
Allocation of File Data in Disk
- File 은 임의의 크기를 가지고 있는데,
- Disk 에는 sector 라는 동일 크기 단위로 나누어서 저장한다.
Contiguous Allocation
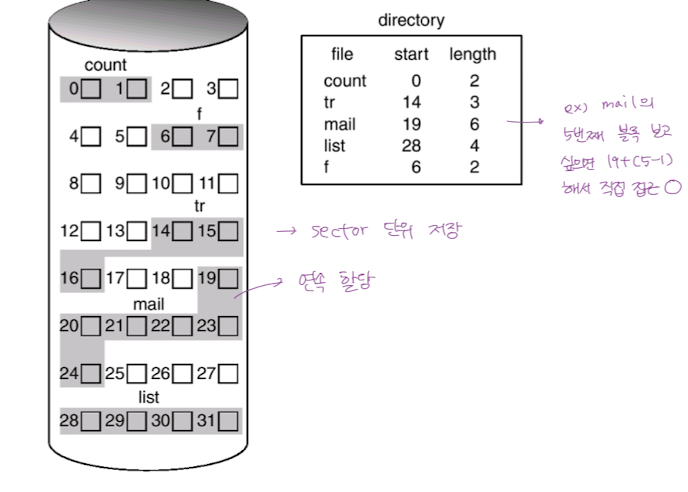
- 하나의 파일에 대해 연속적인 디스크 공간을 할당한다.
단점
- 외부 조각(파일과 파일 사이)이 생길 수 있다.
ex) 3개의 섹터를 사용하는 파일이 있다면 17 18 2칸의 공간에는 들어갈 수 없다. - File grow 가 어렵다. == File 의 크기를 키우기가 어렵다.
미봉책 : 파일을 할당하고 뒤에 빈 공간을 어느 정도 확보해둔다. -> 내부 조각이 생김 (공간 낭비일수도...)
장점
- Fast I/O
- HDD 의 경우는 디스크 헤드가 이동하는 시간이 대부분.
- 연속 할당을 하면 한번만 seek 하면 거기서 다 읽어올 수 있다.
- Swap Area 로 사용. (or realtime file)
- Direct Access(=Random Access) 가능
- mail 이라는 데이터에서 다섯번째 블록을 보고 싶다면? 앞의 블록에 접근하지 않아도 19 + 5 해서 직접 접근 가능.
Linked Allcoation
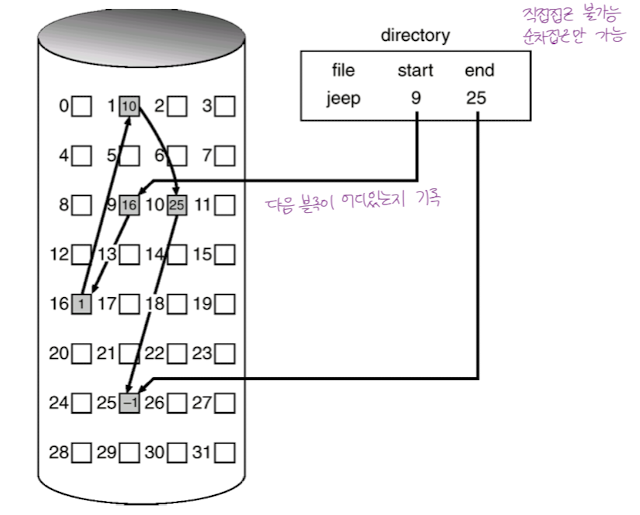
- 해당 블록의 끝에 다음 블록이 어디있는지에 대한 정보를 가지고 있어서 찾아갈 수 있다. 끝이라면 EOF
장점
- 외부 조각이 생기지 않는다.
단점
- 직접 접근 불가능.
- Reliability 문제 : 한 섹터가 고장나서 pointer 가 유실되면 많은 부분을 다 잃어버릴 수 있다.
- Pointer 를 위해서 공간을 할당해야 함.
- 512 bytes/sector, 4bytes/pointer -> 실제 데이터는 508byte.
- 한 섹터에 저장될 내용이 두 섹터에 나누어서 저장될 수도 있음.
변형
- FAT (File-allocation table) 파일 시스템
- 포인터를 별도의 위치에 보관하여 reliablity, 공간 효율성 문제 해결.
Indexed Allocation
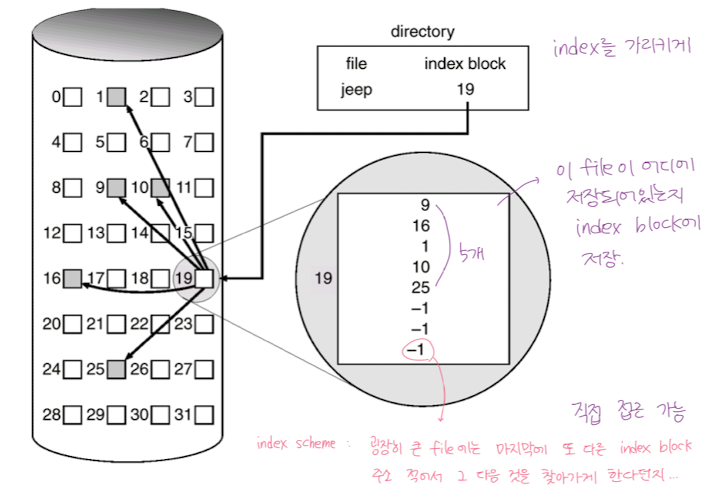
- Linked Allocation 의 모든 포인터를 따라가야 하는 문제를 해결
- 하나의 파일에 해당 파일이 어떤 블록에 저장되어 있는지를 저장해둔다.
장점
- 외부 조각 발생 X
- 직접 접근 가능
단점
- 공간 낭비 : 아무리 작은 파일이라도 블록이 2개 필요하다.
- 파일이 매우 크다면? 하나의 block 으로 index 를 저장하기에 부족함.
- linked scheme : 맨 마지막에 다른 index block 주소를 적어서 찾아갈 수 있게
- multi-level index : 2단계 페이지 테이블처럼 index table 의 index table 사용. but 공간 낭비..
Example
UNIX File System
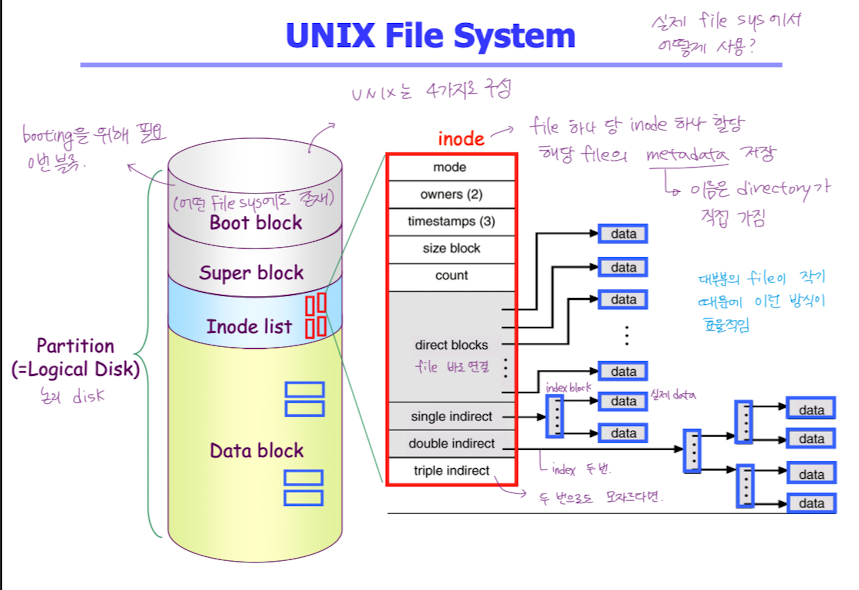
- Boot Block
- 부팅에 필요한 정보 (bootstrap loader)
- Superblock
- 파일 시스템에 관한 총체적인 정보를 담고 있다.
- Inode
- 디렉토리가 메타데이터를 모두 다 가지고 있지 않음. 디렉토리는 메타데이터 중 file 의 이름만 가지고 있음. (data block > directory > file 이름)
- 파일 이름을 제외한 파일의 모든 메타 정보를 저장
- 미리 파일 하나당 inode 크기가 정해져있기 때문에 파일이 작으면 direct 만 사용
크면 single indirect, 더 크면 double indirect 까지 사용해서 실제 파일을 가리키게 한다.- 굉장히 큰 파일도 Inode 하나로 표현 가능. 효율적.
- 대부분의 파일은 크기가 매우 작기 때문에 direct 블록만으로 접근할 수 있다.
- Data block
- 파일의 실제 내용을 보관
FAT File System
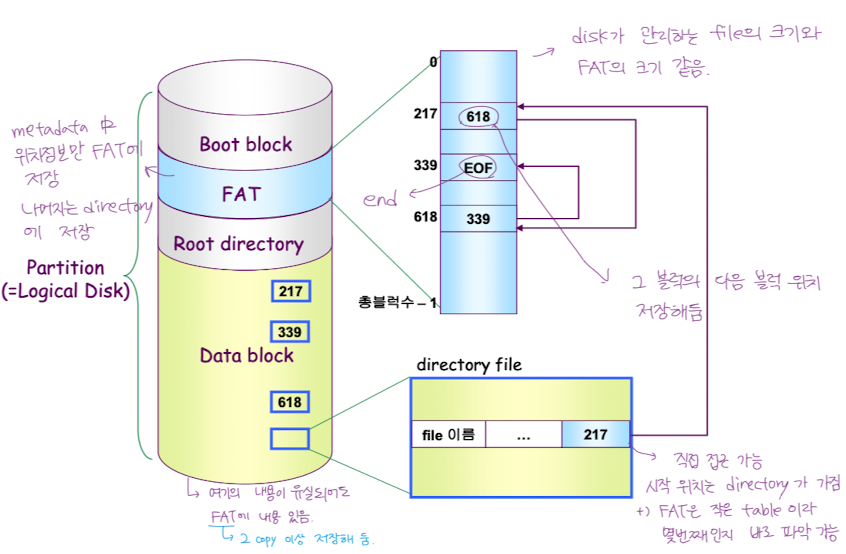
- FAT
- 파일시스템의 메타데이터 중 위치 정보만 FAT 이라는 별도의 테이블에 저장. 나머지는 디렉토리가 가짐.
- 그 블럭의 다음 블럭 번호를 배열에 저장.
- file 크기 == FAT 크기
- 디렉토리에 file 이름과 해당 file 의 첫 블록 위치가 써있음 -> 다음 블록은 FAT 배열에 가서 찾는다.
- 직접 접근 가능. (!= Linked List. 실제로 디스크 헤더가 이동하지 않고 FAT 을 메모리에 올려놓고 따라간 다음에 디스크 헤더를 움직이면 됨.)
Free-Space Management
- 파일에 할당되지 않은 비어있는 블록은 어떻게 관리?
Bit map or bit vector
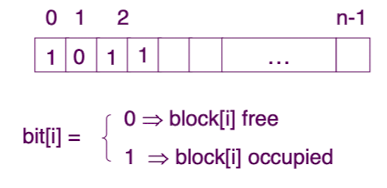
- 부가적인 배열을 하나 두고, 해당 블록이 사용중인지 아닌지를 1, 0 으로 표시.
- 연속적인 n 개의 free block 을 찾는데 효과적.
Linked List
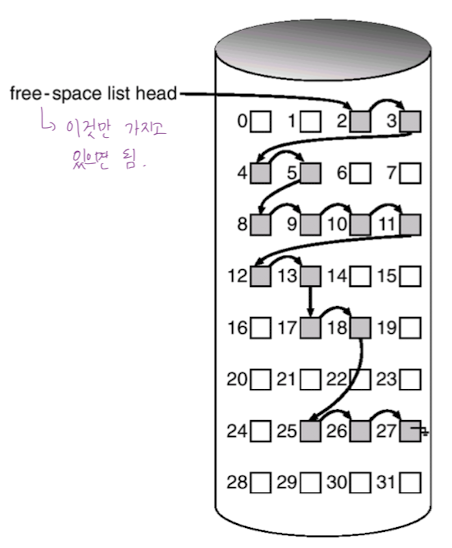
- 비어있는 모든 블록을 연결해둠 -> 첫번째 빈 블록의 주소만 가지고 있으면 됨.
- 공간 낭비가 없지만, 연속적인 가용공간 찾기는 쉽지 않음.
- 실제로 사용하기는 쉽지 않음.
Grouping
- Indexed Allocation 과 비슷.
- 첫번째 free block 이 n개의 포인터를 가짐.
- n - 1 포인터는 free data block 을 가리킨다.
- 마지막 포인터가 가리키는 block 은 또 다시 n 개의 pointer 를 가진다.
- continuous free block 을 찾기는 쉽지 않음.
Counting
- 프로그램들이 여러 개의 연속적인 block 을 할당하고 반납하는 일이 잦으므로,
- (first free block, # of contiguous free blocks) 정보를 유지.
- 첫번째 빈 블록, 부터 몇 개가 비었는지
Directory Implementation
- 디렉토리 파일내의 파일의 메타데이터를 어떻게 관리하는지?
구현 방법
Linear List

- (file name, file metadata) 의 list
- 구현이 간단함.
- 형식이 정해져 있어서 어디서 어디까지가 name 이고 metadata 인지 구분 가능.
- 파일을 찾으려면 linear serach 를 해야한다 -> 시간이 많이 듬.
Hash Table

- linear list + hash
- Hash table 을 이용해서 file name 을 linear list 의 위치로 바꾼다.
- 해시 함수를 적용해서 변환하여 metadata 가 있는지 찾으면 됨.
- search time 은 없지만 충돌 발생 가능성이 있다.
- 해결은 자료구조의 해결 방식으로 하면 됨.
보관 방식
- 디렉토리 내에 직접 보관
- 디렉토리에는 포인터를 두고 다른 곳에 보관 eX) Inode, FAT
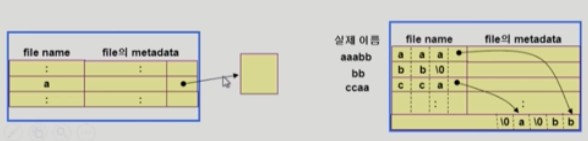
긴 file 이름 지원
- (file name, file metadata) list 에서 각 entry 는 일반적으로 고정적인 크기를 가짐.
- file name 이 고정 크기보다 커진다면??
- entry 마지막 부분에 이름 뒷부분이 위치한 곳의 포인터를 둔다.
- 이름 뒷 부분은 directory file 의 끝부분에 뒤부터 저장.
VFS and NFS
- 사용자가 File system 에 접근하려면 System Call 을 해야함.
- 그런데 File System 별로 System Call 형식이 다르다면? 매우 복잡하고 사용이 힘들 것임...
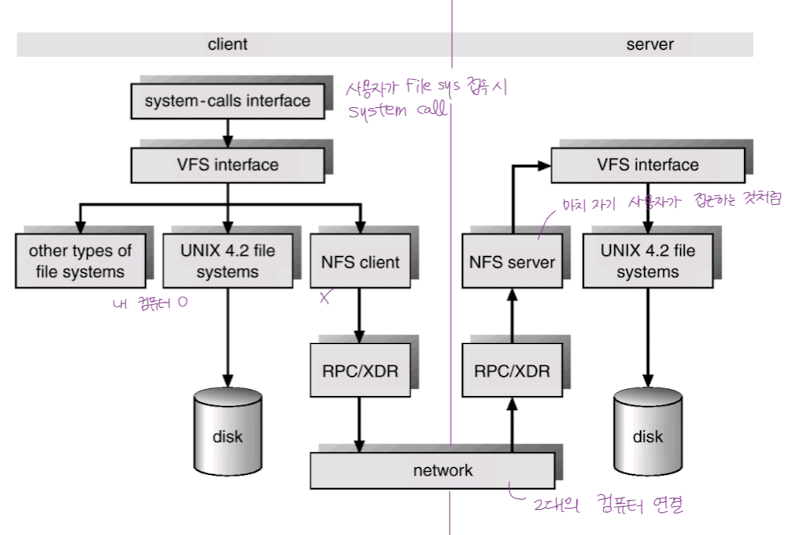
Virtual File System
- 서로 다른 다양한 File System 에 대해 사용자가 동일한 시스템 콜 인터페이스 (API) 를 통해 접근할 수 있게 해주는 OS 의 Layer
Network File System
- 분산 시스템에서 네트워크를 통해 파일이 공유될 수 있음.
- NFS : 분산 환경에서의 파일 공유 방법 (서버와 클라이언트 쪽에 둘 다 NFS 모듈이 있어야함.)
Page Cache and Buffer Cache
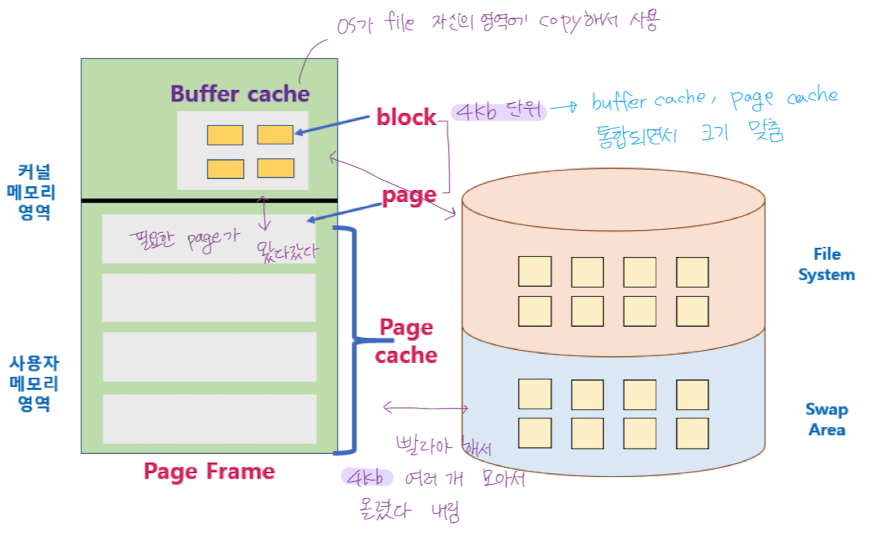
Page Cache
- Virtual Memory 의 Paging System 에서 사용하는 page frame 을 Caching 의 관점에서 Page Cache 라고 부름.
- Memory-Mapped I/O 를 쓰면, file 의 I/O 에서도 page cache 를 사용하게 된다.
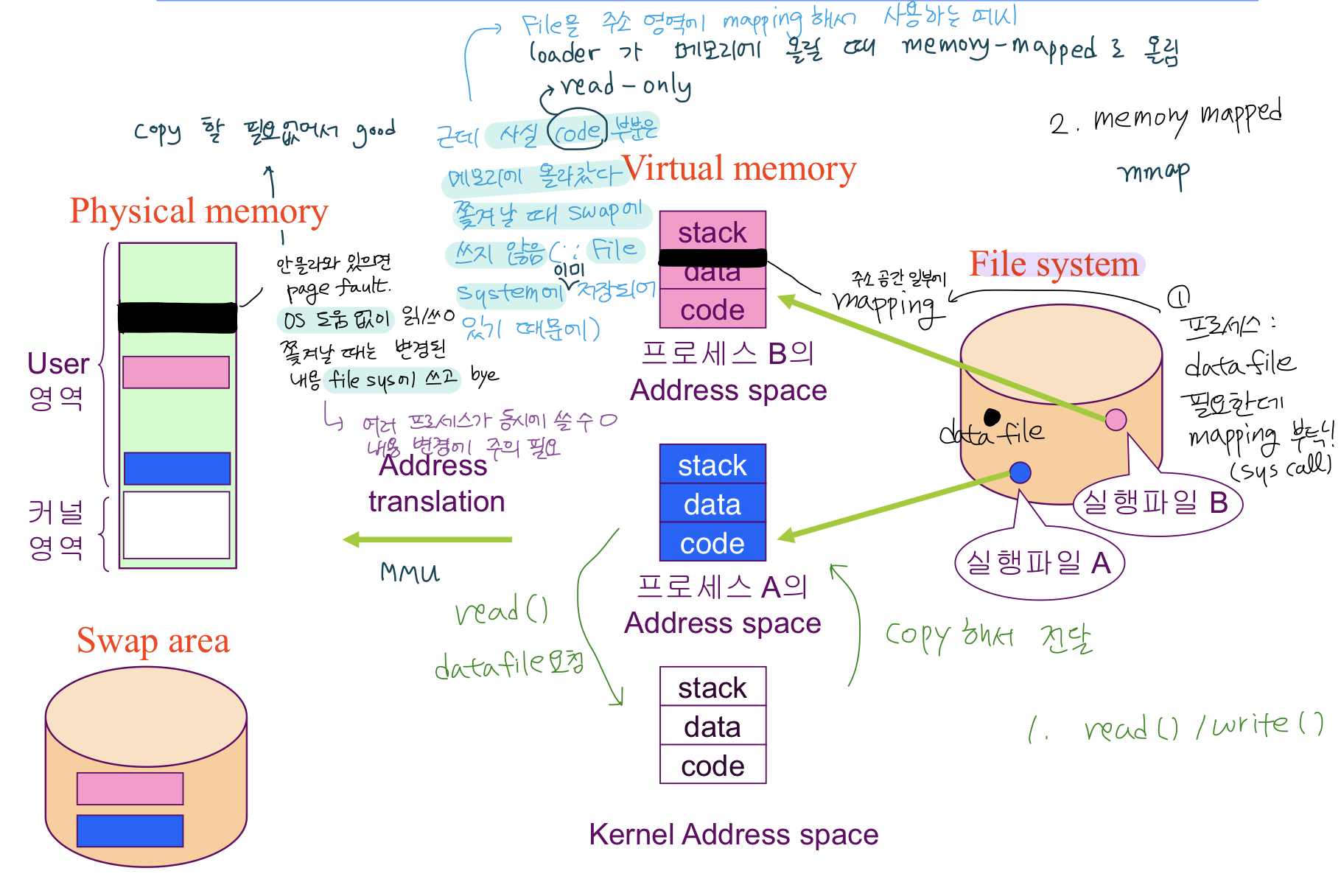
Memory-Mapped I/O
- 파일에 open read write 같은 system call 을 통해 접근하지 않고
- File 의 일부를 virtual memory (프로세스의 주소 공간 일부) 에 mapping 시켜서
- 매핑시킨 영역에 대한 메모리 접근 연산은 파일의 입출력을 수행하도록 했다.
- 한번 올리면 파일에 바로 읽고 쓰는 효과가 나도록.
Buffer Cache
- OS 가 I/O 를 통해 파일시스템에서 읽어온 내용을 메모리의 buffer cache 에 넣어두고 사용.
- 한번 읽어온 block 은 자주 사용하기 때문에 (File 사용의 locality) buffer cache 에 넣어놧다가 즉시 전달할 수 있도록.
- 모든 프로세스가 공용으로 사용
- Replacement Algorithm 필요 (LRU, LFU ...)
- 단위 : 논리적인 disk 블록 == disk 의 sector (512 byte)
Unified Buffer Cache
- 최근 OS 에서는 buffer cache 가 page cache 에 통합되어서 같이 관리된다.
- 버퍼 캐시에서 사용하는 단위도 페이지의 크기 4KB 를 사용하게 됨.
- Ex) LINUX
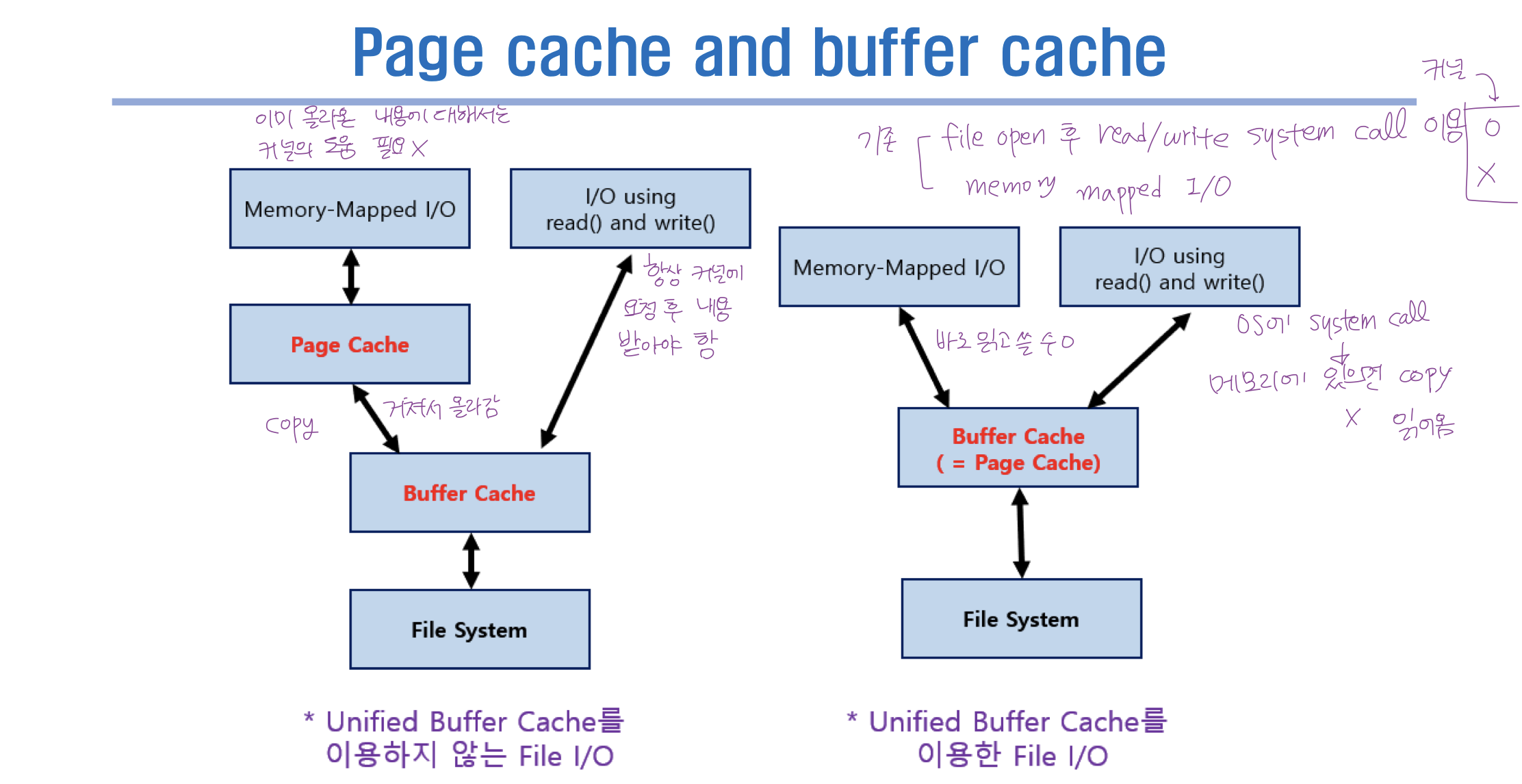
not unified
- not memory-mapped : read/write system call 이 들어오면 OS 가 buffer cache 에 있는지 보고 있으면 전달, 없으면 버퍼 캐시로 읽어옴.
- memory-mapped : 프로세스 주소 공간 일부를 파일에 맵핑. 버퍼 캐시에 읽어오고 -> 해당 내용을 page cache 에 copy -> 사용자 프로세스가 자신의 page cache 에 데이터를 메모리에 읽고 쓰듯이 요청하면 File 에 read / write 됨.
- 메모리에 맵만 해놓고 메모리에 내용 없으면 page fault 로 OS 에 CPU 넘겨서 읽어옴.
- 한번 올라오면 OS 의 도움 없이 메모리에 읽고 씀.
unifed
- not memory-mapped : 필요한 내용이 file system 에 있든 buffer cache 에 있든 OS 에게 CPU 제어권이 넘어감. 이미 메모리에 올라온 영역에 대해서는 buffer cache 에서 copy 없으면 Disk File System 에서 읽어옴.
- memory-mapped : 사용자 프로그램의 주소 영역에 Page Cache 에 매핑되기 때문에 buffer cache 에 있는 것이 copy 하지 않고 바로 사용 가능.
프로그램의 실행
출처 / 참고
반효경 교수님의 2014 운영체제 11. File System Implementaiton 2 강의를 듣고 포스팅하고,
공룡책을 읽고 추가 정리합니다.
사진 출처는 강의 자료.

0년차 iOS 개발자입니다.