goal
1. http
- 웹상에서 client 와 server 간의 통신을 위한 프로토콜
- Web
2. http 캐시
- response의 header를 통해서, 컨텐츠 길이(content-length), 캐시 유효시간(Cache-Control), ETag 등을 전송한다.
- 캐시의 유효시간이 지나면 서버로부터 다시 읽어들이는데, 이때 서버의 응답과 캐시로 가지고있는 컨텐츠의 ETag가 같으면 업데이트하지 않는다.
3. http의 전송 프로토콜 - TCP/IP
- 웹 브라우저는 다양한 프로토콜을 사용해서 웹페이지를 로드한다.
- DNS(Domain Name System) 프로토콜을 사용하여 도메인 이름(ex. www.amazon.com)을 IP 주소(ex. 192.0.2.44)로 변환한다.
- 각 도메인이름은 IP주소에 매핑된다.
- 도메인 네임과 함께 거기에 해당하는 IP 주소값을 한 쌍으로 저장하고 있는 데이터베이스를 DNS라고 부르며, 이러한 변환과정은 네트워크 내부에서 자동으로 수행된다.
- 로컬 캐시 확인
- HTTP(HyperText Transfer Protocol)를 사용하여 해당 IP 주소에서 웹 페이지 콘텐츠를 요청한다.
- TLS(Transport Layer Security, 전송 계층 보안) 프로토콜을 사용하여 안전하고 암호화된 연결을 통해 웹사이트를 제공할 수 있다.
- TLS : 인터넷에서의 정보를 암호화해서 송수신하는 프로토콜로, SSL(Secure Socket Layer) 프로토콜에서 발전한 것. / 두 프로토콜의 기본 목표는 기밀성( 개인정보 보호 라고도 함), 데이터 무결성, 인증, 디지털 인증서를 사용하는 인증을 제공하는 것
- 모든 HTTP 요청도 TCP와 IP를 사용한다.
4. URL 구조
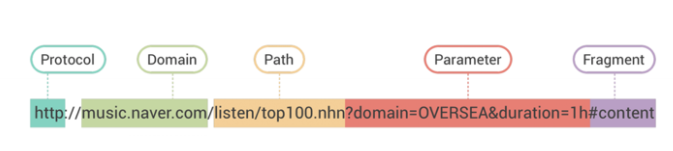
- URL >>>>> 도메인
- 도메인 구조
- www.google.com
www : 호스트명 (서브도메인) - URL로 전송하거나 계정 내의 IP주소나 디렉토리로 포워딩되는 도메인 이름의 확장자
google : 도메인명 - 사이트 이름 보통 서비스명
com : 최상위 도메인명 - 목적, 종류, 국가 등을 나타낸다.
- www.google.com
5. 웹의 구조
- 유저가 웹브라우저에 url을 입력한다.
- url(ex. https://www.google.com)에서 도메인네임(ex. www.google.com)을 찾는다.
- DNS서버에서 도메인네임과 매핑되는 IP주소를 찾는다.
- 브라우저는 HTTP 프로토콜을 사용해서 HTTP 요청을 생성한다.
- 요청메시지는 TCP 프로토콜을 사용해서 (인터넷을 거쳐) 해당 IP주소의 웹서버로 전송된다.
- (참고로) 웹서버는, 하드웨어적으로 보면 컴퓨터이자 소프트웨어적으로 보면 웹사이트들의 파일들 (html, css, js, video 등)을 저장해놓은 곳이다.
- (참고로) 프로토콜은, 두 개 이상의 컴퓨터들이 커뮤니케이션하는 법을 규칙화 해놓은 것이다.
- 해당 웹서버는 요청을 받아, 해당하는 html문서를 찾아 클라이언트에 response한다.
- 이 html문서에는 css, js 파일이 포함되어 있다.
- 브라우저는 이 문서를 웹브라우저에 렌더링한다.
BUT!! - WAS(Web Application Server)의 탄생
- WAS에서 서버단에서 필요한 기능을 수행한 후, 그 결과를 웹서버에 전달한다.
- WAS는 실시간으로 html 문서를 제작해서 클라이언트에게 서비스해준다. (동적 웹페이지 제공 가능)
- 서버에서 html 문서 제작을 도와주는 프레임워크 or 프로그래밍 언어인 JAVA, JSP(JavaServer Page), Servlet, JAVA Spring, Tomcat 등을 사용한다.
- 이후, 서블릿 컨테이너, 서블릿 라이프사이클, 서블릿 컨테이너와 서블릿의 관계, 서블릿 필터, 스코프, 쿠키, 세션 학습하기
- WAS가 이렇듯 복잡하고 웹서버보다 느리기 때문에, 둘을 같이 사용하기도 한다. 트래픽 처리를 위해 WAS의 갯수를 늘려 분산처리하며 로드밸런싱을 가능하게 한다.
- 아무튼, 이렇게 기존 웹서버에 비해 더욱 복잡한 작업을 하게 되었고, 이런 복잡한 설계들을 모듈화시켜 패턴으로 만든 것이 MVC 모델링이다.
MVC Architecture
-
model, view, controller를 분리한 디자인 패턴
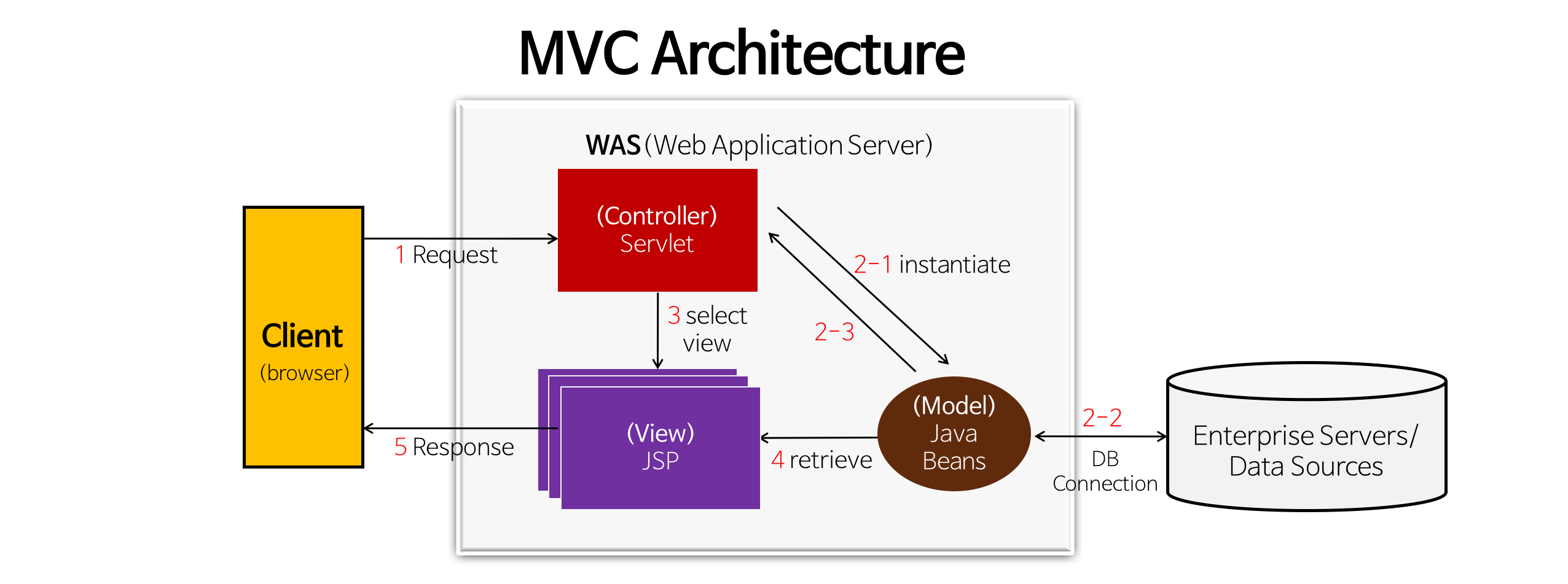
-
model
: 애플리케이션의 상태(data)를 나타냄 / Java Beans (: 자바(Java)로 작성된 소프트웨어 컴포넌트를 일컫는 말로 데이터 표현을 목적으로하는 자바 클래스) -
view
: 디스플레이 데이터 or 프리젠테이션 / JSP (: HTML내에 자바 코드를 삽입하여 웹 서버에서 동적으로 웹 페이지를 생성하여 웹 브라우저에 돌려주는 서버 사이드 스크립트 언어) -
controller
: view와 model 사이의 인터페이스, 상호작용 역할 및 데이터를 컨트롤함 / Servlet (: 자바를 사용하여 웹페이지를 동적으로 생성하는 서버측 프로그램으로 웹 서버의 성능을 향상시키기 위해 사용되는 자바 클래스의 일종)
- 웹의 역사
6. TCP/IP
인터넷
- 전 세계에 걸쳐 파일 전송 등의 데이터 통신 서비스를 받을 수 있는 컴퓨터 네트워크 시스템 / 사업자가 만들어놓은 네트워크 망을 사용 / 데이터를 디지털 신호로 바꿔 전달하고 받은 디지털 신호를 다시 데이터로 바꾸며
TCP/IP
- 인터넷에서 컴퓨터들이 서로 정보를 주고받는데 쓰이는 프로토콜 집합. 인터넷과 관련된 프로토콜들을 모은 것을 TCP/IP라 부른다.
계층(layer)의 개념
- TCP/IP Model
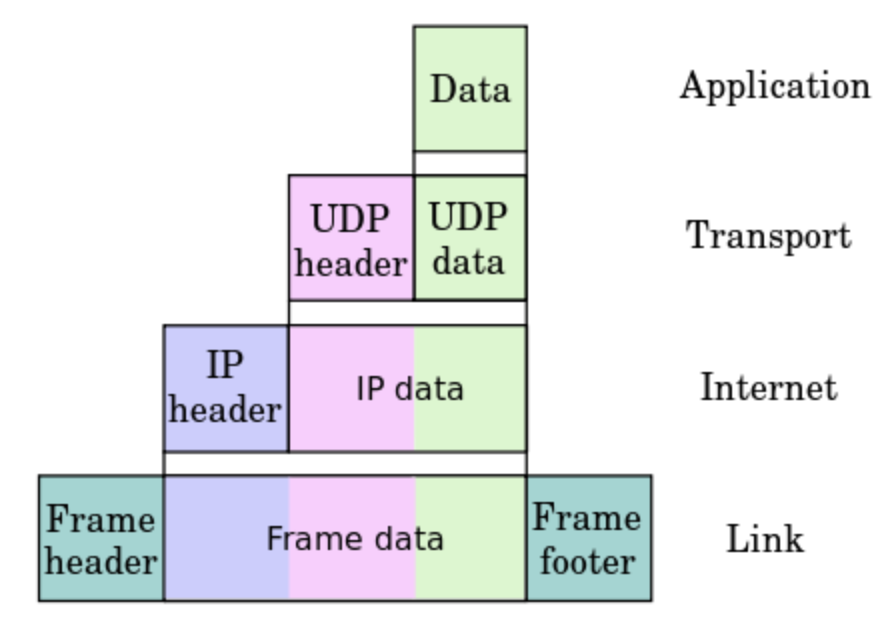
- 계층화의 효율성 : 인터넷이 하나의 프로토콜로 되어 있을 때, 사양이 변경되면 전체를 변경해야하지만, 계층으로 나눠져 있으면 해당 계층만 변경하면 된다.
- 각 계층은 연결부분만 결정되어 있고, 내부는 자유롭게 설계가 가능하다.
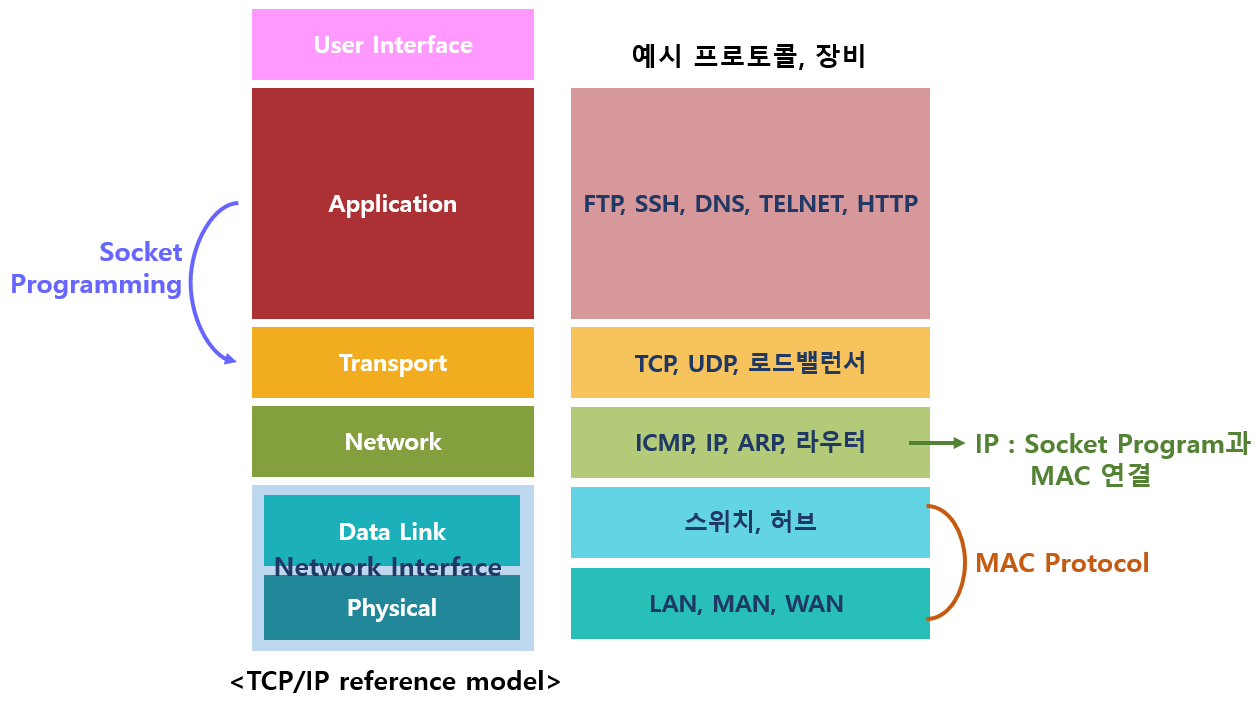
1) Application layer
- 유저에게 제공되는 애플리케이션에서 사용하는 통신의 움직임을 결정한다.
- FTP / DNS / HTTP
2) Transport layer
- application layer에 네트워크로 접속되어 있는 2대의 컴퓨터 사이의 데이터 흐름을 제공한다.
- TCP(Transmission Control Protocol) : 신뢰성있는 바이트 스트림 서비스를 제공하며, 데이터가 정확하게 도착했는지 확인하는 역할을 담당한다.
- 바이트 스트림 서비스 : 용량이 큰 데이터를 보내기 쉽게 TCP 세그먼트라고 불리는 단위 패킷으로 작게 분해해서 관리하는 것
- 데이터를 확실하고 정확하게 보내기 위해 TCP는 Three Way Handshaking 방법을 사용한다.
- (송신) --SYN--> (수신) --SYN/ACK--> (송신) --ACK--> (수신) : SYN/ACK 플래그를 통해 패킷 교환이 완료됨을 확인한다.
- UDP(User Data Protocol)
3) Network or Internet layer
- 네트워크 상에서 패킷의 이동을 다룬다.
- 패킷 : 전송하는 데이터의 최소단위
- IP(Internet Protocol) : IP는 개개의 패킷을 상대방에게 전달한다.
4) Link or Data Link or Network Interface layer
- 네트워크에 접속하는 하드웨어적인 면을 다룬다.
IP (Internet Protocol)
- IPv4 VS IPv6
| 구분 | IPv4 | IPv6 |
|---|---|---|
| 주소 길이 | 32bit | 128bit |
| 표시 방법 | 8bit씩 4마디(=옥텟)로 10진수로 표시 203.252.53.55 | 16bit씩 8옥텟으로 16진수로 표시 2002:0221:ABCD:ABCD:2002:0221:ABCD:ABCD |
| 주소 개수 | 약 43억개 (2011이미 고갈됨) | 거의 무한개 43억43억43억*43억개 기존 컴퓨터뿐만아니라, 모바일기기에도 IP를 할당할 수 있음 |
| 주소 할당 방식 | ABCDE의 클래스 단위 - A : 대규모 네트워크 환경/ 비순차적으로 할당 / 첫째옥텟의 값 범위 (0~127) - B : 중규모 네트워크 환경 / 첫째옥텟의 값 범위 (128~191) - C : 소규모 네트워크 환경 / 첫째옥텟의 값 범위 (192 ~ 223) - D : 멀티 캐스트용 / 첫째옥텟의 값 범위 (224~239) - E : 연구, 개발용 or 미래 사용 목적 / 첫째옥텟의 값 범위 (240~ 255) | 네트워크 규모와 단말기 수에 따라 순차적으로 할당 |
| 보안 | IPSec 프로토콜 별도 설치 | IPSec 자체지원 |
| 서비스 품질 | 제한적 품질 보장 | 확장된 품질 보장 |
| Node Plug & Play | 불가 **Plug & Play : 전용 서버가 없이도 그냥 네트워크에 붙이기만 하면 알아서 자동으로 주소를 만들어주는 것 | 가능 |
-
사용범위에 따른 구분 : 공인 IP 주소 VS 가상 IP 주소
- 공인 IP 주소 : 공인기관에서 인증한 공개형 IP 주소
- 가상 IP 주소 : 외부에 공개되지 않은 폐쇄형 IP 주소
-
할당방식에 따른 구분 : 고정 IP 주소 VS 유동 IP 주소
- 고정 IP 주소 : 컴퓨터에서 명시적으로 IP주소를 설정해서 사용하는 방식
- 유동 IP 주소 : IP 주소를 할당하는 특정 서버가 보내주는 IP 주소 그대로 컴퓨터에 자동 설정되는 방식
7. Web Socket
- 웹소켓은 클라이언트와 서버 간 영구적? 지속적인 커넥션이 가능하도록 한다.
Socket
Socket programming
-
Socket : 소켓, 구멍, 연결, 콘센트 ..
-
전기 소켓이 정해진 규격 (110, 220v)에 맞게 만들어져야 전기를 공급받을 수 있듯이, 네트워크에 연결하기 위한 '소켓'도 마찬가지로, 통신을 위한 '프로토콜'에 맞게 만들어져야 한다.
-
보통, OSI 7 Layer(Open System Interconnection 7 Layer)의 네 번째 계층인 TCP(Transport Control Protocol) 상에서 동작하는 소켓을 주로 사용하는데, 이를 "TCP 소켓" or "TCP/IP 소켓"이라 한다.
-
-
-
소켓 프로그래밍은, 소켓을 만들고, 만든 소켓을 이용해서 데이터를 주고받고, 소켓 API 사용법을 익히고, 다양한 예외사항 및 에러에 대한 처리 등에 대한 전반적인 이해가 필요하다.
-
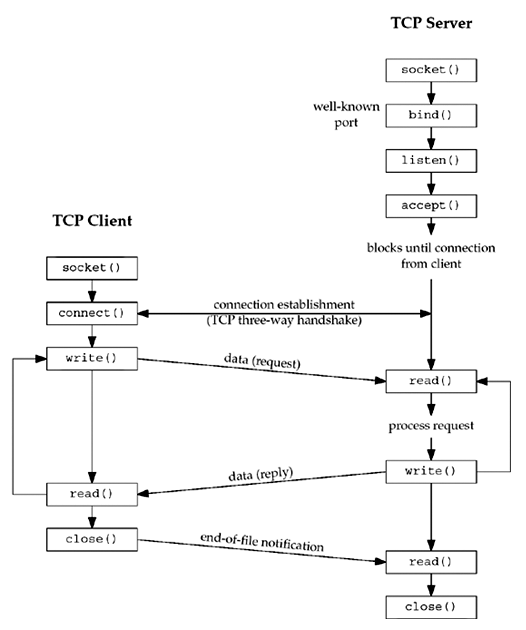
클라이언트 소켓(연결요청)과 서버 소켓(수신)의 역할
-
두 개의 시스템이 소켓을 통해 connection (네트워크 연결)을 하기 위해선, 둘 중 어떤 곳에서는 연결을 'req'해야 한다. (IP주소와, port 번호로 식별되는 대상에게, 본인이 connection을 할 것이라는 것을 알려야 함)
-
또한, 이 connection이 항상 받아들여져서 연결이 되는 것은 아니고, req를 받아들일 준비가 되어 있어야 connection이 이루어 지게 된다. (이 때 보통은, port 번호로 식별함)
-
connection req를 보내는 쪽이 -> 클라이언트 소켓
-
connection req를 받는 쪽이 -> 서버 소켓
-
단, 여기서 client socket과 server socket은 동일한 소켓이다. 단지, API 함수의 종류나 순서 등이 다를 뿐.
-
그리고, client socket과 server socket은 송수신의 역할만 할 뿐, 직접적인 데이터 송수신은 두 소켓의 connection 요청과 수락으로 만들어지는, '새로운 소켓'을 통해서 처리된다.
-
-
client
생성(create) -> 연결요청(connect) -> connect accept 되면 -> 데이터 송수신(write, read) -> 처리 완료 후 닫기(close) -
server
생성(create) -> 서버가 사용할 IP주소와 port번호를 결합(bind) -> 클라이언트의 req를 예의주시(listen) -> (cf. 이때 client connection req에 대한 정보는 시스템 내부의 Queue에 쌓이게 되고, 이때의 상태는 not established로 대기상태) -> req가 수신되면 수락(accept) -> "데이터 송수신을 위한 new 소켓 생성"한 후, 새로운 소켓으로 연결이 수립(connection-establishment) -> 데이터 송수신(read, write) -> 처리 완료 후 닫기(close)
-
-
-
참고1) 로드 밸런서
- 클라이언트가 엄~청 많을 때, 한번에 많은 양의 req가 들어오면, 서버는 결국 숨을 거두게 된다.
- 이러한 문제를 해결하기 위해 다음의 방법으로 해결할 수 있다.
- scale-up : server의 빠른 처리를 위해 하드웨어 성능을 업
- scale-out : 하나의 server가 아닌, 여러대의 server를 통해서 일을 분산
- 여러 대의 server에게 균등하게 traffic을 나누어주는 일을 수행하는 것이 바로 Load Balancer (로드 밸런서)이다.
-
참고2) ARP (Address Resolution Protocol)
- Internet Layer를 Network Interface Layer로 변환하는 역할을 수행
-
참고3) ICMP (Internet Control Message Protocol)
- IP 패킷의 전달에 따른 오류나 오류상태를 report하고 진단하는 기능을 수행
WebSocket
-
WebSocket은 초기 전송 메커니즘으로 HTTP를 사용하지만, HTTP 응답을 받은 후 TCP 연결을 활성 상태로 유지하여, 클라이언트와 서버 간에 메시지를 보내는 데 사용할 수 있다. / WebSocket을 사용하면 롱 폴링을 사용하지 않고 "실시간" 애플리케이션을 구축할 수 있다.
-
웹소켓은 HTTP와는 구별된다. 둘다 Application Layer에 위치해있으며, Transport Layer에 있는 TCP에 의존한다.
-
port 80과 443위에서 동작한다.
-
WebSocket VS HTTP
-
WebSocket HTTP 양방향 단방향 3-way handshaking 을 사용해서 데이터 패킷 전송의 전달을 보장하고, 손실된 패킷을 재전송하는데 이는 연결지향 프로토콜인 TCP 위에서 실행된다. 상태저장 - client와 server의 연결이, 두 당사자 중 한명에 의해 종료될 때까지 활성 상태를 유지 stateless 상태비저장
-
socket.io
- 웹소켓을 좀더 쉽게 사용할 수 있게 해주는 모듈로 just 웹소켓 프레임워크.
8. HTTP 특성
- HTTP는 클라이언트가 요청을 보내고 서버로부터 응답을 받으면, 클라이언트와 서버 간의 연결을 끊는다. (connectionless)
- 따라서, 클라이언트의 각 요청 사이에 상태를 공유할 수 없다.(stateless, 무상태 프로토콜)
- BUT, 로그인과 같이 클라이언트의 행위를 기억하기 위한 목적으로 지원하는 것이 'cookie(쿠키)'이다.
- 서버에서 로그인 요청을 받으면 로그인 성공/실패 여부에 따라, 응답헤더에 Set-Cookie의 값을 읽어 서버에 보내는 요청 헤더의 Cookie 헤더 값으로 다시 전송한다.
- HTTP는 클라이언트와 서버 각 요청 간 데이터를 공유할 방법이 없기 때문에, 헤더를 통해 공유할 데이터를 매번 다시 전송하는 방식으로 데이터를 공유한다.
- 그러나, 이 쿠키 정보는 클라이언트에 저장해서 관리하기 때문에 보안이슈가 생겨났고, 이러한 단점을 보완하기 위해 'session(세션)'이 나왔다.
- 쿠키는 보완을 강화하기 위해 domain, path, max-age, expires, secure 속성을 사용할 수 있다.
- http의 특성으로 인해, 서버는 클라이언트를 식별할 수 있는 방법이 필요해졌다.
cookie & session
cookie
- 클라이언트에 저장되어있는 키와 값이 들어있는 작은 데이터 파일
- 이름, 값, expire date, path 등이 들어있다.
- 일정시간동안 데이터를 저장할 수 있기 때문에 로그인 등 유저의 정보를 일정시간 유지하기 위해 사용된다.
Set-cookie속성을 통해 클라이언트에 쿠키를 만들수 있다.- 한번 생성되면, 다시 req하지않아도 쿠키값을 가지고 전송 시 사용한다.
- 하지만, 보안상의 이슈가 있다.
session
- 세션은 서버의 메모리에 저장되는 정보
- 서버에 저장되기 때문에, 쿠키처럼 유저의 정보가 바로 노출되지 않는다.
- 처리과정 : 로그인버튼 클릭(id, pw 저장) -> 서버에서 정보를 확인하고, 존재하는 유저일 때, 서버메모리에 세션ID를 생성한 후, 유저가 보낸 정보와 매핑한다. -> 클라이언트에 세션 ID를 쿠키로 저장한다. -> 요청시마다, 서버는 req header의 쿠키정보(세션 ID) 확인 후, 세션ID와 맵핑되면 같은 유저로 인식한다.
HTTP Message Header
메시지헤더
개행문자
메시지바디
HTTP Message Header field
- Hop-by-hop Header
- 한 번 전송에 대해서만 유효하다.
- Connection // Keep-Alive // Proxy-Authenticate // Proxy-Authorization // Trailer // TE // Transfer-Encoding // Upgrade - End-to-end Header
- req or res의 최종 수신자에게 전송된다.
- 이외 모두
1. General Header Fields : req, res both
| name | desc |
|---|---|
| Cache-Control | 캐시 동작 지정 |
| Connection | - 프록시에 더이상 전송하지 않는 헤더 필드 지정 - connection 관리 (Connection: keep-Alive => 현 TCP 커넥션을 유지 / Connection: token list => 중계연결(프록시)에 대한 옵션 설정 /Connection: close => 현 커넥션 직후에 TCP 접속을 끊는다는 것을 알림) |
| Date | 메시지 생성 날짜 |
| Pragma | 메시지 제어 |
| Trailer | 메시지의 끝에 있는 헤더 필드를 미리 전달할 수 있음 |
| Transfer-Encoding | 메시지 바디의 전송 코딩 형식 지정 (청크 등) |
| Upgrade | http 및 다른 프로토콜의 새로운 버전이 통ㅅ니에 이용되는 경우에 사용 |
| Via | client와 server 간 req or res 메시지의 경로를 알기 위해 사용 / 프록시 서버에 관한 정보가 담겨있음 |
| Warning | 캐시에 관련된 경고를 client에 전달 Warning: [경고코드][경고한 호스트:포트번호]"[경고문]"([날짜]) |
1) Cache
- client --> cache server <-- origin server
- cache server : 인터넷 서비스 속도를 높이기 위해 사용자와 가까운 곳에 데이터를 임시 저장하여 빠르게 제공해주는 프록시 서버.
또한, 서버가 국외에 있는 경우, 외국과의 통신에 필요한 회선 사용료 절감을 목적으로 설치되기도 한다.
- cache server : 인터넷 서비스 속도를 높이기 위해 사용자와 가까운 곳에 데이터를 임시 저장하여 빠르게 제공해주는 프록시 서버.
- cache request directive
-
directive parameter desc no-cache x 오리진 서버에 강제적으로 재검증 no-store x req, res의 일부분을 보존할 수 없음 max-age=n(초) o res의 최대 age 값 max-stale(=n(초)) opt 기한이 지난 res 수신 / 캐시된 리소스의 유효 기한이 끝났더라도 받아들일 수 있음을 나타냄 min-fresh=n(ch) o 지정한 시간 이후 변경된 res를 보냄 no-transform x 프록시가 미디어 타입을 변환할 수 없음 only-if-cached x 캐시에서 리소스를 get
즉, 캐시 서버에서 res의 리로드와 유효성을 재확인하지 않도록 요구함cache-extension - 새로운 디렉티브를 위한 토큰
-
- cache response directive
-
directive parameter desc public x 다른 유저에게도 res 캐시 가능함 private opt 특정 유저에게만 res 캐시 no-cache opt 캐시로부터 오래된 리소스가 반환되는 것을 막기 위해 사용함
특정 헤더 필드명이 지정된 경우에는 지정된 헤더 필드만 캐시할 수 없음(이 외는 가능)no-store x req or res에 기밀정보가 포함되어 있는 경우이므로, 캐시는 req or res를 로컬 스토리지에 보관해서는 안됨 no-transform x req or res 에서 캐시가 엔티티 바디의 미디어 타입을 변경할 수 없음
-> 캐시 서버 등에 의해 이미지가 압축되는 것을 방지함must-revalidate x res의 캐시가 현재도 유효한지 여부를 오리진 서버에 조회 요구
이 디렉티브가 사용되면, req에서 max-stale 효과를 없앰proxy-revalidate x 모든 캐시 섯버에 대해 이후의 req로 해당 res를 반환할 때 반드시 유효성 검사를 하도록 요구 max-age=n(초) o 캐시 서버가 유효성을 재확인하지 않고 리소스를 캐시에 보관해두는 최대 시간 s-maxage=n(초) o max-age와 기능은 동일
단, 여러 유저가 이용할 수 있는 공유 캐시 서버에만 적용됨cache-extension -
-
2) Connection
2. Request Header Fields : req / 부가정보, 클라이언트정보, 응답 컨텐츠에 관한 우선순위 등의 내용
| name | desc |
|---|---|
| Host | 요청하는 호스트에 대한 호스트명 및 포트번호 |
| Accept ( = 엔티티의 Content-Type) | 클라이언트(자신)가 원하는 미디어타입 및 우선순위 |
| Accept-Charset ( = 엔티티의 Content-Type) | 문자셋 |
| Accept-Encoding ( = 엔티티의 Content-Encoding) | 컨텐츠 인코딩 |
| Accept-Language ( = 엔티티의 Content-Language) | 언어(자연어) |
| Authorization | 웹 인증을 위한 정보 |
| Expect | 서버에 대한 특정 동작 요구를 전달 |
| From | 유저의 메일 주소 전달 |
| Host | req한 리소스의 인터넷 호스트와 포트번호 전달 / (유일한) *필수 헤더 필드 |
| If-... (아래 5개 헤더 필드) | 조건부 req -> 조건부 req를 받은 서버는 지정된 조건에 맞는 경우에만 req를 받음 |
| If-Match | 엔티티 태그의 비교? |
| If-Modified-Since | 리소스의 갱신 시간 비교 |
| If-None-Match | 엔티티 태그의 비교 (If-Match와 반대) |
| If-Range | 리소스가 갱신되지 않은 경우 엔티티의 바이트 범위의 요구를 송신 |
| If-Unmodified-Since | 리소스의 갱신 시간 비교 (If-Modified-Since와 반대) |
| Max-Forwards | 최대 전송 hop 수 |
| Proxy-Authorization | 프록시 서버의 클라이언트 인증을 위한 정보 |
| Range | 엔티티 바이트 범위 요구 |
| Referer | 리퀘스트 중 URI 취득하는 곳 |
| TE | 전송 인코딩의 우선 순위 |
| User-Agent | HTTP 클라이언트의 정보 |
3. Response Header Fields : res / 정보, 서버정보, 클라이언트의 추가 정보 등의 내용
| name | desc |
|---|---|
| Accept-Ranges | 바이트 단위의 요구를 수신할 수 있는지 없는지의 여부 |
| Age | 리소스의 지정 경과 시간 |
| Etag(=entity tag) | 리소스를 특정하기 위한 문자열을 전달 서버는 리소스마다 ETag 값을 할당함 (따라서 리소스가 갱신되면 ETag 값도 갱신해야 한다.) |
| Location | 클라이언트를 지정한 URI에 redirect |
| Proxy-Authenticate | 프록시 서버의 클라이언트 인증을 위한 정보 |
| Retry-After | 리퀘스트 재시행의 타이밍 요구 |
| Server | HTTP 서버 정보 |
| Vary | 프록시 서버에 대한 캐시 관리 정보 |
| WWW-Authenticate | 서버의 클라이언트 인증을 위한 정보 |
4. Entity Header Fields : req, res both / 컨텐츠 갱신 시간 등의 엔티티에 관한 정보 등의 내용
- Entity Header : req or res 메시지의 payload로서 전송되는 '정보' / entity는 Entity-Header 필드 형태의 메타 정보 및 Entity-body 형태의 내용으로 구성되어 있다.
- entity :
실체, 객체, 객체 /
의미있는 하나의 정보 단위 /
사물의 본질적인 성질을 속성이라고 하며, 관련있는 속성들이 모여서 의미있는 하나의 정보 단위를 이룬 것이 바로 개체
- entity :
| name | desc |
|---|---|
| Allow | 리소스가 제공하는 HTTP 메소드 |
| Content-Type ( = req의 Accept-Charset) | 엔티티 바디의 미디어 타입 |
| Content-Encoding ( = req의 Accept-Encoding) | 엔티티 바디에 적용되는 컨텐츠 인코딩 |
| Content-Language ( = req의 Accept-Language) | 엔티티의 자연어 |
| Content-Length | 엔티티 바디의 사이즈 (바이트 단위) |
| Content-Location | 리소스에 대응하는 대체 URI |
| Content-MD5 | 서버에서 메시지 본문에 대한 메시지 무결성 검사를 제공 |
| Content-Range | 엔티티 바디의 범위 위치 |
| Expires | 엔티티 바디의 유효기간 날짜 |
| Last-Modified | 리소스의 최종 갱신 날짜 |
상태코드
| class | desc | |
|---|---|---|
| 1 | informational | req를 받아들여 처리중 |
| 2 | success | req를 정상적으로 처리함 |
| 3 | redirection | req를 완료하기 위해 추가 동작 필요 |
| 4 | client err | 유효하지 않은 client req |
| 5 | server err | 서버의 req 처리 실패 |
- 200 OK : 성공
- 204 No Content : req 처리 성공했지만, res에 entity body는 없음 (res에 리소스는 없는 상태)
- 206 Partial Content : 부분적인 req처리
- 301 Moved Permanently : req된 리소스에 새로운 URI부여되었음을 알림
- 302 Found : 301과 같음. 단, 일시적
- 303 See Other : 302와 같음. 단, redirect를 get 메소드를 사용해야함을 알림
- 304 Not Modified : client가 조건부 req를 했을 시, 리소스에 엑세스하지만 조건이 충족되지 않음을 알림 / 바디 없음
- 400 Bad Request : req 잘못됨
- 401 Unauthorized : req에 http인증 필요함을 알림
- 403 Forbidden : req된 리소스의 엑세스 거부됨 / 서버는 이유를 분명히 알림
- 404 Not Found : req한 리소스가 서버에 없음
- 500 Internal Server Error : 서버에서 req를 처리하는 도중 에러가 발생
- 503 Service Unavaliable : 서버의 과부화 or 점검중으로 현재 req 처리 불가를 알림
HTTPS(HTTP Secure)
-
암호화
-
- 통신 암호화 : HTTP + SSL(Secure Socket Layer) or TSL(Transport Layer Security) 프로토콜을 조합해서 통신 내용을 암호화
- SSL : 상대를 확인하는 증명서 (published by 제3자 기관, 조직 등)
-
- 컨텐츠 암호화 : HTTP 메시지(바디)에 포함되는 컨텐츠의 내용 자체만 암호화
-
-
HTTPS = HTTP + 암호화 + 인증 + 완전성 보호
HTTP/1.0 -> HTTP/2.0
-
HTTP/1.0
- 가장 기초적인 형태의 웹 프로토콜
- 기본적으로 connection 당 단 하나의 요청을 처리한다.
- 따라서, 동시전송이 불가능하다.
- 또한, 클라이언트의 요청과 서버의 응답이 순차적으로 이루어진다.
- 이로인해, 웹의 규모가 거대해지면서 다수의 리소스 (html, js, css 등)를 처리하려면 latency(대기시간)가 길어지게되는 문제점이 나타나기 시작한다.
-
HTTP/1.1
- network latency의 해결을 위한 방법 2가지
- 1) Pipelining
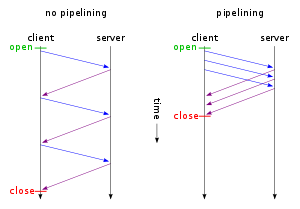
- req가 연속적으로 발생하고, 그에 따른 res도 순차적으로 동작한다.
- 기존 1.0 버전에서는 client req를 소켓에 write한 뒤에, server의 res를 받은 후, 다음 req를 보내는 방식으로 동작했고, 이렇게 계속 client 의 요청이 대기(latency)되는 것은 많은 비용을 요구했다.
- 2) Persistent Connection
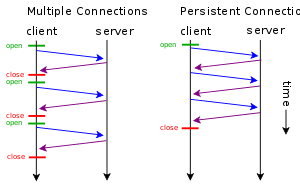
- SYN, SYN-ACK, ACK 3번의 핸드셰이킹을 하면서 계속 TCP연결의 open, close를 반복해야 했는데, 웹의 컨텐츠가 거대해지며, TCP connection의 재사용에 대한 니즈가 커졌다.
Connection: keep-alive를 사용해서 재사용했던 것을, 1.1 버전에서는 위의 헤더를 사용하지 않아도 모든 req와 res가 connection을 재사용하도록 setting되어있다.
- 1) Pipelining
- network latency의 해결을 위한 방법 2가지
-
과도기의 SPDY
- SPDY (스피디) 프로토콜로 HTTP의 병목현상 해소
- 병목 : 물이 병 밖으로 빠져나갈 때 병의 몸통보다 병의 목부분의 내부 지름이 좁아서 물이 상대적으로 천천히 쏟아지는 것에 비유한 것
- 병목현상 : 전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상
- 구글 자체 프로토콜 (더이상 지원하지 않음)
- 페이지 로드시간이 15~50% 감소
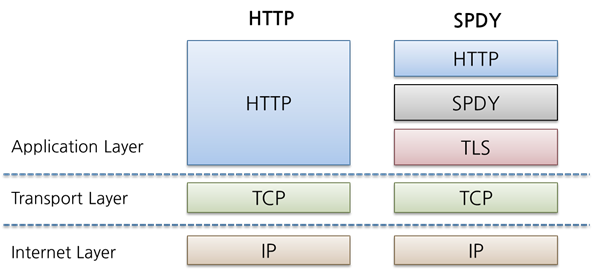
- SPDY (스피디) 프로토콜로 HTTP의 병목현상 해소
-
HTTP/2.0
-
goal : "성능 향상"
-
1) Binary Framing (바이너리 프레이밍)

- Binary Framing Layer로 기존 HTTP 메시지가 캡슐화되어 client와 server 사이에서 데이터가 전송되는 방식을 규정한다.
- 기존의 메소드나, 헤더 등의 변화는 없지만, 데이터 전송 중 이들이 인코딩되는 방식이 달라진다.
-> 기존에 줄바꿈으로 구분되던 일반 text 방식에서 진화하여 HTTP/2.0버전은 더 작은 메시지와 프레임으로 분할되어, 이 각각은 바이너리 형식으로 인코딩된다.- Binary : 이진 코드 / 컴퓨터 언어로 0과1로 표현하는 것
- 프레임(frame) : HTTP/2.0에서 통신의 최소 단위 / 각 최소 단위에는 하나의 프레임 헤더가 포함됨 / 프레임 헤더는 스트림을 식별함
- 메시지(message) : Frame 의 시퀀스 데이터
- 스트림(stream) : 구성된 연결 내에서 전달되는 바이트의 양방향 흐름 / 하나 이상의 메시지가 전달될 수 있음
-
2) Packet Capsulation (패킷 캡슐화)
- HTTP/2.0 의 패킷들은 더 작은 단위로 캡슐화됨
- HTTP/2.0 의 모든 연결은 TCP 기반의 Stream 이며, 양방향으로 Frame Header 를 지닌 Message 들을 통신함

-
3) Multiplexing (다중화) 개선

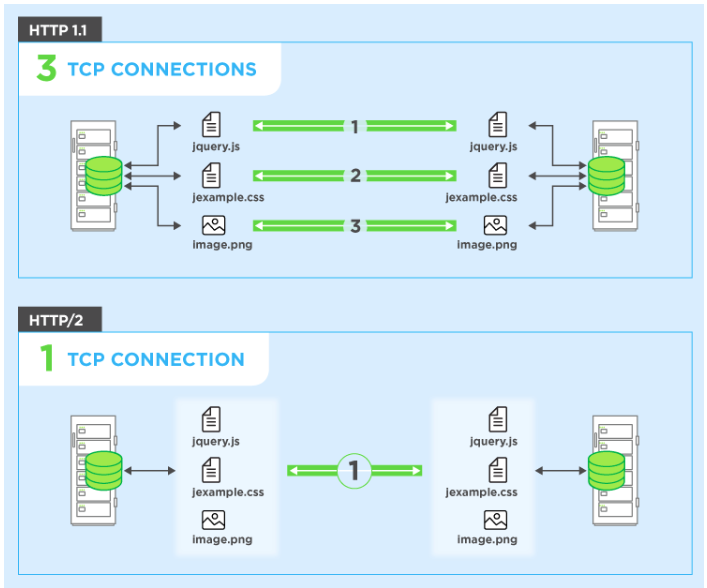
- connection하나에서 여러개의 입출력이 가능하도록 개선 (기존 HOL(Head of Line) 이슈 )
- how? 패킷을 Frame 단위로 세분화해서, 순서에 상관없이 받는 쪽에서 재조립하도록 만들었기 때문
- 따라서, req와 res를 병렬적으로 전달할 수 있게 되었다.
-
4) Stream Prioritization (스트림 우선순위 지정)
- 기존 client가 요청한 html문서 내 css, img 파일이 있을 때, 이 파일들을 각각 요청했을 때, 하나의 파일의 수신이 늦어져서 브라우저에서 렌더링할 때 문제가 발생하곤 했는데, 2.0버전의 경우, 리소스 간 우선순위를 설정해서 위와 같은 이슈를 해결했다.
-
5) Server Push (서버 푸시)
- 서버가 단일 클라이언트 요청에 대해 여러 응답을 보낼 수 있게 되었다. 또한 서버는 클라이언트가 요청하지 않은 리소스를 추가적으로 보내줄 수도 있게 되었다.
-
6) Header Compression (헤더 압축)
- HPACK압축방식을 사용해서 header 정보를 압축해서 최적화
-
feedback 및 추가사항
-
인터넷이 나오기 이전에는 어떻게 데이터를 주고받았을까?
- 넷스케이프 / 인트라넷
-
브라우저의 큰 줄기
- 모질라 / 사파리 / user-agent header 살펴보기
-
uri vs url의 개념
- 여기서 i 의 개념 / 리소스 그의 증명 확인 /
-
www : host : 사람의 언어로 바꾼 별칭 / host = 각 컴퓨터
-
도메인주소 === 호스트명 === 단 한개만 존재할 수 있음 (ex. facebook - meta)
- (my answer : 여러개 존재할 수 있다... 공유기 연결 / 공유기로 연결하는 것은 다른 개념 - port forwarding)
-
ip
- subnet mask 에 대한 개념
- ip 주소를 할당하는 방식
- broadcast
-
소켓은 위에서처럼 client socket vs server socket으로 나뉘는 개념말고
- 동기소켓 vs 비동기소켓 개념이 있음
-
thread polling 폴링에 대한 개념 공부
- 참고로, 폴링에 대한 개념은 소켓 말고도 여러 곳에서 쓰임
-
소켓 : 연결지향형 vs 비연결지향형
-
http는 비동기? 동기? : my answer : 동기에서 비동기 (x)
- 동기 / 동기와 비동기는 lock이 걸리느냐 안걸리느냐에서 일차적으로 판가름
-
병목 - DDos 공격 / 아이돌티켓팅예매
-
쿠키 n 세션
- 쿠키 : 클라가 아이디/패스워드 서버에 주면, 디비에서 일치하는 것을 찾으면, 서버는 쿠키를 구워서 클라에게 줌 / 클라는 그 쿠키를 저장함
- 세션 : 세션아이디를 와스에서 발급을 하는데, 문제는 세션은 하나의 서버만 / 근데 요즘 서버가 여러개로 나눠져 있을 때, 1번 서버에는 세션아이디를, 2번서버에 api call을 하면 ? / 1,2 서버가 각각 세션아이디가 공유되지 않잖아 / 이때 나오는 개념이 세션 클러스터링
-
요즘은, 인증에 관한 것은 api로 따로 가져감 / jwt 토큰 방식으로 / auth 인증방식
- ex. 카카오, 네이버 등 소셜로그인 // 클라 <-> 카카오서버 && 클라 <-> 멜론서버 // 멜론서버에서 secret, access 키 가짐
-
mvc
- model? : 어려운개념 / but, data structure 자체를 의미함
- ddd : domain driven design
- 컨트롤러의 개념은 / 프론트에서 요청하면 서블릿이나 node.js (애들은 해석기일뿐)에서 데이타를 컨트롤러로 control..
-
cors
- 클라 -> 웹서버 -> 와스
- 웹서버에서 와스로 / 이때 클라이언트가 누군지
-
Rxjs
-
리액트 프로그램
-
동기/비동기
-
blocking io / non-blocking io
-
고프의 디자인패턴 (도서)
-
외우지말고, 외우려고하는 경향 / 항상 이해 이해이해 / 왜?왜만들어졌지? 를 찾다보면 / 왜나온개념이지? / 하는 역할에 치중하지말자 / 왜에 대해서 생각하자
