아파치 스쿱(Apache Sqoop)
스쿱(Sqoop)은 구조화된 관계형 데이터베이스(RDBMS)와 아파치 하둡간의 대용량 데이터들을 효율적으로 변환해주는 명령 줄 인터페이스(Command-Line Interface) 애플리케이션이다.
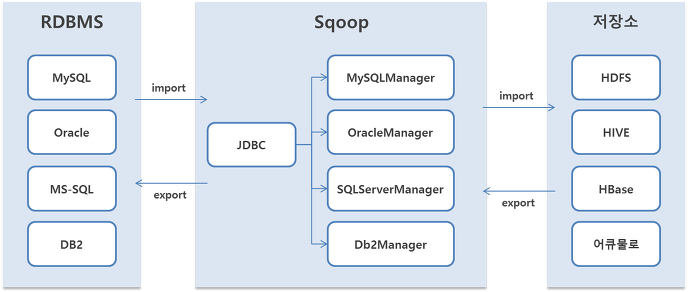
관계형 데이터베이스(Oracle, Mysql, etc..) 데이터를 HDFS, Hive, Hbase에 임포트(import) 하거나, 반대로 관계형 데이터베이스에 데이터를 익스포트(export)할 수 있다.
스쿱은 데이터의 가져오기와 내보내기를 맵리듀스를 통해 처리하여 장애 허용 능력뿐만 아니라 병렬 처리가 가능하게 한다.
(장애 허용 능력: 정상적으로 작동할 수 없는 상황이 발생하였을 때, 데이터가 분실되거나 진행 중인 작업이 훼손되는 사태가 일어나지 않도록 대응하능 능력)
참고 사이트:
https://ko.wikipedia.org/wiki/%EC%95%84%ED%8C%8C%EC%B9%98_%EC%8A%A4%EC%BF%B1
1. 스쿱 아키텍처
스쿱은 관계형 DB를 읽고 쓸 수 있는 커넥터라는 개념을 사용한다.
커넥터는 각 DB별로 구현돼 있으며, JDBC 드라이버를 이용해 데이터베이스 접속 및 쿼리 실행을 요청한다.
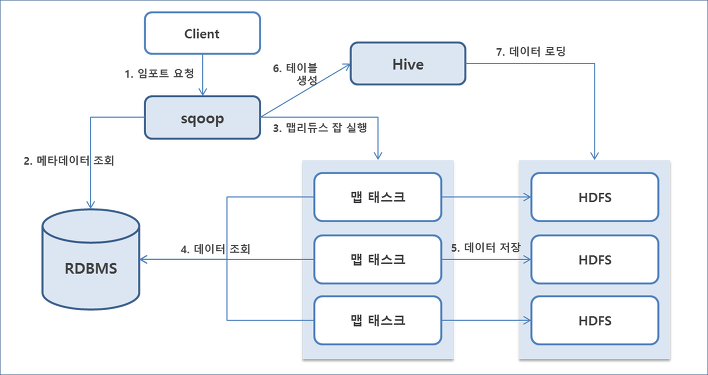
1) 데이터 임포트 동작 방식
1. 클라이언트가 스쿱에 임포트를 요청한다. (이때 클라이언트는 데이터베이스 접속 정보, 임포트 대상 테이블, 임포트 질의, 실행할 맵 태스크 개수 등을 설정하여 요청)
2. 스쿱은 데이터베이스에서 해당 테이블의 메타데이터를 조회해 ORM(Object Realational Mapping) 클래스를 생성한다. ORM에서 익스포트 테이블의 튜플과 임포트 테이블의 튜플이 매핑된다. 그 후 맵리듀스 잡 실행에 필요한 직렬화 메서드가 생성된다.
3. 스쿱은 ORM 클래스가 정상적으로 생성되면 맵리듀스 잡 실행을 요청한다.
(리듀스 태스크는 사용하지 않는다. 맵 태스크의 결과를 임포트해 사용한다.)
4. 맵 태스크는 DB에 JDBC로 접속한 후 SELECT 질의를 실행한다.
5. 맵 태스크는 질의문을 실행한 결과를 HDFS에 저장한다. 모든 맵 태스크가 종료되면 스쿱은 클라이언트에게 작업이 정상적으로 종료됐다고 알려준다.
// 6번 부터는 스쿱 import 문에 테이블 생성 코드 추가했다고 가정.
6. 사용자가 설정한 하이브 테이블을 생성한다.
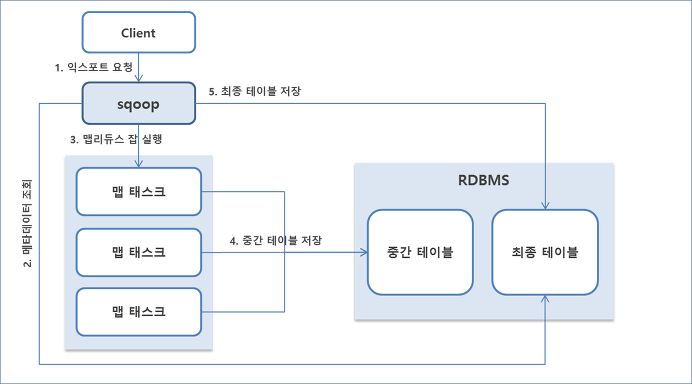
7. 맵 태스크에 저장된 결과를 하이브 테이블의 데이터 경로로 로딩한다.2) 데이터 익스포트 동작 방식
export 작업이 실패하면 일부 데이터가 데이터베이스에 커밋되는 등 삽입 충돌이 발생할 위험성 때문에 중간 테이블을 사용합니다.
1. 클라이언트가 스쿱에 익스포트를 요청한다.
2. 스쿱은 RDBMS에서 메타데이터를 조회 후 맵리듀스 잡에서 사용할 ORM 클래스를 생성한다.
3. 스쿱은 데이터베이스의 중간 테이블의 데이터를 모두 삭제한 후 맵리듀스 잡을 실행한다.
4. 맵 태스크는 HDFS에서 데이터를 조회한 후 INSERT 질의문을 만들어 중간 테이블에 데이터를 입력한다. 이때 질의문은 레코드당 한 번씩 실행하는 것이 아니라 천개 단위의 배치로 실행한다. (중간 테이블 및 배치 단위 옵션은 sqoop.export.records.per.statement 옵션으로 수정가능 )
5. 스쿱은 맵리듀스 잡이 정상적으로 종료되면 중간 테이블의 결과를 최종 테이블에 입력한다.
예를 들어, 중간 테이블이 tmp1, 최종 테이블이 result1이라면 하기 쿼리를 실행한다.
insert into result1 (select * from tmp1)