1 Introduction & Summary
- Challenge
- seq2seq 모델인 mT5는 cross-lingual task에서 괄목할만한 성능 보여줌
- MT5가 이미 성능이 좋은데, 어떻게 하면 tranlation data 사용해서 MT5를 뛰어넘을 수 있을까?
- Approach
- mT5 Vs. mT6
- pre-training task : 1) Machine translation, 2) translation pair span corruption, 3) translation span corruption
- training objective: partially non-autoregressive (PNAT) decoding
: target sequence를 몇개의 그룹으로 나눈 후에, 예측은 source token과 target token이 같은 그룹에 있는 경우로 한정 시킴
- mT5 Vs. mT6
- Experiments
- task: multilingual understanding, generation task, cross-lingual task
- result: mT6 > mT5
- Contribution
- 1) text-to-text transformer pre-training위한 3개의 cross-lingual tasks
- 2) 새로운 objective function 제안 == a partially non-autoregressive objective
- 3) extensive evaluation results of various pre-trainig tasks and training objectives
paper: https://aclanthology.org/2021.emnlp-main.125/
code: https://github.com/microsoft/unilm/tree/master/deltalm
2 Background on T5 & mT5
- Multilingual pretrained language model
- training: multilingual unlabeled text를 가지고 unsupervised LM task 수행
- e.g. mBERT :우리가 아는 BERT랑 똑같은데, 그 중에서 multilingual 데이터셋으로 훈련한 모델 (https://huggingface.co/bert-base-multilingual-cased)
- Cross-lingual task
- taining: translation data 사용해서 학습
- e.g MT5 (the multilingual text-to-text transfer Transformer, 2020) - T5의 text-to-text problem 방식의 장점을 활용하여 구축되었으며, cross-lingual understanding benchmark에서 sota 달성.
-
T5: Exploring the Limits of
Transfer Learning with a UnifiedText-to-TextTransformer (Google, 2020) *(T가 5개!)-
Goal: Task별로 Fine-tuninig하지 않고 NLU, NLG 구분 없어 하나의 Generation 모델 통합하는 Framework 제안
-
Method: 이것 저것 다 해보고 최적의 기법을 찾음 (주요 keyword!)
-
Text-to-Text Framework:
모든 NLP 문제를 text-to-text 방식으로 푼다면 동일한 model, objective, training procedure, decoding preocess를 적용할 수 있다! So, 데이터 셋을 다 pair로 만들 것을 제안!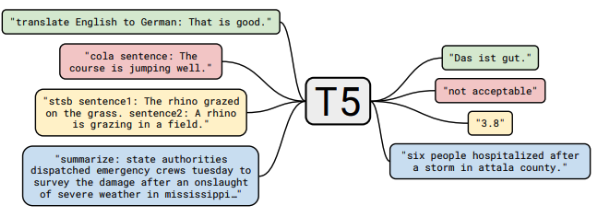
-
Original Encoder-Decoder Transformer:
여러개 해봤더니 Encoder-Decoder가 최고더라!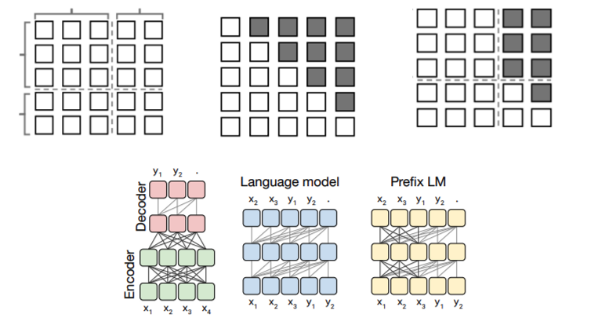
-
Denoising Corrupted Span:
noise를 추가하고 이를 복구시키는 pre-train 시키는 방식으로 objective function 설정
15% 비율로 noisingSpan corruption task (SC) : unsupervised masked LM task
1) g_i : 오리지널 text에서 랜덤하게 span을 선택하고 [mask] 씌운다.
2) g_o : g_i에서 [mask]된 span의 오리지널 token끼리 결합하는데, 각 토큰 앞에 해당 토큰의 특정 [mask]를 함께 붙여서 decode 되어야할 span을 표현한다.
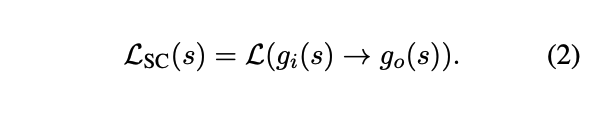
-
C4 Dataset: Colossal Clean Crawled Corpus -
Multi-task pre-training -
Scaling Model Size:
Pre-train시의 Train Loss를 줄이는 것보다는 데이터셋의 크기 자체를 늘리는게 유리
-
-
ref: https://tskim-dev.tistory.com/2
opensource: https://huggingface.co/t5-small
- mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer (Google, 2021)
- Goal: T5 모델을 101가지 언어로 구성된 mC4 데이터셋으로 학습하여 multilingual variant 한 모델 제안
- Method: T5랑 동일
- Training:
- text-to-text process: input의 source text에 조건화된 상태에서 target text를 예측
- e.g. 텍스트 분류에서 모델은 class index 대신 label text를 예측 => 이렇게 되면 모든 task에서 똑같은 objective를 사용해서 fine-tuning할 수 있다. (T5에서도 언급한 내용)
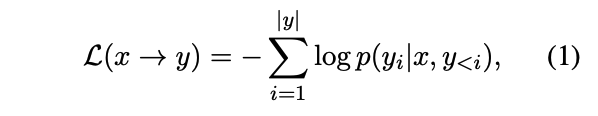
- x: input sequence/ y: output sequence
- Pre-training task : Span corruption task (SC) : unsupervised masked LM task
opensource (한국어): https://huggingface.co/AimB/mT5-en-kr-natural
3 Methods
- 1) text-to-text transformer pre-training위한 3개의 cross-lingual tasks
- 2) 새로운 objective function,a partially non-autoregressive objective
- 3) detailed fine-tuning 과정 for Benchmark 데이터셋
3.1 Cross-lingual Pre-training Tasks with Translation Pairs
- 똑같은 translation pair를 가지고 서로 다른 input-output 구축

3.1.1 Machine Translation (MT)
- Goal: translating a sentecne from the source language into a target language
- sequence-to-sequence learning을 위한 text-to-text pre-training task임.
- Formation:
- (e,f) == (sentence, 번역 setence) == (input, output)
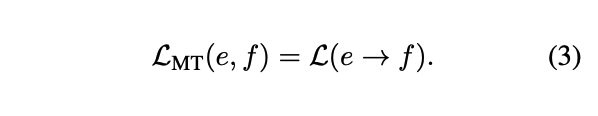
- (e,f) == (sentence, 번역 setence) == (input, output)
3.1.2 Translation Pair Span Corruption (TPSC)
- Goal: to predict the masked spans from a translation pair instead of a monolingual sentence (source, target language의 모든 span 결합해서 target 만든다)
- inspired by the translation masked language modeling task => 이건 뭘까!
- Formation:
- e,f를 하나의 sentence로 합쳐서 span corruption함
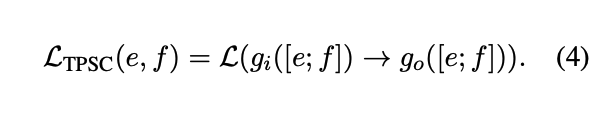
- e,f를 하나의 sentence로 합쳐서 span corruption함
3.1.3 Translation Span Corruption (TSC)
- Goal: only mask and predict the spans in one language.
- TPSC 방식은 source, target span을 모두 결합해버리기 때문에 unnatural한 문장이 생겨버릴 수 있음.
- Foramtion
- e에서만 span corruption을 시행한다.
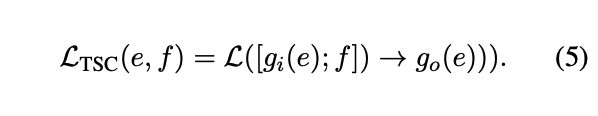
- e에서만 span corruption을 시행한다.
3.2 Pre-trainig Objective: Partially Non-autoregressive Decoding
- MT5의 한계점
- 예측해야할 token이 마지막에 갈 수록 사용할 수 있는 target sequence 정보가 많아진다 (전 step에서 output으로 나온 값을 그 다음 step의 input으로 사용할 수 있으니까). 그렇게 되면 encoder가 학습할 수 있는 양이 줄어들게 된다.
- Approach
- encoding할 땐 많은 정보를 사용하면서, autoregressive decoding의 ability는 보존하자!
- Partially non-autoregressive decoding (PNAT)
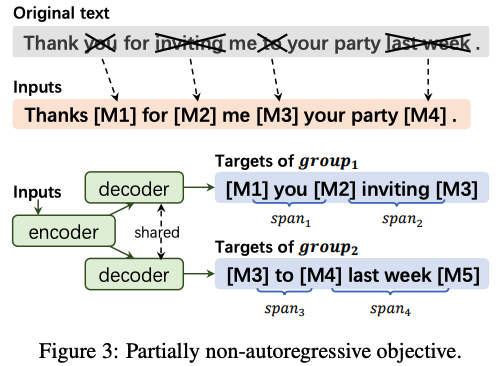
- 1) m개의 span으로 span corruption된 input, output sequence가 있을 때, output sequence (=target sequence)를 n개로 쪼개버린다.
- 2) 모델은 m/n 개의 span을 나눠가진 그룹 각각을 decode하도록 훈련시킨다.
- Formulation
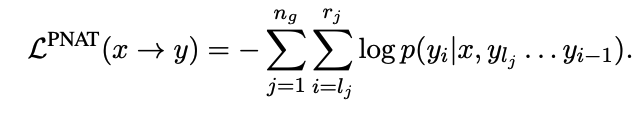
- 일반 text-to-text loss L(x->y)는 그럼 L^PNAT에서 n이 1인 경우라고 할 수 있다!
- Overall pre-training objective
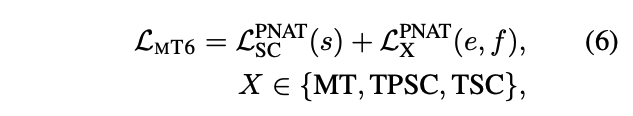
3.3 Cross-lingual Fine-tuning
- Language generation task와는 달리 language understading task는 text-to-text format으로 바꿔야한다.
- Language understanding task
- Classification
- Question Answering
- Named Entity Recognition
4 Experiments
4.1 Setup
- Data
- natural sentences from CCNet in 94 languages for monolingual text-to-text tasks
- parallel corpora of 14 English-centric language pairs for cross-lingual text-to-text tasks

- natural sentences from CCNet in 94 languages for monolingual text-to-text tasks
4.2 Results
4.2.1 XTREME Cross-lingual Understanding
- XTREME : cross-lingual understading을 위한 benchmark
- NER, MLQA, XQuAD, TyDiQA-GoldP, XNLI, PAWS-X
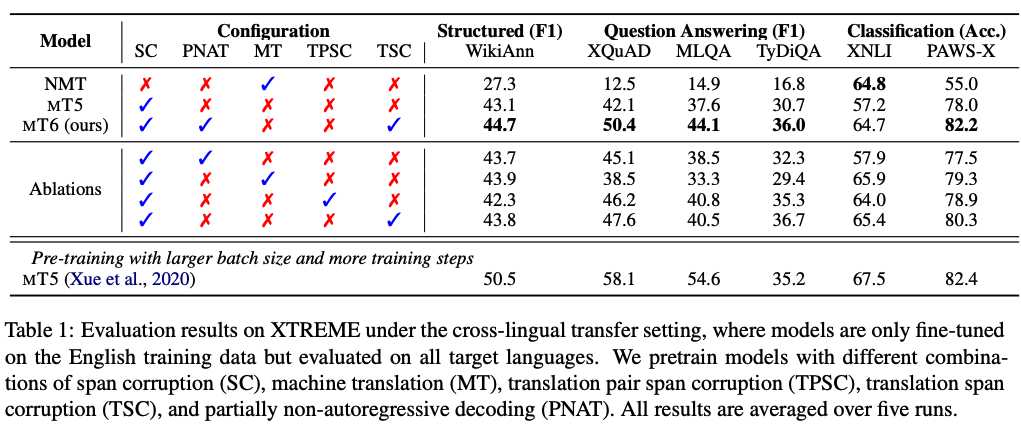
- setting: model은 무조건 영어 데이터로만 fine-tuning 하고, eval은 모든 language로 한다! 모든 언어에 대해서 tuning 하는 거 아님!
- results: MT6 achieves the best performance on XTREME
4.2.2 Comparison of Pre-training Tasks
- pretraining 방식 간에 성능 비교
- setting: 같은 데이터셋으로 task별로 pretrain 시켰음.
- result: SC+TSC with PNAT achieves the best overall performance on the XTREME benchmark + monolingual 성능보다 높음.
- conclusion :
- translation data to text-to-text pre-training는 cross-lingual understanding task 성능 향상하는데 도움이 된다.
- PNAT이 다른 SC나 SC+TSC보다 성능이 좋으며, monolingual뿐만 아니라 cross-lingual tasks에도 효율적!
4.3 Abstractive Summarization
- Multilingual Summarization
- task goal: input이 들어오면 원 의미는 유지하면서 요약을 하는 것.
- input: first sentence/ output: headline
- result: MT6 consistently outperforms MT5 on all the three target languages. 더 적은 데이터셋으로 훈련했을 때 MT5보다 성능 좋음.
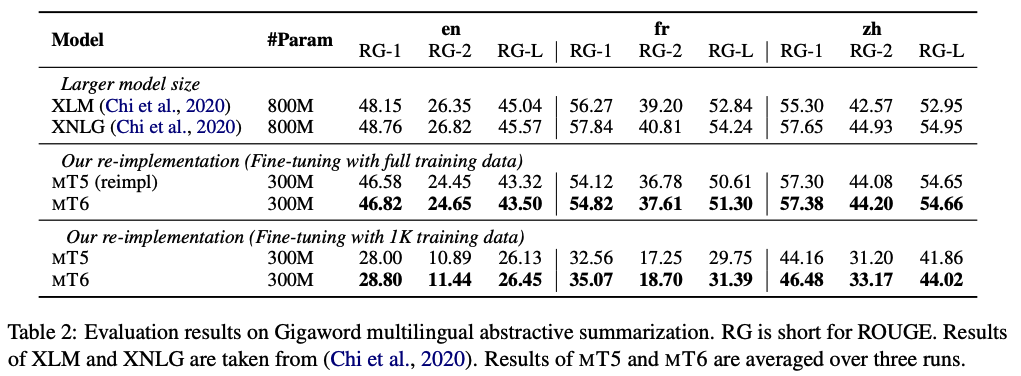
- Cross-Lingual Summarization
- task goal: 훈련 데이터와는 다른 언어의 글을 보고 summary 제공
- result: MT6 outperforms MT5 on the test sets of four language pairs.
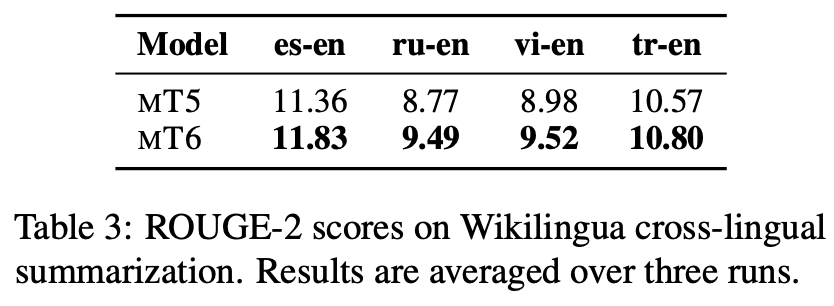
4.4 Cross-lingual Transfer Gap
- Definition: English test set 성능과 non-English test set 성능 평균간의 차이
- Goal: English에서 target 언어로 transfer할 때 얼마나 knowledge가 보존이 되는지 보기 위함 (how much the end-task knowledge preserves when transferring from English to the other tar- get languages.)
- gap score 낮을 수록 cross-lingual transferability 좋은 것!
- Result: MT6 consistently reduces the transfer gap across all the five tasks, demonstrating that our model is more effective for cross-lingual transfer than MT5
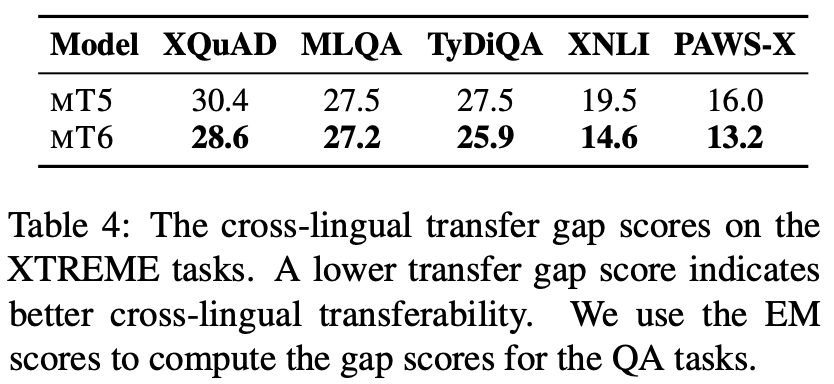
4.5 Cross-lingual Representations
- task: cross-lingual sentence retrieval
- result:
- our MT6 model produces better-aligned text representations
- our pre-training objective is more effective for training the encoder than MT5
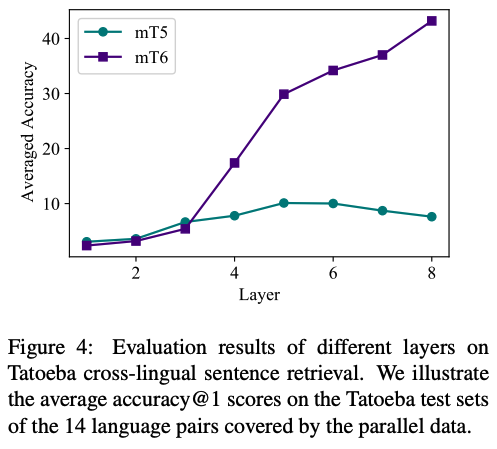
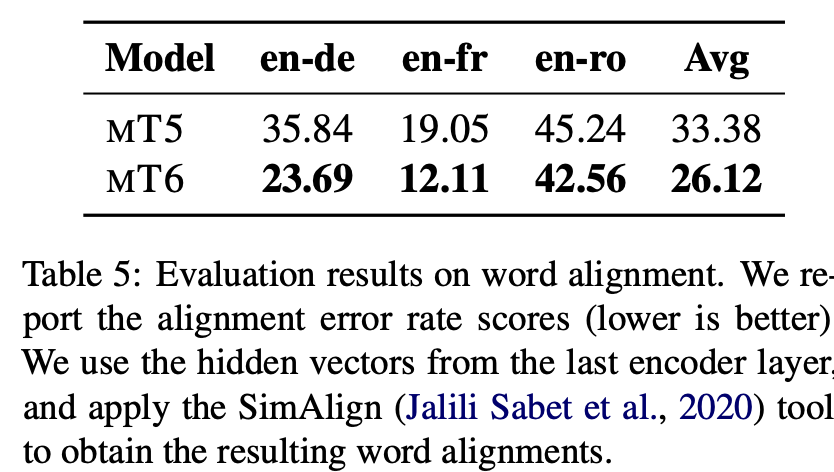
4.6 Word Alignment
- task goal: to find corresponding word pairs in a translation pair
- metric : alignment error rate (AER) scores
- result: MT6 achieves lower AER scores than MT5, indicating that the cross-lingual representations produced by MT6 are also better- aligned at token-level.
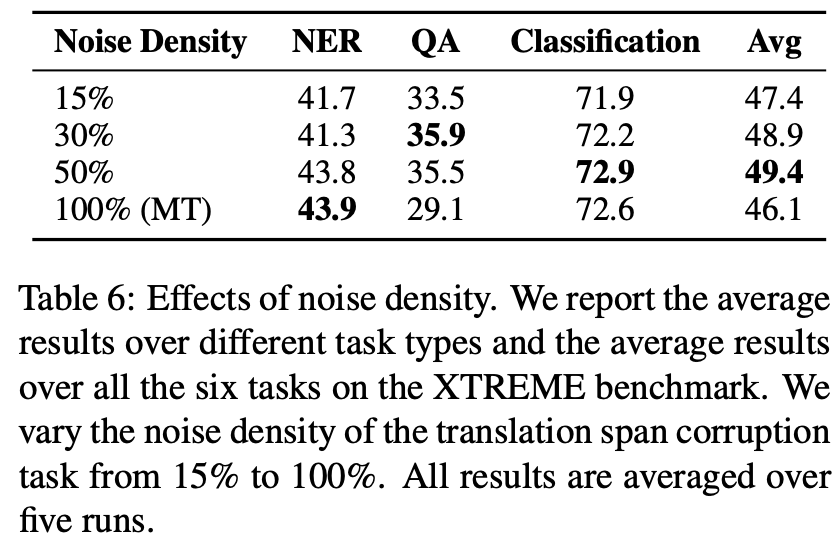
4.7 Effects of Noise Density
- task goal: TSC task 할 때 monolingual에만 span corruption 했을 때와는 달리 input sentences에는 불필요한 정보들이 들어간다. 그래서 어느정도의 noise density가 성능에 영향 미치는지 실험
- result: MT6 achieves the best results with the noise density of 0.5, rather than a higher noise density such as 1.0. The results indicate that the TSC task prefers a higher noise density, so that the model can learn to use more cross-lingual informa- tion. This finding is different from that reported by T5 (Raffel et al., 2020), where the span corruption task works better with the noise density of 0.15 under the monolingual setting.
What if I am a reviewer of this paper?
- Strength
- 결국엔 나중에 zero-shot을 하더라도 이런 Pre-trained 모델 쓰기 때문에 감사함을 느끼자^0^
- 다양한 실험을 통해 robust함을 보여주는 것은 배우자!
- Weakeness:
- 결국 대기업의 횡포인가? 자기들끼리 싸움 ㅎㅎ 다른 논문들에 비해 이렇다할 novelty가 없는대도 합격한 건 google이라서인건가!! 소시민들은 어떻게 살란 말인가!!!
- 우리 팀은 보통 social issue를 해결하기 위한 모델 제안이기 때문에 구조 하나하나 타당한 근거가 필요하다. 그런데 요런 논문은 이것 저것 다해봤는데 이게 제일 낫더라! 해버림. 아무래도 general한 것과 task-specific의 차이 때문이긴 하겠지만...!!!! 과연 맞는 것인가?!
- 작은 데이터셋으로도 좋은 성능을 낼 수 있는 방향도 발전 하면 좋겠다.
Code review

8개의 댓글

안녕하세요 누렁이님 ! 글 잘 보고 갑니다 Cross-lingual과 Multilingual 연구에 관심이 많은데 덕분에 좋은 논문 읽게 되네요 ㅎㅎ
T5
- Task별로 Fine-tuninig하지 않도록 한다는 게 엄청 좋은 것 같아요 !
- Prefix LM : prompting 방법에서 영감을 얻어서 해당 prefix 와 관련된 파라미터만 튜닝하는 방법이라고 하는데 본 post를 통해 처음 접해봤네요
- Corrupted Span이라는 새로운 Pretraining 전략이라니, 이런 것 생각해내는 게 신기합니다
mT5/mT6
- T5에서 다국어 언어 모델로 만들기 위한 mT5의 pretraining 전략 또한 흥미로워요 ~


- t5부터 백그라운드 설명이 잘 되어 있어서 이해하기에 어려움이 적었습니다~
- 개인적으로 loss가 mt6 학습방법의 핵심같은데 설명이 쉽게 되어 좋았습니다~
Span corruption task 부분으로 3개의 cross-lingual tasks를 사용하여 학습하는 방법이 흥미롭네요! 깔끔한 요약 해주셔서 잘봤습니다~~ 😇!