
What is it
분할 정복 알고리즘의 하나로, 기준점을 두고 다른 원소와의 비교 해 정렬하는 방법이다.
병합 정렬과 달리 퀵 정렬은 리스트를 비균등하게 분할한다
How to works it
분할(Divide) - 기준점(pivot)을 정해, 피벗보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right)으로 분할
정복(Conquer) - 더 이상 분할이 불가능 할때까지 분할 후 분할된 부분 배열을 정렬.
결합(Combine) - 정렬 된 부분 배열을 하나의 배열에 병합
Let's make it Code
- 기준점(pivot)을 정해, 피벗보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right)으로 모으는 함수를 작성
- 각 왼쪽(left),오른쪽(right)은 재귀 용법을 사용해 다시 동일 함수를 호출하여 더 이상 분할이 불가능 할때까지 위 작업을 반복
- 함수는 왼쪽(left) + 기준점(pivot) + 오른쪽(right)을 리턴
func quickSort(_ data: [Int]) -> [Int] {
if data.count <= 1 { return data } //#1
var left: [Int] = []
var right: [Int] = []
let pivot = data[0] //#2
for index in 1..<data.count {
if pivot > data[index] { //#3
left.append(data[index])
}else {
right.append(data[index])
}
}
return quickSort(left) + [pivot] + quickSort(right) //#4
}
print(quickSort([3,6,1,8,0,7,4,2])) //0,1,2,3,4,6,7,8
#1
입력된 데이터의 길이가 1이하인 경우 데이터 그대로 리턴
#2
데이터의 가장 앞 요소를 피벗으로 지정한다
#3
피벗보다 작은 것은 left배열에, 큰 것은 right 배열에 나눠서 삽입한다(divide and conquer)
#4
left배열과 right배열 사이에 피벗을 넣어 리턴
Algorithm analysis
매 단계에서 적어도 1개의 원소가 자기 자리를 찾게 되므로 이후 정렬할 개수가 줄어든다. 때문에 일반적인 경우 퀵 정렬은 다른 O(n log n) 알고리즘에 비해 훨씬 빠르게 동작한다. 이러한 이유로 퀵소트(빠른정렬)라는 이름의 기원이 되었다. 그리고 퀵 정렬은 정렬을 위해 O(log n)만큼의 memory를 필요로한다.
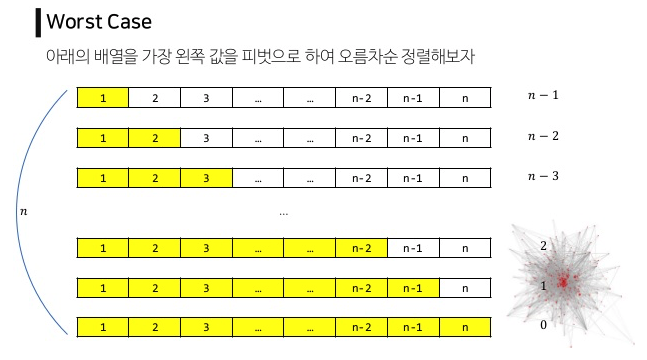
단, 최악의 경우 (맨 처음 pivot이 가장 크거나, 가장 작으면) 에는 모든 데이터를 비교하는 상황이 나옴. O(n^2)
References

🌐Code makes world better