Paper : https://arxiv.org/pdf/2308.16512
Github : https://github.com/bytedance/MVDream
0. Abstract
MVdream
Text prompt를 이용해서 multi-view image를 생성할 수 있는 diffusion model
-
2D, 3D data를 함께 학습함으로써, 2D diffusion model의 generalizability와 3D rendering의 consistency를 모두 달성함
-
Generalizability : 2D diffusion model은 diffusion(확률 과정)을 통해 이미지를 생성하므로, 다양한 입력 데이터나 조건에서 얼마나 일관적으로 좋은 품질의 이미지를 생성할 수 있는지를 의미함
-
Consistency : 3D rendering은 3차원을 2차원 이미지로 변환하는 과정이므로, rendering된 이미지들이 얼마나 일관적으로 정확하고 자연스러운 2D 이미지로 변환할 수 있는지를 의미함
-
-
어떤 종류의 2D data든 모두 받아서 3D generation을 위한 학습에 사용할 수 있음 (그만큼 3D 구조에 대한 이해도가 높음)
-
Dreambooth처럼 적은 수의 2D image를 가지고도 3D generation을 위한 새로운 concept 학습 가능
Agnostic
어떤 모델이든 상관없이 적용 가능한 방법론
1. Introduction
기존 3D object generation 방법
-
Template-based generation pipeline : 미리 정해둔 기본 템플릿을 활용하여 자동으로 콘텐츠를 생성하는 방법
-
3D generative model : 3D 공간에서의 객체나 장면을 자동으로 생성할 수 있는 모델
-
2D-lifting method : 2D image에서 3D 정보를 추정하여 복원하는 방법 (2D에서 얻을 수 없는 depth 정보나 3D 구조를 유추할 수 있음)
-
Pre-trained 2D generation model을 3D generation에 적용함
-
Pre-trained 2D generation model이 대용량 2D dataset들을 학습했기 때문에, image에서 보이지 않거나, 사실적이지 않은 부분들도 생성해낼 수 있음
-
ex. Dreamfusion, Magic3D
- 2D image를 통해 학습된 정보와 Score Distillation Sampling를 이용해서 3D representation을 생성함
-
Score distillation sampling(SDS)
Score-Based Generative Models에서 생성된 데이터의 품질을 개선하기 위해 사용되는 방법
- 모델이 학습한 score를 바탕으로, 데이터 포인트가 얼마나 진짜 데이터 분포에 가까운지를 판단하여 더 현실적이고 고품질의 데이터를 생성할 수 있도록함
기존 3D object generation 방법들의 단점
-
Template-based generation pipeline, 3D generative model
- 두 방법 모두 3D dataset을 사용해야하는데, 3D dataset 자체가 매우 크고 사용할 수 있는 3D model 자체가 적어서 어려움
- 위와 같은 문제 때문에 단순한 형태와 질감을 가진 3D 밖에 생성하지 못하기 때문에, 현실감이 떨어짐
-
2D-lifting method
-
2D image를 학습하기 때문에 데이터에 대한 multi-view 정보가 부족하고, 3D 구조에 대한 이해도가 낮아 정확하게 3D를 표현하기에 부족함
-
Multi-face Janus Problem : 하나의 사람이 여러 얼굴 이미지에서 다양한 각도, 표정, 조명, 나이 등에 의해 다르게 보일 수 있는 것처럼, 2D-lifting method는 multi-view에 대한 정보가 부족하므로 다른 각도에서 보이는 이미지를 표현할 수 없음
-
Content Drift Problem : 3D 객체를 생성할 때, 내용이 일관되지 않고 변화하거나 왜곡되기 때문에 다른 각도에서는 잘못된 결과물이 생성될 수 있음
-
-

MVdream 모델의 Contribution
2D-lifting method가 가지고 있는 이런 문제점들에도 불구하고, 본 논문은 대용량의 2D dataset을 이용해서 3D generation하는 방법을 선택하고 있다.
-
동시에 multi-view image를 생성하여 Multi-view에 대한 이해도를 높임
-
Multi-view images(from 3D assets)과 2D image-text pairs를 jointly training함으로써, 앞서 언급했던 Generalizability와 Consistency를 달성함
-
Fine-tuning을 통해 dreambooth와 같이 robust한 multi-view diffusion model로 만듬
- 3D Nerf model까지 만듬
2. Related work and Background
-
3D generative model
-
Diffusion model for object novel view synthesis
-
Lifting 2D diffusion for 3D generation
3. Method
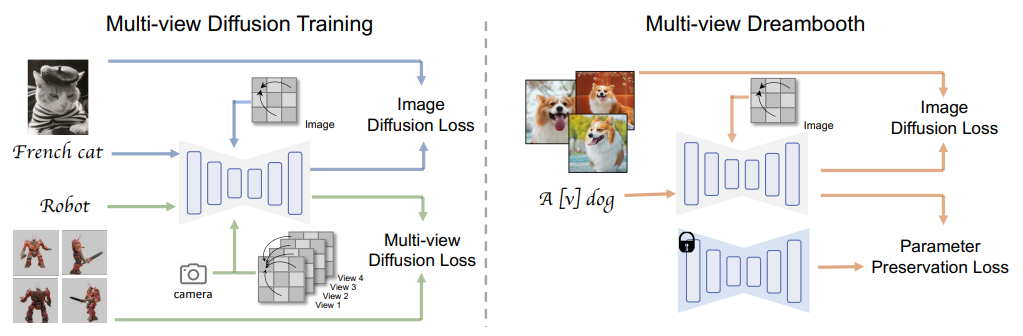
Multi-view Diffusion model

기존 diffusion model에서 3D Self-Attention과 Camera Embeddings가 추가된 모델
- Mathematical Expression
- noisy image : xt ∈ R_F×H×W×C
- F : different angle 개수
- text prompt : y
- extrinsic camera parameter : c ∈ R_F×16
- generate image standard : x0 ∈ R_F×H×W×CExtrinsic camera parameter
Camera parameters 관련 참고하면 좋을만한 사이트
1. Multi-View Consistent Generation with Inflated 3D Self-Attention
Q. How to generate a set of consistent images from the same text prompt
(Multi-view를 학습하기 위해 어떻게 같은 text prompt로부터 일관된 이미지를 생성할 수 있을까?)
A. Self-attention에 있는 모든 view들을 이어서 2D self-attention layer를 3D로 바꾼다.
- tensor shape : B×F×H×W×C -> B×FHW×C
2. Camera Embeddings
Q. How to add the camera pose control
(어떻게 하면 camer 시점을 추가할 수 있을까?)
A. 여러가지를 실험해본 결과, 2-layer MLP를 이용해서 embedding한 camera parameters가 가장 quality가 좋았다.
-
Multi-view를 위한 different view를 나타내기 위해, MVdream 모델은 position encoding이 중요함
-
Residual처럼 camera embedding을 time embedding처럼 추가했을 때 가장 성능이 좋았음
- cross attention에 넣는 것처럼 text embedding으로 넣으면 아무래도 누락된 부분들이 있을 수 있어서 robust하진 않다고 함
3. Training Loss Function
Q. How to maintain the quality and generalizability
(어떻게 하면 생성 quality와 generalizability를 유지할 수 있을까?)
A. 대용량의 text-to-image dataset을 이용해서 joint training을 하면 된다.
-
Mathematical Expression
-
text-image dataset : X
-
multi-view dataset : X_mv
-
training samples : {x, y, c} ∈ X ∪ Xmv
-
noisy image : x_t
-
random noise : ϵ
-
condition : y
-
camera condition : c
-
multi-view diffusion model : ϵθ
-
multi-view diffusion loss
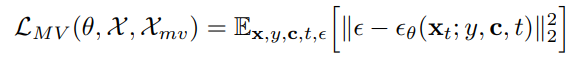
-
2. Text-to-3D Generation
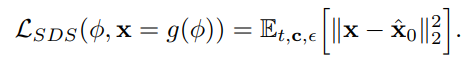
4. Experiments
Results
-
Image Generation

-
Text-to-3D Generation


사랑스러운 MVDream 논문 리뷰 잘 보고 갑니다!!
딥러닝에 대해 해박하신것 같아요~!!!!!! 종종 들리겠습니다 ^~^