
프로젝트를 진행하면서 단순 쿼리만을 작성하는 것이 아닌 IO 작업을 많이 하는 쿼리에 대해서 힌트절을 작성한 부분을 접하게 되었다.
쿼리 작성시 옵티마이저가 최적의 실행계획을 세우지만 그러지 못한 경우 힌트절을 사용하여 옳바른 실행계획을 하게 한다. 무분별한 힌트절은 오히려 쿼리문에 독이 되고 상황에 맞고 적절한 힌트절을 작성하고자 공부한 내용을 정리하고자 한다.
들어가기에 앞서
join에 대해 아는 것이 있으세요? 라고 물었을 때 떠오르는 건 inner join , outer join , natual join이 생각날 것이다. 하지만 이 외에도 오라클이 최적의 성능을 뽑기 위해서 테이블 간 조회 하는 방법에 대해 알아보기 전에 Driving Table과 Driven Table에 대해 알아보자
Driving Table(outer Table), Driven Table( inner Table)
두 개의 테이블을 조인 하는데 있어서 어느 테이블을 가져오는게 효율적인가에 대해 생각해 보아야 한다. 만일 두 개의 테이블에 인덱스가 있거나 둘다 없다면 where 절에 맞는 레코드의 수가 적은 테이블이 Driving Table에 올라와야 한다.
문제는 이제 하나의 테이블에만 where 절 컬럼의 인덱스를 가지고 있는 경우이다. 필자는 처음에 어느 테이블을 가져와도 N^2 의 시간이 걸리는 거 아닐까? 라고 생각하였는데 우선 조인시에 Driving Table을 Buffer Cache에 가져와야 한다.
그 이후 해당 테이블와 매칭되는 컬럼을 인덱스를 통해서 가져오는 과정과 그냥 가져오는 것에 대한 시간차이가 분명 날 것이다. 컬럼의 양과 관계도 있기 때문에 여러 테이블을 바꿔가면서 Explain 을 실행하고 최적의 방법을 찾는 것도 방법이다 😉
심화 JOIN
앞에서 말한 join 이외에도 NL-join , Sort-merge-join , hash-join에 대해 알아보자
NL- join
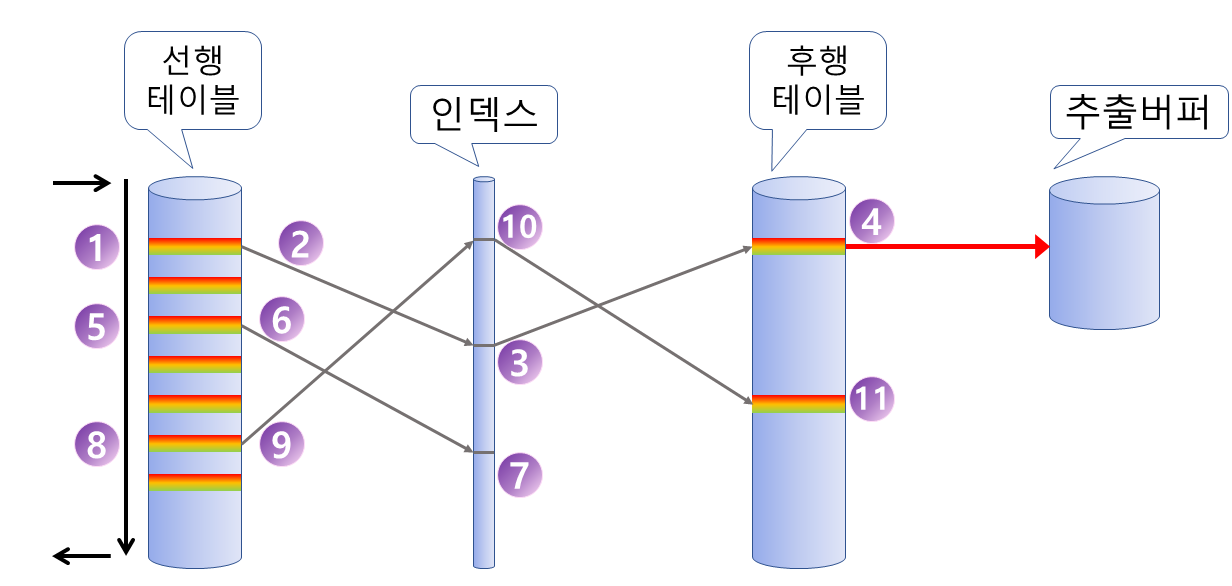
NL-join 은 선행테이블(Driving Table)에서 첫번째 행에 접근하고 나서 그 행의 조인할 속성을가지고 후행테이블 인덱스(Driven Table)를 거쳐 접근하여 데이터들을 가져와서 출력을 하게 된다.
Driving Table은 인덱스 대부분 Full Scan을 사용해서 가져오기 때문에 비교적 작은 테이블에 하는 것이 효과적이며 두개의 테이블에 인덱스가 있다면 Random Access를 통한 빠른 속도로 인해 OLTP 쿼리에 적합하다. 하지만 하나의 테이블이 인덱스가 있더라도 레코드 양이 많다면 그만큼 SGA Buffer Cache를 잡고 있는 것이므로 다른 조인 방법을 생각해 보자.
Sort-merge-join
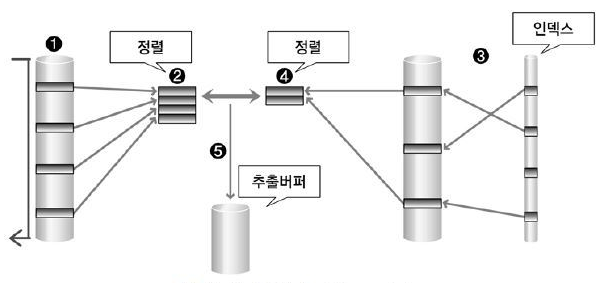
Sort-merge-join은 선행 테이블에서 조인 조건을 만족하는 행을 찾아 행에 따른 정렬을 먼저 하고 이 후 후행 테이블의 조건을 만족하는 행을 찾고 또 행에 따른 정렬을 실행한다.
정렬된 두 결과를 비교하여 조인수행하고, 성공결과를 버퍼에 저장하여 출력하게 된다.
해당 정렬은 인덱스가 없는 테이블에서 조인을 하기 위해 추가적으로 Equl Join(=) 이 아닌 <, > 와 같은 크기 비교 연산을 위한 쿼리에 적합하다.(정렬로 인한 속도 개선)
또 최종적으로 Lock 에 대한 경합 이 없어서 안정적이라는 것이 장점이다.
하지만 양쪽의 레코드를 정렬하는 것이기에 그 만큼의 시간과 자원을 차지하게 되고 만일 두 개의 테이블의 레코드 차이가 크게 된다면 먼저 정렬된 레코드들이 후에 완료되는 레코드 정렬을 기다려 자원을 낭비하는 상황도 발생한다.
왜 경합이 없는 것일까?
해당 Sort-join 할 때에 정렬하는 과정을 PGA 의 Sort work area의 Order Area 에서 진행하게 된다. 따라서 접근하는 테이블의 레코드에 다른 사람이 접근하더라도 이미 PGA 메모리에 정렬하기 때문이다.
PGA에 대해 까먹었다면 아래 링크 참고 해보자 😳
PGA와 오라클의 기본동작
Hash-join
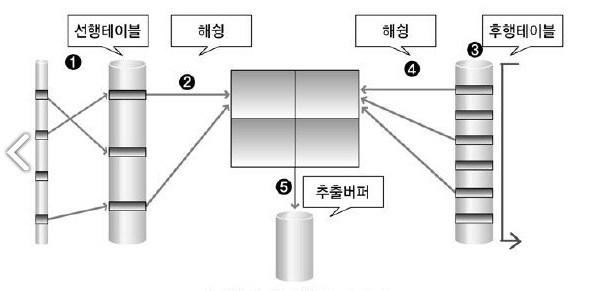
Hash-join은 선행 테이블(Build Input)에 대해서 조건을 만족하는 행을 찾고 나서 해당 행을 기준으로 HASH 함수를 적용하고 해시 테이블을 생성한다.
후행 테이블(Prov Input)에서 해당하는 행을 찾고 나서 해시 함수를 적용하고 나온 데이터와 맞는 해시 버켓에 넣고 최종적으로 join이 마무리 하게 되면 출력하게 된다.
hash-join은 Sort-merge-join을 시행하기에 너무 큰 테이블이라 PGA에 담지 못하는 경우가 발생하여 생긴 join이라고 생각하면 좋다. PGA의 Sort Work Area 중에서 Hash Area에 Hash 테이블을 생성하게 되며 후행 레코드 데이터를 Buffer Cache에 넣거나 혹은 Swapped Area 에 저장하여 Join을 시행한다.
앞에서 말한 Sort-Merge-join 처럼 인덱스에 의존하지 않고, 또 배치 프로그램에 적합하지만 해시 함수의 결과값이 어떤 값이 되는지 알수 없으며 큰 값이 항상 큰 버켓에 해슁 되고 작은 값이 작은 버켓에 해슁된다는 보장이 없기 때문에 비교 연산이 아닌 동등 조인에서만 가능하다는 단점이 있다. 또 PGA의 영역에 담지 못할 정도로 Build Input 값이 많다면 Sort-Merge-join과 마찬가지로 Swapped Area를 이용하기 때문에 그 점 유의하자.
Join Operations에 관하여
/*+ USE_NL(table1 table 2...) */
앞에서 설명한 NL-JOIN 을 지정하는 것이며 앞에 오는 테이블이 outer table(Driving)이 된다.
/*+ USE_HASH (table_name) */
앞에서 말한 HASH-JOIN을 명시할 떄 사용한다.
/*+ USE_MERGE (table_name) */
지정된 테이블들의 조인이 SORT-MERGE형식으로 일어나도록 명시한다.
위의 Join Operations 들은 대부분 ORDERED , LEADING 같은 Join oders 힌트절과 명시된다.
Optimizer_mode 에 관하여
쿼리를 작성 할 때 빠른 쿼리문도 좋지만 각 상황에 따라서 요구가 되는 쿼리문이 다를 것이다. 배치를 돌리는 쿼리문에서는 Throughput 을 OLTP 쿼리문은 Time이 중요할 것이다. 따라서 해당 옵티마이저에게 우리가 원하는 GOAL을 지정해 줄 수 있다.
/*+ ALL_ROWS */
해당 이름만 봐도 알 수 있듯이 best Thorughput 을 낼 때 사용하는 것이다. index Scan 이 아닌 Full Table Scan을 사용하고자 할 때 사용한다. 해당 힌트절을 사용하게 되면 NL-join이 아닌 Hash-join을 선호하게 된다.
/*+ FIRST_ROW */
해당 조건에 어울리는 첫 번째 Row를 반환하는 방식이다.
만일 해당 쿼리가 order 절에 인덱스 컬럼으로 조회하는 부분이 있다면 Sort 과정을 피해서 index를 통해 결과를 가져올 수 있다. 해당 힌트절은 Sort-merg join 보다는 NL-join을 선호한다.
/*+ CHOOSE */
Optimizer가 CBO(Cost-Based optimization) , RBO(Rule-Based optimization) 을 할 지 결정하는 것이다. 앞에서 오라클을 배웠을 때 테이블, 인덱스, 통계자료 같은 메타 데이터에 대해 정보를 가지고 있는 Dictionary Cache에 접근하여 해당 쿼리에 대한 데이터를 가지고 있는지 확인한다. 만일 데이터가 없다면 RBO를, 데이터가 존재하게 된다면 CBO를 목표로 하게 된다.
/*+ RULE *+/
말 그대로 RULE 기반을 목표로 하는 기법이다. 현재는 잘 쓰이지 않은 기법이기도 하며 1~10 우선순위가 있지만 그 중에서 3가지 정도를 소개하려고 한다.
ROW_ID에 의한 single row accesscluster join에 의한 single row accessunique key를 가지는 hash cluster에 의한 single row access
Access Methods 에 대하여
/+ FULL(table_name) */ + /+ PARALLEL(table_name, degree) */
테이블을 가져올 때 Full Scan으로 가져오는 것이 해당 db를 다른 db로 마이그레이션 할 때 자주 봤던 힌트절이며 추가적으로 Parallel 하게 보내기 위해 사용한다. degree는 서버 프로세스의 개수를 의미하며 해당 System의 CPU에 따라 설정을 달리 해야 한다.
/+ INDEX(table_name index_name) / + ASC , DESC
테이블을 가져올 때 해당 인덱스를 사용하여 Random Access하게 가져오는 방법이다.
INDEX_ASC , INDEX_DESC 처럼 해당 인덱스를 오름차순으로 쓸지 , 내림차순으로 사용할지 정살 수 있다.
/+ INDEX_FFS(table index) /
일반 INDEX와는 다른 점은 SING BLOCK ACCESS에서 MULTI BLOCK ACCESS를 한다는 것이다. 당연히 여러 블럭을 읽어드리기 때문에 속도면에서 빠르지만 컬럼의 순서를 보장할 수 없다는 단점이 있다.
/*+ *_AJ , *_SJ */
우선 AJ(ANTI JOIN) , SJ(SEMI JOIN) 앞에는 HASH , MERGE 가 올 수 있으며 WHERE 절 중에서 NOT IN 혹은 NOT EXIST 를 사용하면 AJ , IN , EXIST 를 사용하면 SJ 라고 한다. 우리는 서브쿼리로 작성되어 있는 부분을 조인으로 풀면 대부분의 경우 속도 개선한다고 믿는다. 따라서 우리는 WHERE 절에 IN , EXIST 로 이루어진 서브쿼리를 메인 쿼리와 조인시키려고 한다. 이 때 사용하는 것이 _AJ , _SJ 이며 이때 풀어지는 것을 UNNEST 라고 한다.
밑에서 UNNEST와 MERGE에 대해 더 자세히 알아보자.
/*+ APPEND , APPEND_VALUES */
배치 프로그램을 작성하는 도중에 많이 본 힌트문이다. APPEND를 공부하다가 APPEND_VALUES 라는 힌트가 있다는 것을 알았고 이것에 대한 많은 오해와 진실을 파해치는 시간을 가져보도록 하자.
INSERT … SELECT문에 APPEND 속성은 주로 다이렉트 로드 인서트라고 한다.
기본 APPEND 는 Serial 다이렉 로드 인서트라고 하며 이 때 Parrel으로 저장하기 위해 PARALLEL 옵션을 주면 페러렐 다이렉 로드 인서트라고 한다.
다이렉트 로드 인서트는 데이터를 가져올 때 데이터를 가져오고 나서 로그, 버퍼와 캐시를 사용하지 않고 바로 데이터 파일을 다른 테이블에 넣는 작업을 진행한다. 또 한 바로 테이블에 넣는 것이 아닌 TEMPARY 공간인 HWM(하이워터 마크) 공간에 저장해두고 ISNERT문이 끝나면 MERGE 하는 형식이다. ( 따라서 DELETE가 자주 발생하는 테이블에는 오히려 독이다.)
단점으로는 해당 테이블에 베타 락이 걸려 다른 트랜잭션이 수행할 수 없다는 점이다.
APPEND 힌트는 아래와 같은 두 가지 경우에만 NO-LOGGING을 하게 된다.
1) NOARCHIVELOG 모드 데이터베이스가 사용되고 있는 경우
2) NOLOGGING으로 표시된 테이블을 대상으로 작업하고 있는 경우
하지만 현업에서는 DB복구를 위해 아카이브 로그와 LOGGING을 주로 하는 상태라 NO-LOGGING을 하기 힘든 상태이다.
또 한 넣고자 하는 테이블에 인덱스가 존재한다면 해당 테이블에 데이터가 들어올때마다 인덱스 테이블 생성으로 인한 리소스 낭비도 심하게 될 것이다.
첫번째 대안책 : 삽입할 테이블의 INDEX 비활성화
임시적으로 NO-LOGGING 을 할 수 없게 되어 해당 테이블의 INDEX를 비활성화를 하고 나서 데이터를 다 넣고 활성화 하는 방식이며 어느정도의 리소스 낭비를 방지 할 수 있다.
인덱스 비활성화를 하지 않는다면 APPEND 는 의미없는 힌트일까?
아니다. 앞에서 말했던 것처럼 로그만 작성하느 것이 아닌 버퍼와 캐시와도 관련이 있다.
로깅을 하더라도 어느정도 REDO 버퍼에 작성하는 양이 적어지며 버퍼 캐시에 저장하는 일련의 과정이 없어지기 때문에 현업에서 쓸 정도로 효과가 있다. 테스트는 아래의 사이트를 참고하면 좋다.
참고 :
APPEND 힌트는 쓸모 없는 것일까?
APPEND 에 대한 부연 설명
APPEND 힌트를 잘 사용하는 방법
APPEND 힌트에 대한 오해와 진실
추가적으로
insert values 구문에서는 오직 APPEND_VALUES 힌트만 Direct Path I/O 가 가능 하고 insert select(sub query) 구문에서는 APPEND 힌트만 Direct Path I/O 가 가능 하다 라고 정의 되어 있지만 하위 버전의 호환성 (Backward compatibility) 을 위하여 APPEND_VALUES 힌트에는 APPEND 힌트 기능이 포함되어있다.
/*+ USE_CONCAT */ , /*+ NO_EXPAND */
이번에 프로젝트를 하면서 마주친 힌트절이다. 익숙하면서도 위험성이 높은 힌트절이기도 하다.
우선적으로 USE_CONECAT은 조건절에 있는 OR 연산자 조건 또는 IN 연산자 조건을 만나면 해당 쿼리문을 UNION ALL 로 풀어내는 방식을 말한다.
처음에는 각 OR절에 해당하는 컬럼들이 INDEX컬럼이면 각 INDEX를 타게 하여 연산량을 줄이는 줄 알았다. (복합 INDEX라고 하더라도 각 인덱스 별로 나누면 더 느리게 되어있다.)
결과론적으로는 UNION ALL을 통해서 쿼리를 풀게 되면 해당 SELECT 결과문을 SORT JOIN 및 NEST LOOP 를 하는 과정에서 더 많은 자원을 사용하게 된다.
반대로 NO_EXPAND는 해당 OR,IN 절을 펼치지 말라는 조건이다. 현재 오라클 버전업이 되면서 IN-LIST 절이 UNION-ALL 보다 무조건 효율적이다. (DB에서 무조건이라는 말이 없다고 생각했는데 의외였다..)
프로젝트가 차세대이다 보니까 RBO를 타던 쿼리가 CONCAT 하는 것을 방지하려고 사용한 것 같으며 현재는 NO_EXPAND를 사용하지 않더라고 자동적으로 IN-LIST 형태로 풀어낸다.
CONCAT 에 대하여
IN-LIST 와 BETWEEN 비교
-> 연속적인 범위에 대해서 조회하는 경우에는 BETWEEN 을 사용하는 것이 효율적이다. :0
Join Orders 에 대하여
자주 사용하는 join Orders는 다음과 같으며 어떤 테이블을 Driving Table로 지정할 것인지에 대해 다룬다.
/*+ ORDERED */
From절에 기술된 테이블 순서대로 join이 일어나도록 유도하며 맨 앞에 선언 되어 있는 테이블이 Driving Table로 선언된다.
/*+ LEADING */
From절이 아닌 Leading 절에 기술된 테이블 순서대로 join이 일어나도록 유도하며 맨 앞에 선언 되어 있는 테이블이 Driving Table로 선언된다.
추가적인 힌트절에 대하여
/+ CASHE */ , /+ NOCASHE */
테이블 FULL SCAN시에 가져온 데이터에 대해서 BUFFER CASHE LRU LIST 중에서 LIST 앞단에 데이터를 넣는 것이다. 따라서 해당 데이터가 오랫동안 버퍼 캐시에 올라갈 수 있는 것이고 NOCASHE 를 사용하면 LIST 뒷단에 넣게 되어 바르게 교체 될 가능성이 높다.
/+ UNNEST */ , /+ NO_UNNEST */
서브쿼리로 선언된 부분이 있다면 메인쿼리 레코드를 하나 읽고 서브쿼리에서 비교하는 작업을 하다보니 비효율이 발생한다. 따라서 서브쿼리를 메인 뷰와 조인을 하여 더 나은 실행계획을 가지고자 하는 것이다.
select * from emp
where deptno in ( select deptno
from dept )위와 같은 코드가 있다면
select * from emp A, ( select dept from dept ) B
where A.deptno = B.deptno와 같은 코드로 변경되고 이후에 merge 작업을 통해서 서브쿼리를 지우는 방식을 진행하게 된다.
특정하게 HASH_SJ , HASH_SJ , 해시 아우터 조인에서 아우터 표시가 붙어있지 않은 컬럼이 먼저 테이블을 불러와 DRIVING 테이블을 하게 된다. 따라서
SWAP_JOIN_INPUTS(TABLE)을 통해서 DRIVING 테이블을 지정해 줄 수 있다.
NO_SWAP_JOIN_INPUTS(TABLE) 은 해당 테이블을 DRIVEN 테이블로 지정하는 힌트절이다.
왜 NO_UNNEST 가 존재 하는 것일까?
앞서 우리가 작성한 서브쿼리절에 NO_UNNEST를 사용하게 되면 해당 서브쿼리는 FILTER로 실행되게 된다. 해당 서브쿼리 캐싱하는 것도 있지만 세미조인에서의 캐싱기법이랑 같아 캐시에서는 속도 개선을 할 수 없다. 하지만 레코드 하나와 서브쿼리를 비교하는 작업보다 FILTER로 걸러지는 레코드가 많다면 NO_UNNEST가 더 빠른 쿼리문이 존재한다.
/*+ PUSH_SUBQ */
앞에서 말한 것처럼 서브쿼리는 필터방식으로 진행되고 쿼리가 작동되는 방식중에서 서브쿼리가 마지막에 작동한다. 앞서 말한 것 처럼 filter로 걸러진 레코드가 많다면 마지막에 작동하는 것이 아닌 먼저 실행하기 위한 힌트절이다.
따라서 NO_UNNEST 와 힌트절과 짝궁으로 많이 쓰이는 쿼리문이다. NO_PUSH_SUBQ 는 메인 쿼리부터 먼저 수행하라는 힌트절이다.
/+ MERGE */ , /+ NO_MERGE */
앞에서 말했던 것처럼 FROM 절에 인라인 뷰는 메인뷰와 조인을 하려고 한다.
우선적으로 단순뷰 와 복합 뷰로 나뉘게 되는데
단순뷰는 간단한 조건과 조인절만 사용된 경우를 말하며
복합 뷰는 쿼리에서 group by , distinct 쿼리가 들어가 있는 경우를 말하며 _complex_view_merging 파라미터를 true 일 경우 merging 이 일어난다.
이런 복합 뷰 보다 더 심한 집한 연산자(union , intersect , minus) 와 group by 없이 집계함수를 사용하는 경우 , 분석함수 , ROWID 를 사용하는 경우 에는 일어나지 않는다.
우리는 대부분 조인으로 풀어냈을때 좀 더 나은 실행계획을 세울 수 있다고 생각한다. 하지만 뷰 머지를 통해서 조인을 하게 된 경우보다 서브쿼리로 조건으로 해당 테이블을 많이 FILTER 한 경우 조인시에 적은 컬럼들과 매핑이 되므로 더 좋은 실행계획을 가질 수 있다.
따라서 만약 VIEW MERGE 를 하지 못했다면 두번째로 조건절 PUSHING을 사용한다.
/*+ 조건절 PUSHING */
조건절 PUSHING 에는 아래와 같이 3가지로 나눌 수 있다.
1. 조건절 PUSHDOWN : 쿼리 블럭 밖에 있는 조건들을 쿼리 블록 안쪽으로 넣는 것을 말한다.
2. 조건절 PULLUP : 쿼리 블록 안에 있는 조건들을 쿼리 블록 밖으로 내오는 것을 말하고 그것을 다른 쿼리 블록에 PUSHDOWN 하는데 사용 할 수 있다.
3. 조인조건 PUSHDOWN : NL 조인 수행 중에 드라이빙 테이블에서 읽은 값은 조건인 Inner 쪽(=right side) 뷰 쿼리 블록 안으로 밀어 넣는 것을 말한다.
조건절 Pushdown과 Pulup은 항상 더 나은 성능을 보장함으로 별도의 힌트를 제공하지 않고 옵티마이저가 자동으로 실행한다. 하지만 조인 조건(Join Predicate) 은 성능이 나빠질 수 도 있기때문에, 제어할수 있도록 push_pred와 no_push_pred 힌트를 제공한다.
push_pred : 조인 조건 Pushdown을 유도한다.
no_push_pred : 조인 조건 Pushdown을 방지한다.
힌트절 파트를 마무리 하며😀
단순히 힌트절에 대해 공부해 보았다가 아닌 실제 현업에서 IO를 많이 잡아먹는 쿼리를 Hint절을 통해서 성능 개선을 해 보았다는 것이 추후에도 도움이 될 것 같다.
하지만 이론과 현업과는 다르듯이 조인절에 =를 사용했을 때 unique index를 타는 것이 아닌 range index를 타거나 select 해오는 특정 컬럼이 추가되는 경우 index를 타지 않는 등 더 여러가지 경험을 쌓으면서 익숙해지고 싶다 💪
-> 복합 인덱스로 이루어진 테이블에서 하나의 인덱스를 사용하거나 BETWEEN , LIKE에 INDEX를 사용하는 경우에 발생한다. :)
