
컴파일러의 등장 배경
컴퓨터는 0과 1만 알아보기 때문에, 우리가 작성하는 명령어를 더 편리하게 나타내기 위해 어셈블리어가 등장했다.
** 어셈블리어 : A(ADD)처럼 기호를 사용하는 프로그래밍 언어
(기계어와 일대일 대응이 되는 저급 언어)
하지만 어셈블리어도 기계어 처리 방식을 알아야 했으므로 프로그래밍이 매우 어려웠다. 이후 만들어진 고급 언어들이 우리가 현재 배우고 있는 C, JAVA 등이다.
그러나 얘네도 기계어로 다시 바꿔주는 과정이 필요하기 때문에 어셈블리와 같은 번역기가 필요하다. 이때 등장하게 된 번역기 중 이 글에서 다룰 번역기가 컴파일러다.
(이외에도 인터프리터, 프리프로세서 등이 있음)
결론적으로, 컴파일러가 필요한 이유는 어찌 보면 단순하다. 우리가 이해하기 쉽게 작성한 언어로 작성된 코드들은 0,1만 알아보는 컴퓨터가 당연히 알아볼 수 없기 때문에 컴파일 과정이 필요할 수 밖에 없다!
컴파일러란?
= 우리가 작성한 고수준의 언어를 컴퓨터가 이해할 수 있도록 기계어(0,1)로 변환해 주는 것 (like 번역기)
기능
- 고급 언어 -> 기계어 코드 로 직접 변환! (C/C++)
- (자바) 바이트 코드 변환 후 중간 단계의 코드를 생성하고, 해석 후 실행
TMI를 말하자면, 자바는 운영 체제에 종속적이지 않기 때문에 바이트 코드로 해석 후 실행이 가능하고, 다른 고급 언어들은 마이크로프로세서(CPU)가 각각 다른 기계어 코드를 가지기 때문에 같은 고급 언어라도 다른 기계어 코드를 생성해야 한다! 자바는 바이트 코드를 해석하여 실행할 프로그램 구조가 필요하기 때문에 다른 프로그래밍 언어보다는 속도가 늦다!
++ 추가적으로 궁금한 인터프리터
= 고급 언어를 한 줄씩 번역하여 실행 결과를 바로 출력하는 컴파일러
(일단은 아래 참고의 예시를 빌려오겠습니당 🙇♀️)
const a = 1; => 실행, 결과 : a 변수 생성 및 a 변수에 1을 할당
const b = 2; => 실행, 결과 : b 변수 생성 및 b 변수에 2를 할당
console.log(a + b); => 실행, 결과 : a + b 결과 값을 출력컴파일러의 실행 순서
실행에 앞서!!!
2가지 조건을 지켜주세요!
- 프로그램의 뜻 보존하기!
- 입력 프로그램 실용적으로 개선하기!
1. 구문 분석
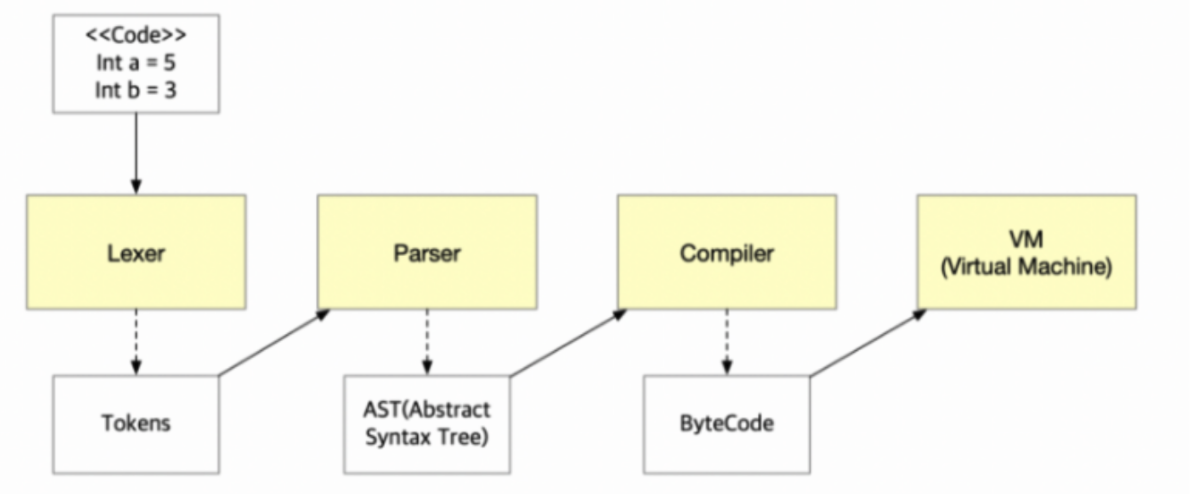
-
Tokenizer
= 어떤 대상의 의미있는 요소들을 토큰(어휘 분석 단위)로 쪼개는 역할 -
Lexer
=Tokenizer가 쪼갠 토큰의 의미를 분석하는 역할** 1, 2의 과정을
Lexical Analyzer라고 부른다. -
Parser
= 위의 두 과정을 통해 의미가 분석되어 이 데이터를 구조적으로 나타내는 역할
- 구조적이라는 의미는AST(Abstract Syntax Tree)형태로 데이터를 나타낸다는 말!
- 위에서는 말이 되는 단어인지만 확인했다면, 여기서는 토큰이 정확한 의미를 갖는지 확인한다!추상 구문 트리 (AST)
= 소스 코드 구조를 표시하는 계층적 프로그램 표현
- 트리를 구성하며 우선순위 확인을 위해 사용
- 작성한 코드 -> 의미별 분류 -> 컴퓨터 이해 O 구조 트리!
- 실제 구문의 모든 정보를 다 나타내지 X =추상예시
let a = 5라는 명령어가 제시되었다.
1. Tokenizer ={"let", "a", "=", "5"}
2. Lexer ={type: "keyword", value: "let"}, {type: "identifier", value: "a"}, {type: "operator", value: "="}. {type: "literal", value: "5"}3. Parser =
// https://astexplorer.net/를 활용해 AST를 만들어 // 위에서 내가 임의로 설정한 type, value와 살짝 다름 주의,, { "type": "VariableDeclaration", "start": 0, "end": 10, "declarations": [ { "type": "VariableDeclarator", "start": 4, "end": 9, "id": { "type": "Identifier", "start": 4, "end": 5, "name": "a" }, "init": { "type": "Literal", "start": 8, "end": 9, "value": 5, "raw": "5" } } ], "kind": "let" }
++ DOM Parser
웹 페이지의 관점에서 설명해보자. DOM 파서는 웹 페이지의 HTML이나 XML 코드를 읽고, 이 내용을 구문 분석 + 이해 하는 역할을 한다. Parser는 두 종류의 문서를 파싱하여 트리 구조로 변환한다. (위에서 설명한 구문 분석 과정과 동일) DOM 파서가 파싱이 끝나면 웹 페이지의 구조와 내용을 메모리에 저장하고, 브라우저에 제공된다(랜더링).
이렇듯 파서는 '데이터를 컴퓨터가 이해할 수 있는 구조로 재구성' 해주는 중요한 역할을 담당하기 때문에 위의 동작원리를 아는 것은 꽤나 중요하다!!
DOM = Document Object Model (문서 객체 모델)
= HTML문서를 객체로 표현한 모델
XML = 플랫폼/프로그램으로부터 독립적이고, 개방된 표준으로 인간과 기계 모두 처리할 수 있는 마크업 언어
2. 최적화
= 구문 분석의 결과인 AST를 분석하여 최적화를 수행
= 전달 속도 절약을 위한 단계!
(ex. 우리가 말할 때도 머릿속에서 생각을 다듬어 말 한다면 기억해야 할 말과 말하는 시간을 효과적으로 줄일 수 있는 것처럼)
- 도달할 수 없는 코드 식별
- 상수 표현식 미리 계산
- 루프 풀기
3. 코드 생성
= 최적화를 거친 트리로부터 목적 코드 생성
- (if) 목표 언어가
기계어=> 하드웨어에 맞는 최적화
(ex. 레지스터 할당, 연산 순서 바꾸기, ..)
4. 링킹
- (if) 목표 코드 = 기계어 => 여러 라이브러리 목적 코드를 묶어 하나의 실행 파일 생성 (by 링커)
(해석에 따라 링커를 컴파일러로 간주하지 않기도 함)
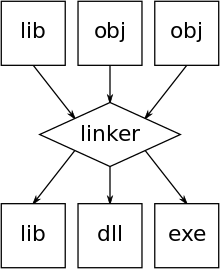
++ 링커 = 하나 이상의 목적 파일을 가져와 이를 단일 실행 프로그램으로 병합하는 프로그램
++ 목적 코드/파일 = 컴파일/어셈블 하여 생성하는 파일
컴파일 순서
++ 여기는 새로 학습해야 하는 내용이라 더 자세히 읽어보고 추가 작성 예정!
잠깐! 컴파일러와 컴파일 똑같은 거 아님?
(아무도 안그럴 것 같다) 나는 처음에 같은 동작으로 묶이는 줄 알고 두 개념을 구글링 했는데, 순서가 달라서 ??? 놀랐다.. (또 나만 놀랐지)
여기서 설명할 컴파일은 고급 언어로 작성된 프로그램을 기계어로 번역해 기계어 프로그램으로 고치는 과정을 말하고, 이 과정을 처리하는 프로그램이 컴파일러다.
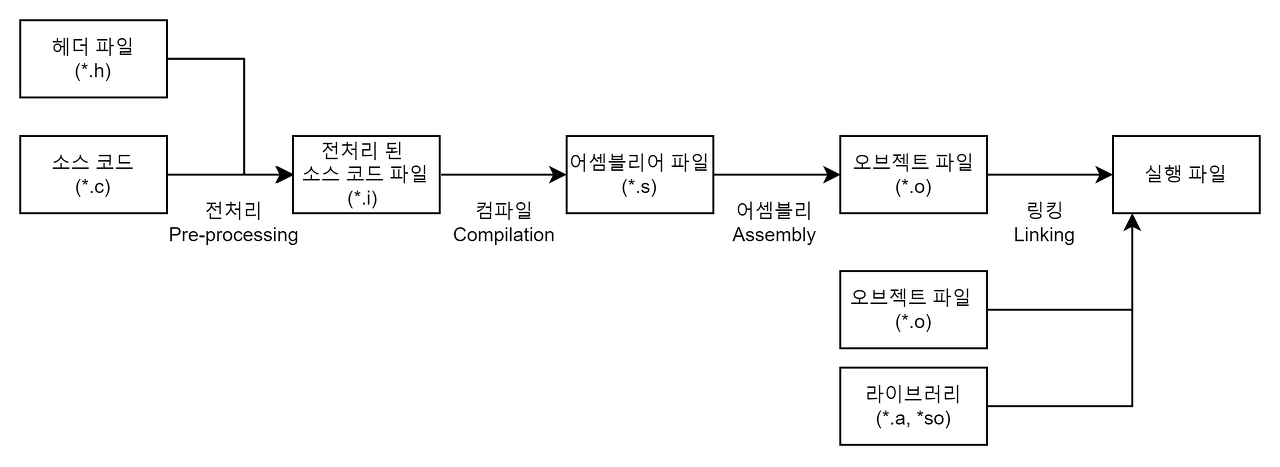
1. 전처리
= 전처리기 과정을 통해 입력받은 소스 코드를 전처리된 소스 코드로 변환시켜주는 과정
(ex. 주석 제거, 헤더 파일 삽입, 매크로 치환/적용)
** 매크로 = ex. # define
2. 컴파일
= 전처리 과정을 거친 코드를 어셈블리어 파일로 변환시켜주는 과정
3. 어셈블리
= 어셈블러를 통해 어셈블리어 파일을 오브젝트 파일로 변환시켜주는 과정
(사람이 알아볼 수 없는 기계어로 변환된 코드)
4. 링킹
= 링커를 통해 위에서 만들어진 오브젝트 파일들을 묶어 실행 파일로 만드는 과정
참고
