Class 와 객체의 차이는?
클래스는 객체를 만들어 내기 위한 틀이고 객체는 소프트웨어 세계에 구현할 대상이자 개별적으로 구분할 수 있는 실체다. 객체는 클래스로 부터 만들어진다.
객체와 인스턴스
인스턴스는 클래스로 부터 생성된 객체다. 객체는 소프트웨어 세계에 구현할 대상이고, 이를 구현하기 위한 설계도가 클래스이며, 이 설계도에 따라 생성된 실체가 인스턴스이다.
Overloading 과 Overriding 의 차이는?
- 오버로딩: 다중 정의
- 오버라이딩: 재정의
오버로딩 특징
두 함수의 이름이 같지만 인자의 수나 자료형이 다름으로, 같은 이름의 함수로 다중 정의가 가능하다.
오버라이딩 특징
상위 클래스의 함수 이름과 signature 가 같은 함수를 하위 클래스에 재정의 하는 것이다. 상속 관계에 있는 클래스 간의 같은 이름의 함수를 정의한다.
Garbage Collector 에 대해 설명하라
메모리 기법 중 하나로, 프로그램이 동적으로 할당했던 메모리 영역에서 필요없게 된 영역의 데이터(어떤 변수도 가르키지 않는 영역)를 지워버리는 기능이다.
GC 가 실행 될 때는, GC 를 실행하는 쓰레드를 제외한 모든 쓰레드들이 작업을 멈춘다.
Mark & Sweep
GC 가 스택의 모든 변수/객체를 스캔 하면서 각각 어떤 객체를 참고하고 있는 지 찾는 과정이 Mark.
이후 Mark 되어 있지 않은 객체 틀에서 제거하는 과정이 Sweep.
OOP 에 대해 설명하라
객체지향 프로그래밍은 컴퓨터 프로그래밍 패러다임(견해, 사고법)의 하나로, 프로그래밍에서 필요한 데이터를 추상화 시켜서 상태(속성, 어트리뷰트)와 행위(메서드)를 가진 객체 로 만들고, 그 객체간의 상호작용을 통해 로직을 구성하는 방법.
객체지향 프로그래밍이란 인간 중심적 프로그래밍 패러다임이라고 할 수 있다. 즉, 현실 세계를 프로그래밍으로 옮겨와 프로그래밍하는 것을 말한다. 현실 세계의 사물들을 객체라고 보고 그 객체로부터 개발하고자 하는 애플리케이션에 필요한 특징들을 뽑아와 프로그래밍 하는 것이다.
4가지 특성:
-
Encapsulation
클래스 안에 데이터의 상태와 행동을 정의하는 것.
코드를 수정없이 재활용 하는 것을 목적으로 함.
클래스라는 캡슐에 기능과 특성을 담아 묶는다. 목적을 기준으로 묶는다.Information hiding (은닉화)은 캡슐화의 일부라고 볼 수 있으며, 목적으로 묶인 캡슐 안을 사용자는 볼 수 없다는 것이 은닉화.
-
Abstration
다른 객체들의 공통적인 요소 및 필수적인 요소를 정리하여 큰 틀의 클래스의 넣는 것
예: 아반떼, 소나타, 그랜져 등 여러 종류의 차종을 다 클래스화 한 후 변수, 함수를 개별적으로 만드는 것은 비효율적. 따라서 공통/필수적인 요소를 끄집어내 큰 틀의 클래스로 만드는 것이 추상화 -
Polymorphism
같은 동작이지만 다른 결과물이 나오는 것
특정 기능을 설계 부분과 동작 부분으로 분리한 후 동작 부분을 다양한 방법으로 만들어 선택하여 사용할 수 있게 하는 기능
코드의 재사용, 코드 길이 감소, 유지보수가 용이하도록 도와주는 개념대표적인 예가 오버로딩, 오버라이딩.
-
Inheritance
클래스로부터 속성과 메서드를 물려받는 것을 말함.
다른 클래스를 가져와서 수정할 일이 있다면, 그 클래스를 직접 수정하는 대신 상속을 받아 새로운 기능을 추가하거나, 변경하고자 하는 부분만 변경
장점
- 추상화와 상속으로 인한 코드의 재사용성
- 라이브러리가 제공하는 기능들의 사용으로 높은 생산성
- 객체 단위로 코드가 나눠져 작성되기 때문에 디버깅이 쉽고 유지보수에 용이하다.
단점
- 객체 간의 정보 교환이 모두 메시지 교환을 통해 일어나므로 실행 시스템에 많은 overhead 가 발생
- 객체가 상태를 가지고 있어 변수가 존재하고 이 변수를 통해 객체가 예측할 수 없는 상태를 갖게 되어 애플리케이션 내부에서 버그를 발생
OOP의 5가지 법칙 (SOLID)
-
Single Responsibility Principle, 단일 책임 법칙
각 클래스는 목적을 하나씩만 가지고 그에 대한 책임을 져야 한다. -
Open Close Principle, 개방 폐쇄 법칙
각 클래스는 클래스에 대한 수정을 폐쇄하고, 확장에 대해 개방해야 한다.
즉 클래스를 수정해야 한다면 그 클래스를 상속, 즉 확장하여 수정한다 -
Liskov Substitusion Principle, 리스코프 치환 법칙
자식 클래스를 사용 중일때, 거기에 부모 클래스로 치환하여도 문제가 없어야 한다. -
Interface Segreation Principle, 인터페이스 분리 법칙
각 행위에 대한 인터페이스는 서로 분리되어야 한다.
핸드폰을 예로 들면, 전화를 하는데 핸드폰 카메라가 방해가 되면 안된다는 말. -
Dependency Inversion Principle, 의존성 역전 법칙
상위 클래스가 하위 클래스에 의존하면 안된다는 법칙. 즉 기본적인 공통되는 속성을 하위 클래스에 의존하면 안된다.
프로세스와 쓰레드의 차이는?
프로세스는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램이고 쓰레드는 프로세스 내에서 실행되는 여러 흐름의 단위이다.
프로세스는 CPU, 주소 공간, 그리고 Code, Data, Stack, Heap의 구조로 되어 있는 독립된 메모리 영역을 할당 받고 쓰레드는 Stack만 할당 받고 나머지 영역은 공유 한다.
둘의 차이점은 프로세스가 다른 프로세스에 접근하기 위해선 프로세스간의 통신이 필요하지만 같은 프로세스 안에 있는 쓰레드들은 힙을 공유하기 때문에 접근할 수 있다.
Restful 이란?
REST란 REpresental State Transfer의 약자
자원을 표현하여 상태를 전달한다는 뜻으로, 웹에 있는 자원을 HTTP를 통하여 직관적으로 전달하기 위한 간단한 인터페이스이다.
Restful API는 대부분의 데이터를 JSON형식이나 XML형식을 담아서 HTTP 프로토콜 위에서 통신하는 API 인 것이다.
HTTP 요청 흐름에 대해서 설명하라* (웹브라우저에서의 요청)
브라우저
브라우저에서 먼저 URL에 적힌 값을 파싱하여, HTTP 요청 메세지를 만든다. 만든 메세지를 웹 서버로 전송하는데, 이때 웹 브라우저 직접 전송을 하는것이 아니라 OS에 보내달라고 의뢰를 하게 된다. OS는 DNS서버를 조회해서 Host이름을 보내야 할 IP 주소로 변환하게 된다.
프로토콜 스택, LAN 어댑터
프로토콜 스택(운영체제에 내장된 네트워크 제어용 소프트웨어, TCP/IP 계층)과 LAN 어댑터 에서 (1)브라우저로부터 메시지를 받는다. 브라우저로부터 받은 메시지를 (2)패킷 속에 저장한다. 그리고 수신 주소를 제어정보에 덧붙인다. 그 다음, 패킷은 (3)LAN 어댑터에 넘긴다. LAN 어댑터는 (4)패킷을 전기 신호로 변환시켜 LAN 케이블에 송출하게 된다.
프로토콜 스택은 통신 중 오류가 발생했을 때, 이 제어 정보를 사용하여 고쳐 보내거나, 각종 상황을 조절하는 등 다양한 역할을 하게 된다. 네트워크 세계에서는 비서가 있어서 우리가 비서에게 물건만 건네주면, 받는 사람의 주소와 각종 유의사항을 써준다! 여기서는 프로토콜 스택이 비서의 역할을 한다고 볼 수 있다.
허브, 스위치, 라우터
허브, 스위치, 라우터 에서 (1)LAN 어댑터로부터 송신한 패킷을 수신한다. 라우터는 패킷을 (2)ISP에 전달, 인터넷으로 들어가게 된다.
액세스 회선
액세스 회선이라는 것은 인터넷의 입구에 있는 통신 회선이다. 액세스 회선에 의해 (1)통신사용 라우터(POP, Point Of Presence)까지 운반된다. (2)POP를 거쳐 인터넷의 핵심부로 들어가게 된다. (3)고속 라우터들 사이로 목적지까지 패킷이 흘러가게 된다.
방화벽, 캐시서버
인터넷 핵심부를 통과한 패킷은 목적지의 LAN에 도착하게 된다. 방화벽이 먼저 패킷을 검사한 후, 캐시서버로 보내서 웹 서버까지 갈 필요가 있는지 검사한다.
굳이 서버까지 가지 않아도 되는 경우를 골라낸다. 액세스한 페이지의 데이터가 캐시서버에 있으면 웹 서버에 의뢰하지 않고 바로 그 값을 읽을 수 있다. 페이지의 데이터 중에 다시 이용할 수 있는 것이 있으면 캐시 서버에 저장된다.
웹 서버
패킷이 물리적 웹 서버에 도착하면, 웹 서버의 프로토콜 스택이 패킷을 추출하여 메시지를 복원하고, 웹 서버 애플리케이션에 넘긴다. 애플리케이션은 요청에 대한 응답 데이터를 넣어 클라이언트로 회송한다. 온 방식 그대로 전송되게 된다.
브라우저 렌더링 과정에 대해 설명하라*
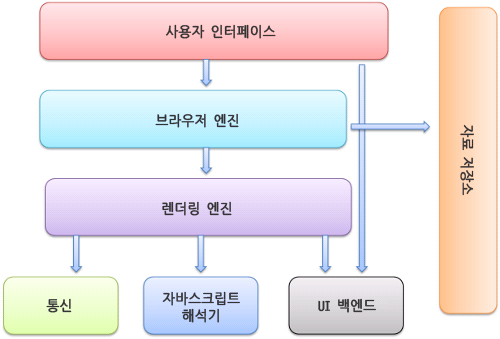
브라우저 주요 구성 요소
- 사용자 인터페이스 (UI)
주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등. 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분 - 브라우저 엔진
사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어 - 렌더링 엔진
요청한 콘텐츠를 표시. 예를 들어 HTML을 요청하면 HTML과 CSS를 파싱하여 화면에 표시함. - 통신
HTTP 요청과 같은 네트워크 호출에 사용됨. 이것은 플랫폼 독립적인 인터페이스이고 각 플랫폼 하부에서 실행됨. - UI 백엔드
콤보 박스와 창 같은 기본적인 장치를 그림. 플랫폼에서 명시하지 않은 일반적인 인터페이스로서, OS 사용자 인터페이스 체계를 사용. - 자바스크립트 해석기
자바스크립트 코드를 해석하고 실행. - 자료 저장소
이 부분은 자료를 저장하는 계층이다. 쿠키를 저장하는 것과 같이 모든 종류의 자원을 하드 디스크에 저장할 필요가 있다. HTML5 명세에는 브라우저가 지원하는 '웹 데이터 베이스'가 정의되어 있다.
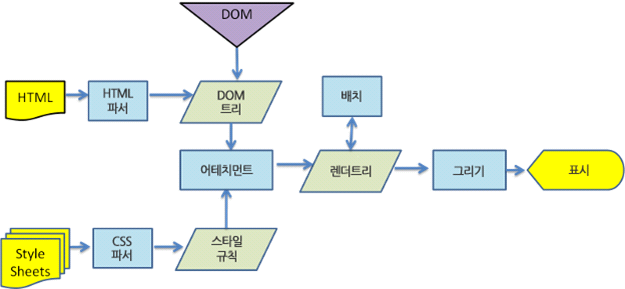
렌더링 엔진 동작 과정

1. DOM 트리 구축을 위한 HTML 파싱
페이지를 이동하는 내비게이션 실행 메시지를 렌더링 엔진이 받고 HTML 데이터를 수신하기 시작하면 렌더링 엔진의 메인 스레드는 문자열(HTML)을 파싱해서 DOM(document object model)으로 변환하기 시작한다.
2. 렌더 트리 구축
외부 CSS 파일과 함께 포함된 스타일 요소도 파싱한다. CSS 파싱이 끝나면 중단된 HTML 을 다시읽고 DOM 트리를 완성한다. 완성된 DOM 트리와 CSSOM 트리를 합쳐 스타일 정보와 HTML 표시 규칙으로 "렌더 트리"라고 부르는 또 다른 트리를 생성한다.
3. 렌더 트리 배치 및 그리기
렌더 트리 생성이 끝나면 배치가 시작되는데 이것은 각 노드가 화면의 정확한 위치에 표시되는 것을 의미한다. 다음은 UI 백엔드에서 렌더 트리의 각 노드를 가로지르며 형상을 만들어 내는 그리기 과정이다.
잠깐, 자바스크립트는?
<script> 태그를 만나면 HTML 파서는 HTML 문서의 파싱을 일시 중지한 다음 JavaScript 코드를 로딩하고 파싱해 실행해야 한다.
왜?
JavaScript는 DOM 구조 전체를 바꿀 수 있는 document.write() 메서드와 같은 것을 사용해 문서의 모양을 변경할 수 있기 때문이다.
고로 HTML 파싱을 재개하기 전에 HTML 파서는 JavaScript의 실행이 끝나기를 기다려야 한다.
MVC 구조란?
모델-뷰-컨트롤러의 약자로, 디자인 패턴의 하나이다. 비즈니스 처리 로직과 사용자 인터페이스를 구분시켜 서로 영향없이 개발이 가능하다는 장점이 있다(MVC패턴).
모델(Model)은 어플리케이션이 "무엇"을 할 지에 대한 정의한다. 처리되는 데이터, 데이터베이스, 내부 알고리즘 등 내부 비즈니스에 관한 로직의 처리를 수행한다. 즉 사용자에게 보이지 않는 로직.
뷰(View)는 말 그대로 사용자에게 보여지는 영역이다. JSP등 사용자 인터페이스를 담당한다.
컨트롤러(Controller)는 모델에게 "어떻게"할 것인지를 알려주며, 모델과 뷰 사이를 연결하는 역할을 한다. 사용자의 입출력을 받아 데이터를 처리한다.
CSS Box Model에 대해서 설명하라
CSS에서 Position의 사용법을 설명하라
HTTP와 HTTPS의 차이는?
HTTP
- 하이퍼 텍스트 전송 프로토콜의(Hypertext Transfer Protocol)의 약자
- 서로 다른 시스템들 사이에서 통신을 주고받게 해주는 가장 기초적인 프로토콜
HTTPS
- 하이퍼 텍스트 전송 프로토콜 보안(Hypertext Transfer Protocol Secure)의 약자
- 일반 HTTP 프로토콜의 서버에서부터 브라우저로 전송되는 정보가 암호화 되지 않는다는 문제점을 SSL(보안 소켓 계층)을 사용해서 해결
SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결을 만들 수 있게 도와주고, 서버 브라우저가 민감한 정보를 주고받을 때 이것이 도난당하는 것을 막아줍니다.
SSL 인증서는 사용자가 사이트에 제공하는 정보를 암호화하는데, 쉽게 말해서 데이터를 암호로 바꾼다고 생각하면 쉽다. 이렇게 전송된 데이터는 중간에서 누군가 훔쳐 낸다고 하더라도 데이터가 암호화되어있기 때문에 해독할 수 없다.
LocalStorage, SessionStorage, Cookie의 차이점은?
HTML5 에는 웹의 데이터를 클라이언트에 저장할 수 있는 새로운 자료구조인 Web Storage 스펙이 포함되어 있다.
Web Storage의 개념은 키/값 쌍으로 데이터를 저장하고 키를 기반으로 데이터를 조회하는 패턴이다.
그리고 영구저장소(LocalStorage)와 임시저장소(SessionStorage)를 따로 두어 데이터의 지속성을 구분할 수 있어 응용 환경에 맞는 선택이 가능하다.
LocalStorage
- key, value 저장소 이상의 기능은 없고, key 와 value는 String 타입만 지원한다.
- 최대로 저장할 수 있는 용량이 크지 않다. (5MB ~ 10MB)
- localStorage는 일부러 지우지 않는다면 브라우저를 닫고 열어도 계속 남아있다.
- 사용예제 : 지속적으로 필요한 데이터(자동 로그인 등)
SessionStorage
- 사용 방법은 localStorage 와 동일하나, 데이터들이 영구적이지 않고 브라우저를 닫거나 새 탭을 열면 초기화 된다.
- 하지만 같은 탭에서 새로고침을 하면 초기화 되지 않는다.
- 사용예제 : 잠깐 동안 필요한 정보(일회성 로그인 정보), 자동 임시 저장
Cookie
- 만료기한이 있는 key-value Storage
- 쿠키는 하나의 도메인 페이지에서 최대 20개, 4KB의 용량제한이 존재
- 매 요청마다 서버로 쿠키가 같이 전송(쿠키는 처음부터 서버와 클라이언트 간의 지속적인 데이터 교환을 위해 만들어졌기 때문)된다.
- Web Storage 와 다르게 데이터 유효기간 설정 가능
TCP와 UPD를 비교하라
전송계층에서 사용하는 프로토콜로써, 목적지 장비까지 전송한 패킷을 상위의 특정 응용 프로토콜에게 전달하는 것
전송 계층 Transport Layer
송신자와 수신자를 연결하는 통신 서비스를 제공하는 계층으로, 쉽게 말해 데이터의 전달을 담당
전송 계층이 없다면?
1. 데이터 순차 전송에 어려움
2. Flow 문제 (송수신자 간의 데이터 처리 속도 차이)
3. Congestion 문제 (네트워크 데이터 처리 속도)
TCP
연결형 서비스를 지원하는 전송 계층 프로토콜로써, 인터넷 환경에서 기본으로 사용한다. 일반적으로 TCP와 IP를 함께 사용하는데, IP가 데이터의 배달을 처리한다면 TCP는 패킷을 추적 및 관리하게 됩니다.
- 신뢰성 있는 데이터 전송
- 데이터의 순차 전송 보장
- Flow control
- Congestion control
UDP
비연결형 서비스를 지원하는 전송계층 프로토콜로써, 인터넷상에서 서로 정보를 주고받을 때 정보를 보낸다는 신호나 받는다는 신호 절차를 거치지 않고,보내는 쪽에서 일방적으로 데이터를 전달하는 통신 프로토콜
- 비연결형 서비스로 데이터그램 방식을 제공한다
- TCP보다 신뢰성이 떨어지지만 전송 속도가 빠르다
결론
TCP는 연속성보다 신뢰성있는 전송이 중요할 때에 사용하는 프로토콜이며,
UDP는 TCP보다 속도가 빠르며 네트워크 부하가 적다는 장점이 있지만, 신뢰성있는 데이터 전송을 보장하지는 않습니다.
그렇기 때문에 신뢰성보다는 연속성이 중요한 서비스의 예를 들면 실시간 서비스(streaming)에 자주 사용됩니다.
HTTP의 GET과 POST를 비교하라
GET
- 요청하는 데이터를 HTTP Request Message의 Header부분의 URI에 담아서 전송한다.
- URI라는 공간에 담겨서 데이터를 전송하기때문에 데이터 크기가 제한적이고, 보안이 필요한 데이터를 그대로 전송하면 URI에 노출된다.
- GET은 Request를 할 때, 필요한 데이터를 쿼리 스트링에 담아서 전송한다.
- 쿼리 스트링 이란, URL의 끝에 ? 다음으로 Key와 Value로 이루워진 파라미터를 의미한다. 다양한 파라미터를 전송하기 위해서는 &로 연결하면 된다.
- GET은 Request를 할 때, 필요한 데이터를 쿼리 스트링에 담아서 전송한다.
- 브라우저에서 캐싱할 수 있다. 따라서, 데이터 크기가 작고 보안이슈가 없다고 GET요청을 보내면 기존에 캐싱된 데이터가 응답할 가능성이 있다.
POST
- HTTP Message의 Body에 데이터를 담아서 전송한다. 전송할 수 있는 데이터의 크기가 GET방식보다 크고 보안면에서 상대적으로 좋다.(암호화 하지 않는 이상 큰 차이는 없다.)
- 서버의 상태나 값을 변경하거나 추가하는데 사용한다.
차이점:
- GET은 idempotent(멱등), POST는 non-idempotent하다.
- GET은 해당 요청을 몇번을 수행해도 요청에 대한 결과가 계속 동일하게 돌아오는 것을 의미
- POST는 해당 요청이 수행되면 서버에서 무언가가 변경되고, 동일한 결과가 돌아오는 것을 보장할 수 없음을 의미
HTTP의 PUT과 PATCH를 비교하라
PUT
- 리소스의 모든 것을 업데이트 한다.
- 캐싱이 불가능하다.
- 멱등하다. ( 같은 요청이면 반환되는 모든 응답은 동일해야 한다. )
PATCH
- 리소스의 일부를 업데이트 한다.
- 캐싱이 가능하다.
- 멱등하지 않다. ( 같은 요청이라도 응답이 각각 다르다. )
