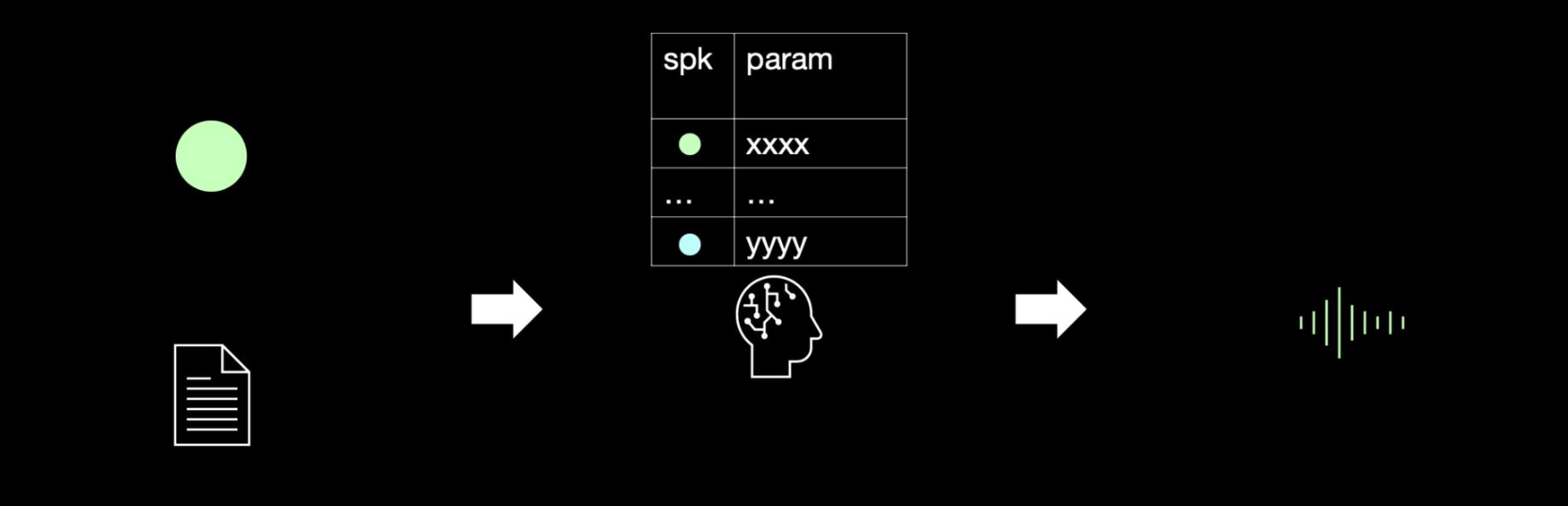
동작
- 여러명의 목소리를 제공하는 하나의 합성기
- 음색을 선택하고 스크립트를 입력하면 선택된 화자의 목소리로 합성음을 출력
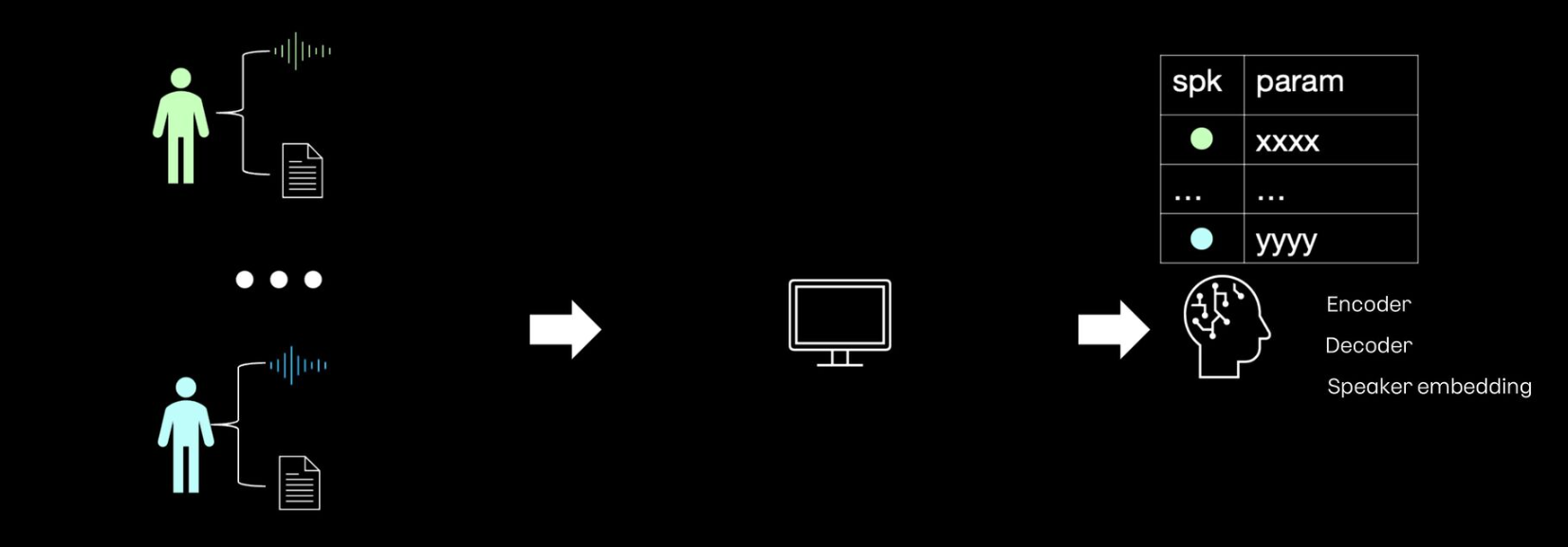
훈련
- 화자들이 공유하는 모듈과 화자별로 존재하는 모듈로 나눌 수 있음
- encoder, decoder는 여러 화자가 공유
- speaker embedding이라는 파라미터는 화자 고유의 음색 정보를 저장
- 공유하는 파라미터가 있기 때문에 화자 한명당 필요한 문장 수가 줄어들음
화자 추가
- 모델의 파라미터 일부를 여러 화자가 공유하고 있기 때문에 모델 업데이트 과정에서 기존 화자들의 합성음도 영향을 받음
- 신규화자의 데이터 필요 (수천 문장)
신규 화자를 추가하기 위해 수만 문장을 추가해야했던 일반 합성기에 비해, 다화자 합성기는 수천 문장만 추가하면 되긴 하지만, 여전히 데이터가 많이 필요합니다.
커스텀 음성 합성기에 목소리 추가하기 쉬운 이유
커스텀 음성 합성기란
다 만들어진 합성기에 목소리만 넣기만 하면 작동하는 합성기
다화자 합성기
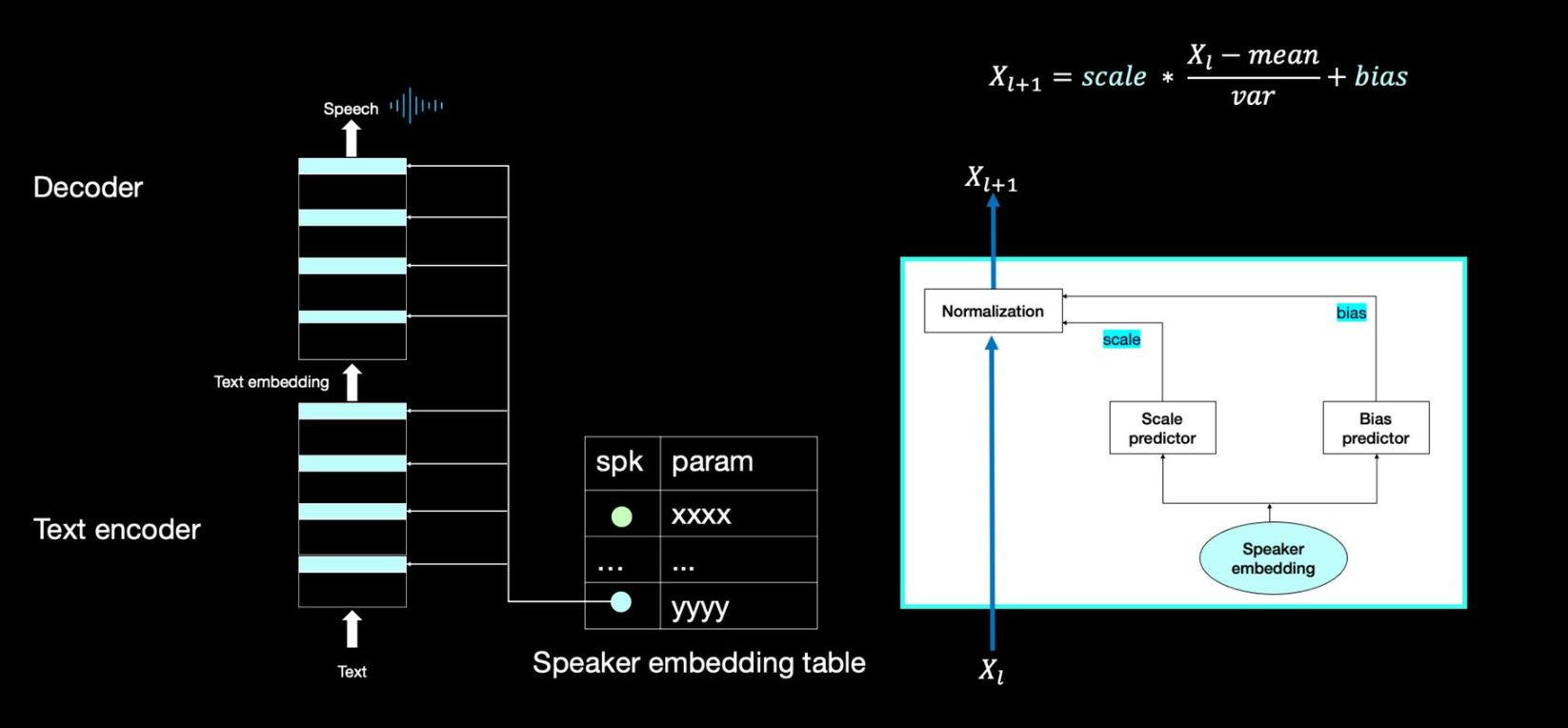
- 커스텀 음성 합성기는 다화자 합성기로부터 출발
- 크게 세가지 모듈로 구성됨
- speaker embedding table: 화자별로 다른 음색 정보를 저장하는 파라미터
- encoder: 텍스트를 받아서 기계가 이해할 수 있는 text embedding으로 변환
- decoder: text embedding을 받아서 사람이 이해할 수 있는 스피치로 변환
- 하늘색 블록마다 오른쪽 normalization 연산을 진행
- X[L+1] 값에는 speaker embedding이 반영됨
- 반복적인 연산으로 화자의 특성을 적용 가능
- 이는 Adaspeech 논문을 바탕으로 한 설명
적응 기반 커스텀 합성기
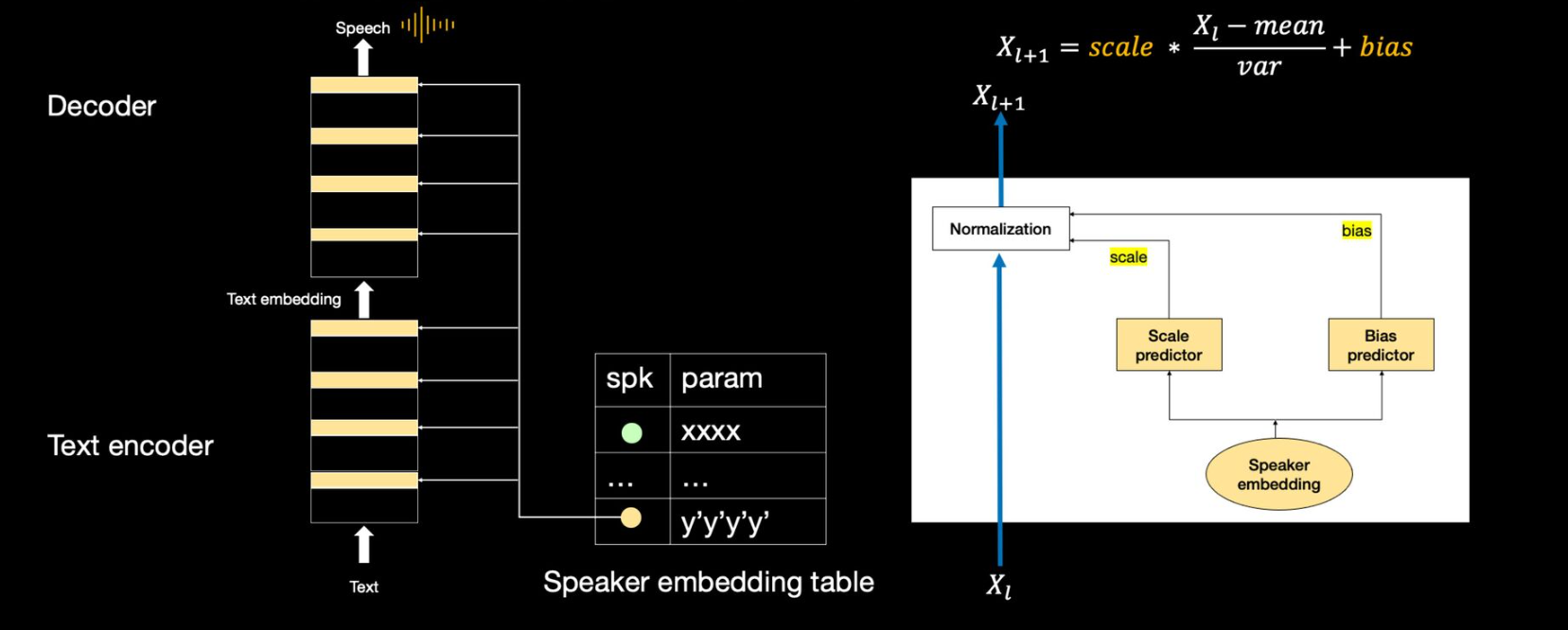
- 앞서 훈련이 완료된 다화자 합성기에 추가 훈련 (적응) 을 통해 목소리를 추가
- 적응 훈련중에는 speaker embedding, scale predictor, bias predictor만 훈련되도록 함
- loss가 다른 파라미터들은 역전파되지 않도록 함
- 기존 다화자 합성기에 다른 화자들은 영향을 받지 않음
- 업데이트되는 파라미터 수도 적기 때문에 필요 문장 수도 적음
Zero-Shot 커스텀 합성기
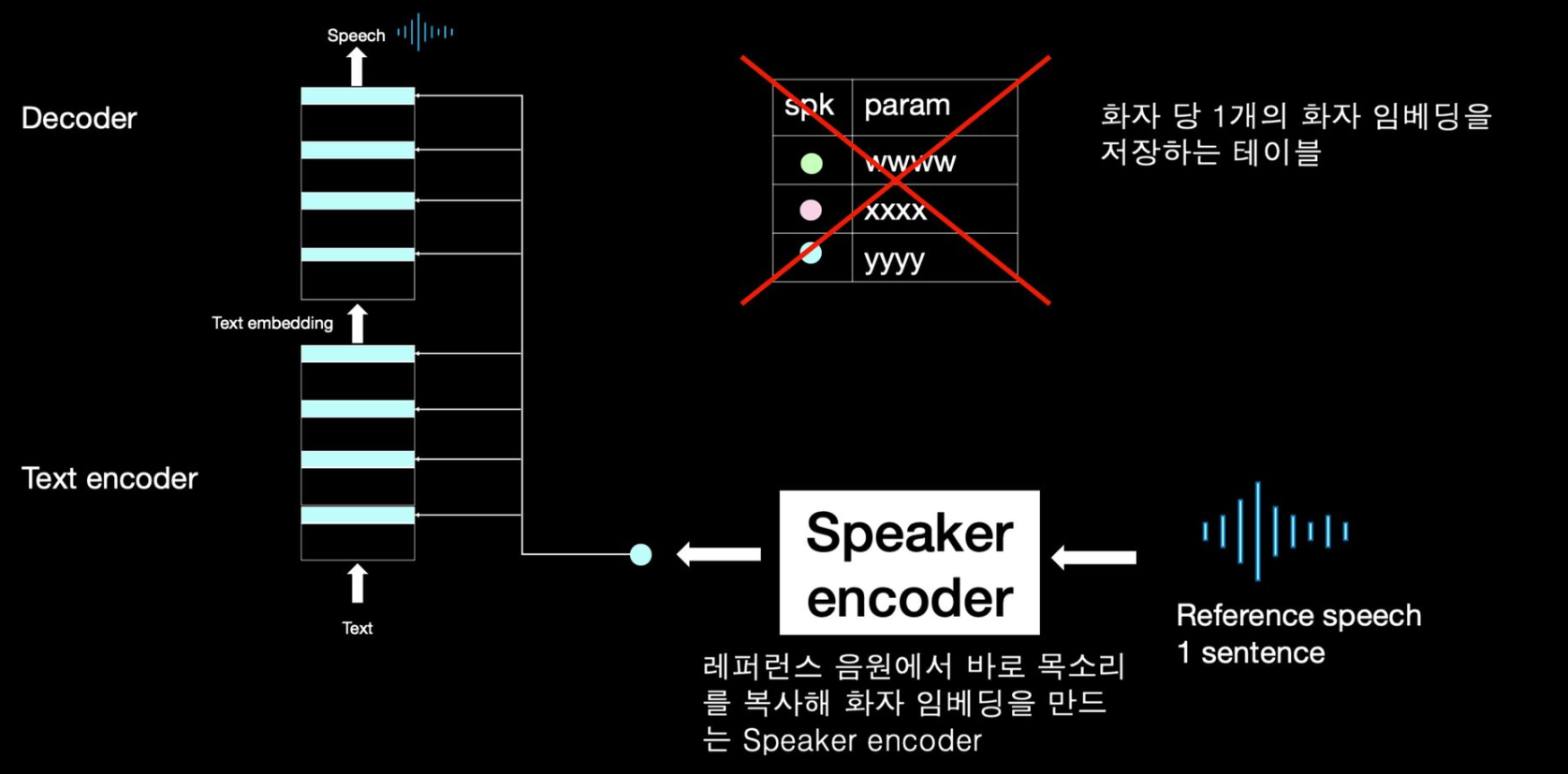
- 새로운 화자 추가를 위해 추가 훈련을 할 필요가 없음
- speaker embedding table 대신 speaker encoder 모듈 사용
- speaker encoder는 주어진 레퍼런스 음원에서 바로 목소리를 복사함
- 즉 새로운 화자를 추가하려면 encoder에 입력을 새로운 사람으로 주기만 하면 됨
커스텀 합성기 비교
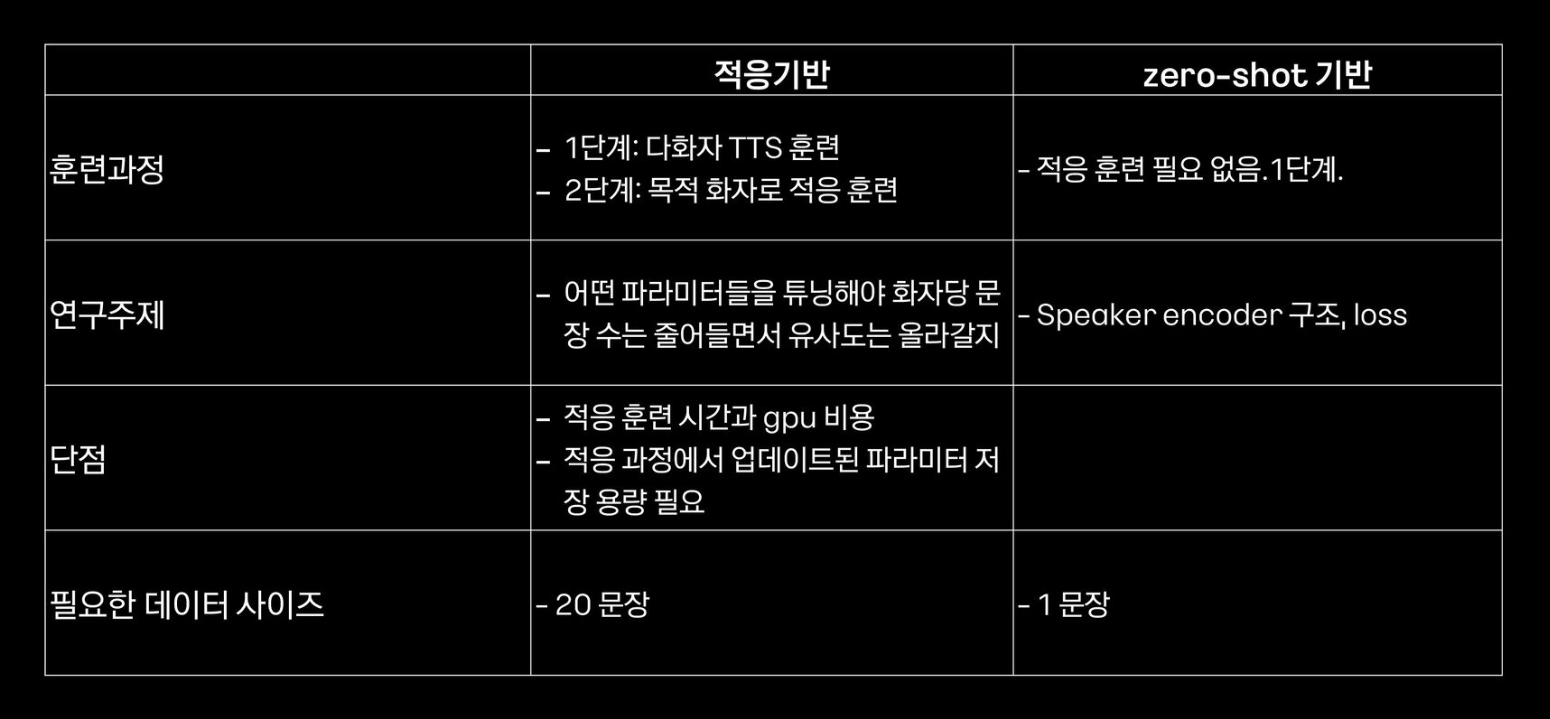
수천 문장을 훈련 데이터로 줘야했던 다화자 합성기에 비하면 커스텀 합성기는 데이터가 극적으로 줄었다고 할 수 있습니다.

개발을 하며 경험한 것들을 이것저것 작성해보고 있습니다!