0. Abstract
병렬 처리에 유용하고 학습 시간을 단축시키는 Transformer 모델을 소개함
- Encoder와 Decoder를 attention mechanism으로 연결함
- 변역 task에 탁월함
- 대용량이고 한정적인 학습 데이터에 적용 가능함
1. Introduction
About Sequence Model
Sequentce model의 계산 과정을 설명하면서 한계점을 드러냄
- RNN, LSTM, GRNN은 모두 sequence model 이다.
- Previous hidden state h(t-1)이 계산되어야 다음 hidden state h(t)가 계산될 수 있다.
- 병렬 처리가 불가능하다 (= long sequence length에서 매우 불리함)
- Sequential computation 방법을 바꿔야한다!
Attention Mechanisms
Attention의 중요성을 설명함
중요한 이유 ?
Input, Output의 sequence에서 단어 사이의 거리와 상관없이 dependency를 연산할 수 있음
- Sequence model과 Transduction model에서 매우 중요한 역할을 함
- RNN에 결합하여 사용할 수 있음
Transformer
논문에서 Transformer 모델이 어떻게 구성될지와 어떤 장점이 있는지 설명함
Transformer Architecture
- RNN 구조를 피하는 대신 Attention mechanism에 전적으로 기댈 예정
Transformer Ability
- 병렬 처리 가능함
- 매우 적은 학습 시간(12시간 정도)로 질 좋은 변역 결과물을 도출함
2. Background
3. Model Architecture
Transformer 모델 구조를 설명함
- 대부분의 competitive neural sequence transduction model은 Encoder-Decoder 구조를 가지고 있음
- Encoder : Input sequence x -> Representation sequence z
- Decoder : Representation sequence z -> Output sequence y
- 전체적으로 전부 가지고 있는 공통적인 구조적 특징이 있음
- Staked self-attention
- Encoder + Decoder
(Point-wise fully connected layers)
Model Architecture
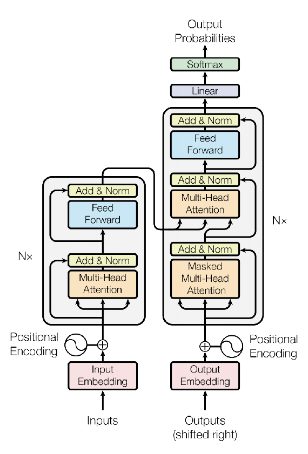
3.1 Encoder and Decoder Stacks
3.1.1 Encoder
Encoder의 구조를 설명함
Encoder의 구조적 특징
- 6개의 Encoder로 이루어져 있음
- 각 layer는 2개의 sub-layer로 이루어져있음
(1) Multi-head self-attention
- Stacked self-attention
- 다양한 관점에서 모델의 표현성을 높여줌
(2) Residual Connection + Layer Nomalization
- Output : LayerNorm(x + Sublayer(x))
Layer Nomalization
- 평균과 분산을 이용해 값을 Nomalize해줌
- 일각에서는 왜 사용하는지 모르나, 사용하면 성능이 높아져서 사용한다고 말함
Residual Connection
- Residual Connection을 거치므로 자기 자신 Sublayer(x)를 더해주는 형태
- Gradient Propagation이 잘되도록 사용되므로 Embedding layer를 포함한 모든 sub-layer에 적용함
(3) Feedforward network
- positio-wise fully connected
- 비선형 함수를 이용하여 모델의 성능과 표현력을 높임
(4) Residual Connection + Layer Nomalization
- Final Output dimension = 512
3.1.2 Decoder
Decoder의 구조를 설명함
Decoder의 구조적 특징
- 6개의 Decoder로 이루어져 있음
- 각 layer는 3개의 sub-layer로 이루어져있음
- Encoder에서 도출된 output에 multi-head attention을 적용함
- Encoder와 비슷함
(1) Masked Multi-head self-attention
- Future sequence를 보지 못하도록 Masking된 multi-head attention을 사용함
(2) Residual Connection + Layer Nomalization
(3) Multi-head self-attention
(4) Residual Connection + Layer Nomalization
(5) Feedforward network
(6) Residual Connection + Layer Nomalization
3.2 Attention
3.2.1 Scaled Dot-Product Attention
Input 차원
- Query = d(k)
- Key = d(k)
- Value = d(v)
Value의 가중치 (Using matrix Q, K, V)
