
출처 : https://developer.chrome.com/blog/inside-browser-part2/
자세한 내용은 원문을 참고해주세요.
지난 "모던 웹 브라우저 톺아보기1"에서 각 프로세스와 스레드가 브라우저의 여러 부분들을 어떻게 처리하는 지 살펴보았습니다. 이번 글에서는 웹 사이트가 보여지고 어떻게 통신하는 지 살펴보겠습니다.
브라우저 랜더링
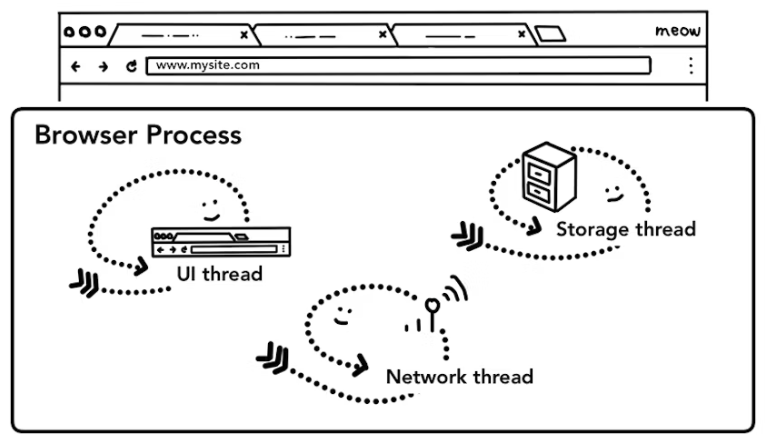
웹 서핑을 생각해 봅시다. 브라우저에 주소를 치면, 브라우저는 인터넷에서 데이터를 받아 페이지를 표시합니다.
탭 밖의 것들은 모두 브라우저 프로세스가 담당합니다. 브라우저 프로세스는 버튼이나 입력창을 그리는 UI 스레드, 인터넷에서 데이터를 수신하기 위해 통신 스택을 건드리는 네트워크 스레드, 파일 등에 접근하기 위한 스토리지 스레드 등을 가지고 있습니다.
Step 1 : 입력 처리
주소창에 타이핑을 한후에 UI 스레드는 우선 '검색어인지 URL 인지'부터 판단을 하게 됩니다. 입력 문구를 파싱해서 검색엔진에 보낼지, 요청한 페이지로 연결할지 결정하게 됩니다.
Step 2 : 탐색
사용자가 enter를 누르면, UI 스레드는 사이트의 콘텐츠를 받기 위해 네트워크 호출을 시작합니다. 로딩 스피너가 코너에 보이게 되며, Network 스레드는 요청에 대한 DNS loopup 과 TLS 연결설정과 같은 적절한 프로토콜을 거치게 됩니다.
이때 Network스레드는 HTTP 301과 같은 server redirect header를 수신할 수도 있습니다. 이 경우, Network스레드는 서버가 redirect을 요청하도록 UI스레드와 통신합니다.
그런 뒤에 다른 URL요청이 시작될 것입니다.
Step 3 : 응답 읽기
응답 바디(payload)가 들어오기 시작하면, 네트워크 스레드가 스트림의 처음 몇 바이트를 확인합니다. Content-Type 헤더가 데이터 타입을 알려주지만, 빠지거나 틀릴 수 있기 때문에 MIME Type 스니핑을 수행합니다. 소스 코드의 주석에서 content-type과 payload를 어떻게 처리하는지 알 수 있습니다.
만약 응답이 HTML 파일일 경우 렌더러 프로세스에 데이터를 넘기고, zip 또는 다른 형식의 파일이라면 다운로드 메니저에 데이터를 넘깁니다.
이 때 safe browsing 체크를 통해 악성 사이트인지 확인하고, CORS 체크를 통해 민감한 cross-site 데이터가 렌더러 프로세스에 도달하지 못하게 합니다.
Step 4 : 렌더러 프로세스 찾기
모든 검사가 완료되면 네트워크 스레드가 브라우저가 요청한 사이트로 이동해도된다고 확신하면 UI 스레드에게 데이터가 준비되었음을 알려줍니다. 그러면 UI 스레드는 웹 페이지 렌더링을 담당할 렌더러 프로세스를 찾습니다.
여기서 네트워크 요청이 응답을 받는데 수백 밀리초가 걸릴 가능성이 있음으로 이 프로세스의 최적화를 위해 UI 스레드는 Step 2에서 네트워크 스레드에 URL 요청을 보낼 때부터 이미 어떤 사이트로 옮겨가야하는 지 알고 있는 상태이기 때문에, UI 스레드는 네트워크 요청과 동시에 랜더러 프로세스를 사전에 찾거나 시작하려고 합니다.
이렇게 진행을 했을 때, 네트워크 스레드가 데이터를 수신했을 때, 랜더러 프로세스는 이미 대기 상태에 있게 됩니다.
(만약 탐색 도중 cross-site로 리다이렉트된다면 준비된 프로세스는 사용되지 않고 다른 프로세스가 필요하게 됩니다.)
Step 5 : 탐색 수행
데이터와 렌더러 프로세스가 준비되면, 탐색을 커밋하기 위해 브라우저 프로세스에서 렌더러 프로세스로 IPC가 전송됩니다. 또 데이터 스트림을 전달하여 렌더러 프로세스가 html 데이터를 계속 받을 수 있게 합니다. 렌더러 프로세스에서 커밋이 확인되면 브라우저 프로세스는 탐색을 완료하고 문서 로딩 단계를 시작합니다.
이 시점에서 주소창이 갱신되고 security indeicator와 사이트 설정 UI가 새 페이지의 사이트 정보를 반영되고 탭의 세션 이력이 갱신됩니다. 탭/세션 복구 기능을 위해, 탭이나 윈도우를 닫을 때 세션 이력은 디스크에 저장됩니다.
Extra Step : 초기 로드 완료
탐색이 커밋되고 나면, 렌더러 프로세스가 리소스 로딩과 페이지 렌더를 지속합니다. 렌더링을 끝내면 브라우저 프로세스에 IPC를 반환합니다. 이 시점에서 UI 스레드는 탭의 로딩 스피너를 정지시킵니다. 클라이언트 사이드의 JS는 이 시점 이후에도 계속 추가적인 리소스를 로드하거나 새로운 뷰를 렌더할 수 있습니다.
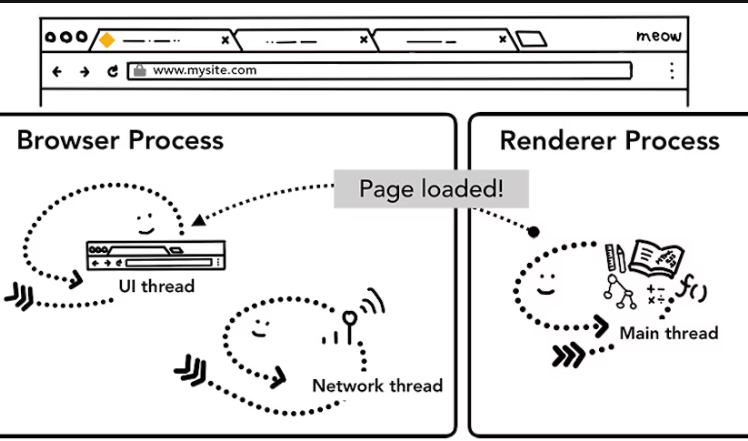
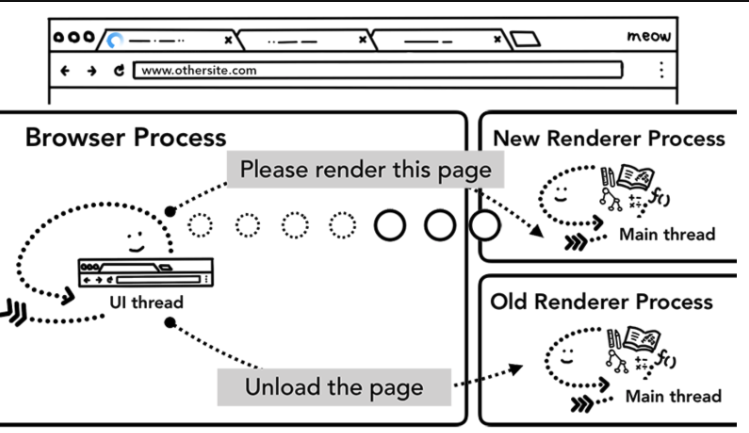
다른 사이트로 이동하기
간단한 탐색 절차는 위와 같습니다. 그러나, 사용자가 주소창에 다른 URL을 다시 입력하게되면 브라우저 프로세스는 동일한 단계를 거쳐 다른 사이트로 이동하게 될 것입니다.
하지만 이것이 수행되기 전에 현재 랜더링된 사이트에서는 beforeunload 이벤트를 고려하는 지 확인할 필요가 있습니다.
beforeunload
beforeunload 는 다른 사이트를 방문하거나 탭을 닫을 때 "이 사이트에서 나가시겠습니까?" 팝업을 띄울 수 있습니다. JS 코드를 포함한 탭 안의 모든 것들은 렌더러 프로세스가 처리하므로, 브라우저 프로세스는 새 탐색 요청이 들어올 때 렌더러 프로세스를 체크할 필요가 있습니다.
무조건적으로 beforeunload 이벤트 핸들러들을 추가하지는 마세요. 탐색을 시작하기도 전에 해당 이벤트에 대한 헨들러를 실행시켜야 하기 때문에 대기 시간이 더 생깁니다. 페이지에 작성한 데이터가 소실될 수 있음을 경고하는 등, 반드시 필요한 경우에만 추가하세요.
렌더러 프로세스가 탐색 과정을 초기화하면 렌더러 프로세스는 우선 beforeunload 핸들러를 체크합니다. 이후 탐색 초기화 프로세스는 동일합니다. 차이점은 렌더러 프로세스가 탐색 요청을 브라우저 프로세스에게 토스한다는 것입니다. 현재 렌더러 프로세스가 unload 같은 이벤트를 처리하는 동안 별개의 렌더러 프로세스가 새 탐색을 처리하기 위해 호출됩니다.
추가 도입 : 서비스 워커(Service Worker)
탐색 프로세스에 최근 변경점으로 서비스 워커 (Service Worker)가 도입되었다는 점입니다.
서비스 워커란 ?
브라우저가 백그라운드에서 실행하는 스크립트로, 웹 페이지와는 별개로 동작하며 웹페이지 또는 사용자의 인터랙션이 필요하지 않은 기능만 제공하고 있습니다.
서비스 워커의 생명주기는 웹 페이지와는 완전히 별개입니다. 웹 서비스와 브라우저 및 네트워크 사이에서 프록시 서버의 역할을 하며, 오프라인에서도 서비스를 사용할 수 있도록 합니다.
여기서 서비스 워커는 개발자로 하여금 로컬에 캐시할 데이터와 네트워크로부터 받아올 데이터를 컨트롤할 권한을 더 가지게 합니다. 서비스 워커가 페이지를 캐시에서 로드하도록 세팅되면 네트워크에서 데이터를 받아올 필요가 없어집니다.
그렇다면, 서비스 워커는 랜더러 프로세스에서 돌아가는 JS 코드인데 어떻게 탐색 요청이 들어오자마자 서비스워커가 있다는 사실을 알 수 있을까요 ?
서비스 워커가 등록되면 서비스 워커의 스코프는 래퍼런스로 취급됩니다. (자체 글로벌 스크립트 컨텍스트에서 실행 ) 탐색을 시작할 때, 네트워크 스레드는 등록된 서비스 워커 스코프와 도메인을 비교하여, 동일한 url에 서비스 워커가 등록되어 있으면 UI 스레드가 해당 서비스 워커 코드를 실행하기 위해 렌더러 프로세스를 찾게 됩니다. 서비스 워커는 데이터를 캐시에서 로드할테니, 네트워크 데이터 요청을 다 날리거나 새로운 리소스를 요청하게 됩니다.
선제 탐색 (Navigation Preload)
서비스 워커가 결국 네트워크에 데이터를 요청하기로 결정한다면 브라우저 프로세스와 렌더러 프로세스간의 이러한 반복 행위는 딜레이의 요인이 될 수 있습니다.
선제 탐색은 서비스 워커의 시작과 동시에 리소스들을 병행 로딩하여 이 과정을 빠르게 하는 메커니즘입니다. 이런 요청들에 헤더를 표기하여, 서버가 전체 문서 대신에 갱신된 내용만 보내는 등 다른 콘텐츠를 보낼지 결정하게합니다.
( 아래와 같은 형식으로 쓰이는 거 같습니다. 코드는 참고용 입니다~! )
https://web.dev/navigation-preload/#the-solution
addEventListener('activate', event => {
event.waitUntil(async function() {
// Feature-detect
if (self.registration.navigationPreload) {
// Enable navigation preloads!
await self.registration.navigationPreload.enable();
}
}());
});여기까지 브라우저 랜더링을 알아보았습니다.
브라우저가 네트워크로부터 데이터를 얻기위해서 거치는 과정 및 선제 탐색과 같은 api가 왜 개발이 되었는 지 등.. 을 알 수 있었습니다.
다음은 브라우저가 페이지를 렌더링하는 렌더링 프로세스에대해 알아보도록 하겠습니다~!
