
들어가기 전에 헷갈리지 말 것!
Collection은 인터페이스, Collections는 클래스**!!!!
과장 조금 보태서 책 부피의 0.3 정도는 이 단원이 차지하지 않을까 하는 생각을 한다. 그만큼 우리가 개발할 때 자주 사용하는 프레임워크이다! 그렇기에 더욱 무엇인지 잘 알아야 한다고 생각하고!
자바는 Java API(패키지)를 통해 개발자들이 자바 Application을 쉽게 개발할 수 있도록 돕는다. 따라서 개발 전에 어떤 패키지를 사용하면 좋을 지 찾아보고 생각해 볼 필요가 있다.
책에서는 3가지 그룹으로 자주 사용되는 클래스를 나눠주었다.
(java.util 패키지 중심)
- Collection Framework
- 유용한 클래스
- 형식화 클래스
[컬렉션 프레임워크]
= 데이터 군(group)을 저장하는 클래스(ex. 벡터)들을 표준화한 설계
- 인터페이스, 다형성을 통한 객체지향적 설계를 통해 표준화돼 있기 때문에 사용법을 익히기에 편리하고, 재사용성이 높은 코드를 작성할 수 있음
JDK 1.2부터 컬렉션 프레임워크를 통해 다양한 종류의 컬렉션 클래스를 표준화된 방식으로 다룰 수 있도록 체계화 됨
컬렉션 = 다수의 데이터 / 프레임워크 = 표준화된 프로그래밍 방식
▼ 핵심 인터페이스(List, Set, Map)
List와 Set은 공통된 부분이 맣아 이들을 다시 뽑아 Collection 인터페이스를 정의할 수 있었으나, Map 인터페이스는 전혀 다른 형태의 집합을 다루기 때문에 같은 상속 계층도에 포함되지 못한다.
Collection Framework의 모든 클래스들은 List, Set, Map 중의 하나를 구현하고 있고 그 이름 안에 위 세가지의 이름이 포함돼 있어 이름만으로도 클래스의 특징을 파악할 수 있다.
(Vector, Stack 등은 이 프레임워크가 생기기 이전부터 존재했으므로 위의 명명법을 따르지 않음)
- List
- 순서가 있는 데이터의 집합
- 데이터의 중복 허용
ex. 대기자 명단 / ArrayList, LinkedList, Stack, ..
- Set
- 순서를 유지하지 않는 데이터의 집합
- 데이터의 중복 허용 X
ex. 소수의 집합 / HashSet, TreeSet
- Map
- 키와 값의 쌍으로 이뤄진 데이터 집합
- 순서 유지 X, key는 중복 X, value는 중복 O
ex. 우편번호 / HashMap, TreeMap, Hashtable
Collection Interface
- 주로 데이터를 읽기, 추가, 삭제 등의 기본적인 메서드를 정의
-
add(Object o),addAll(Collection c) -
clear -
contains(Object o),containsAll(Collection c) -
equals(Object o) -
hashCode() -
isEmpty() -
iterator()
Iterator라는 단어가 익숙치 않아 실제로 어떻게 사용되는지 보았다.
LinkedList<Integer> list = new LinkedList<Integer>();
list.add(1);
list.add(2);
Iterator<Integer> iter = list.iterator(); // 요기!!
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}- 위의 경우처럼 Iterator(반복자)를 활용하여 객체를 순회하고 있음을 알 수 있다.
- 컬렉션 인터페이스를 상속받는 List나 Set에도 사용할 수 있다.
- 컬렉션 요소를 순회할 때 한 방향으로만 순회할 수 있다.
-
remove(Object o),removeAll(Collection c)
후자는 지정된 컬렉션에 포함된 객체들을 모두 삭제 -
retainAll(Collection c)
지정된 컬렉션에 포함된 객체'만' 남기고 나머지는 컬렉션에서 삭제
이 메서드로 인해 변화가 있다면 true 반환 (아니면 false) -
size() -
toArray(),toArray(Object[] a)
후자는 지정된 배열에 컬렉션의 객체를 저장하여 반환
※ 아래의 클래스부터는 모르는 메서드만 작성하였다 ※
List
중복을 허용하며 저장순서가 유지되는 컬렉션을 구현하는데 사용
- 상속계층도
List <- Vector <- Stack
<- ArrayList
<- LinkedList- ListIterator
listIterator()
List 객체에 접근할 수 있는 ListIerator 반환
- 대체, 추가, 검색 시 양방향으로의 이동이 가능
LinkedList<Integer> lnkList = new LinkedList<Integer>();
ListIterator<Integer> iter = lnkList.listIterator();
while (iter.hasPrevious()) {
System.out.print(iter.previous() + " ");
}- Object
set(int index, Object element)
저장된 위치에 객체를 저장 - List
subList(int fromIndex, int toIndex)
지정된 범위 안에 있는 객체를 반환
Set
- 상속계층도
Set <- SortedSet(인터페이스) <- TreeSet
<- HashSetMap
- Map은 두 값을 연결한다는 의미에서 붙여짐
- 상속계층도
Map <- Hashtable
<- HashMap <- LinkedHashMap
<- SortedMap <- TreeMap- 키와 값을 하나의 쌍으로 묶어 저장하는 컬렉션 클래스
clear()
Map의 모든 객체를 삭제한다.entrySet()
Map에 저장된 key-value 쌍을 Map.Entry 타입의 객체로 저장한 Set으로 반환한다.remove(Object key)
지정된 key 객체와 일치하는 key-value 객체를 삭제한다.- 이때
values()는 반환타입이 Collections이고,keySet()은 반환타입이 Set이다. 두 반환타입이 다른 이유는 중복 여부에 있음!!
Map.Entry
- Map 인터페이스의 내부 인터페이스
- Map은 내부적으로 Entry 인터페이스를 정의해 놓음(for 객체지향)
public interface Map {
interface Entry {
Object getKey();
Object getValue();
Object setValue(Object value);
boolean equals(Object o);
int hashCode();
}
}동기화 (Synchronization)
멀티스레드 프로그래밍에서는 하나의 객체를 여러 스레드가 동시에 접근할 수 있기 때문에 데이터 일관성 유지를 위해 동기화가 필요하다!
구버전(JDK1.2 이전)의 클래스(ex. Vector, Hashtable)들은 자체적으로 동기화 처리가 돼있지만, 멀티스레드가 아닌 경우에는 불필요한 기능이므로 성능이 떨어짐
-> 새로 추가된 컬렉션은 동기화를 자체적으로 처리 하지 X
대신 필요한 경우에만 동기화 메서드를 이용해 처리하도록 함!
-> 동기화 메서드 리스트
- static Collection synchronizedCollection(Collection c)
- static List synchronizedList(List list)
- static Map synchronizedMap(Map m)
- static Set synchronizedSet(Set s)
- static sortedMap synchronizedSortedMap(SortedMap m)
- static SortedSet synchronizedSortedSet(SortedSet s)
ex. List list = Collections.synchronizedList(new ArrayList<>());
▼ Else
Vector & ArrayList
- 둘 모두 List 인터페이스를 구현 => 순서 유지, 중복 O
- 둘 모두 데이터의 저장 공간으로 배열을 사용
(Object 배열을 활용해 데이터를 순차적으로 저장)
ex.
public class Vector extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable {
...
protected Object elementData[];
//자손클래스가 데이터를 저장해야 하므로 protected로 접근 제한!
...
}- ArrayList는 Vector를 개선한 클래스, 따라서 Vector < ArrayList
- Vector 클래스의 메서드 목록 (내가 모르는 것들만)
Vector()
크기가 10인 벡터 생성Vector(int initialCapacity)
Vector의 초기 용량 지정할 수 있는 생성자void copyInto(Object[] anArray)
Vector에 저장된 객체들을 anArray 배열에 저장void ensureCapacity(int minCapacity)
Vector의 용량이 최소한 minCapacity가 되도록 함- void
trimToSize()
용량을 크기에 맞게 줄임 (보통은 빈 공간을 없앨 때 사용)
import java.util.*;
class VectorEx1 {
public static void main(String[] args) {
Vector v = new Vector(5);
v.add("1");
v.add("2");
v.add("3");
print(v);
v.trimToSize();
System.out.println("===After trimToSize() ===");
print(v);
v.ensureCapacity(6);
System.out.println("===After ensureCapacity(6) ===");
print(v);
v.setSize(7);
System.out.println("===After setSize(7) ===");
print(v);
v.clear();
System.out.println("===After clear() ===");
print(v);
}
public void print(Vector v) {
System.out.println(v);
System.out.println("size : "+v.size());
System.out.println("capacity: "+v.capacity());
}
}trimToSize()를 호출하면 v의 빈 공간이 사라진다. 그러나 배열은 크기를 변경할 수 없어 새로운 배열을 생성해 그 주소값을 v에 할당시킨다. 원래의 v 인스턴스는 사용되지 않아 추후 GC에 의해 제거된다.ensureCapacity()는 최소한 크기가 6이 되도록 하여 새로운 인스턴스를 생성하여 v의 3개 요소를 복사해온다.- 이 예시를 통해 Vector와 ArrayList는 배열을 이용한 자료구조이므로 데이터를 읽기/저장에는 좋지만, 크기가 변경될 때는 새로운 배열을 생성해야 하므로 효율이 떨어진다.
이를 위해 책에서는 Vector 클래스를 쉽게 재구성해 보았다.
import java.util.*;
public class MyVector implements List {
protected Objec[] data = null;
protected int capacity = 0;
protected int size = 0;
public myVector(int capacity) {
if(capacity < 0) throw new IllegalArgumentException("유효하지 않은 값입니다: "+capacity);
this.capacity = capacity;
data = new Object[capacity];
}
public MyVector(int capacity) {
this(10);
}
public void ensureCapacity(int minCapacity) {
int newCapacity = capacity;
if(minCapacity > capacity) newCapacity = 2 * capacity;
if(minCapacity > newCapacity) newCapacity = minCapacity;
setCapacity(newCapacity);
}
public Object remove(int index) {
Object oldObj = null;
if(index < 0 || index >= size)
throw new IndexOutOfBoundsException("범위를 벗어났습니다.");
oldObj = data[index];
if(index != size-1) {
System.arraycopy(data, index+1, data, index, size-index-1);
}
data[size-1] = null;
size--;
return oldObj;
}
}
//아마 적다가 도중에 그만둔 것 같은데 책 있으면 다시 적어보기!!- ArrayList는 배열의 단점을 통해 탄생하였다.
그럼 배열의 단점이 무엇?
-
크기를 변경할 수 없다.
-> 변경할 시에는 새로운 배열을 생성하고 데이터 복사
(비용이 많이 들고, 만약 크기를 넓혀도 낭비가 심해짐) -
비순차적인 데이터의 추가, 삭제에 시간이 많이 걸린다.
(데이터 추가 or 삭제를 위해, 많은 데이터를 옮겨야 함)
- Shallow Copy VS Deep Copy
=> 말 그대로 shallow는 '얕은 복사', 즉참조변수만 복사하는 것을 의미한다. 따라서 같은 주소값의 변수를 가리키기 때문에 원본이 변화하면 새로운 복사본도 변경된다. 깊은 복사 보다 빠르지만 포인터나 참조를 다루기에 게으르다(?)
=> 그러나 Deep은 '깊은 복사', 즉같은 내용의 새로운 객체를 생성하기 때문에 원본이 바뀌어도 복사본과는 관련이 없어진다.
LinkedList
LinkedList도 마찬가지로 배열의 단점을 보완한 클래스이다. 불연속적으로 존재하는 데이터를 연결한다.
class Node {
Node next;
Object obj;
}- 데이터의 삭제, 추가가 단 한 번의 참조변경만으로 가능하다.
[삭제]
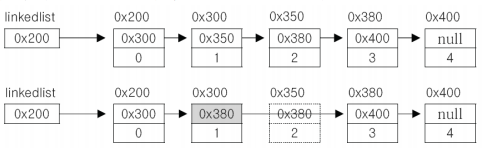
[추가]

- data, link 두 개의 필드를 갖는 노드로 구성됨
(data는 값을 갖고, link는 다음 data를 가리킴)
- linked list (연결리스트)
-> 각 노드에 데이터, 포인터 공간만 존재
-> 데이터 접근성이 나쁨 - doubly linked list (이중 연결리스트)
-> 각 노드에 이전 주소, 데이터, 다음 주소 세 개의 공간 존재
-> 접근성 향상 - doubly circular linked list (이중 원형 연결리스트)
-> 1번의 마지막 노드 포인터가 NULL이 아닌head를 가리킴
-> 리스트의 끝이 존재하지 않음
- 메서드(내가 모르는것)
-
ListIterator
listIterator(int index)
지정된 index에서 시작하는 ListIterator 반환 -
Object
set(int index, Object element)
주어진 index의 값을 element로 바꿔줌
ArrayList vs LinkedList
- 순차적으로 데이터 추가/삭제 시,
ArrayList - 비순차적으로 데이터 추가/삭제 시,
LinkedList - 접근 시간
ArrayList가 더 빠름
Stack과 Queue
- Stack
- Vector를 Stack으로 처리할 수 있는 다섯 가지 작업으로 Vector 클래스를 확장
-> 메서드
empty()peek()pop()push(E item)search(Object o)
Stack의 가장 상단 항목을 거리 1로 간주하고 o가 스택에 존재한다면 순번을 반환, 아니라면 -1 반환
- LIFO(Last In First Out) 구조
= 마지막에 저장된 것이 제일 먼저 나옴 - 더 완전하고 일관된 LIFO Stack 작동은
Deque인터페이스 및 구현에 의해 제공됨 (Stack 클래스보다 우선적으로 사용해야 하는)
ex.Deque<Integer> stack = new ArrayDeque<Integer>(); - 수식 계산, 괄호 검사, undo/redo, 뒤/앞
- Queue
- FIFO(First In First Out) 구조
= 처음에 저장된 것이 제일 먼저 나옴 - 최근 사용문서, 대기목록, 버퍼
Queue는 인터페이스만 존재하고 클래스가 없어 이를 구현할 클래스(ex. LinkedList)를 사용해야 함- 일반적으로 NULL 원소 삽입 허용 X
Deque,PriorityQueue가 그 예시- 메서드들은 null이나 false와 같은 특별한 값을 반환하거나, 예외를 던지는 두 가지 형태로 존재한다.
- 메서드
poll()
head에 있는 원소를 제거하고 해당 원소를 리턴
(but 큐가 비어있을 때 null을 반환하는 점이remove()와의 차이 /remove()는NoSuchElementException을 발생시킴)offer()
값을 추가하는 메서드
(Queue의 사이즈가 정해져있거나, 성공 여부를 굳이 확인하지 않아도 될 때add()대신 사용)
Enumeration, Iterator, ListIterator
세가지 모두 Collection 클래스에 저장된 데이터를 접근하는데 사용하는 인터페이스
- Enumeration
- Enumeration(Java6)은 Iterator의 구버전
- 객체들을 집합체 형태로 관리해주는 인터페이스
- 객체들을 한번에 하나씩 처리할 수 있는 메서드 제공
- 커서가 존재하여 이를 통해 하나의 데이터에 접근
- 메서드
hasMoreElements()nextElement()
- 스레드에 안전
- Vector, Hashtable에서만 사용 가능
- 순방향 읽기만 OK
(추가, 제거 X)
- Iterator
- 요소들을 나열하는 방법 제공
- 객체들을 집합체 형태로 관리해주는 인터페이스
iterator()를 호출하여 이를 구현한 객체를 얻음- 메서드
1.hasNext()
2.next()
3.remove() - 스레드에 안전하지 않음
- 모든 Collection 객체에서 사용 가능
- 단방향
- 새로운 데이터 교체/추가 X
(Iterator값을 초기화하면 가능)
- ListIterator
= List 컬렉션에서 사용되는 클래스, Iterator 상속
- 양방향
- 데이터 추가/교체 O
- 메서드
1.hasNext()
2.next()
3.remove()
4.hasPrevious()
5.previous()
6.set(Object)
7.add(Object)
예시
//정리해보는 Iterator 예시
public class IteratorEx {
public static void main(String[] args) {
ArrayList original = new ArrayList(10);
ArrayList copy1 = new ArrayList(10);
ArrayList copy2 = new ArrayList(10);
for(int i = 0; i < 10; i++) {
original.add(i+"");
}
Iterator it = original.iterator();
while(it.hasNext()) {
copy1.add(it.next());
}
System.out.println("original: "+original);
System.out.println("copy1: "+copy1);
System.out.println();
it = original.iterator();
while(it.hasNext()) {
copy2.add(it.next());
it.remove();
}
System.out.println("original: "+original);
System.out.println("copy2: "+copy2);
}
}사실 이 단원은 내가 Set을 사용할 때 인덱스에 직접적으로 접근할 수 없어 리스트로 우회해서 사용하는 경우가 많았는데, iterator를 사용하면 더 편리할 것 같아서 읽는데 신기했다..
HashSet
= Set 인터페이스를 구현한 Collection 클래스
- 중복 X, 순서 X
-> 순서를 유지하고자 한다면LinkedHashSet클래스를 활용하는 것이 좋음 add()를 통해 객체를 저장하고, 만약 중복된 객체를 저장한다면false를 반환
-> 이 메서드는 객체의equals()와hashCode()를 호출하므로 적절히 오버라이딩 돼야 중복으로 간주하지 않음
->hashCode()는 다음의 세가지 조건을 만족
1. 여러번 호출해도 동일한 int값을 반환해야 함
2.equals()메서드를 이용한 비교에 의해 true를 얻은 객체에 대해 각각hashCode()를 호출해 얻은 결과는 반드시 같아야 함
3.equals()메서드를 호출했을 때 false를 반환하는 두 객체는hashCode()호출에 대해 같은 int값을 반환하는 경우가 있어도 괜찮으나, 해싱을 사용하는 컬렉션의 성능을 향상시키려면 다른 int값을 반환하는 것이 좋음- null 허용
- 동기화 X
(만약 동기화하려면Set s = Collections.synchronizedSet(new HashSet(..))이렇게) - 메서드
add(E e),clear(),clone(),contains(Object o),isEmpty(),size(),remove(Object o)iterator()spliterator()
-> 분할할 수 있는 반복자 (병렬 작업에 특화된 새로운 인터페이스)
TreeSet
= 이진검색트리 라는 자료구조의 형태로 데이터를 저장하는 클래스
이진검색트리
-> 왼쪽 자식노드의 값 < 부모노드의 값 < 오른쪽 자식노드의 값
-> 노드 추가/삭제에 시간 소요 ↑ (순차 저장 X)
-> 검색/정렬에 유리 (저장할 때 이미 정렬됨)
이진트리
= 여러 개의 노드가 서로 연결된 구조
-> 각 노드에 최대 2개의 노드 연결 가능
-> 루트로 불리는 하나의 노드에서부터 계속 확장 가능
class TreeNode {
TreeNode left;
Object element;
TreeNode right;
}- 정렬, 검색, 범위 검색에 뛰어난 성능을 보임
- 그들만의 nature ordering이나 Comparator에 의해 정렬됨
( nature ordering = 끼리기리,
같은 클래스에 속하는 객체끼리의 순서 ) - 기본적인 동작 메서드는 log(n)의 시간 복잡도를 보장
- fail-fast 방식 (= 동작 중 오류가 발생하면 바로 오류를 알린 뒤 작업 중단)
- 메서드 (내가 모르는 것 위주)
- SortedSet
headSet(Object toElement)
지정된 객체보다 작은 값의 객체 반환 - boolean
retailAll(Collection c)
주어진 컬렉션과 공통 요소를 남기고 다 삭제 (교집합) - SortedSet
subSet(Object fromElement, Object toElement)
두 범위 검색 사이의 결과를 반환 - SortedSet
tailSet(Obejct fromElement)
지정된 객체보다 큰 값의 객체 반환
Comparator과 Comparable
야물딱진 호구마의 정리.txt
추가적으로 말하자면, 둘 모두 인터페이스로, 객체들을 정렬 or 이진검색트리를 구성하는데 필요한 메서드를 정의함
public interface Comparator {
int compare(Object o1, Object o2);
boolean equals(Object obj);
}
public interface Comparable {
public int compareTo(Object o);
}
// 기억하면 좋을만한 예시
class ComparatorEx1 {
public static void main(String[] args) {
TreeSet set1 = new TreeSet();
TreeSet set2 = new TreeSet();
int[] score = {30, 50, 10, 20, 40};
for(int i = 0; i < score.length; i++) {
set1.add(new Integer(score[i]));
set2.add(new Integer(score[i]));
}
System.out.println("set1: "+set1);
System.out.println("set2: "+set2);
}
}
class Descending implements Comparator {
public int compare(Object o1, Object o2) {
if(o1 instanceof Comparable && o2 instanceof Comparable) {
Comparable c1 = (Comparable) o1;
Comparable c2 = (Comparable) o2;
return c1.compareTo(c2)*(-1);
//-1을 곱해 기본 정렬방식의 역으로 변경
}
}
}HashTable과 HashMap
둘 사이의 관계 = Vector <-> ArrayList의 관계
따라서 새로운 버전인 HashMap을 사용하는 것이 되도록이면 좋다
// HashMap이 데이터를 저장하는 방식
public class HashMap extends AbstractMap implements Map, Cloneable, Serializable {
transient Entry[] table;
...
static class Entry implements Map.Entry {
final Object key;
Object value;
...
}
}- HashMap도 Map과 마찬가지로 Key, Value 쌍 형태로 저장하고 Key는 저장된 값을 찾는 용도이므로 컬렉션 내에서
유일해야 한다!! - 메서드 (내가 모르는 것 위주)
- Set
entrySet()
HashMap에 저장된 키와 값을 엔트리 형태로 Set에 저장해서 반환 HashMap(int initialCapacity, float loadFactor)
지정된 초기용량과 loadFactor의 HashMap 객체 생성
Hashing(해싱)
해시함수를 이용해 데이터를 hash table에 저장하고 검색하는 기법
- 데이터가 저장돼 있는 곳을 알려줌
=> 다량의 데이터 중 원하는 데이터 빨리 찾을 수 있음
ex. 간호사가 환자들의 데이터를 앞자리 생년을 기준으로 10개의 서랍에 나눠 분류해놓음 - ex. HashSet, HashMap, Hashtable
- 배열+LinkedList 의 조합으로 되어 있음
- 실제로 해싱을 구현한 Collection 클래스는
Object 클래스에 정의된 hashCode()를 해시함수로 사용함
TreeMap
- TreeMap << HashMap (검색 성능)
- TreeMap >> HashMap (범위검색, 정렬)
Properties
= HashMap의 구버전인 Hashtable을 상속받아 구현한 것
= (String, String)의 형태로 저장 => 단순화된 Collection 클래스
- 주로 application의 환경설정과 관련된 속성 저장
=> 데이터를 파일로부터 읽고 쓰는 편리한 기능을 제공 - 메서드
- void
loadFromXML(InputStream in)
저장된 InputStream으로부터 XML 문서를 읽어와 저장된 목록을 읽어 담음 - void
storeToXML(OutputStream os, String comment)
저장된 목록을 지정된 출력스트림에 XML문서로 출력 (comment는 주석)
좀 낯선 클래스라 예시를 좀 봐야겠다..
import java.util.*;
class PropertiesEx {
public static void main(String[] args) {
Properties prop = new Properties();
prop.setProperty("timeout", "30");
prop.setProperty("language", "kr");
prop.setProperty("size", "10");
prop.setProperty("capacity", "10");
Enumeration e = prop.propertyNames();
//왜 Iterator가 아닌 Enumeration을 사용했냐면
//Property도 Collection 프레임워크 이전의 버전
while(e.hasMoreElements()) {
String element = (String) e.nextElement();
System.out.println(element+"="+prop.getProperty(element));
}
}
}** 생각해보니까 이 클래스 application.properties로 막 DB 연결하고 이럴 때 사용했던 것 같다!!
driver=org.postgresql.Driver url=jdbc:postgresql://localhost:8080/postgres 요런 식으로?
컬렉션 클래스 정리!!
(이렇게만 알아도 코테에서 클래스 고르기 좋음)

[+ α를 담당하는 유용한 클래스]
java.util.*에서 위의 중요한 클래스 외에도 자주 쓰이는 알아두면 유용한 클래스들을 알아보자!
Calender & Date
JDK 1.0 ~ => Date
JDK 1.1 ~ => Calendar (추상클래스)
// 1. Calendar -> Date
Calendar cal = Calendar.getInstance();
...
Date d = new Date(cal.getTimeInMills());
// 2. Date -> Calendar
Date d = new Date();
...
Calendar cal = Calendar.getInstance();
cal.setTime(d);Random
= Math.random() 외에 난수를 얻는 다른 방법
그러나 기능이 Math.random()과 별 다를바 없어 가능하면 전자를 사용하길 권한다.
- 메서드
- Random()
인스턴스 생성 - 자료형
next자료형()
자료형 타입의 난수 반환
=> 아마도 이게 Math.random()과 Random의 차이이다. 종자값(seed)을 설정할 수 있다는 것..? 난수를 만드는 공식에 같은 종자값을 넣으면 같은 난수를 얻는다. - void
setSeed(long seed)
종자값을 주어진 seed로 변경
import java.util.*;
class RandomEx {
public static void main(String[] args) {
Random rand = new Random(1);
Random rand2 = new Random(1);
System.out.pritnln("=rand=");
for(int i = 0; i < 5; i++) {
System.out.println(i+":"+rand.nextInt());
}
System.out.pritnln("=rand2=");
for(int i = 0; i < 5; i++) {
System.out.println(i+":"+rand2.nextInt());
}
}
}
//출력값을 보면 예시에서 rand와 rand2의 값이 같다!
//(같은 종자값을 사용하므로)✨ 정규식
나에게 지금 가장 필요한 챕터가 아닐까,, 코테 풀 때 필요해,,
= 텍스트 데이터 중 원하는 조건과 일치하는 문자열을 찾아내기 위해 사용하는 것 (미리 정의된 기호와 문자를 이용해 작성한 문자열)
-
Pattern: 정규식 정의
-
Matcher: 정규식(패턴)을 데이터와 비교하는 역할
-
[정규식 정의 -> 데이터 분석 순서]
- 정규식을 매개변수로 Pattern 클래스의 static 메서드인 Pattern compile(String regex)을 호출하여 Pattern 인스턴스를 얻음
- 정규식으로 비교할 대상을 매개변수로 Pattern 클래스의 Matcher를 호출하여 인스턴스를 얻음
- Matcher 인스턴스에 matches()를 호출하여 정규식에 부합하는지 확인
(find()도 해당 문자열이 존재하면 true 반환하는 메서드
- 정규식 패턴
c[a-z]*
c로 시작하는 영단어c[a-z]
c로 시작하는 두 자리 영단어c[a-zA-Z]
대/소문자 구분 안하고 c로 시작하는 두 자리 영단어.*
모든 문자열c.
c로 시작하는 두 자리c.*
c로 시작하는 모든 문자열.*a.*
a를 포함하는 모든 문자열c.*t
c로 시작하고 t로 끝나는 문자열[b|c].{2}
b or c로 시작하는 세 자리 문자열\\d{3,4}
최소 3자리 최대 4자리의 숫자
Scanner
= 입력소스(화면, 파일, 문자열)로부터 문자 데이터를 읽어오는데 도움을 줄 목적으로 추가된 클래스 (JDK 1.5~)
// JDK1.5이전
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String input = br.readLine();
// JDK1.5이후
Scanner in = new Scanner(System.in);
String input = in.nextLine();
// 예시
class ScannerEx {
public static void main(String[] args) {
scanner in = new Scanner(new File("data3.txt"));
int cnt = 0;
int totalSum = 0;
while(in.hasNextLine()) {
String line = in.nextLine();
Scanner in2 = new Scanner(line).useDelimiter(",");
int sum = 0;
while(in2.hasNextInt()) {
sum += sc2.nextInt();
}
totalSum += sum;
cnt++;
}
}
}StringTokenizer
= 긴 문자열을 지정된 구분자(delimiter)를 기준으로 토큰이라는 여러 개의 작은 문자열로 잘라내는 데 사용
- 구분자로
단 하나의 문자만 사용할 수 있어 복잡한 형태의 구분자로 나누려면Scanner나split()를 활용하는 것이 좋음 - 메서드
- StringTokenizer(String str, String delim)
str을 지정된 구분자(delim)로 나누는StringTokenizer를 생성 - StringTokenizer(String str, String delim, boolean returnDelims)
1번과 똑같은데 returnDelim값을 true로 하면 구분자로 토큰으로 간주함 - int
countTokens()
전체 토큰의 수 반환 - boolean
hasMoreTokens()
토큰이 남았는지 알려줌 - String
nextToken()
다음 토큰을 반환
class StringTokenEx {
public static void main(String[] args) {
String data = "100,,,200,300";
String[] result = data.split(",");
StringTokenizer st = new StringTokenizer(data, ",");
for(int i = 0; i < result.length; i++) {
System.out.print(result[i]+"|");
}
System.out.println("개수: "+result.length);
int i = 0;
for(;st.hasMoreTokens();i++) {
System.out.print(st.nextToken()+"|");
}
System.out.println("개수:"+i);
}
}
//split()
//100|||200|300 (개수 5)
//StringTokenizer
//빈 문자열을 토큰으로 인식하지 X
//100|200|300 (개수 3)[형식화 클래스]
그렇게 중요할 것 같진..
읽고만 넘어가용~~
DecimalFormat
SimpleDateFormat
ChoiceFormat
MessageFormat
[제네릭스]
JDK1.5에서의 가장 큰 변화 중 하나로, 다룰 객체의 타입을 미리 명시함으로써 형변환을 하지 않게끔 만들어준다.
- 장점
- 타입 안정성 제공
(** 타입 안전성: 의도하지 않은 타입의 객체를 저장하는 것을 막고, 저장된 객체를 꺼내올 때 원래의 타입과 다른 타입으로 형변환되어 발생할 수 있는 오류를 줄여줌) - 타입 체크와 형변환을 생략할 수 있어 코드가 간결해짐
- 참조형 '타입' = 'T' 라는 기호를 사용
- 와일드 카드
?를 사용
객체<? extends 객체> => ?는 객체의 하위 타입
객체<? super 객체> => ?는 객체의 상위 타입
면접때 이 용어가 안나서ㅠㅠ
ArrayList<E>
컬렉션 클래스<저장할 객체 타입> 변수명 = new 컬렉션클래스<저장할객체타입>();
Iterator<E>
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
//예시
class Student {
String name = "";
int ban;
int num;
Student(String name, int ban, int num) {
this.name = name;
this.ban = ban;
this.num = num;
}
}
public static void main(String[] args) {
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("호구마", 7, 10);
list.add(new Student("김인하", 7, 1);
Iterator<Student> iterator = list.iterator();
//여기서 형변환을 시켜주지 않아도 됨!
while(iterator.hasNext()) {
Student s = iterator.next();
System.out.println(s.name);
}
}Comparable<T>와 Collections.sort()
타입이 미리 정해져있기 때문에 instanceof로 원하는 타입이 들어왔는지 확인하지 않아도 되고, 코드도 간편해진다.
HashMap<K,V>
Map은 키와 값 형태로 저장되므로 지정해줘야 할 타입이 K, V로 두개이다!
ex. HashMap<String, Student> map = new HashMap<String, Student>();
map.put("자바", new Student("자바왕", 1, 1, 100, 100, 100));참조
자바의 정석, 2nd Edition.
http://www.tcpschool.com/java/java_collectionFramework_iterator
https://opentutorials.org/module/1335/8857
https://applefarm.tistory.com/141
https://docs.oracle.com/javase/8/docs/api/java/util/Queue.html
