
주소
메모리는 주소를 통해서 접근하는 HW
Logical Address ( = Virtual Address )
- 프로세스마다 독립적으로 가지는 주소 공간
- 각 프로세스마다 0부터 시작
- CPU 가 보는 주소!!!
Physical Address
- 메모리에 실제 올라가는 위치
주소 바인딩 (Address Binding)
- 주소를 결정하는 것
- Symbolic Address -> Logical Address -> Physical Address
- 변수, 함수 -> 0번지 부터 시작하는 주소 -> 실제 물리 주소
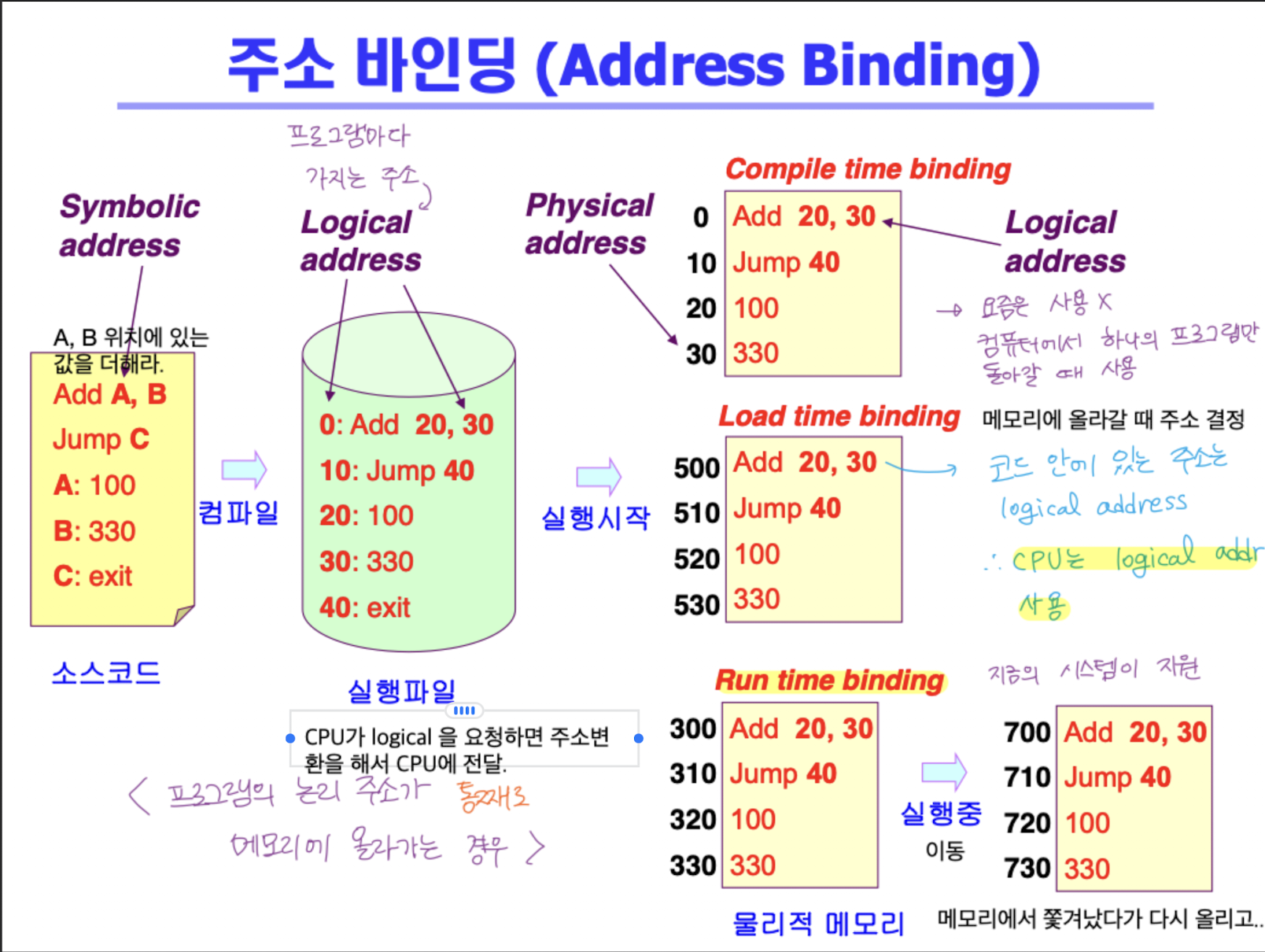
종류
Complie Time Binding
- 컴파일 할 때 프로그램이 올라갈 물리 메모리 주소 결정
- 시작 위치가 변경되면 재컴파일
- 컴파일러가 절대 코드(absolute code)를 생성한다.
- 절대 코드에 있는 주소에 그대로 올라감.
Load Time Binding
- 메모리에 올라갈 때 loader 가 메모리 주소 부여
- 컴파일러가 재배치가능코드(relocatable code) 를 생성
- 메모리에 비어있는 공간 어디에도 올라갈 수 있음
Execution Time Binding (= Run time binding)
- 프로그램의 수행이 시작된 이후에도 프로세스의 메모리 상 위치를 옮길 수 있음
- CPU 가 주소를 참조할 때마다 binding 을 점검 (address mapping table)
- CPU 가 바라보는 논리적인 주소를 실제 메모리 주소에 binding
- binding 을 점검하기 위해서 HW적인 지원이 필요하다.
- base and limit registers / MMU
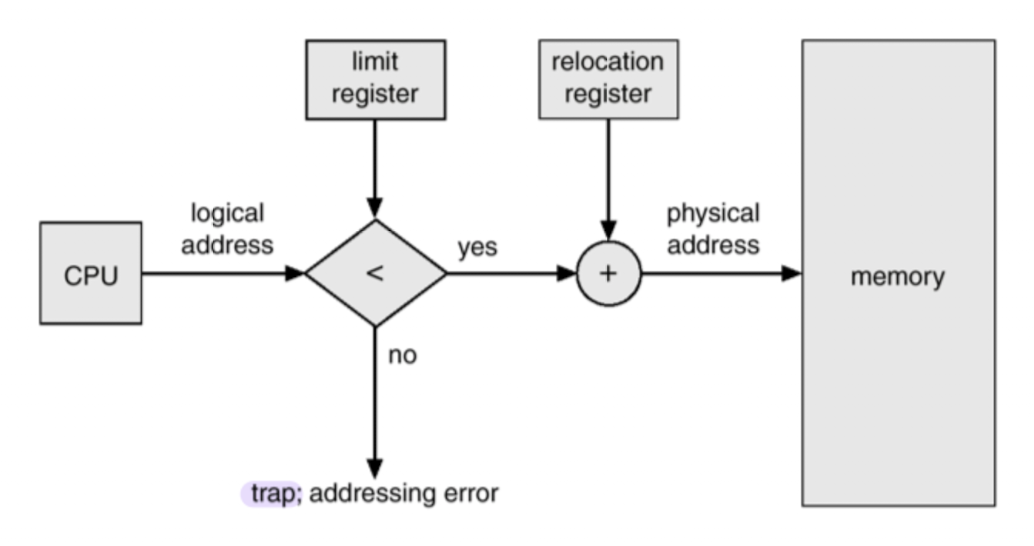
MMU (Memory-Management Unit)
- logical address --(mapping)--> physical address 하는 HW
- 2개의 레지스터를 가지고 변환한다. base and limit registers
- 사용자 프로세스가 CPU 에서 수행되며 생성하는 모든 주소값 + base register (= relocation register)
- 사용자 프로세스는 logical address 만 알고 physical address 는 모름.
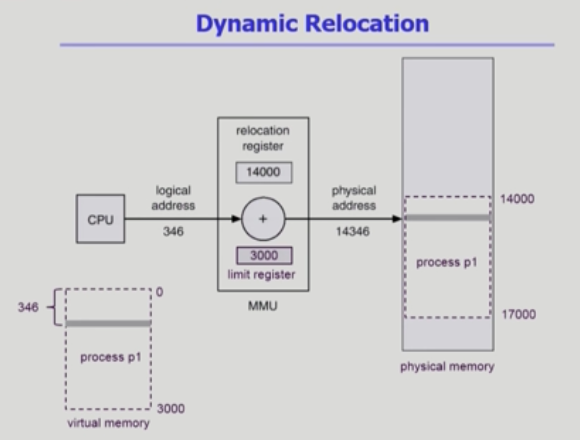
Dynamic Relocation
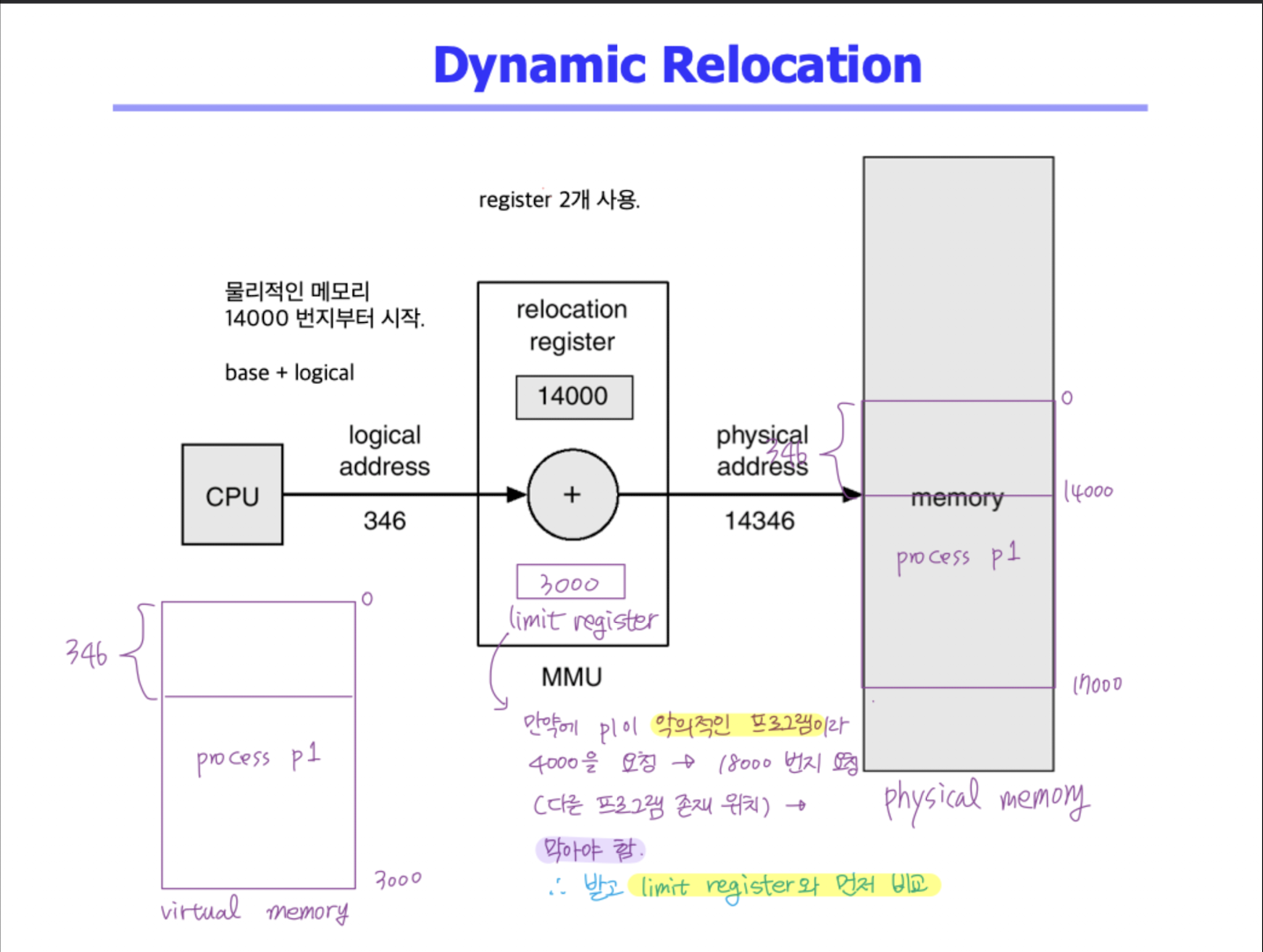
- Base (relocation) Register : 접근할 수 있는 물리적 메모리의 최소 값
- Limit Register : 논리적 주소의 범위
프로세스를 메모리에 로드하는 방법
Dynamic Loading
- 처음부터 프로세스 전체를 메모리에 다 올리지 않고 해당 루틴이 불릴 때 (필요할 때) 메모리에 동적으로 로드하는 것.
- 메모리 사용성 향상
- 사용이 덜 되는건 올려둘 필요가 없으니까!
- 사용이 자주 안되는 코드가 많을 때 유용하다.
- ex) 오류 처리 루틴
- OS 의 지원 없이 프로그램 자체에서 구현할 수 있다.
- Dynamic Loading 은 OS 의 페이징과는 다른 것!
- OS 에서는 라이브러리를 통해 지원 가능
Overlays
- 메모리에 프로세스에서 실제 필요한 부분만을 올린다.
- 프로세스 크기 > 메모리 일 때 유용
- OS 지원 없이 사용자가 구현한다.
- 작은 공간의 메모리를 사용하던 초창기 시스템에서 수작업으로 구현
- Manual Overlay
- 지원해주는 것이 없기 때문에 프로그래밍이 매우 복잡
Swapping
- 프로세스를 일시적으로 메모리에서 backing store (swap area) 로 통째로 쫓아내는 것.
- Paging 에서는 일부만 쫓겨나는 것도 swap-out 이라고 부름.
- Swap Area : 사용자 프로세스 이미지를 많이 담을 만큼 빠르고 큰 저장 공간
Swap in / out
- 중기 스케줄러(Swapper) 에 의해 swap out 시킬 프로세스를 선정한다.
- priority-based CPU seheduling algorithm
- priority 가 낮은 프로세스를 swap out 하고 높은 프로세스를 메모리에 올려놓는다.
- Compile time / load time binding 에서는 항상 처음에 올라왔던 메모리 위치로 swap in 해야함.
- 비효율적. 다른 메모리가 비어있어도 여기로만 올라와야 하니까
- Execution time binding 에서는 빈 메모리 영역 아무데나 올릴 수 있다.
- Swap time ∝ transfer time ∝ Swap 되는 데이터 양
- 디스크 같은 경우는 trasfer time <<< seek time
Dynamic Linking
- Linking 을 실행 시간까지 미루는 방법.
- Link : 컴파일 해서 여러 소스를 묶어 실행 파일을 만드는 과정.
Static Linking
- 라이브러리가 프로그램의 실행 파일 코드에 포함됨
- 동일한 라이브러리를 각 프로세스가 메모리에 올리므로 메모리 낭비
Dynamic Linking (= Shared Library)
- 라이브러리가 실행 시 연결됨
- 라이브러리 호출 부에 라이브러리 루틴을 찾기 위한 stub 이라는 작은 코드를 둬서
- 라이브러리가 이미 메모리에 있으면 그 주소로 가고, 없으면 디스크에서 읽어올 수 있게 한다.
- OS 의 도움이 필요하다.
Allocation of Physical Memory
영역
일반적으로
OS 상주 영역
- interrupt vector 와 함께 낮은 주소 영역 사용.
사용자 프로세스 영역
- 높은 주소 영역 사용
으로 나누어서 사용한다.
사용자 프로세스 영역의 할당 방법
- Contiguous Allocation
- Fixed partition allocation
- Variable partition allocation
- Noncontiguous Allocation
- Paging
- Segmentation
- Paged Segmentation
Contiguous allocation
- 각 프로세스가 메모리의 연속적인 공간에 적재되도록 하는 것
- 시작 주소만 알면 되기 때문에 메모리 변환이 간단하다.
외부 조각
- 프로그램 크기보다 분할의 크기가 작은 경우
- 아무 프로그램에도 할당되지 않은 빈 메모리 공간인데 프로그램이 올라갈 수 없는 작은 조각.
- 프로그램이 실행되고 종료되고 하면서 외부 조각이 발생하게 된다.
내부 조각
- 프로그램 크기보다 분할의 크기가 큰 경우
- 하나의 분할 내부에서 사용하지 않는 메모리 조각 발생.
- 특정 프로그램에 할당됐지만 사용되지 않는 공간.
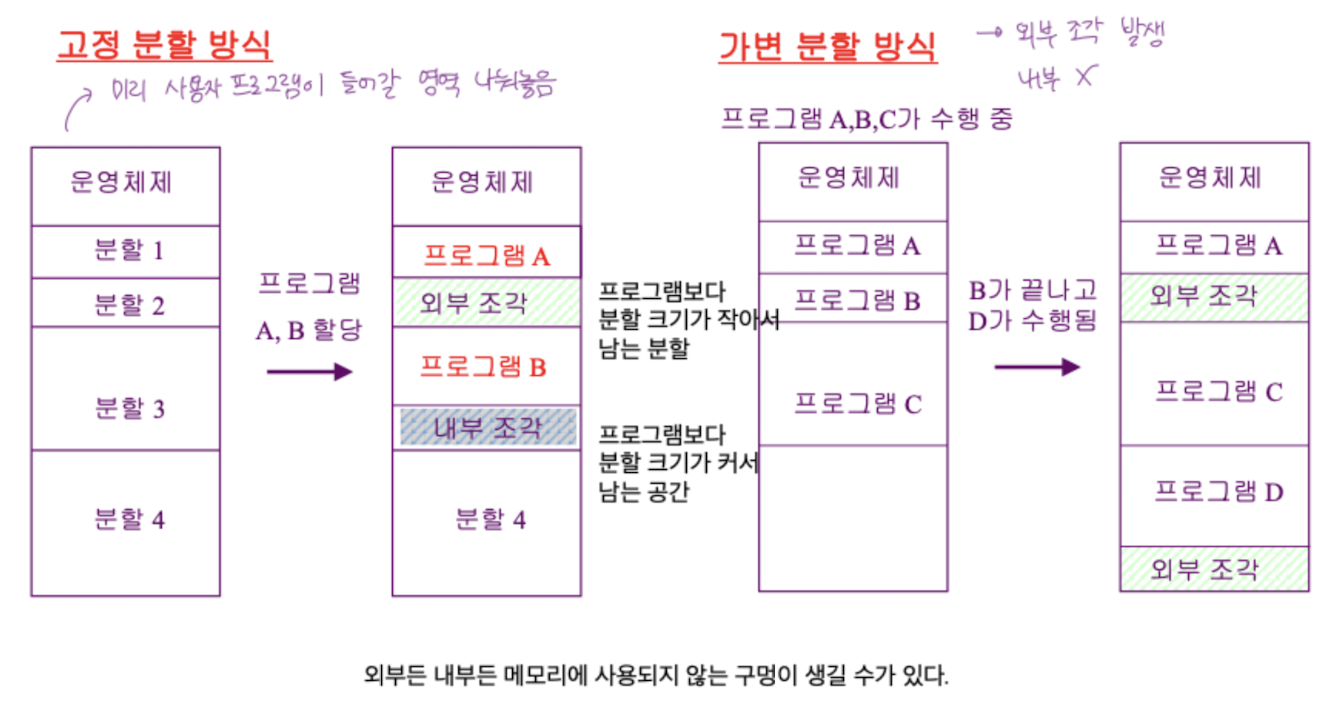
고정 분할 방식 (Fixed partition allocation)
- 물리적 메모리를 몇 개의 영구적인 분할 로 나눈다.
- 분할의 크기를 모두 같게 할수도 있고 서로 다르게 할 수도 있음.
- 분할 당 하나의 프로그램을 적재한다.
- 융통성 X 비효율적
- 동시에 메모리에 로드되는 프로그램 수가 고정되고,
- 최대 수행 가능 프로그램 수도 정해져 있음.
- Internal Frgmentation / External Fragmentation 모두 발생
가변 분할 방식 (Variable partition allocation)
- 프로그램 크기를 고려해서 할당한다.
- 분할 크기, 개수가 동적으로 변환됨.
- 기술적 관리 기법 필요
- External Fragmenatation 만 발생.
Hole
- 가용 메모리 공간
- 다양한 크기의 홀이 메모리에 흩어져 있다.
- 프로세스가 도착하면 해당 프로세스를 수용할 수 있는 홀을 할당해준다.
- OS 는 두 정보를 유지.
- 할당 공간
- 가용 공간 (hole)
- 프로세스에 홀을 할당해주고 프로세스가 끝나면 홀을 다시 돌려받고!
Dynamic Storage-Allocation Problem
가변 분할 방식에서 size n 인 요청을 만족하는 가장 적절한 hole 을 찾는 문제.
- First-Fit
- size n 이상인 것 중 최초 hole 에 하랑
- Best-Fit
- size n 이상인 가장 작은 hole 을 찾아서 할당.
- hole 리스트가 정렬되지 않은 경우, 순차 탐색.
- 아주 작은 hole 이 많이 생성된다.
- Worst-Fit
- 가장 큰 hole 에 할당.
- 순차 탐색 필요.
- 상대적으로 큰 hole 이 생성된다.
- First / Best > Worst - 속도, 공간 면에서.
Compaction
- External Fragmentation 문제를 해결하는 방법 중 하나.
- 사용 중인 메모리 영역을 한군데로 몰고, hole 을 다른 한쪽으로 몰아서 큰 block 을 만든다.
- 전체 프로그램의 binding 을 다시 확인하고 만들어야 하므로 매우 비용이 많이 듬.
- 최소한의 메모리 이동으로 compaction 하는 것 자체가 복잡한 방법이다.
- 프로세스 주소가 실행 시간에 동적으로 재배치가 되는 경우에만 수행할 수 있다. -> Run-time Binding 이어야 가능.
Noncontiguous allocation
- 하나의 프로세스가 메모리 여러 영역에 분산되어 올라갈 수 있다.
- 현대의 OS 는 Noncontiguos Allocation 을 사용해서 메모리에 프로세스를 어떤 단위대로 올리고 내린다.
- 메모리에 올리고 내릴 때 주소 공간을 변환하는 Dynamic Programming 을 하기는 어려워진다. 이렇게 직접 컨트롤 해도 페이지 단위로 올라가니까.
Paging
- 동일한 크기로 자름.
- base register : page table 의 시작 위치
- limit register : page table 의 길이
TLB, 2단계 페이징, 다단계 페이징
TLB
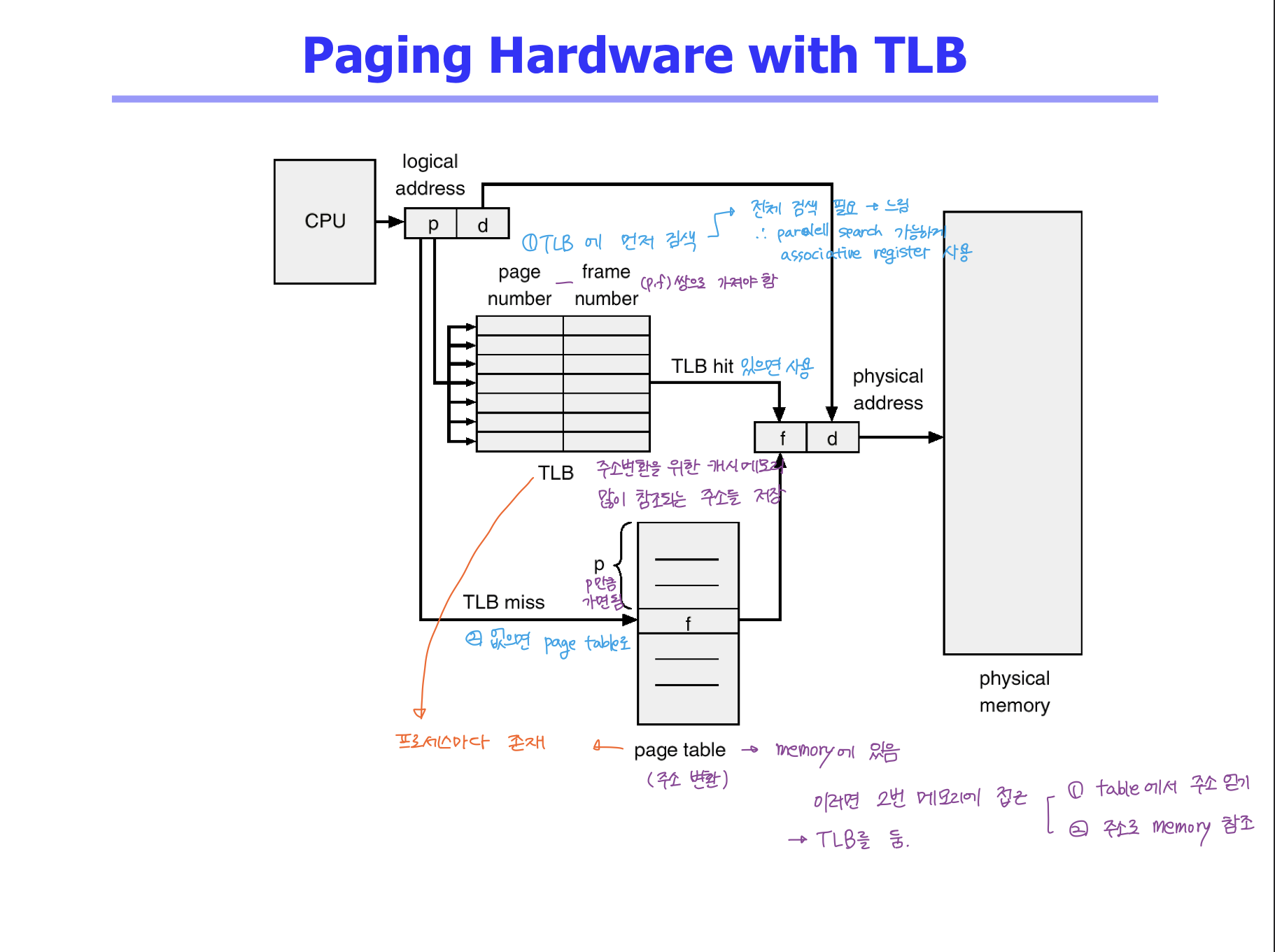
- 메모리 주소 변환을 위한 캐시 메모리 (HW)
- 페이지 테이블에서 빈번하게 사용되는 일부 엔트리를 캐싱해둠.
- TLB 에 없으면 메인 메모리 내의 page table 이용해서 찾는다.
- (논리적인 페이지 번호 p, p가 있는 물리적 메모리 주소 f) 를 가지고 있음.
- TLB 에서 검색하려면 특정 항목만 검색할 수가 없음 -> 전체 항목에 대해 다 찾아봐야 함. (시간 오래 걸림) -> parallel search 가 가능한 Associative Register 사용.
- TLB 에 있는 정보는 context switch 가 일어날 때 flush 해서 모든 데이터 비움.

- 입실론은 작고 a 는 큰 값
- page table << TLB (속도)
Two-Level Page Table
- 페이지 테이블이 2개 있어서 안쪽 / 바깥쪽 나누어짐
- 주소 변환 시 2번 변환 -> 공간을 절약하기 위해서.
- 현대의 컴퓨터는 32 bit (2^32 개의 정보 표현 가능), 64 bit 로 매우 큰 프로그램을 지원하기 때문.
- 2^10 = K, 2^20 = M, 2^30 = G
- 페이지 크기가 4K 라면, 해당 페이지 테이블을 나타내기 위해서 2^12 (페이지 크기) * 2^20 (개수) 이므로 1M (2^20) 개의 page table entry 가 필요.
- 각 page entry 크기가 4B 라면 2^2 * 2^20 = 4 MB 의 page table 필요.
- 별로 안큰데? 라고 생각할 수도 있지만, 각 프로그램마다 페이지 테이블이 있고... 대부분의 프로그램은 4G 의 주소 공간 중 매우매우매우 조금의 공간만 사용하므로 page table 로 인해 공간 낭비 심각. (안쓰는 공간인데 페이지 테이블을 만들어야함)
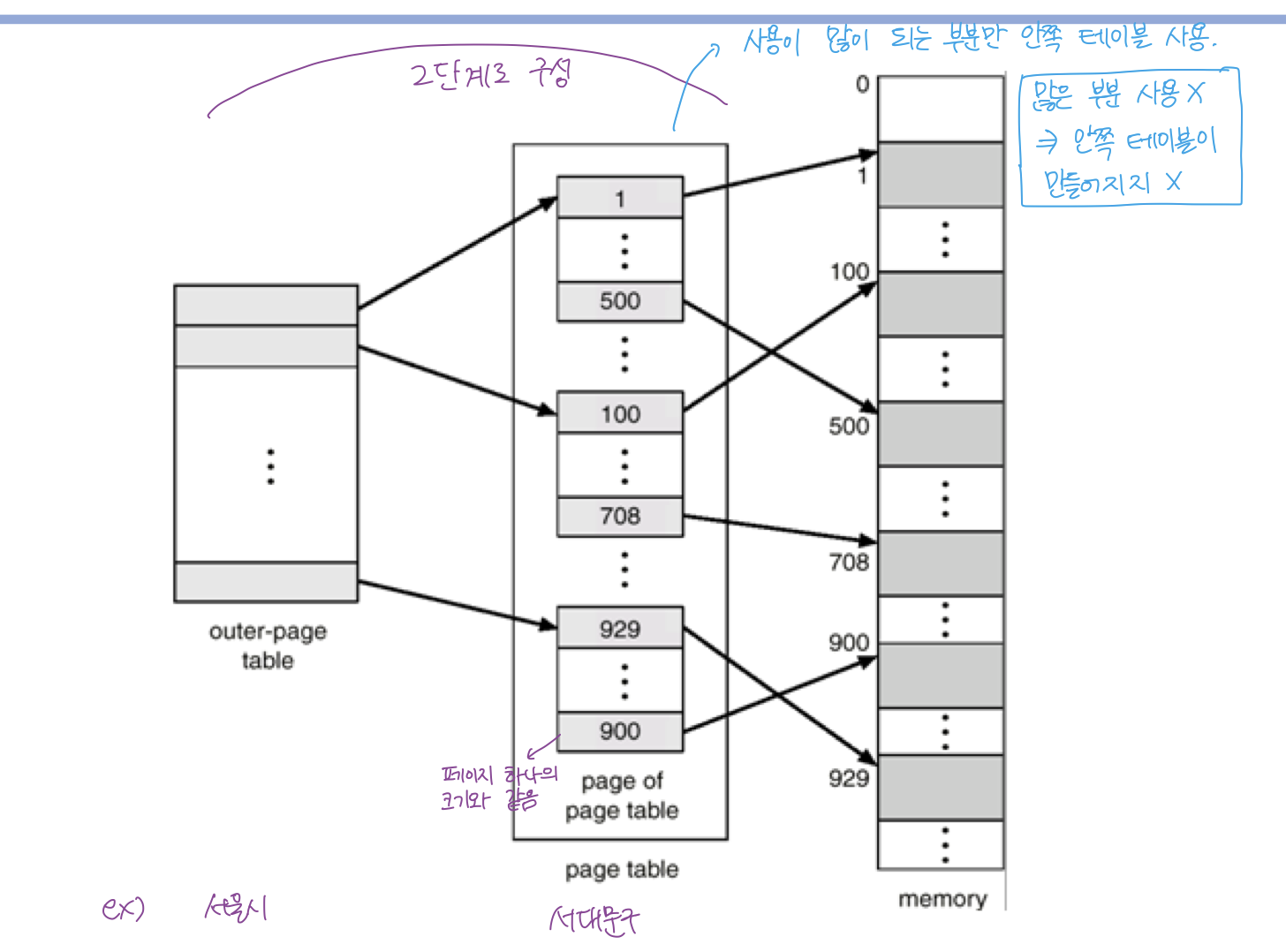
- 사용되는 주소 공간은 inner page table 로 이동해서 주소 변환.

- 바깥쪽 페이지 테이블 엔트리 하나 당 안쪽 페이지 하나 매칭
- p1 : 바깥쪽 페이지 테이블의 페이지 번호
- p2 : 안쪽 페이지 테이블의 페이지 번호
- d : 실제 메모리에서 p2 에 있는 page frame 번호에서 얼마나 떨어져 있는지
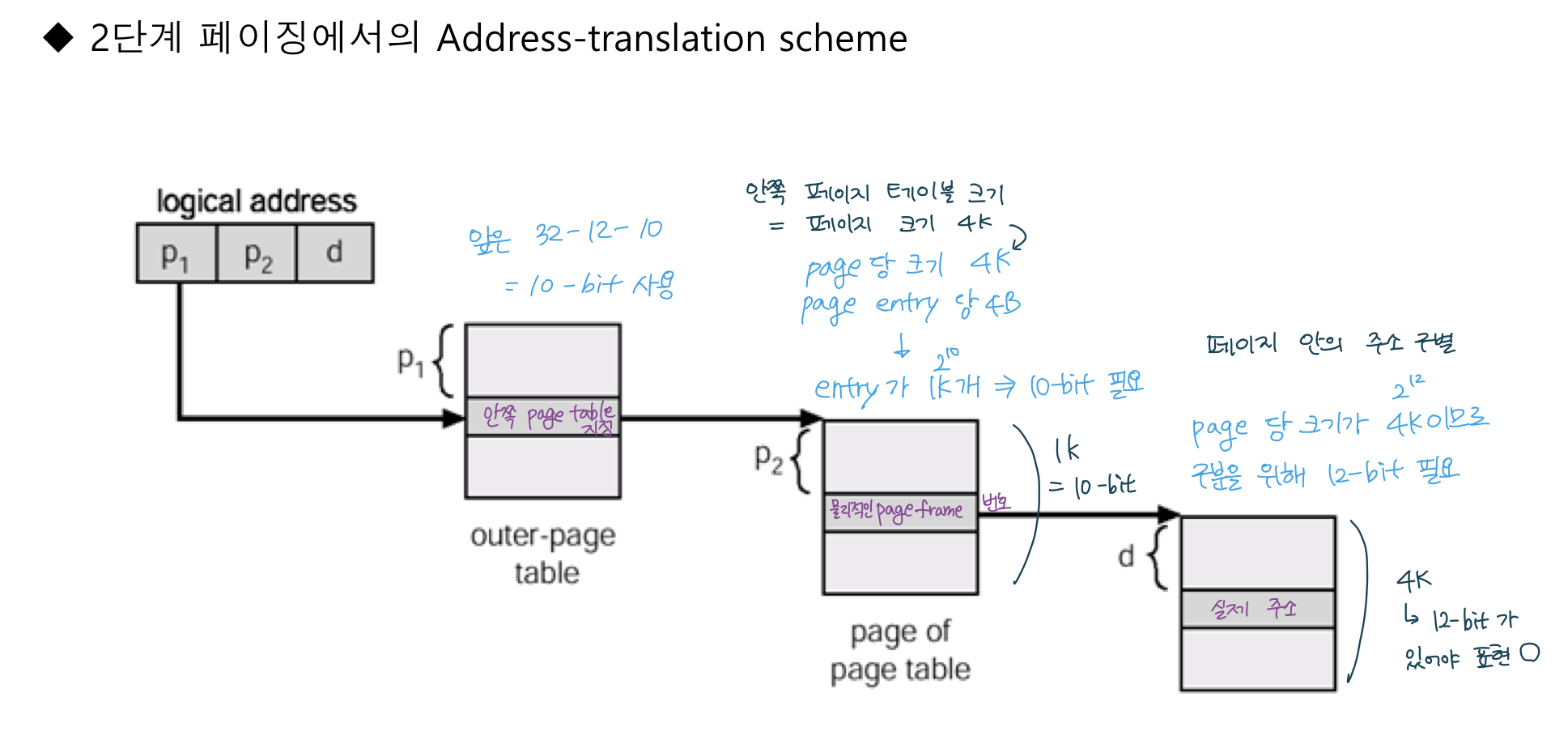
안쪽부터 따라가면 크기를 알 수 있음.
- d (offset)
- 한 페이지 안에서 구분하려면 몇 개가 필요한지.
- page 하나 당 크기가 4K (2^12) 이므로 페이지 안의 주소 구분을 위해 12-bit 가 필요
- p2
- 안쪽 페이지 테이블 크기 = 페이지 크기 (4K)
- 엔트리 하나 당 4B 라면
- 페이지 테이블에 1K (2^10) 개가 들어갈 수 있으므로 10-bit 필요.
- p1
- 32 - 12 - 10 = 10
- page table 자체를 page 로 구성
- 사용되지 않은 주소 공간에 대한 outer page table 엔트리 값을 NULL 로 만든다.
- 사용 안하는 주소 공간에 대해서는 안쪽 페이지 테이블을 안만들어도 되기 때문에 공간이 매우 절약됨.
Multi-level Paging
- 2단계 이상의 페이지 테이블
- 주소 변환을 위해 많은 메모리 접근(단계 개수 + 실제 접근 1)이 필요.
- 하지만, 대부분의 메모리 접근은 TLB 를 통해서 이루어지므로, 속도가 크게 저하되지 않는다.
- 4단계 페이지 테이블에서 메모리 접근 시간 100ns, TLB 접근 시간이 20ns 이고,
- TLB hit ratio 가 98% 라면
- effective memory access time = 0.98 120 + 0.02 520 (TLB 접근 + 4단계 페이징 + 실제 메모리 접근 1) = 128 ns
- 주소 변환을 위해 28ns 가 소요되는 것. (메모리 접근 시간은 28% 정도만 down)
Valid / Invalid Bit in Page Table
page table 에는 해당 페이지로 가는 주소만 적혀있는 것이 아니라 추가적인 정보를 담는 비트가 존재. -> Valid / Invalid & Protection
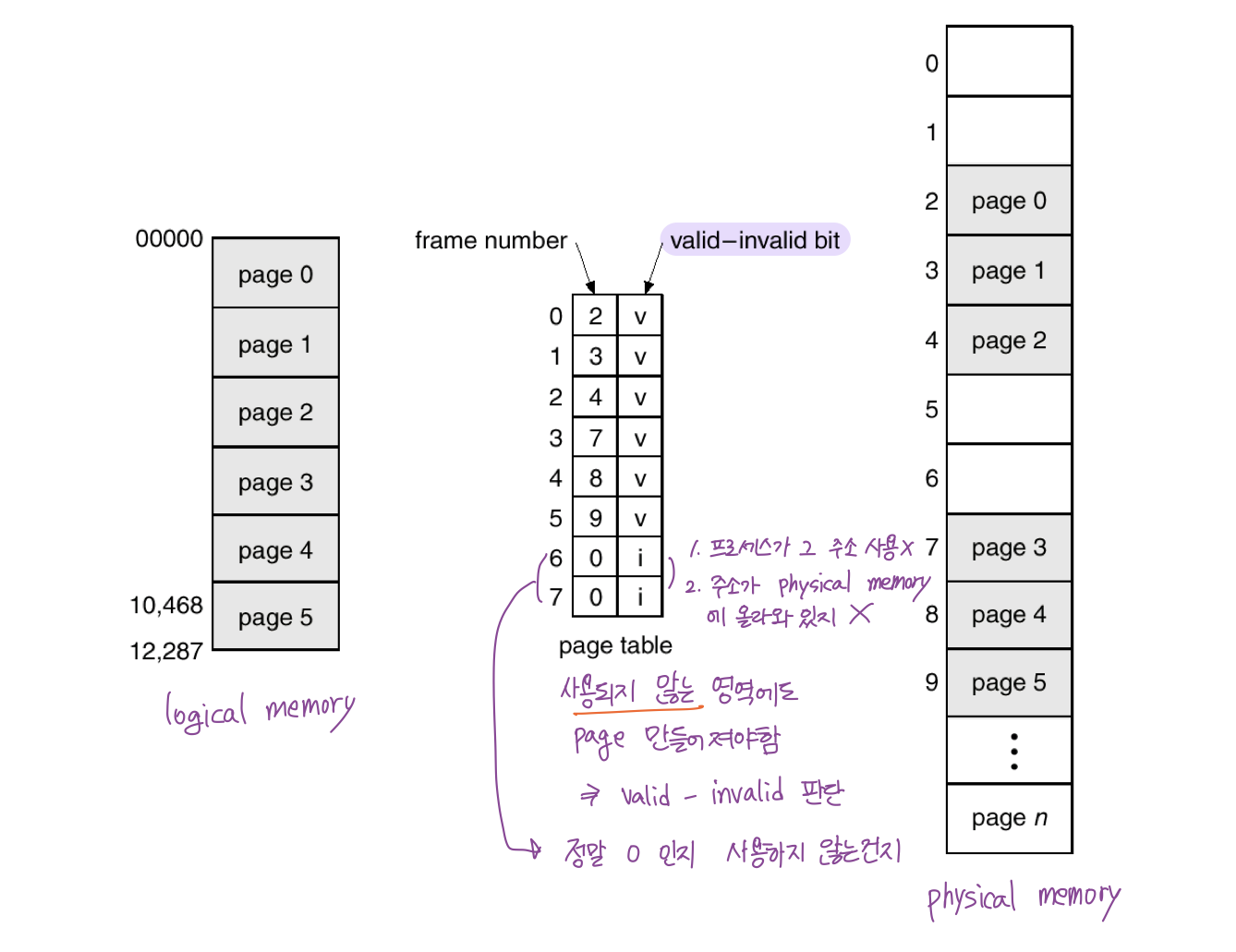
- table 자료구조 특성 상, 인덱스를 이용해서 접근하기 때문에 사용되지 않는 구역도 page table entry 가 만들어져야 함. -> valid / invalid 구분 필요.
- invalid
- 해당 주소를 사용하지 않거나
- 주소가 physical memory 에 올라와있지 않음
Protection bit
- page 에 대한 접근 권한 (read & write / read-only)
- 어차피 해당 메모리 공간에는 해당 프로그램만이 접근하기 때문에
- 이 권한은 연산에 대한 권한
- ex) code, data, stack 에서 code 부분은 내용이 바뀌면 안됨. -> read-only
Inverted Page Table
- page table 의 문제 : 너무 큰 공간을 차지
- 모든 프로세스별로 해당 logical address 에 대응하는 모든 page 에 대한 page table entry 존재.
- 대응하는 페이지가 있든 없든 page table entry 존재
이런 문제를 해결해보고자 역으로 사용!
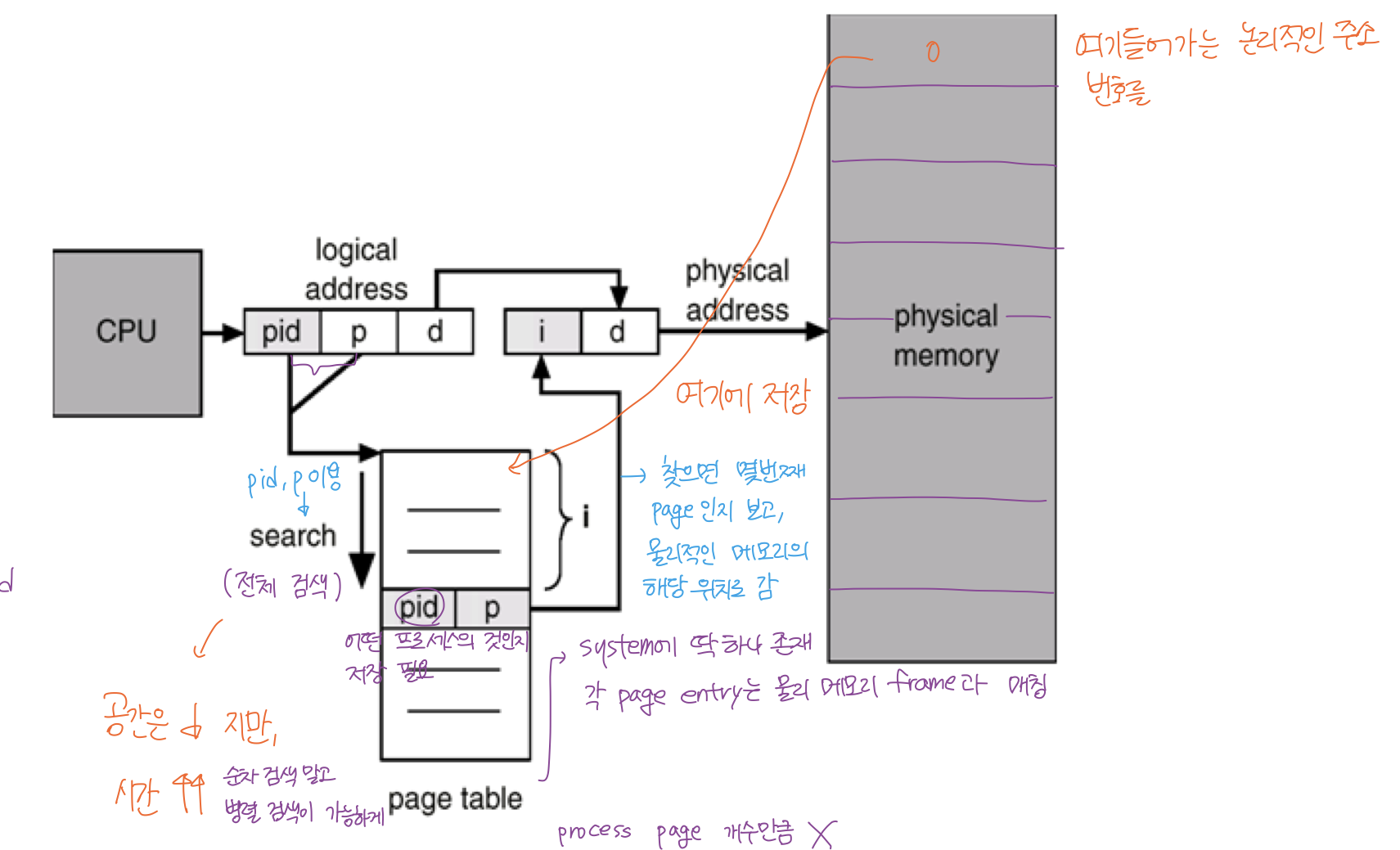
- 원래는 프로세스마다 존재하던 page table 을
- page frame 하나 당 page table에 하나의 entry 를 두게 바꿔서
- 각 시스템에 page 가 하나만 존재.
- 각 page table entry 는 각 물리적 메모리의 page frame 이 담고 있는 내용 표시 (process-id, process logical address)
- physical -> logical 을 하는 테이블임.
- 단점 : 페이지 테이블 전체를 탐색해야함. 시간이 오래 걸림.
- associative register 를 사용하여 병렬 탐색 but 비쌈.
Shared Pages
- 같은 프로그램을 돌리면 code 부분(Re-entrant Code == Pure Code) 은 share 해도 됨.
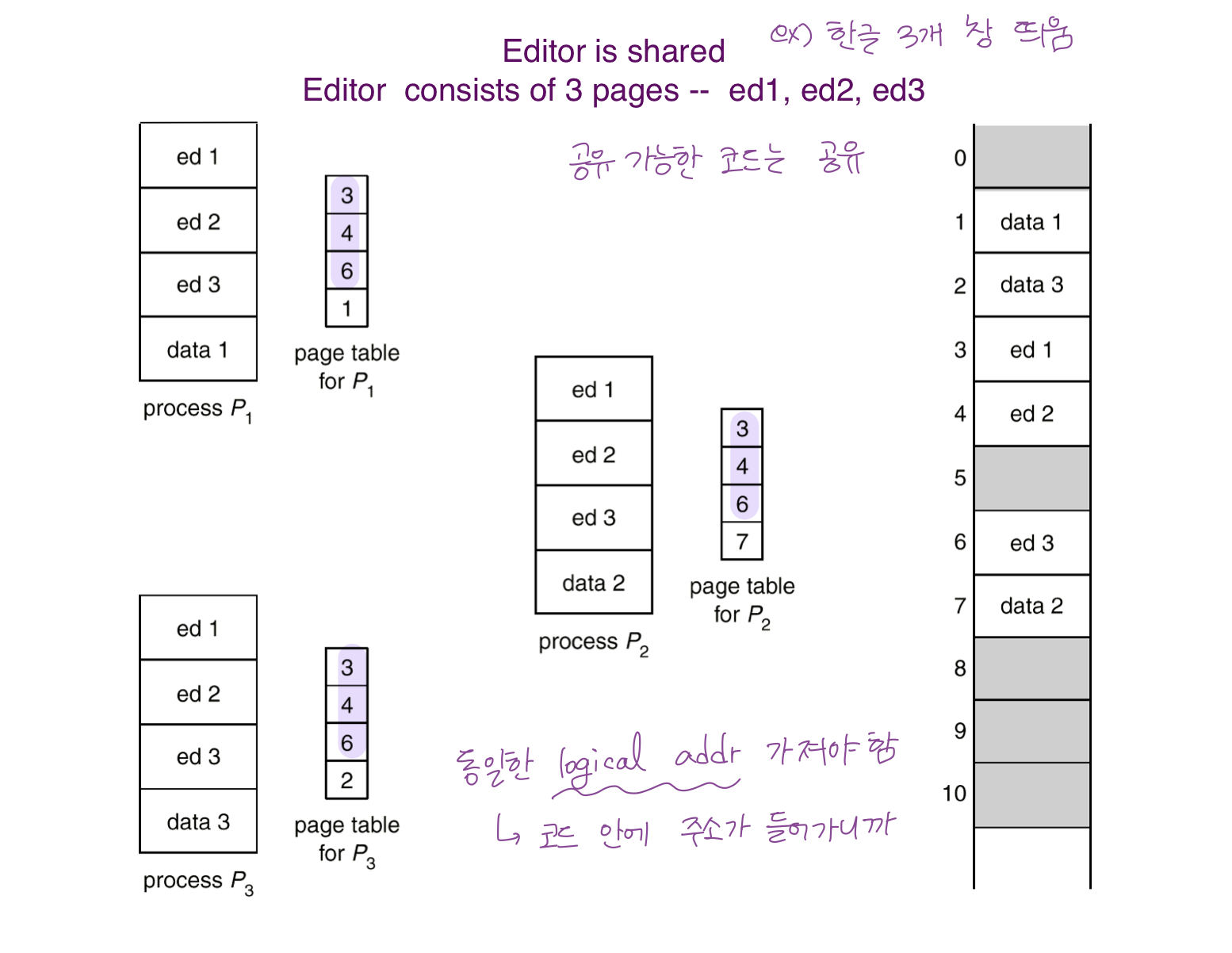
- read-only 로 프로세스 별로 하나의 코드만 메모리에 올림
- 대신 Shared Code 는 모든 프로세스의 logical address space에서 동일한 위치에 있어야 함.
- Why? 코드가 컴파일 되면 변수가 logical address 로 변환되어서 저장되기 때문.
- Private code and data
- 각 프로세스가 독자적으로 메모리에 올리고,
- logical address space 에서 어디에 있어도 무방.
Segmentation
- 의미 단위로 자름 (ex. 스택, 데이터, 코드 / 함수 하나하나 / 프로그램 전체)
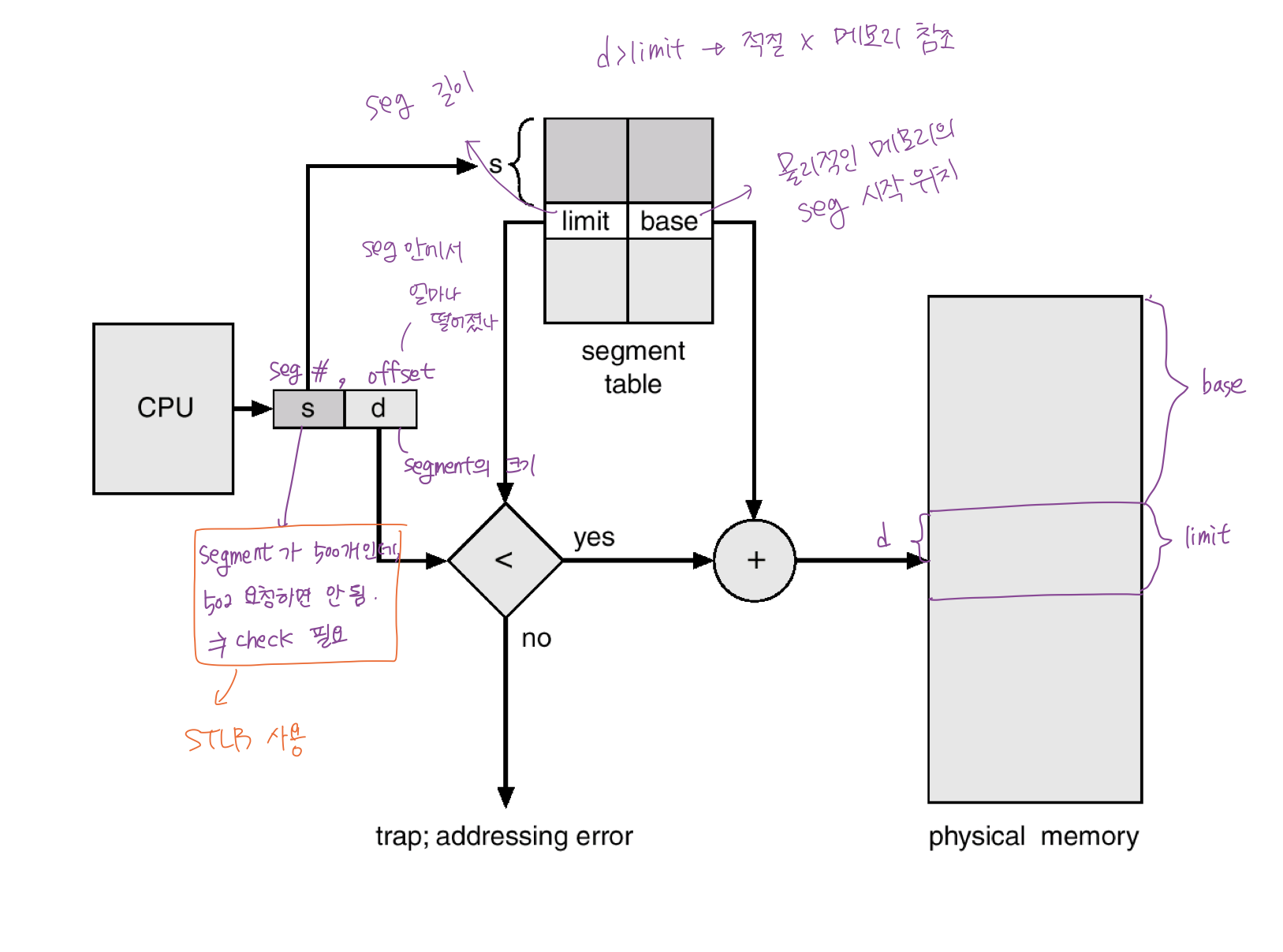
Segment table
- 각 세그먼트 별로 주소 변환
- entry 하나는 <segment-number, offset> 으로 구성되어 있음.
- Segment table
- 각 테이블 entry 가 <base, limit> (<물리적 메모리에서 해당 세그먼트의 시작 주소, 해당 세그멘트의 길이>) 을 가지고 있다.
- 각 세그먼트의 길이가 다 다르니까.
- offset < 세그먼트 길이 인지 체크해야함.
- Paging 과 다른 점
- Paging 은 frame 크기가 정해져 있어서 몇 번 프레임인지만 알면 됐음.
프로세스가 Segment table 에 대해 가지는 정보
- 주소 변환을 위한 테이블에 대한 정보
- STBR (Segment-table base register)
- 물리적 메모리에서의 segment table 의 위치
- STLR (Setment-table limit register)
- 프로그램이 사용하는 segment 개수 (== entry 개수)
- 논리적인 segment 번호 s < STLR 인지 체크해야함.
Protection
Segmentation 의 장점
- 각 세그멘트 별로 Protection bit 가 있음.
- 각 엔트리 별로 Valid / Read/Write/Execution 권한 bit 을 줄 수 있다.
- Paging 의 경우.. Read-only 와 Write 인 영역이 한 페이지로 묶인다면...? 복잡해짐.
Sharing
Segmentation 의 장점
- Shared Segment
- Same Segment Num
의미 단위라서 공유하는 곳만 세그멘트로 묶어서 효과적으로 공유 가능.
Allocation
Segmentation 의 단점 == 고정 분할에서 가변 분할 방식의 단점
- 메모리 크기가 균일하지 않기 때문에 First Fit, Best Fit 을 사용해야하고,
- 외부 조각 발생.
Paging vs Segmentation
일반적인 시스템 기준.
| Paging | Segmentation | |
|---|---|---|
| 단위 | 크기 | 의미 |
| Hole | X | 외부 |
| page 개수 | 많음 | 적음 |
| table 크기 | 큼 | 작음 |
| 메모리 낭비 | 큼 | 적음 |
Paged Segmentation
- 시스템에서 original segmentation 을 쓰는 경우는 거의 없음
vs pure segmentation
- segment 를 여러개의 페이지로 구성
- segment-table entry 가 segment 의 base address 가 아니라 segment를 구성하는 page table 의 base address 를 가진다.
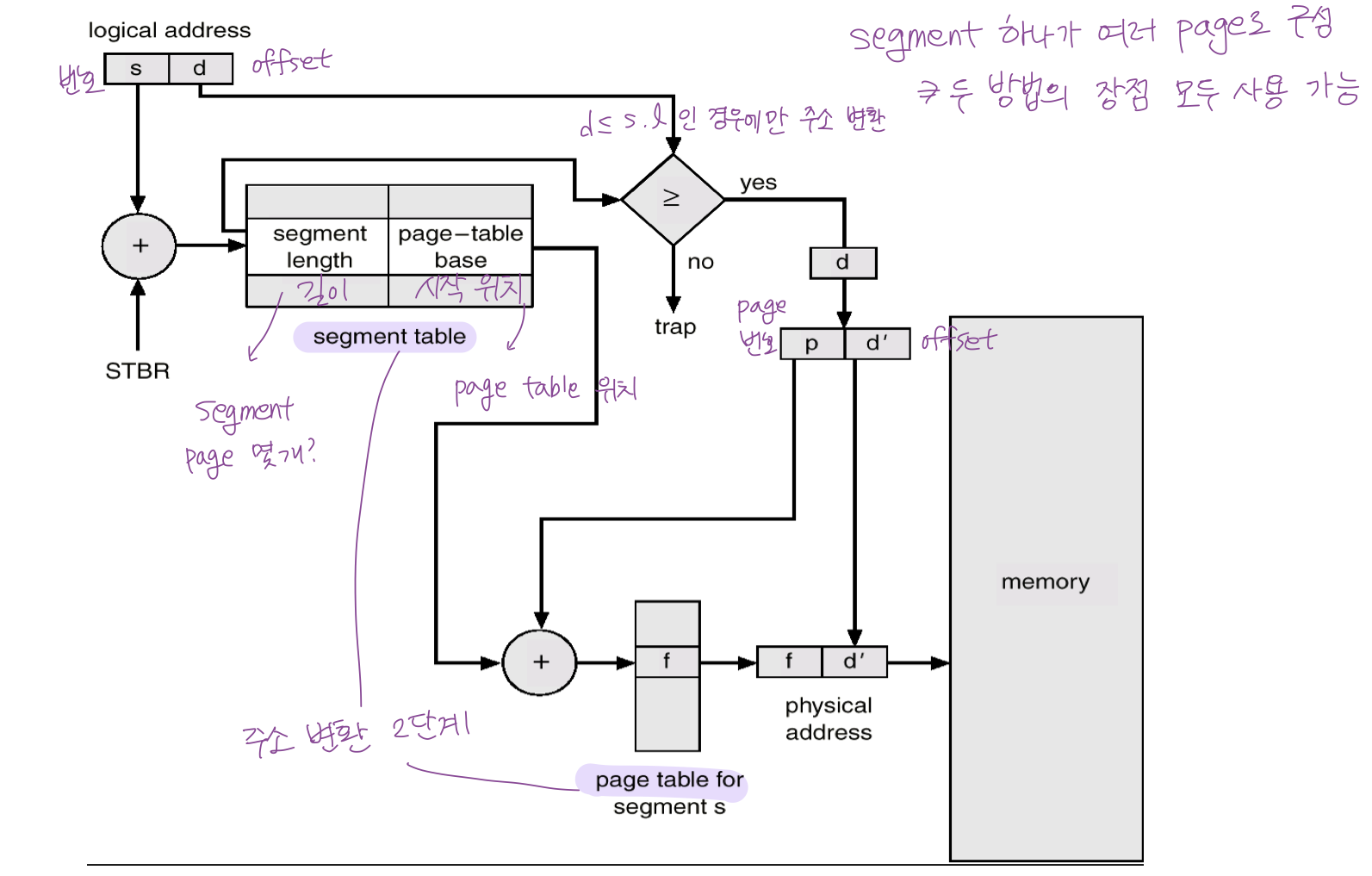
- hole 이 안생김 -> 메모리에는 페이지 단위로 올라가니까
- segment 단위라 의미 단위로 하는 일에도 효율적
- 이 챕터는 물리적인 메모리 관리. 주소 변환 이 가장 중요함.
- 주소 변환에 있어서 OS의 역할? 없음.. MMU 라는 HW 를 통해서 처리함.
- CPU 가 논리적인 주소를 가지고 메모리에 접근하는 것이기 때문. (OS가 만약 해주게 되면... 메모리 접근 시마다 OS 에 CPU 를 줘야하는데... 너무 비효율적. OS 역시 메모리에 올라가 있는 CPU 를 잡고 실행하는 프로그램일 뿐임..)
- OS가 필요할 때? CPU 는 I/O 에 접근이 안되기 때문에 OS 에게 시킴.
출처 / 참고
반효경 교수님의 2014 운영체제 8. Memory Management 2 3 4 강의를 듣고 포스팅하고,
공룡책을 읽고 추가 정리합니다.
사진 출처는 강의 자료.

0년차 iOS 개발자입니다.