독자 대상📣
👉 Pandas Dataframe을 사용하여 상관분석을 하고 싶은 분
👉 상관 분석을 그래프화하고 싶은 분
출간 이유❓
상관분석, 그래프화 정도는 구글링이나 책 좀 보면 누구나 쉽게 따라할 수 있쥬? 😀
근데 간혹가다 결과물로 생성된 그래프에 "NaN"으로 빈 줄이 쭈~욱 그어진 분들도 계시쥬? 😂
🙏이 글 그 분들을 위해 바칩니다...🙏
R.I.P My time (like gold)...
문제 파악🔍
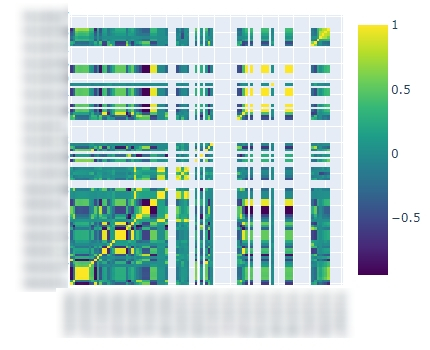
Q: 아니... 하란대로 프밍했는데 중간중간에 왜 그래프가 비어있어요?A: 예... 저도 이거 때문에 Dataframe 컬럼별로 NaN 제거,
corr() 결과 Dataframe에서 NaN 제거 했는데,
그게 문제가 아니더라구요 ㅋㅋㅋㅋㅋ 근본부터 문제였더라구요😄😄Q: 그래서 뭐가 문제고, 어떻게 고쳐야 하는데요?문제 해결🎊
cor(i,j) = cov(i,j)/[stdev(i)*stdev(j)]
A: corr() 상관계수 계산을 할 땐 위와 같은 수식을 쓴단 말이지?
근데 보여? stdev... 표준편차 알지?
이 표준편차 값이 0이 되면 계산 결과가 NaN이 나오더라곸ㅋㅋㅋ
해결절차는 아래에 적어놨으니까 참고해😀- Dataframe에서 std를 계산
- std가 0.00000 이상인 컬럼명만 리스트로 추출
- Dataframe에 추출한 컬럼 리스트 필터링
A: 잘 모르겠다고? pseudo-code 적어줄테니까 참고해~dataframe.dropna(axis=1, inplace=True)
std_df = dataframe.std(axis=0)
filtered_col_list = std_df[std_df > 0.00000].index.tolist()
dataframe = dataframe[filtered_col_list]
print(dataframe.corr())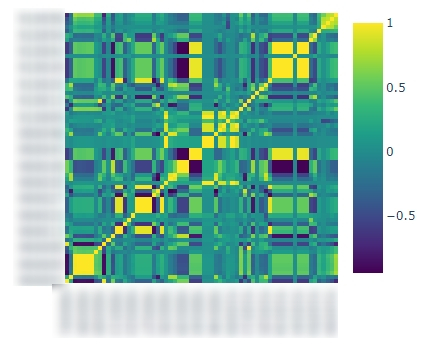

데이터 요리사