
🔍 함수
✍ 특정한 결과 값을 얻기 위해 데이터를 입력할 수 있는 특별한 명령어, 크게 내장형 함수 와 사용자 정의 함수 로 나뉜다.
✍ 내장 함수 : 오라클 내부에서 기본으로 제공하는 함수, 단일행 함수와, 다중행 함수 로 나뉜다.
✍ 단일행 함수(Single-row-function) : 데이터가 한 행씩 입력되고, 입력된 각 행별로 결과가 하나씩 나오는 함수
✍ 다중행 함수(Multiple-row-function): 여러 행이 입력되어, 하나의 행으로 결과가 반환되는 함수
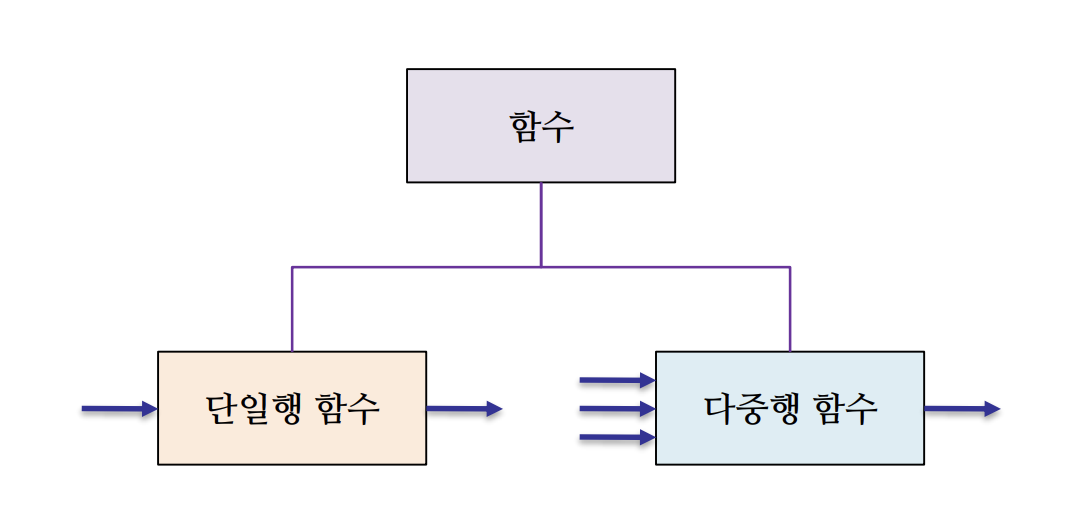
✍ 이 글에선 오라클에서 제공하는 내장 함수 중 다중행 함수를 알아보도록 하겠습니다.
✍ GROUP BY 절에 없는 열은 SELECT절에 올 수 없다. (그룹함수와 같이 올 수 있다.)
🔍 GROUP BY
✍ 데이터를 그룹화하여 결과 값을 얻을 수 있다.
SELECT [조회할 열 이름1], [조회할 열 이름2], ...
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY [그룹화할 열을 지정(여러 개 지정 가능)]
ORDER BY [정렬하려는 열 지정(여러 개 지정 가능)];-- GROUP BY
SELECT DEPARTMENT_ID, AVG(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;
SELECT DEPARTMENT_ID, JOB_ID, SUM(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID, JOB_ID;
SELECT DEPARTMENT_ID, COUNT(FIRST_NAME)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;🔍 HAVING
✍ 그룹화된 데이터의 조건을 걸어 조건에 맞는 데이터만 출력한다.
SELECT [조회할 열 이름1], [조회할 열 이름2], ...
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY [그룹화할 열을 지정(여러 개 지정 가능)]
HAVING [그룹화된 대상의 출력을 제한하는 조건식]
ORDER BY [정렬하려는 열 지정(여러 개 지정 가능)];-- 그룹함수로 행을 제한하기 위해 WHERE절에 사용할 수 없다.
SELECT DEPARTMENT_ID, AVG(SALARY)
FROM EMPLOYEES
WHERE AVG(SALARY) > 2000
GROUP BY DEPARTMENT_ID; -- ERROR
-- HAVING = 그룹된 집합을 제한
SELECT DEPARTMENT_ID, ROUND(AVG(SALARY), 2)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING AVG(SALARY) > 8000;
SELECT JOB_ID, AVG(SALARY) payroll
FROM EMPLOYEES
WHERE JOB_ID NOT LIKE 'SA%'
GROUP BY JOB_ID
HAVING AVG(SALARY) > 8000
ORDER BY AVG(SALARY);✍ WHERE은 SELECT의 출력 대상 행을 제한하는 것이고, HAVING은 그룹화된 대상의 조건에 맞지 않는 그룹의 출력을 제한한다.
🔍 GROUPING SETS 함수
✍ 같은 수준의 그룹화 된 열이 여러 개일 때 각 열별 그룹화를 통해 결과 값을 출력할 때 사용하는 함수
SELECT [조회할 열 이름1], [조회할 열 이름2], ...
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY GROUPING SETS [그룹화 열 지정(여러 개 지정 가능)];-- GROUPING SETS
SELECT DEPARTMENT_ID, JOB_ID, MANAGER_ID,
ROUND(AVG(SALARY), 2) AS AVG_SAL
FROM EMPLOYEES
GROUP BY GROUPING SETS((DEPARTMENT_ID, JOB_ID), (JOB_ID, MANAGER_ID))
ORDER BY DEPARTMENT_ID, JOB_ID, MANAGER_ID;
SELECT DEPARTMENT_ID, JOB_ID, AVG(SALARY)
FROM EMPLOYEES
GROUP BY GROUPING SETS(DEPARTMENT_ID, JOB_ID)
ORDER BY DEPARTMENT_ID, JOB_ID;🔍 ROLLUP 함수
✍ 소그룹간의 합계를 구하는 함수(첫 번째로 명시한 컬럼에 대해서만 소그룹 합계를 명시)
SELECT [조회할 열 이름1], [조회할 열 이름2], ...
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP([그룹화할 열을 지정(여러 개 지정 가능)]);
ROLLUP(A, B, C)
1. A 그룹별 B 그룹별 C 그룹에 해당하는 결과 출력
2. A 그룹별 B 그룹에 해당하는 결과 출력
3. A 그룹에 해당하는 결과 출력
4. 전체 데이터 결과 출력-- ROLLUP = 행 집계
SELECT DEPARTMENT_ID, JOB_ID, ROUND(AVG(SALARY), 2), COUNT(*)
FROM EMPLOYEES
GROUP BY ROLLUP(DEPARTMENT_ID, JOB_ID)
ORDER BY DEPARTMENT_ID, JOB_ID;🔍 CUBE 함수
✍ 소그룹간의 합계를 구하는 함수(ROLLUP과 다르게 첫 번째 컬럼만이 아닌 명시한 모든 컬럼 대해서 소그룹 합계를 명시)
SELECT [조회할 열 이름1], [조회할 열 이름2], ...
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY CUBE([그룹화할 열을 지정(여러 개 지정 가능)]);
CUBE(A, B, C)
1. A 그룹별 B 그룹별 C 그룹에 해당하는 결과 출력
2. A 그룹별 B 그룹에 해당하는 결과 출력
3. B 그룹별 C 그룹에 해당하는 결과 출력
4. A 그룹별 C 그룹에 해당하는 결과 출력
5. A 그룹에 해당하는 결과 출력
6. B 그룹에 해당하는 결과 출력
7. C 그룹에 해당하는 결과 출력
8. 전체 데이터 결과 출력SELECT DEPARTMENT_ID, JOB_ID, ROUND(AVG(SALARY), 2), COUNT(*)
FROM EMPLOYEES
GROUP BY CUBE(DEPARTMENT_ID, JOB_ID)
ORDER BY DEPARTMENT_ID, JOB_ID;🔍 GROUPING, GROUPING_ID 함수
✍ 특별히 연산 기능을 하지 않지만, 그룹화 데이터의 식별이 쉽고 가독성을 높이기 위한 목적으로 사용된다.
SELECT [조회할 열 이름1], [조회할 열 이름2], ...
GROUPING([GROUP BY절에 ROLLUP 또는 CUBE로 명시한 그룹화 대상 열 이름])
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP 또는 CUBE([그룹화할 열을 지정(여러 개 지정 가능)]);-- GROUPING = 소계 영역으로 생성되어 NULL이면 1
SELECT
DECODE(GROUPING(DEPARTMENT_ID), 1, '소계', TO_CHAR(DEPARTMENT_ID)) AS 부서,
DECODE(GROUPING(JOB_ID), 1, '소계', JOB_ID) AS 직무,
ROUND(AVG(SALARY), 2) AS 평균,
COUNT(*) AS 사원의수
FROM EMPLOYEES
GROUP BY CUBE(DEPARTMENT_ID, JOB_ID)
ORDER BY 부서, 직무;✍ GROUPING 함수 결과가 0이면 대상 컬럼이 그룹화 되었음을 의미, 0이면 그룹화되지 않았음을 의미한다.
SELECT [조회할 열 이름1], [조회할 열 이름2], ...
GROUPING_ID([그룹화 여부 확인할 열(여러 개 지정 가능) - ROLLUP 또는 CUBE에 명시한 열 이름])
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP 또는 CUBE([그룹화할 열을 지정(여러 개 지정 가능)]);-- GROUPING_ID = 소계 영역으로 생성된 열의 위치에 1 아니면 0을 표시하여 2진수 형식을 10진수로 변환
-- (1, 0) = 2, (0, 1) = 1, (1, 1) = 3
SELECT
DECODE(GROUPING_ID(DEPARTMENT_ID, JOB_ID),
2, '소계', 3, '합계',
TO_CHAR(DEPARTMENT_ID)) AS 부서번호,
DECODE(GROUPING_ID(DEPARTMENT_ID, JOB_ID),
1, '소계', 3, '합계',
JOB_ID) AS 직무,
GROUPING_ID(DEPARTMENT_ID, JOB_ID) AS GID,
ROUND(AVG(SALARY), 2) AS 평균,
COUNT(*) AS 사원의수
FROM EMPLOYEES
GROUP BY CUBE(DEPARTMENT_ID, JOB_ID)
ORDER BY 부서번호, 직무;✍ GROUPING_ID는 소계 영역으로 생성된 열의 위치에 1 아니면 0을 표시하여 2진수 형식을 10진수로 변환
✍ GROUPING_ID는 그룹화 여부를 검사하는 열을 여러 개 지정할 수 있다.
📖 reference
https://earth-95.tistory.com/156
https://for-my-wealthy-life.tistory.com/44
https://gent.tistory.com/386
인프런 오라클 데이터베이스 강의
