Paper : https://arxiv.org/pdf/2005.11401
0. Abstract
RAG : pre-trained된 parametric memory에 non-parametric memory를 붙혀서 만든 lauguage generation model
- Parametric memory : pre-trained seq2seq model
- Non-parametric memory : index of Wikipedia
RAG formulation
2개의 RAG formulation을 비교함
- sequence 전체를 같은 구절을 조건으로 검색하는 방법
- tocken마다 다른 구절을 조건으로 검색하는 방법
RAG Evaluation
3가지 분야에서 RAG를 평가했고, state-of-the-art parametric-only seq2seq 모델보다 specific, diverse, factual하다고 결론지었음
- Open domain QA tasks
- Outperforming parametric seq2seq model
- Task-specific retrieve-and-extract architectures
Knowledge-intensive task
사람조차 외부지식(ex. 위키피디아 검색 등) 없이 해결하기 어려운 문제
Sparce vector vs. Dense vector
- Sparce vectors : vectors 내 대부분의 값이 0인 것
(ex. one-hot vectors)- Dense vectors : vectors 내 대부분의 값이 0가 아닌 것
(ex. word embedding vectors)
1. Introduction
기존 Pre-trained NLP 모델의 문제점
-
Knowledge memory 확장이나 update가 힘듬
-
직접적으로 insight를 제공해서 모델의 판단을 유도할 수 없음
-
hallucination이 발생할 수 있음
그래서 나온게 Hybrid model!
Hybrid model
parametric memory에 non-parametric memory를 붙혀서 만들어진 모델
= masked language model + retriever
(ex. REALM, ORQA)
- Knowledge 확장이나 update 가능함
- Knowledge를 검사하고 해석할 수 있음
Hybrid model의 문제점
-
Open-domain QA 관련된 task에만 집중함
-
Encoder-Only 구조의 BERT 기반 모델이기 때문에, 특정 corpus안에서 알맞은 부분만 추출하는 방식으로 Open-domain QA task를 수행하게 됨
Open-domain omain Question Answering
엄청나게 많은 정보들을 포함하고 있는 대량의 문서(ex. 위키피디아)들로부터 주어진 질문에 대한 답변을 찾는 문제
- 주어진 질문이 어떤 도메인에 해당되는 질문인지, 어떤 키워드인지에 대한 힌트는 전혀 주어지지 않음
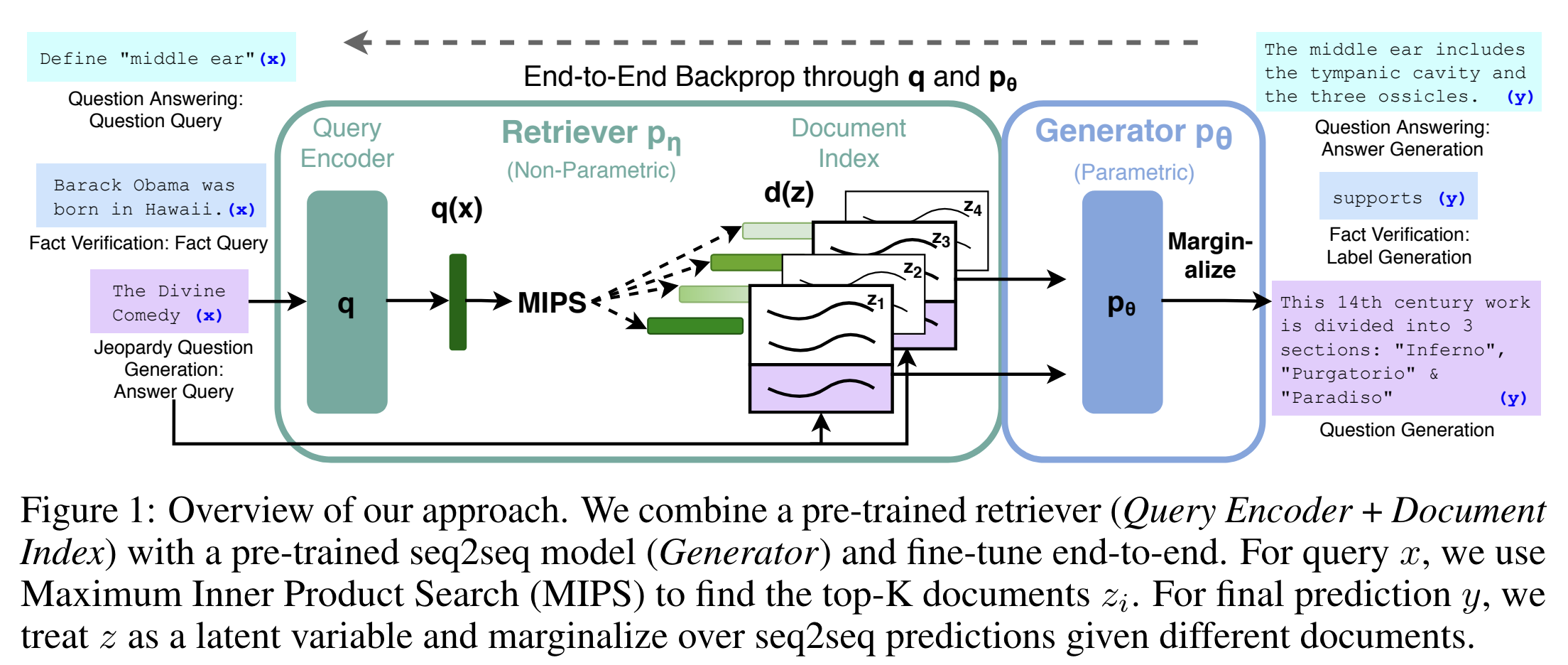
2. Methods
RAG Architecture
BERT 대신 seq2seq 모델(BART) 을 사용해서 QA task를 text-to-text task로 변경시킴
-
Dense Passage Retriever : input에 따른 latent document를 제공함
-
Seq2seq model(BART) : input과 함께 retriever가 제공한 latent document를 바탕으로 output을 생성함
-
per-output basis 또는 per-token basis에 따라 top-K approzimation을 이용해서 상관없는 latent document는 제외시킴
(per-output basis: 같은 document면 모든 token과 관련있다고 가정하는 것)
(per-token basis: 다른 document면 각자 다른 token과 관련있다고 가정하는 것) -
RAG를 이용하면 generator와 retriever 모두 동시에 학습됨
-
Latent Document
문서 집합과 해당 문서에 포함된 용어 간의 관계가 담긴 document
Top-K approzimation
전체 데이터 집합에서 가장 상위 K개의 결과를 효율적으로 찾는 것
- 대용량 데이터에서 가장 관련성 높은 아이템을 빠르게 검색할 때 유용함
Methods
RAG는 input sequence x 를 받아서 external knowledge corpus로부터 관련성이 높은 document z 를 k개 탐색함. 그리고 x와 z 를 additional context로 이용해서 target sequence y 를 생성함

RAG는 2개의 component로 이루어짐
-
Retriever : input query x 를 받아서 document에 대한 distribution을 제공해주는 부분
-
Generator : x 와 z 를 이용해서 y 를 생성하는 부분
그리고 RAG는 retriever와 generator를 동시에 학습함
Models
Retriever와 Generator를 end-to-end로 학습시키기 위해 retrieved document를 latent 변수로 사용해야하는데, output text에 대한 distribution을 제공하기 위해 latent document를 marginalize하는 2가지 방법을 제안하고 있음
(Output을 산출하기 위해 retrieve된 document에 대해 marginalize하게 되는데, 2가지 marginalize 방식을 제안하고 있음)
RAG-Sequence Model
같은 retrieved document를 사용해서 각 target token을 예측하는 모델
(같은 document를 사용해서 전체 sequence를 생성함)
-
retrieved document를 single latent variable로 취급함
- top-k approzimation을 이용한 seq2seq 확률을 얻기위해서 marginalize를 진행함
-
따라서
- retriever를 사용해서 top k documents를 탐색함
- generator를 사용해서 각 document에 대한 output sequence probability를 생성함
- 그다음에 marginalize가 진행됨
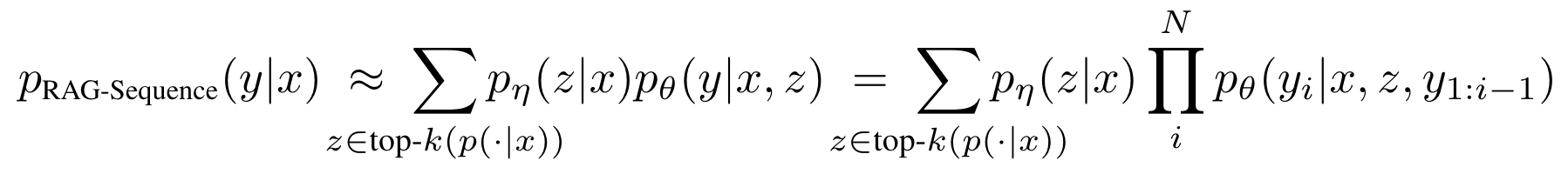
RAG-Token Model
다른 retrieved document를 사용해서 각 target token을 예측하는 모델
(각 target token에 대해 각기 다른 latent document를 사용하고, 그에 따라서 marginalize를 진행함)
-
generator가 답변을 생성할 때, content를 골라서 사용할 수 있음
-
따라서
- retriever를 사용해서 top k document를 탐색함
- generator를 사용해서 각 document에 따른 다음 output token distribution을 생성함
- 그다음에 marginalize가 진행됨
- 그리고 이 과정이 output token에 따라 계속 반복됨
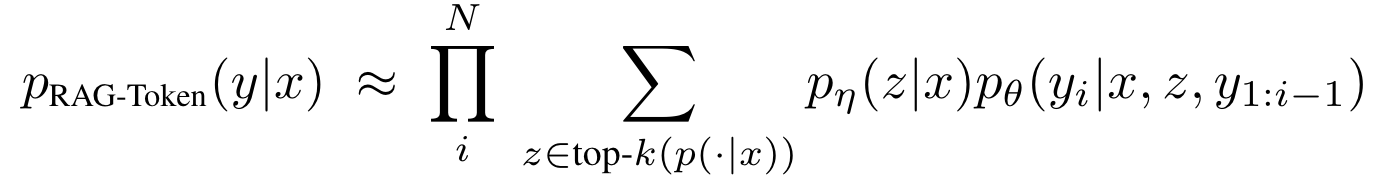
+) target class를 target sequence 길이로 취급하면 RAG를 sequence classification task에도 쓸 수 있음
(이러면 RAG-Sequence와 RAG-Token이 동급으로 취급됨)
Retriever: DPR
Bi-encoder 구조를 가진 탐색기
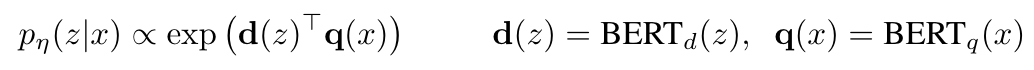
-
d(z) : BERT-BASE 구조로 구성된 document encoder를 통해 산출되는 dense representation of a document
-
q(z) : BERT-BASE 구조로 구성된 query encoder를 통해 산출되는 query representation
-
retriever Pη(z|x) : d(z) 와 q(z) 를 내적 연산한 후, 내적 값이 높은 순서대로 top-k document를 골라 retrieve함
(input x에 대한 document z의 분포)- MIPS 알고리즘을 사용하여 효율적으로 탐색함
Generator: BAR
Encoder-decoder 구조를 가진 생성 모델
- DPR retriever로 retrieve된 document z와 input x를 이용해 output sequence를 생성함
- BART-large 모델을 사용함
Training
DPR기반의 retriever와 BART-large 기반의 generator를 동시에 학습함
- output seqence에 대해 NLL(Negative Log-Likelihood)를 최소화하는 방식으로 학습됨
(generator가 더 좋은 output을 산출할 수 있도록 retriever가 더 나은 document를 가져오게끔 학습됨) - Document encoder는 fix하고, query encoder와 generator만 학습함
Negative Log-Likelihood
모델이 주어진 데이터를 얼마나 잘 설명하는지 측정하는 손실 함수
- 모델이 예측을 잘못할 때 큰 값을 가짐
- 모델이 데이터를 잘 설명할수록 작은 값을 가짐
Decoding
RAG-Token
Token 별로 document에 대한 output distribution을 더해서 최종 output을 산출함
- seq2seq generator와 비슷함
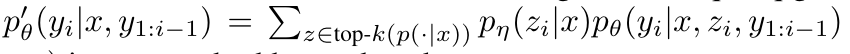
RAG-Sequence
Document 별로 beam search를 진행하면서 fast decoding을 거쳐 최종 output을 산출함
- Fast Decoding : beam search에서 발견되지 않은 값들은 모두 0으로 처리함
- 원래는 additional foward를 통해 추가적으로 model에 넣어서 값을 산출해야하는데, cost가 많이 들기 때문에 발견되지 않은 값들을 싹 다 0으로 처리하는거임
3. Experiments
Open-domain Question Answering
- Answer를 직접 generate하고 이에 대해 NLL loss를 최소화하는 방법으로 학습을 진행했기 때문에, external knowledge 없이 task를 수행할 경우 다른 모델보다 성능이 훨씬 뛰어남
- knowledge intensive task에서 유용함
Jeopardy Question Generation
- Q-BLEU-1 metric 사용함
- Generation factuality와 specificity에 대해 human evaluation 진행함
Q-BLEU-1 metric
기존 BLEU를 matching entity에 더 많은 가중치를 두는 방식으로 수정하여 human judgement에 조금 더 상관관계를 보이는 metric
Fact Verification
- Input으로 받은 "claim"에 대해 wikipedia 정보를 바탕으로 해당 claim이 support 되는지, refuse되는지, 혹은 wikipedia에 충분한 정보가 없는지를 판별함
- SOTA를 달성하진 못했음
4. Results


