Paper : https://arxiv.org/pdf/2406.05981
Code : https://github.com/GATECH-EIC/ShiftAddLLM
0. Abstract
Shift-and-add Reparameterization
Reparameterization
주로 sampling 연산을 미분할 수 없어서 backprop을 사용하지 못하는 문제를 해결하기 위해 사용함
- sampling 과정을 바로 미분할 수 없으니, sampling 연산 과정의 파라미터를 바꿔서 미분이 가능하도록 변환하는 기법
1. Introduction
하드웨어 요구에 맞춰 LLM 모델을 넣기에 최근에 가장 대두되는 문제점은
- 거대한 파라미터 사이즈
- 그와 연관된 연산 작업들
이다.
그래서 최근에 LLM의 효율성을 높이기 위해 시도됐던 방법들은 pruning quantization과 attention optimization이였다.
하지만 이 두 방법 모두 attention과 MLP layer에서는 costly한 multiplication operation에 의존하고 있다는 문제점이 있다.
그래서 제안하는게..
extensive한 multiplication을 bitwise shift, add와 같은 하드웨어에서 cost-effective한 방법으로 대체하자!
이렇게 했더니 아래 표에서처럼 에너지는 31배, 면적은 26배나 줄었다.
그리고 이런 방법은 이미 ShiftAddNet에서도 증명됐다.
그래서 결론적으로는
기존의 Reparameterization technique들(scratch로부터 학습하거나, 거대한 fine-tuning을 해야하는..)과 달리,
우리는!
post-training optimization을 통해 shift-and-add 컨셉을 LLM에 적용하는 새로운 방법을 제시한다..!
ShiftAddNet
선행 연구
Post-training Optimization
이미 학습이 완료된 네트워크를 통계적으로 분석하여, 가장 정보 손실 정도가 작은 max or threshold or α 를 선택하는 방법
Multiplication-less LLM Challenges
Multiplication-less LLM을 디자인하기 위해서 3가지 callenges가 있다.
- 어떻게 post-training 하면 효율적으로 pretrained된 LLM에 shift and add의 컨셉을 적용할 수 있을까?
-
기존 방법들은 치명적인 quantization error들이 발생하곤 했기 때문에, accuracy를 유지하기 위해서 extensive fine-tuning이나 retraining을 해야만 했음
-
그래서 우리는!
LLM을 위한 ready-to-use post-training reparameterization을 개발했다.
- 어떻게 shift-and-add reparameterization 방법에서 accuracy가 떨어지지 않도록 할 수 있을까?
-
multiplication 연산을 shift와 add 연산으로 바꾸면 당연히 정확도가 떨어질 수 밖에 없음
-
다른 연구들은 그래서 어쩔 수 없이 fine-tuning하거나 모델 사이즈를 늘리거나 LLM 구조를 복잡하게 만들거나 할 수밖에 없었음
-
그래서 우리는!
weight와 activation error를 모두 optimize하면 reparameterization error가 최소화될꺼라고 가정했다.
(최근에 나온 activation-aware weight quantization method와 같음)
- 어떻게 LLM의 layer들과 block들의 다양하고 민감한 조건들을 모두 충족하면서 reparameterization을 handling 할 수 있을까?
-
각 layer마다 따로따로 reparameterized weight에 최적화된 bit를 할당하기 위해서 자동화된 방법이 필요함
- vulnerable layer : higher-bit representation이 필요함
- less-sensitive layer : lower-bit representation이 필요함
-
그래서 우리는!
저렇게 자동화된 방법을 각 layer마다 따로따로 사용한다.
(aggressive한 reparameterization과 redundancy exploitation을 최대화했기 때문에, bottlenecked layer는 없을거라 확신함)
Activation-aware Weight Quantization
중요하지 않은 가중치는 낮은 정밀도로, 중요한 가중치는 높은 정밀도로 유지하는 방식으로 quantization을 진행하는 방법
Contributions
-
ShiftAddLLM(bitwise shift-and-add reparameterization을 이용해서 pretrained LLM을 post-training하는 방법)을 제안함
- 모든 weight는 binary matrices로 경량화됨
- 연관된 multiplications는 모두 shift-and-add operation으로 reparameterized됨
-
Multi-objective optimization method와 weight와 output activation objective를 모두 최적화하는 방법을 사용해서 Accuracy loss를 완화시킴
- 전반적으로 reparameterization error를 최소화함
- lower perplexity와 better task accuarcy를 달성함
-
각 layer의 compression에 대한 vulnerability에 따라 최적의 bit를 자동으로 할당해주는 방법을 제안함
- 각 layer의 reparameterized된 weight에 따라 최적의 bit 숫자를 결정해줌
Perplexity
언어모델 평가 지표
- 언어 모델이 샘플을 얼마나 잘 예측하는지를 정량화함
- Perplexity 점수가 낮을수록 모델이 샘플을 예측하는 데 더 나은 것으로 간주함
2. Related Works
2-1. LLM Quantization
Quantization-aware Training(QAT)
- 보정된 data와 거대한 retraining resource가 필요함
Post-training Quantization(PTQ)
- 계산할게 적고, time overhead도 적게듬 => 그래서 이게 더 좋긴 함!
- PTQ strategy
- weight와 activation에 모두 uniform한 quantization을 적용하는 방법
(보통 8 bit로 제한되고, 이로 인해 정확도가 현저히 낮아질 수 있음) - FP16 형식으로 activation을 유지하면서 LLM weight에만 lower bit를 할당하는 weight-only quantization를 적용하는 방법
(LLM의 방대한 양의 파라미터들로 인해 발생하는 Memory bottleneck을 줄여줄 수 있음)
- weight와 activation에 모두 uniform한 quantization을 적용하는 방법
- Quantization-aware Training(QAT) : 학습하면서 quantization을 적용하는 방법
- Post-training Quantization(PTQ) : 학습 이후에 quantization을 적용하는 방법
ShiftAddLLM
ShiftAddLLM은 Multiplication을 hardware-friendly primitives로 대체함으로써 이 자체만으로 weight가 사용하는 bit를 줄일 수 있고, 더 나아가 에너지, latency, memory 사용량도 줄일 수 있다.
2-2. Multiplication-less Models
그동안 Multiplication less를 시도한 model들은 많았다.
하지만 이런 모델들은 트랜스포머에 의해 조정되거나, 최근 연구들은 scratch부터 학습해야하거나 엄청난 양의 파라미터를 fine-tuning해야한다는 문제점이 있었다.
그래서 본 논문에서 제안하는 ShiftAddLLM 모델은 추가적인 학습이나 fine-tuning 없이 적용 가능하고, 더 나아가 정확도를 높이고 GPU latency, energy, memory usage를 줄였다고 한다.
3. Preliminaries
3-1. Binary-coding Quantization (BCQ)
본 논문에서는 PTQ 기법 중 하나인 Binary-coding Quantization이라는 binarization 기법을 사용하고 있다. BCQ를 통해 가중치 행렬을 이진 형식으로 변환하여 곱셈 연산을 더 효율적인 쉬프트와 덧셈 연산으로 대체하는 방법을 보여주고 있다.
먼저 BCQ 기법을 이용해서 LLM의 layer에 있는 각 weight tensor를 q bit로 quantization한다. Q bit로 quantization할 때, binary matrices와 scaling factor의 linear combination을 이용한다. Quantization error를 최소화하기 위해, weight를
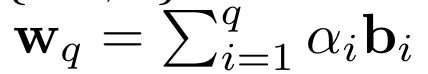
로 근사한다.
다시 말해, 최적의 binary matrices와 scaling factor를 얻기 위해
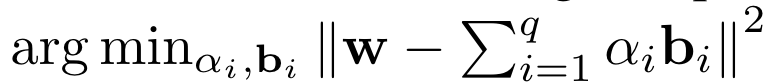
의 식을 사용한다.
만약에 q가 1이라면, 단순한 binary quantization이 된다.
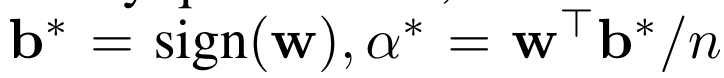
만약에 multi-bit quantization이라면, 그리디 알고리즘을 이용할 수 있다. 처음은 그리디 알고리즘을 이용해서 binary matrices와 scaling factor를 초기화한 후에, i번째 bit부터는 (i-1)번째 bit로부터 residual r를 최소화하는 방식으로 quantization을 진행한다.
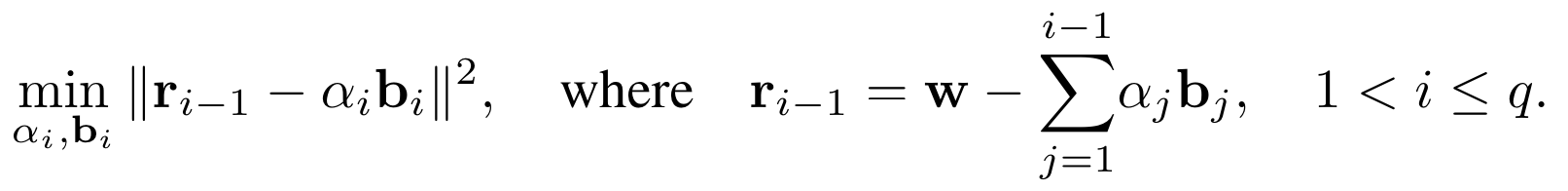
Insight
- BCQ 방법은 Scaling factor와 biases를 조절하면서 uniform과 non-uniform quantization format을 모두 지원할 수 있음
- ShiftAddLLM은 BCQ를 바탕으로 두되, 관련된 모든 multiplication을 lower-cost hardware substitutes(ex. add, shift..)로 바꿔서 사용했음
- ShiftAddLLM은 weight quantization error 뿐만 아니라 output activation error도 최적화함으로써, lower quantization bit로 energy, memory, computational cost를 절약했음
3-2. Shift and Add Primitives
Multiplication을 직접적으로 하드웨어에 구현하는 것은 비효율적이다.
따라서, shift and add operation를 대신 이용하는게 더욱 효율적이다.
- Shift 연산 = 거듭제곱과 같음
- Energy와 Area 측면에서 절약됨
4. The Proposed ShiftAddLLM Framwork
4-1. ShiftAddLLM: Post-training Reparameterization of LLMs with Shift and Add Primitives
Post-training shift-and-add 관점에서 어떻게 pretrained LLM을 reparameterization하는 설명할꺼임
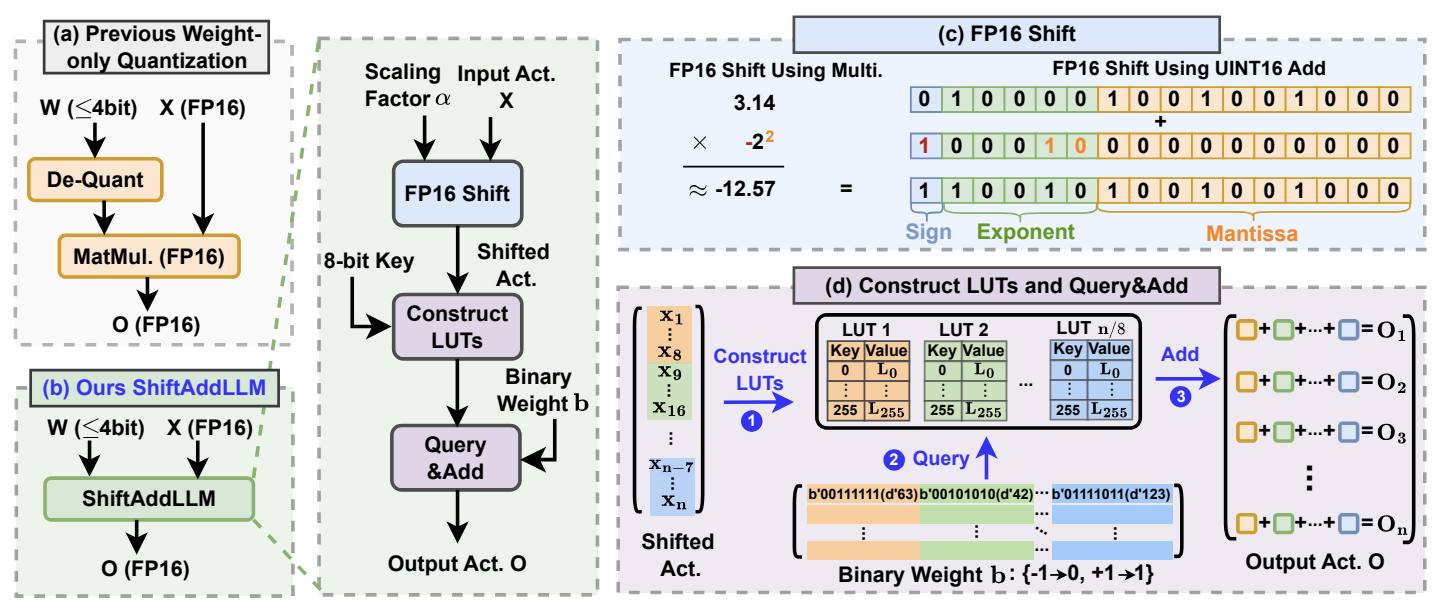
Post-training Reparameterization of LLMs
Reparameterization 한 후에, 또 fine-tuning 하게 만들지 않기 위해, LLM에서 기존에 쓰이는 multiplication을 최대한 따라하려고 했다.
-
(기존 방법) Weight-only Quantization : gradient-based 또는 activation-aware uniform quantization을 사용해서 pretrained weight distribution에 더 잘 fit하게 만들었음
- 장점 : quantization error가 줄어듬
- 단점 : 하드웨어에 바로 사용할 수 없고, activation을 가지고 multiplication을 하려면 FP16에 on-the-fly dequantization을 해야함
-
(논문 속 방법) ShiftAddLLM : non-uniform quantization도 지원하는 BCQ 형식을 이용해서 dequantization에 필요한 것들을 우회함
- 이 알고리즘을 이용해서 pretrained weight를 binary matrics와 scaling factors로 quantization함
- Alternating optimization cycle을 돌면서, 모든 scling factor를 PoT 형식으로 맞춰 quantization함
(메모리를 절약시키기위해서)

이 reparameterization을 통해서,
weights와 activations에 관련된 모든 multiplication을 2 step을 통해 대체할 수 있다.
- Activations와 scaling factor 사이의 bitwise shifts 진행
- Activations는 FP16 형식이고 부동소수점과 양수/음수의 PoT 정수 사이의 multiplication은 정수형 덧셈으로 바꿀 수 있음
- Binary matrics를 이용해서 shifted activations 사이에 queries와 add 끼워넣기
- 불필요한 축적을 막기 위해, shifted activations의 8개 elements마다 256개의 가능한 value들을 미리 계산하고 LUT를 만들어두었음
(이렇게 함으로써, LUT의 query로 binary matrix와 shifted activations 사이의 multiplication을 다룰 수 있게됨) - 그리고 모든 partial sum을 더하여, final output activation을 얻음
따라서!
ShiftAddLLM은 BCQ 기법과 PoT를 이용해서 non-uniform한 quantization을 할 수 있는 새로운 multiplication-less 접근 방법을 제시했다.
- outlier weight과 activations에 대한 representation capacity(표현 능력)을 높였음
- PoT를 사용함으로써, non-outlier weight과 activations에 대해 제한적이였던 quantization resolution을 해결했음
on-the-fly dequantization
데이터가 필요할 때마다 실시간으로 양자화된 값을 원래의 값으로 변환하는 과정
(저장된 데이터가 양자화된 상태로 유지되다가, 실제 사용 시점에서 dequantization됨)
PoT
이미지의 가로 세로 크기가 2의 제곱식으로 설정되는 것
- 컴퓨터에서 이미지를 로드할 때 PoT texture가 아닐 경우 가까운 PoT 크기로 변형해 사용하므로 메모리 낭비가 발생함. 그래서 보통 PoT 규칙에 맞춰 32, 64, 128, ..., 4096 등의 크기로 변형해 사용함.
- Bitwise shifts : 이진수의 비트를 좌우로 이동시키는 연산
- 곱셈과 나눗셈을 보다 효율적으로 수행할 수 있는 방법임
- Dense shifts : 부동 소수점 수와 2의 거듭제곱(PoT) 정수 사이의 곱셈을, 하드웨어에 맞게 효율적인 정수 덧셈 명령어로 대체하는 연산
LUT(Look-Up Table)
미리 계산된 결과 값을 저장해 두고 필요할 때 빠르게 참조하는 데 사용되는 데이터 구조
- 복잡한 계산을 단순화하고 처리 속도를 높이는 데 유용함
Quantization resolution
신호나 데이터를 quantization할 때 사용하는 비트 수
- Quantization 해상도가 높을수록 더 많은 비트가 사용되어 더 정밀하게 원본 신호를 표현할 수 있음
4-2. ShiftAddLLM: Multi-objective Optimization
Motivating Analysis on Previous LLM Quantization Objectives
본 논문에서는 Weight-only Quantization 방법을 실험하면서 large quantization error와 accuracy drop이 발생하는 이유를 찾았다.
(보통 quantization error를 최소화하기 위해, Weight Objective/Activation Objective 방법을 사용함)
- Weight Objective : weight quantization error를 최소화하기 위한 방법
- quantizied weights의 각 row에 대한 scaling factor를 이용함
- 하지만!output activation error를 최적화할 수 없음
(왜냐하면 각 weight가 최종 Output을 생성하기위해 더해지기 전에, unique input activation 각각 곱해져있기 때문임)
(input activation이 다양하기 때문에, weight quantization error를 각각 다르게 rescale 해야하고 이런 과정으로 인해 output activation에 거대한 divergence가 생기게됨)
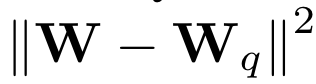
- Activation Objective : output activation error를 최소화하기 위한 방법
- weight의 한 column을 한번에 quantizing하고 끊임없이 남아있는 unqunatized weights를 업데이트함
- 하지만! 고정된 scaling factor는 나중에 조정된 weight를 적절하게 수용하지 못할 수 있음
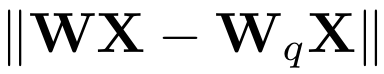
Our Multi-Objective Optimization
그래서 본 논문에서는 column-wise scaling factor를 사용해서 Weight Objective와 Activation Objective를 합친 새로운 방식을 제안했다.
-
이 방법은 weights와 activations에서 모두 quantization error를 효과적으로 줄여주고, ShiftAddLLM의 정확도를 높여줬음
-
quantized weight의 다양한 input activations의 영향을 제거함으로써, column-wise scaling factor를 이용해서 Weight Objective가 가진 단점을 극복했음
(각 scaling factor는 끊임없이 activation value와 대응함) -
subsequent column에 대한 scaling factor는 이에 대응하는 column's weight에 맞춰 업데이트되므로, 기존의 Activation Objective보다 더 fit해짐
column-wise scaling factor
행렬의 각 열에 개별적으로 적용되는 scaling factor
- 행렬의 각 열이 서로 다른 범위나 분포를 가질 때, 차이를 보정하여 보다 안정적인 계산을 가능하게함
Accuracy vs. Latency Tradeoffs
column-wise scaling factor을 통해 reparameterization 이후 정확도는 올라갔지만, BCQ의 문제점을 완전히 해결한 것은 아니다.
왜냐하면 30B 이상의 파라미터를 가진 Large model에서는 여전히 latency로 인한 time overhead가 발생하고 있기 때문이다.
이 문제(latency)를 해결하기 위해서 본 논문에서는, block-wise scaling factor를 제안하고 있다.
- block-wise scaling factor : 8 column 마다 기존 row의 8/1씩 scaling factor를 공유하는 구조
- 그래프를 보면 latency가 줄어든 것을 확인할 수 있음
따라서!
단순히 column-wise와 block-wise design을 이용한 Multi-Objective Optimization을 통해 weight quantization error와 activation quantization error를 줄일 수 있었다.
4-3. ShiftAddLLM: Mixed and Automated Bit Allocation
Sensitivity Analysis
Different layer와 block에 따라 sensitivity를 분석한 결과,
뒤에 있는 block일수록 quantization이나 reparameterization error가 더 많이 생긴다는 것을 알게 되었다.
5. Experiments
5-1. Experiment Settings
Models
5개의 SOTA LLM 모델들(OPT, LLaMA-1/2/3, Gemma, Mistral, Bloom)을 사용했다.
Task and Datasets
WikiText-2를 dataset으로 이용했다.
- 추가적으로 OPT-66B, LLaMA-2-70B은 7가지 downstream task에 대해 zero-shot task accuracy를 측정했음 (가장 큰 두 모델에서 진행한거임)
- Downstream task : ARC (Challenge/Easy), BoolQ, Copa, PIQA, RTE, StoryCloze
Baselines
4개의 SOTA LLM quantization 모델들(OPTQ, LUT-GEMM, QuIP, AWQ)를 사용했다.
Evaluation Metrics
Accuracy랑 Efficiency metrics를 이용해서 평가했다.
- Accuracy : WikiText-2에 대한 perplexity, Downstream task에 대한 zero-shot accuracy
- Efficiency : single A100-80GB GPU에 대한 latency, Eyeriss-like hadware accelerator를 이용한 energy cost(computational energy cost와 data movement energy cost를 모두 측정할 수 있음)
Eyeriss-like hadware accelerator
딥러닝 신경망(DNN)을 위한 고효율 하드웨어 가속기
- 에너지 효율성을 극대화함
- 모바일 및 임베디드 장치에서 DNN 모델을 효과적으로 실행할 수 있도록 설계되어있음
5-2. ShiftAddLLM over SOTA LLM Quantization Baselines
Results on OPT Models
4개의 baseline 모델과 ShiftAddLLM을 비교해서 효율성을 평가했다.
- Perplexity
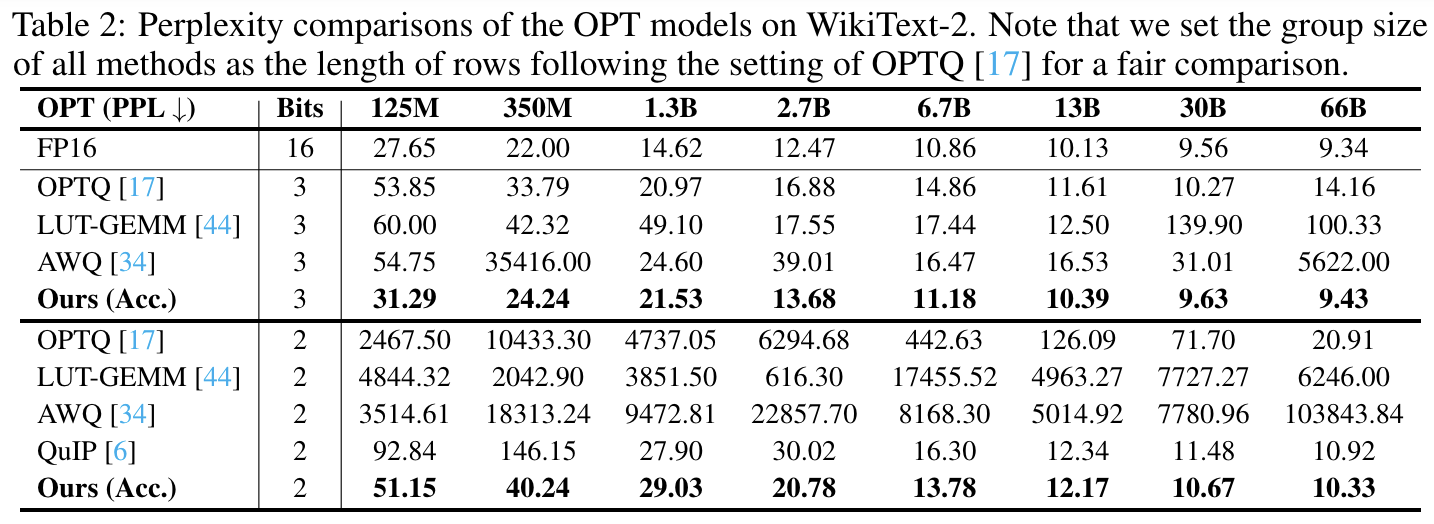
3 bit, 2 bit 모두 다른 OPT 모델들에 비해 월등하게 낮은 perplexity를 보여주고 있다.
- Accuracy-latency tradeoffs
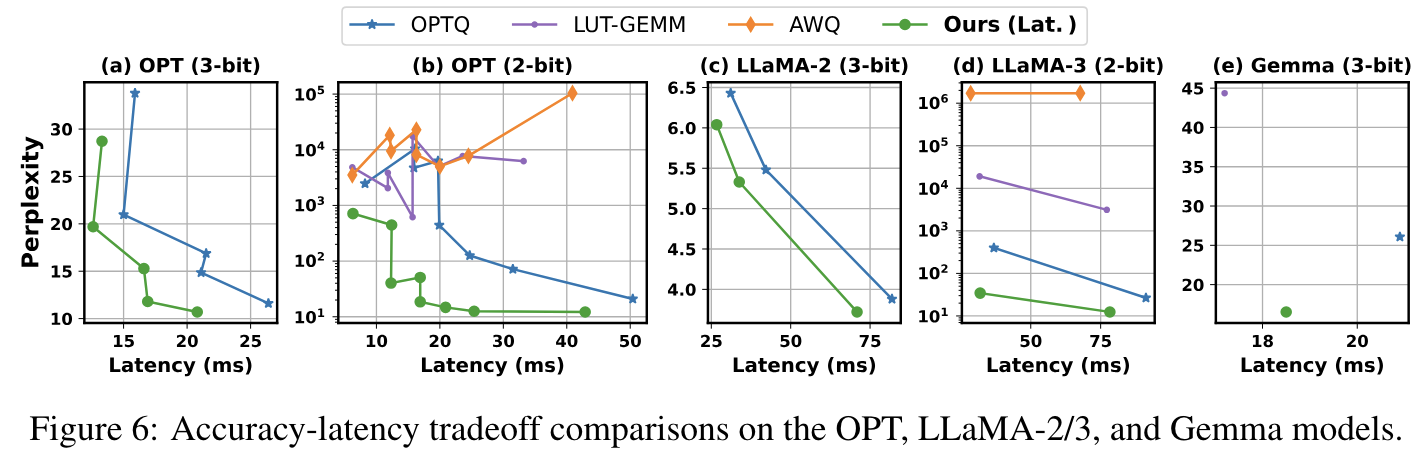
다른 OPT 모델들에 비해 더 나은 accuracy-latency tradeoff를 보여주고 있다.
- perplexity reduction에도 유사한 latency를 보여주거나, 다른 모델들에 비해 현저히 낮은 latency reduction을 보여줌
- 유사하거나 낮은 perplexity에서 더 높은 energy saving도 보여줌(appencix에 나옴!)
Results on LLaMA Models
오픈 소스 LLM 중에서 월등한 성능을 보이고 있는 LLaMA 모델과 ShiftAddLLM을 비교해서 평가했다.
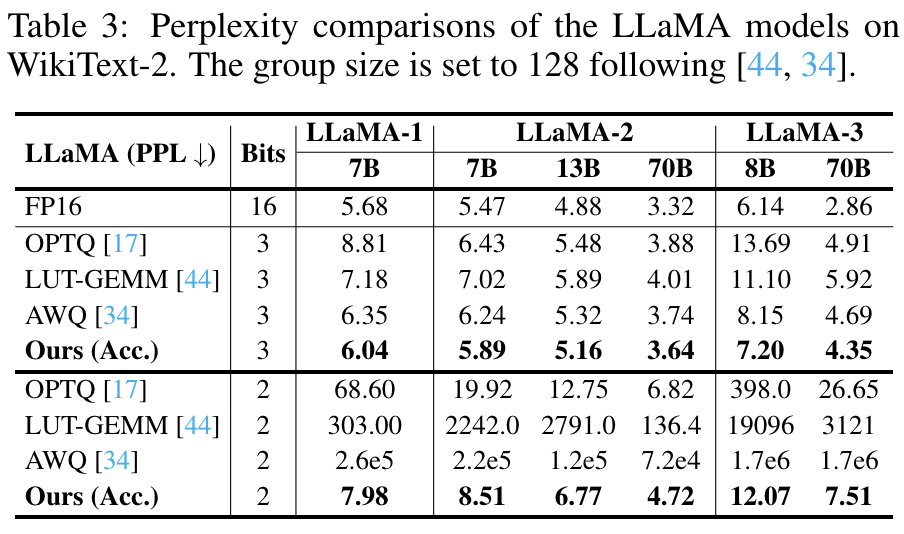
이 표나 위에 그래프에서 보면 알 수 있듯이 perplexity, accuarcy, latency 모두 LLaMA 모델에 비해 ShiftAddLLM이 뛰어나다.
Results on Gemma/Mistral/Bloom Models
오픈 소스 LLM과 MoE 모델 중에서 가장 인기가 많은 모델들과 ShiftAddLLM을 비교해서 평가했다.
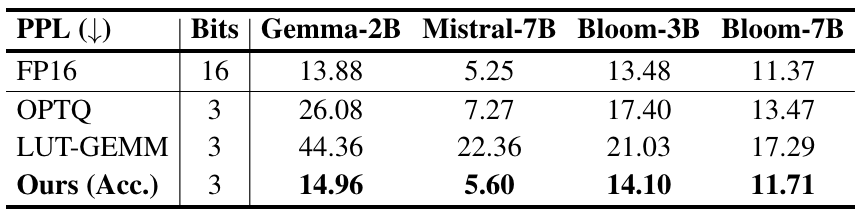
그리고 역시나 perplexity, accuarcy, latency 모두 다른 모델에 비해 ShiftAddLLM이 뛰어나다.
(별로였으면 논문에 안써놨을듯..)
Zero-shot Downstream Tasks
Zero-shot Downstream task에 대한 종합 평가도 시행했다.
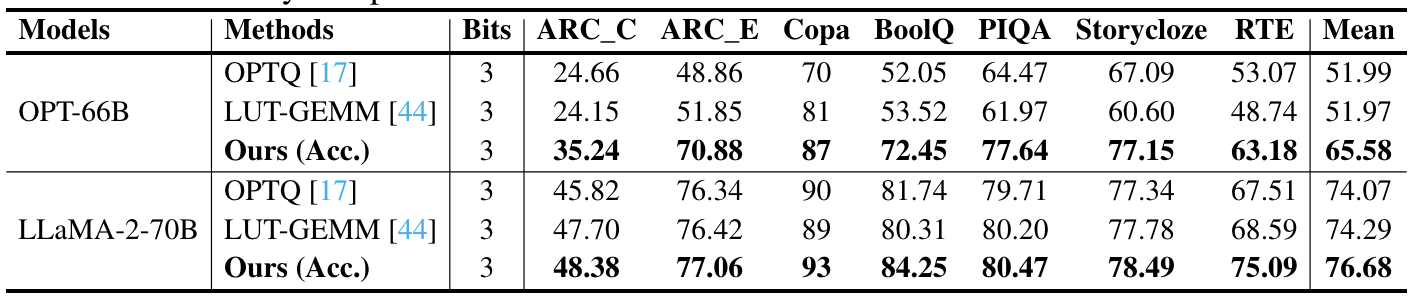
평균적인 accuracy 안에서 SOTA baseline 모델들보다 더 좋은 performance를 보여주고 있다.
- 이 결과는 ShiftAddLLM 모델이 perplexity를 줄여주는 것 뿐만 아니라, downstream task accuracy도 향상시킬 수 있음을 보여줌
GPU Memory Savings
FP16에 대한 memory cost를 확인한 결과, 다른 모델들보다 GPU memory usage도 줄여준다는 것을 확인했다.
Results of Mixed Bit Allocation
Mixed bit allocation strategy를 사용하고 말고를 실험했더니, 사용한 결과가 적은 perplexity로 latency를 줄여준다는 것을 확인했다.

6. Conclusion
- Multiplication-free model
- Reparameterizes weight matrics into binary matrics
- Multi-objective optimization strategy
- Automated bit allocation strategy
