
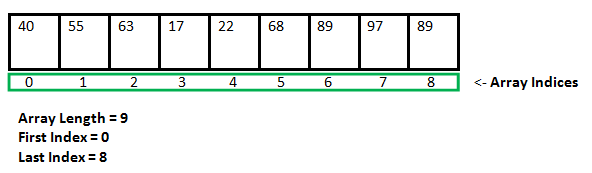
Array (배열)
가장 기본적인 자료구조 중 하나이다. 메모리에 데이터가 저장될 위치가 물리적으로 연결되어 있고, 순서대로 데이터가 저장된다. 따라서 물리적인 순서와 논리적인 순서가 동일하다.
장점
index를 통한 조회 빠르다.
찾고자 하는 데이터가 위치하는 index를 알고 있으면, 해당 데이터만 조회하는 것이 가능하다. 즉, Random Access가 가능하다. 조회하는 경우에는 Big-O(1)에 해당 요소로 접근이 가능하다.
단점
데이터의 삽입과 삭제 과정에서 불필요한 과정이 있어 시간이 오래 걸린다.
중간 위치에 존재하는 데이터를 삭제하게 된다면, 빈 공간이 생겨 배열의 연속적인 특징이 깨진다. 이 빈 공간을 채우기 위해, 뒷쪽의 요소들을 모두 앞으로 옮기는(shift) 작업을 해야 한다.
만약 맨 앞의 요소를 삭제하게 되면, 삭제된 요소를 제외한 모든 요소를 앞으로 한 칸씩 shift해야 한다. 이런 경우가 worst case로 Big-O(n)의 시간복잡도를 가진다.
이러한 단점은 데이터 삽입 때도 마찬가지이다. 맨 뒤에 데이터를 추가하는 것은 바로 가능하지만, 맨 앞에 데이터를 덮어씌우는 것이 아닌 추가한다 하면, 데이터를 추가하기 전에 모든 데이터를 한 칸씩 뒤로 shift하여 맨 앞 자리에 빈 공간을 만들어줘야 가능하다. 이 경우에도 Big-O(n)의 시간복잡도를 가진다.
또한, 처음 선언 할 때 크기를 정해야 하고 이를 변경할 수 없다.
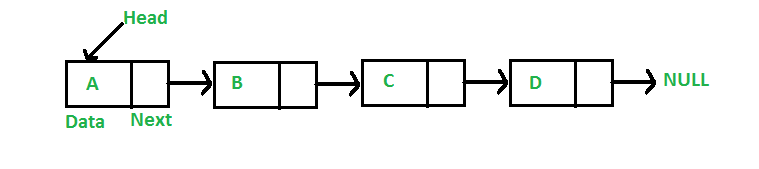
Linked List (연결 리스트)
Array의 단점을 극복하기 위해 만든 자료구조이다. 메모리 상에서 모든 요소의 물리적인 위치가 떨어져 있다. 각 요소마다 자신이 가진 데이터와 다음 요소의 주소를 기억하고 있다.
장점
-
동적 크기
Array와 다르게 크기를 변경할 수 있다. -
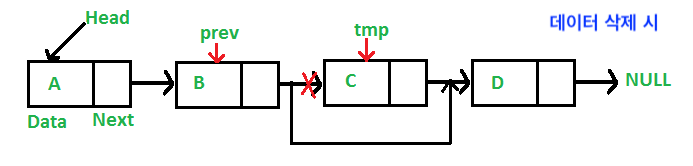
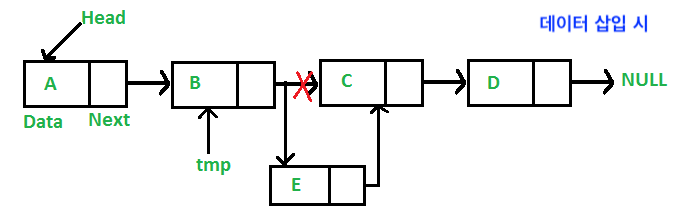
삽입/삭제 용이
데이터를 중간에 삽입하거나 삭제하는 것이 용이하다. 삽입 또는 삭제 시 요소가 기억하는 다음 요소의 주소만 바꿔주면 되기 때문에 많은 자원이 소모되지 않는다.
단점
- Random Access 불가
Linked List는 Sequentail Access를 지원하기에 Random Access가 불가능하다. 어떤 요소에 접근하기 위해서 처음부터 순차적으로 검색해야 한다.
특정 요소에 접근하기 위한 시간복잡도는Big-O(n)이다.
- 포인터를 저장하는 추가적인 메모리 공간 필요
각 요소마다 데이터를 저장할 공간 외에 다음 요소의 포인터 위치를 저장해야 하기 때문에 추가적인 메모리 공간이 필요하다.
Array vs Linked List
데이터의 저장 체계가 다름에 따라 서로 장단점이 존재한다.
메모리 저장 방식
- Array: 물리적으로 인접한 위치에 저장
- Linked List: 저장된 위치가 물리적으로 떨어져 있다. 위치 주소는 각 이전 요소의 memory 영역에 저장됨.
크기
- Array: 선언하는 시점에 size를 지정해야 한다.
- Linked List: 추후에 크기를 변경할 수 있다.
메모리 할당
- Array: Array가 선언되자 마자, Compile 할 때 메모리에 할당된다.
(Staticc Memory Allocation) - Linked List: 요소가 추가될 때, runtime 때 메모리에 할당된다.
(Dynamic Memory Allocation)
메모리 저장 위치
- Array: Stack
- Linked List: Heap
삽입 및 삭제
- Array
- index로 접근 후 삽입/삭제:
Big-O(1) - 삽입 전/삭제 후 전체적으로 shift:
Big-O(N)
- index로 접근 후 삽입/삭제:
- Linked List
- index로 접근 후 삽입/삭제:
Big-O(N) - 삽입 전/삭제 후 전체적으로 shift:
Big-O(1)
- index로 접근 후 삽입/삭제:
요소 접근
- Array
Random Access- index를 통해 직접적으로 접근이 가능
- 시간 복잡도:
Big-O(1)
- Linked List
Sequential Access- 처음부터 순차적으로 접근하며 찾아야 한다.
- 시간 복잡도:
Big-O(N)
출처
한재엽님 Github Interview_Question_for_Beginner
gyoogle님 Github tech-interview-for-developer
geeksforgeeks.org Data Structure
https://wooono.tistory.com/281
