[NLP] When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer (NAACL, 2022)
NLP
0. Abstract
multilingual language 모델이 발전하면서 cross-lingual zero-shot transfer 할 수 있는 능력치도 상승함. 하지만 어떤 properties들이 언어간에 transfer 되는지에 대한 연구는 부족함.
본 연구에서는 다양한 실험들을 통해서 linguistic properties들의 효과에 대해서 분석한다. 이를 위해서 4가지 언어를 사용하며 각각의 script, word, order, syntax에 변화를 줘서 실험해본다.
결과적으로 언어간의 순서가 다를 때 sub-word overlap의 부재는 zero-shot transfer 성능에 엄청 큰 영향을 미쳤다. (한국어랑 영어가 예시이겠군) 그리고 언어간의 transfer performance랑 word embedding alignment가 큰 상관관계가 있었음.
앞으로 연구를 할때 implicit한 정보말고 word embedding alignment에 힘줄 것을 제안한다!
Paper: https://aclanthology.org/2022.naacl-main.264/
Code: https://github.com/princeton-nlp/MultilingualAnalysis
1. Introduction
Background
-
Requirements for zero-shot transfer
XLM, m-BERT : MLM 방식으로 multiple language text 학습시킴. cross-lingual zero-shot transfer 성능 good. But 아직 연구자들끼리 zero-shot transfer을 잘하기 위해서 필요한 properties가 어떤건지는 의견이 분분함.
예를들어, 1) sub-word 2) 그건 중요하지 않아! (영어만 source language로 봄) 3) typological similarity (유형이 비슷한 애들) -
Need for systematic analysis
이렇게 합의점이 도달하지 않는 이유는 언어들끼리는 너무나 다양한 특징들을 공유하기 때문임. 그래서 transfer하려고 뭔가 하나의 요소를 isolating한다는 게 무척 어려움.
그래서 어떤 연구는 딱 하나의 특정한 언어적 특징을 바꾼 synthetic languages를 만들어가지고 비교 실험을 하기도 함. ex) "invariant to the script" == 어떤 언어로 쓰였냐 상관없이 언어의 속성들을 고려하여 다양한 언어에 공통적으로 적용되는 속성들
그렇지만, 이러한 연구들은 영어만을 source language로 두고 실험을 했고, 실험 scale도 작다. 그래서 그 실험의 결과를 generalization하기엔 한계가 있음.
Approach
두개의 언어 pair를 만들어서 cross-lingual transfer 실험을 하는데, 하나는 자연어이고 하나는 대응할 수 있는 다른 언어로 만든다.
1. 언어: 실험에 사용하는 언어는 English, French, Arabic, Hindi (한국어는 왜 없나!)
2. 형식: variants : structural properties 다양하게 둔다. 1) inverting, permuting word order, altering scripts, varying syntax.
총 16개 pairs가 생김.
3. 4가지 downstreantask : natural language inference (NLI), named entity recognition (NER), part-of-speech tagging (POS), question-answering (QA)
Findings
- 이전 연구의 결과와는 다르게, 언어간의 word order가 다를 때 sub-word overlap의 부재는 transfer 성능을 크게 떨어트림.
- 서로 다른 task 간에 zero-shot transfer 할 때는 token embedding alignment 영향이 큼.
- 다른 언어여도 같은 출처에서 나온 corpora 사용해서 학습을 하면, 다른 곳에서 가져오는 것보다 더 도움이 됌.
Contribution
- 우리는 zero-shot transfer에서 token embedding alignment가 큰 영향이 있다는 거 quantitatively하게 증명한 첫 연구임.
- 최신 multilingual pre-training methods들은 source와 target언어 간의 token embedding alignment 하는 능력 떨어짐.
- 우리는 explicityl 한 alignmnet를 더 improve할 것을 call for 한다!
2. Related work
Multilingual pre-training for Transformers
- M-BERT : mlm방식으로 104개 언어 학습
- XLM : mlm 방식으로 언어들 pair를 이용해서 학습을 시킨 translation language model. 이 방법은 representation들이 alignment하는 데 도움.
- 둘다 cross-lingual zero-shot performance good
Analysis of cross-lingual transfer
- 우리가 비교군으로 삼고자 택한 방식들에 대해 언급한 이전 연구:
- no share : 공유되는 vocab 없는 언어들끼리도 transfer 가능함을 보여줌.
- share: transfer 할 때 sub-word overlap, shared parameters의 중요성, typoligically similar한 언어들 (NER, POS할때)
- no 효과: change the syntax order
Transfer between real and synthectic Languages
- 기존 연구의 한계점
- 영어로 된 script를 가지고 spanish로 바꿔서 synthectic language를 만들었음. 이 때 overlap되는 sub-word가 없는대도 효과가 있었음. 하지만, english만 source 언어로 사용했고, task도 두개 task만 가지고 실험함. 실험적으로 한계가 있었음.
- 영어 script를 가지고, script, word order, model delimiter바꿔서 비교한 실험이 있는데, 사용한 corpus 크기가 작음. 그리고 embedding similarity만 비교하고 zero-shot performance는 측정하지 않음.
- 마지막 연구는 good zero-shot transfer 할 수 있는 properties연구했는데 source 언어가 영어만 있고, token embedding alignment analysis 실시하지 않음. 근데 우리 연구에선 이게 중요하다는 걸 확인함.
3. Approach
3.1 Background
Bilingual pre-training
두 개의 언어를 가지고 학습을 진행하는데, 한 가지 언어만 이용해서 loss를 구하고, 최종적으로 그 두 loss를 합해서 shared byte pair encoding tokenizer를 학습시킨다.
batch 안에는 두 언어 다 포함되어 있음.
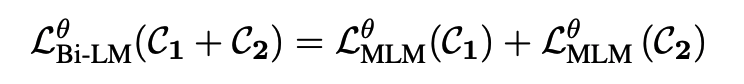
Zero-shot transfer evaluation
source 언어로만 학습을 시키고, target언어로 test시킨다. target언어는 train때 절대 포함되지 않는다!
3.2 Generating language variants with systematic transformations
언어 특징별로 어떤 효과가 있는지 보기 위해서 synthectic language를 만들어봅니다!!
original corpora를 가지고 sentence별로 transformation을 적용해서 만들게 됩니다!
그래서 derived corpora랑 original corpora는 사이즈가 똑같음.
- notation

Type of transformations

- Inversion (T_inv) : 문장 내 token 순서 바꾸기. 맨 첫번째 토큰과 맨 마지막 토큰 순서 바꾸기
- Permutation (T_perm): uniformly at random하게 문장 순서 바꾸기, 1/n! 확률
- Transliteration (T_trans): 모든 token을 다른 special token으로 변경. 오리지널 vocab과 1:1 매칭되는 새로운 vocab이 생기게 된다.
- Syntax (T_syn): 명사와 동사의 순서를 조정해서, 다른 언어의 syntax 구조로 변경.
- ex. 만약 한국말을 영어의 syntax로 바꾼다면?
- 나는 밥을 먹었다. => 나는 먹었다 밥을 (I have dinner.)
- composed transformations: 연속적으로 서로 다른 transformations 적용.
실제 언어들 사이에서는 한 개 이상의 속성이 공유되는 경우가 많은데, 우리의 setting은 그러한 특성들을 isolating해서 good transfer을 측정하기에 좋은 접근법이라고 생각한다!
Transformations for downstream tasks
-
Corpus 필요한 경우: 훈련때 사용한 거랑 똑같은 derived language에서 얻음.
-
Text classification (NLI) : 모든 dataset instance에 대해서 문장마다 transformation을 적용한다.
- sentiment analysis: (sent1, label1)
- NLI : (sent1, sent2, label1)

-
Token classification (NER, POS): 보통 각 토큰마다 라벨링 되어있음. 그럼 token의 순서를 바꾸는 transformation이 적용됐다면, 그 순서에 맞게 token에 할당된 label의 순서도 바꿔준다.

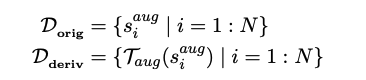
3.3 Model Training and Evaluation
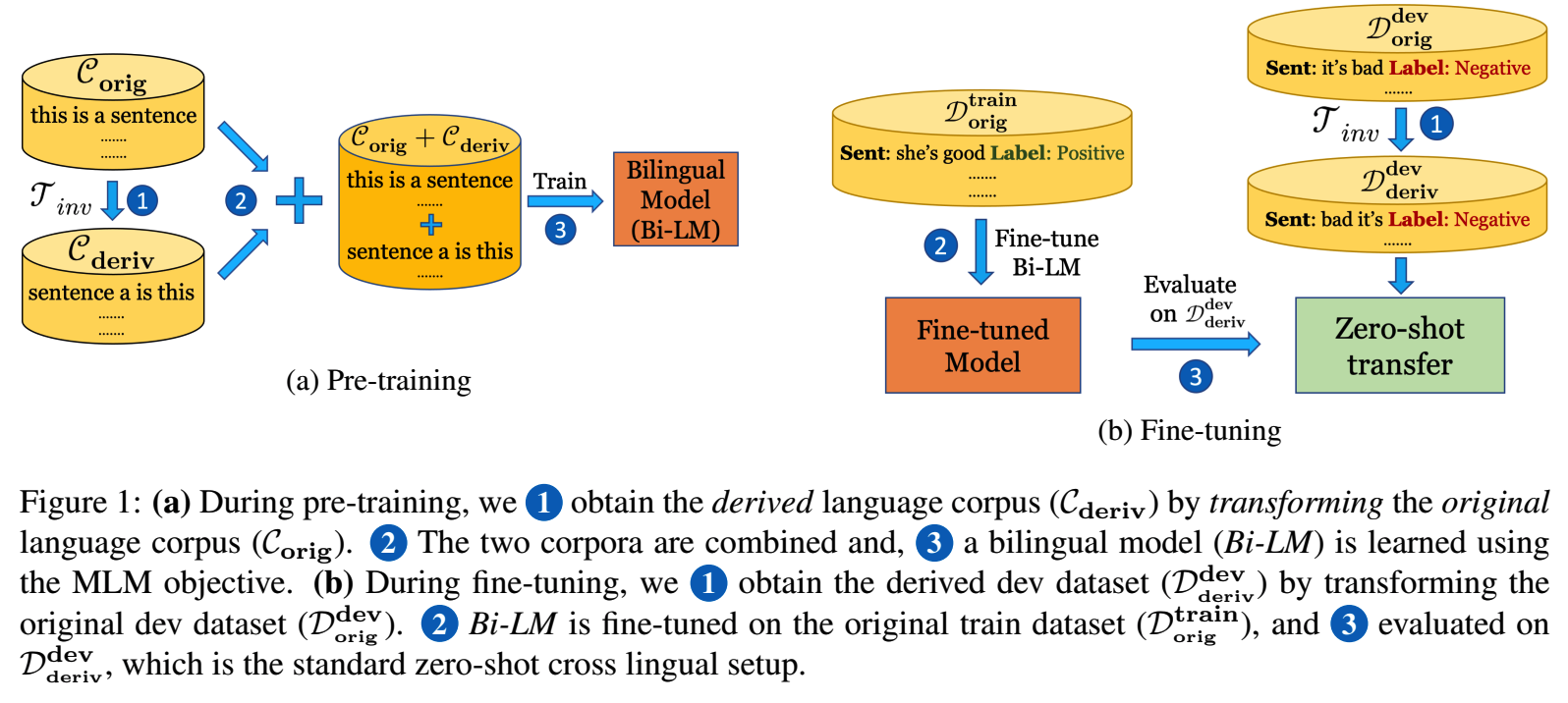
Pre-training
- Bilingual Model: 오리지널과, derived 가지고 pretrainig
- Monolingual Model: derived는 없고 오리지널로만 pretraining
Evaluation
- Bilingual zero-shot transfer (BZ): how well a bilingual model fine-tuned on orig zeroshot transfers to the other language.
- Bilingual supervised synthetic (BS): finetuning의 train, test언어가 동일하고, 둘다 derived된 언어임.
- Monolingual zero-shot transfer (MZ): baseline임. derived language로는 Pretrained되지 않았음. eval할때만 사용된다.
- 예상 result: BS>BZ>MZ
- 아래 수식 다 (-)나옴. (왜왜왜 어째서 bs가 필요한거지 그냥 바로 bz, mz비교하면 안되는거임..?)
- (1) == (2) 면 poor zero-shot transfer: derived 있으나 없으나 성능 비슷한거니까.
- (1)번 == 0 이고, (1) > (2)가 나오면 그 setting은 good zero shot transfer임.
- 왜냐하면 supervised랑 비슷한 성능이 zeroshot setting에서 나온거라면, 그 때 사용한 T 방식은 원어랑 거의 같다, 비슷한 걸 공유한다고 할 수 있는 거니까! (아 이걸 위해서 bs가 필요한건가보다..)
- 그리고 (1)> (2)여야 derived가 효과가 있다고 확인할 수 있으니까!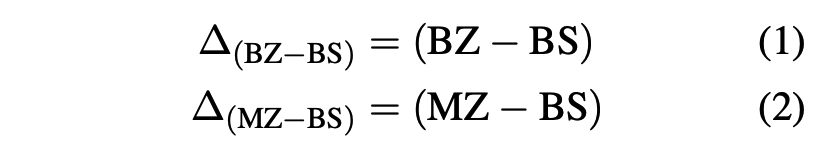
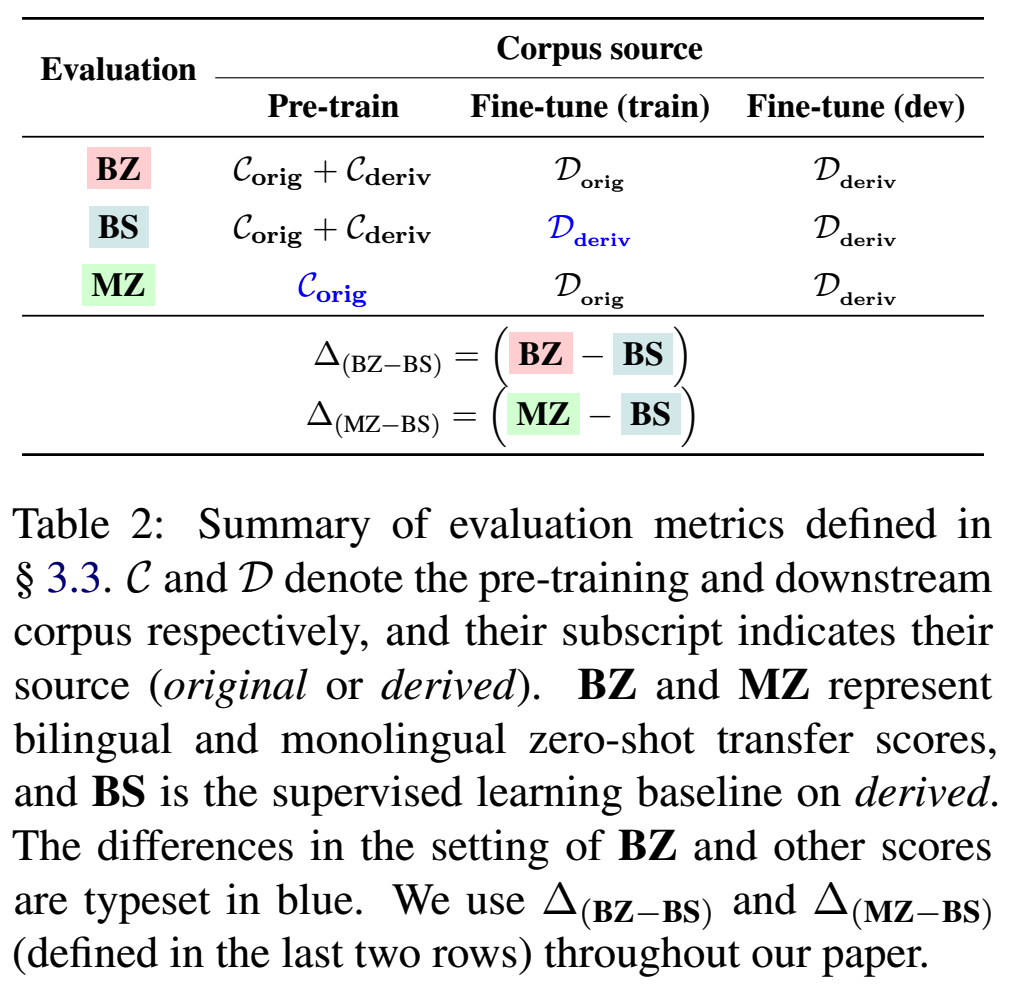
- 아래 수식 다 (-)나옴. (왜왜왜 어째서 bs가 필요한거지 그냥 바로 bz, mz비교하면 안되는거임..?)
3.4 Experimental Setup
Languages
- 총 4개 언어: English, French, Hindi, Arabic -> XTREME benchmark
- 각 언어마다 4가지 방식의 transformation적용해서 총 16개 origin-derived pairs가 만들어진다.
- syntax transformation의 경우: FR, HI, AR은 EN의 syntax로 바꾸고, EN은 FR의 syntax로 바꿨다.
근데!!! 각 언어별로 사용하는 인종? 나라들을 보니까 다 비슷하구만....
English: indo-european, germanic
French: indo-european, romance
Hindi : Indo-european, Indo-Iranian
Arabic (Afro-Asiatic, semitic
언어별 어순 조사:https://namu.wiki/w/%EC%96%B4%EC%88%9C
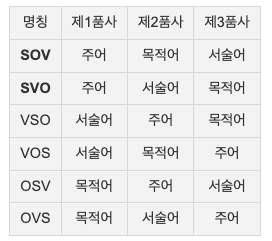
syntax는 통사론 문법이랑 비슷한 맥락인데, 이거를 제일 잘 알수 있는게 어순임.- SVO : 중국어, 영어, 러시아어, 아랍어 (방언), 아프리칸스어, 프랑스어
- SOV: 한국어, 힌디어, 일본어, 우즈벡어,
- VSO: 아랍어 (표준어), 타갈로그 (필리핀)
—
명사 형용사 어순 (구) - AN: 영어, 일본어, 중국어, 한국어, 힌디어, 등
- NA: 아랍어, 프랑스어, 스페인어, 히브리어 등
왜 저런 기준으로 바꿨을까..!! 영어가 숫자가 많아서? 다 영어 어순 적용한것일까..? 기준이 뭐야! 영어랑 프랑스어는 어순도 비슷하구만!
Datasets
- pretrainig: 500MB subset of wikipedia (~100M tokens) for each language
- 4개 downstream task
Implementation Details
- RoBERTa 사용
- 각 모델 500k step 훈련, 128 batch, 1e-4
- original language vocab : 40000
4. Results
4.1 Sub-word overlap is not strictly necessary for strong zero-shot transfer
-
Setting
Transformation 방식 비교 -
Result
This result indicates that zero-shot transfer is possible even when languages with different scripts have similar word orders (in line with K et al. (2020)). However, it is unrealistic for natural languages to differ only in their script and not other properties (e.g., word order).
다른 것보다 단어들 순서가 제일 중요하다는 거구먼!!!!!!
(영어-프랑스어? or.. 영어-중국어)
다른 연구를 보니 거기도 비슷한 결과 (근데 거긴 알파벳 사용한 애들끼리 더 성능ㅇ ㅣ높든디..)
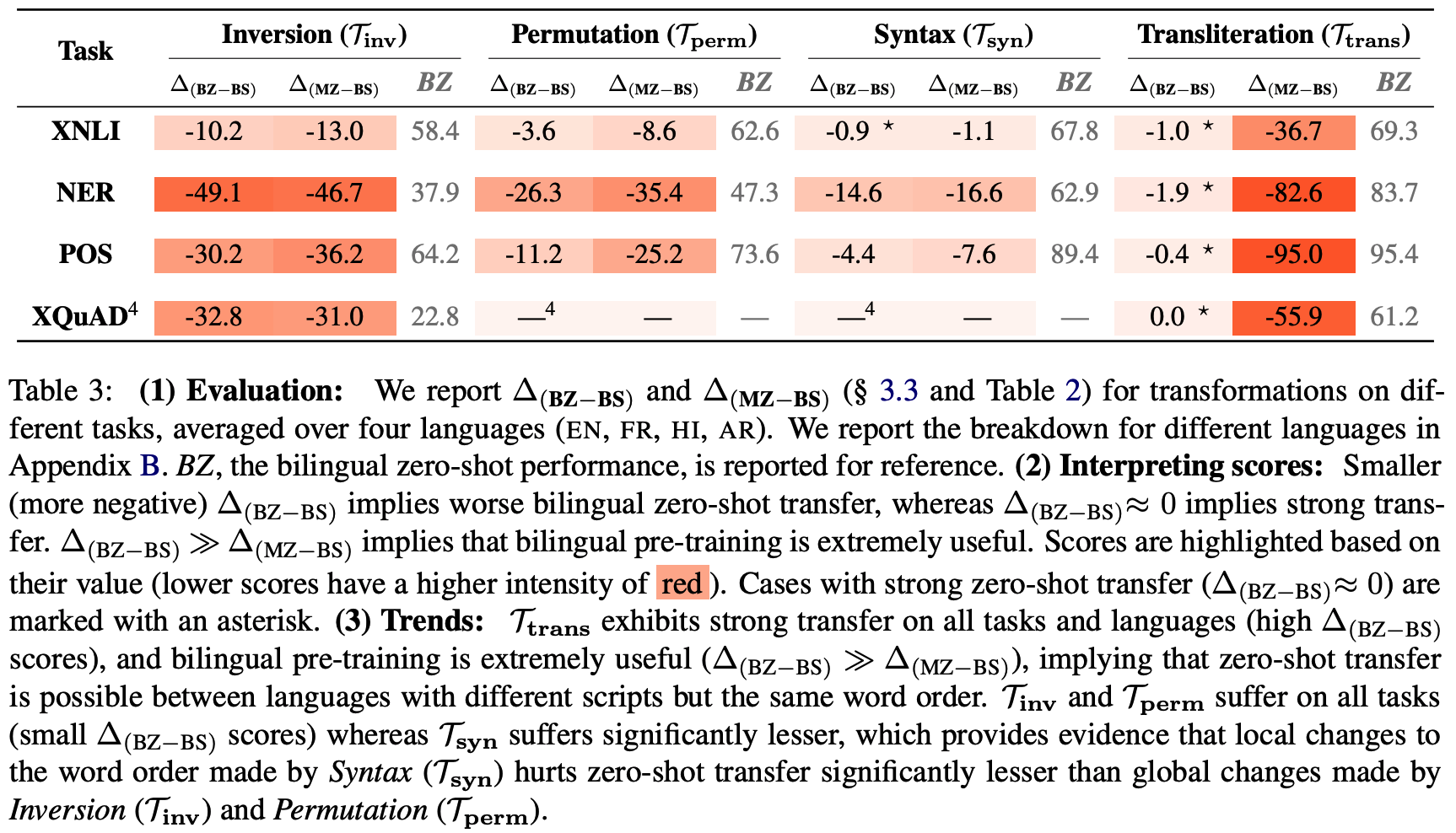
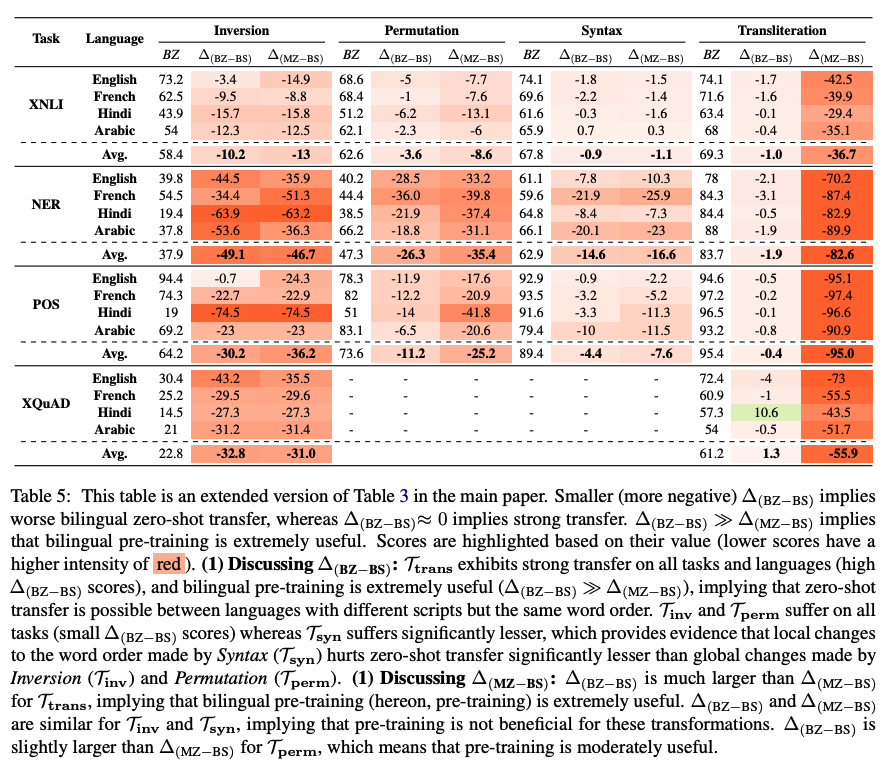
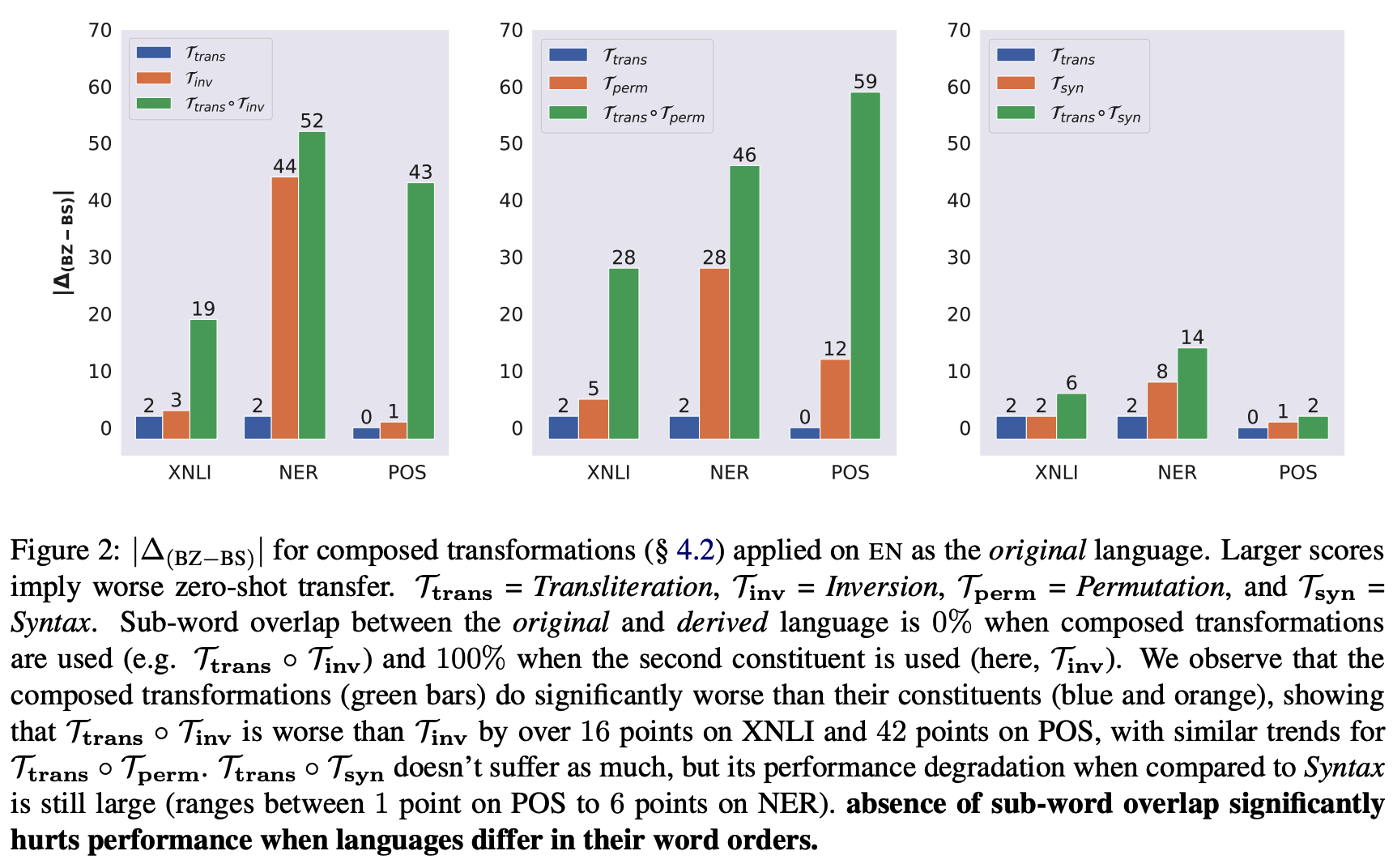
4.2 Absence of sub-word overlap significantly hurts zero-shot performance when languages differ in their word-orders
- Setting
- 순서도 다르고, sub-word ovelap도 0%로 만들어버린다!
- (a) trans - inv
- (b) trans - perm
- (c) trans - syn
- 결과
- 앞에선 subword가 그렇게 중요하지 않았음. 오히려 순서가 더 중요했지.
- 그렇다면 trans+순서바뀐거로 실험을 했을때 순서바뀐거 모델이랑 성능이 비슷해야하는데, 결과표를 보면 어어어엄청 차이가 나버림!!!!!!!!
- 이때는 만약에 언어간에 word order가 많이 다를 때는, overlap되는 sub word도 없으면 성능이 엄청 떨어질 수 있다는 것! (한국어-영어가 대표적이겄네!)
=> 그렇다면 영어를 source로 실험했을 때 중국어보다는 한국어 test할 때 성능이 더 낮을 가능성이 높겠다.
=> 여기서 syn의 성능이 크게 떨어지지 않은 것을 보아라!!! 결국 쟤네 syntax다 비슷하단 얘기 아니겠느냐!!!!! 오 앞에서의 생겼던 의문점이 해결됐다!!!
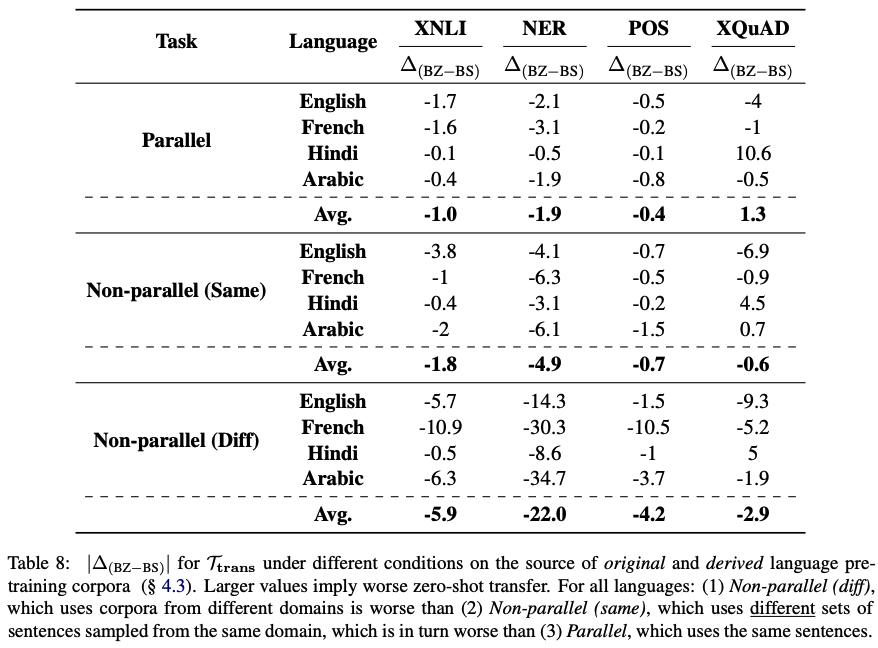
4.3 Data from the same domain boosts bilingual performance
-
Setting
- (1) parallel : 오리지널 셋이랑 one-to-one matching되는 derived C 데이터셋으로 bilingual model 학습
- (2) non-parallel (same): 같은 위키피디아 데이터셋은 쓰지만, original이랑 다른 split의 데이터셋을 가지고 derived만든 거 사용해서 학습
- (3) non-parallel (diff): original셋이랑, 아예 다른 web text (common crawl data)를 사용해서 만든 derived 셋을 이용해서 학습
- derived set은 transliteration transformation 사용해서 만들었음
-
결과
- parallel > non-parallel (same) > non-parallel (diff)
- 1:1 매칭되는 데이터 쓰면 최고이겠지만, 현실적으로 어려우니까 최소한 같은 domain에서 얻은 데이터를 쓰면 성능 향상 기대할 수 있다!
하지만! 여기서 얘네가 말하지 않은 것은..! parallel-nonparallel(diff)랑 same-diff는 비교해놓고, parallel-same은 비교 안함!!!! 보면 XNLI french, XQuAD에서 french, hindi는 성능이 오히려 좋아짐. 이건... 추론이런 느낌이라 더 다양한거 봐서 더 좋았던 걸까..?!!?!?!

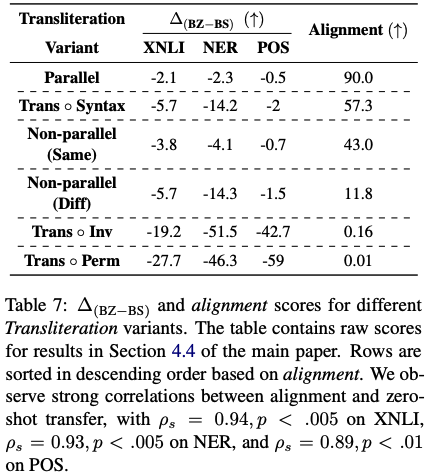
4.4 Zero-shot performance is strongly correlated with embedding alignment
- Setting
앞에서 sub-word가 겹치는 게 없으면 성능이 안좋아지는 걸 확인함. (4.2, 4.3). 이걸 더 분석해보기 위해서 bilingual model로 학습된 static word embedding을 살펴봄 - Result
- pretrained 데이터 애들의 alignment가 높으면 transfer score도 높았다!
- 다른 domain학습한 애들이라도 train이랑 test의 word-order가 똑같으니까!! 성능이 높구나!
왜 그런데... non-parallel은 아예 alignment가 없는거 아님..????? 왜...? trans_inv보다 더 없는거자나.... 같은 단어가 많이 쓰임...? 쟤네는 word-order가 안바뀐 애들이구나....?
왜 어째서 syn은 저렇게 alignment가 높은데, perm, inv는 저렇게 낮은건가... 똑같은애들아닌가.../????///// 오히려.. non-parallel은 아예 matching 되는 애 자체가 없어야하는거 아냐..?
유레카! 이건 앞에 4.2 결과랑 같이 봐야 아는 것임. syntax자체가 언어별로 비슷한 순서 애들 사용했기 때문에 크게 alignment가 변하지 않는 것이여! 그래서 다른 애들보다 alignment가 엄청 높은 것을 확인할 수 있음.!!!!!
이제 이게 거의 비슷하다는 것은 알겠고!!!!!
그럼 parallel이 perm 애들보다 alignment가 높은 이유는..? 아예 다른 문장을 사용했지만 언어 순서가 변하지 않기 때문에 겹치는 경우가 많다는 거구만!

4.5 Connections to results on natural language pairs (기존 연구들과 비교)
Effect of sub-word overlap
- 우리 연구에서 word 순서가 다를 때 sub-word는 성능 영향 크게 미친다는 것 확인함
=> 기존 연구에서 english-bulgarian (different script but same word order - svo)이 english-japanese (different script and word order - sov) 보다 zeroshot 성능이 더 좋음.
Effect of token embedding alignment
- 우리 연구에서 word embedding alignment가 굉장히 중요하다고 밝힘. 이는 임베딩 alignment를 높일 수 있는 auxiliary objectives를 적용해서 multilingual pre-training성능을 높이려는 연구들한테 도움이 될 수 있을 것으로 보인다.
=> DICT-MLM, RelatedLM: aux task로 cross-lingual synonyms 예측하는 task를 사용함. 이렇게 하면 indirectly하게 word-embedding alignment 향상시킬 수 있음.
=> Hu et al. (2021) : word embedding aligmnment에 집중했더니 large모델과 비슷한 성능을 보임.
=> Cao et al(2019) : 번역된 문장 pair를 가지고 word-level alignment information 이용해가지고 contextual word embeddign alignment높임.
=> 우리는 얘네가 옳은 방향으로 가고 있따고 생각
5. Conclusion
- 어떤 특성이 good zero-shot transfer 하게 해줄지 탐색하기 위해서 다양한 transformation 기법 적용하여 실험해봄
- findings
- 어순이 다를 경우 sub-word가 중요한 영향을 미친다.
- word embedding alignment가 높을 수록 좋은 영향
Review
- 아쉬운 점
- syntax를 비슷한 어순의 것으로 변경해서 별로 효과가 없어보임. 이것에 대해서 자세히 말해줬어야한다고 생각.
- 평균을 이용해서 trend와 다른 결과에 대해선 discussion하지 않음.
- 여기서 말한 2번째 findings가 첫번째의 4.1결과와 똑같은 얘기가 아닌지.... 일단 어순이 제일 중요하고, 그 다음 sub-word ovelap이 중요하단 거잖앙...??! token embedding 보니까 어순 같은 순서랑 똑같은거 같더만 그냥 sub-word로 보는 거 같은댐... 아 .. synonym도 들어감..?!
