SQL문은 저장된 데이터를 읽어오는 과정을 편리하게 만들어준다.
WHERE절과 자주 쓰이는 문법
SQL쿼리에서 조건을 지정하여 특정한 행(row)만을 선택할 때 사용된다.
SELECT, UPDATE, DELETE 등의 명령문과 함께 사용되어, 조건을 충족하는 데이터만 처리할 수 있게 한다.
여기에선 데이터를 불러오고(SELECT), 조건에 맞게 필터링(WHERE절)과 자주 쓰이는 문법에 대해 공부해보자.
'같지 않음' 조건 - !=
SELECT * from orders
WHERE course_title != "웹개발 종합반";'범위' 조건 - between
SELECT * from orders
WHERE created_at between "2020-07-13" and "2020-07-15";'포함' 조건 - in
SELECT * from checkins
WHERE week in (1, 3);'패턴' (문자열 규칙) 조건 - like
예를 들어 이메일의 경우
SELECT * from users
WHERE email like '%daum.net';일부 데이터만 가져오기 - Limit
5개가 출력이 된다.
SELECT * from orders
WHERE payment_method = "kakaopay"
limit 5;중복 데이터는 제외하고 가져오기 - Distinct
SELECT distinct(payment_method) from orders;몇 개인지 숫자 세보기 - Count
orders 테이블에 데이터가 몇 개 들어 있는지 확인 가능하다.
SELECT count(*) from orders;[응용] Distinct와 Count 같이 써보기
SELECT count(distinct(name)) from users;Group by, Order by
데이터를 범주에 따라 묶어서 통계치를 구하고(Group by), 정렬하는 것(Order by)을 배워보자.
Group by
동일한 범주를 갖는 데이터를 하나로 묶어서, 범주별 통계를 내준다.
동일한 범주의 개수 구하기
예를들어, 같은 성씨의 데이터를 하나로 묶고, 각 성씨의 회원수를 구할 수 있다.
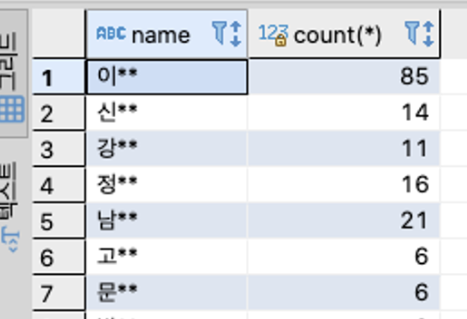
SELECT name, count(*) from users
group by name;위 쿼리가 실행되는 순서: from → group by → select
동일한 범주에서의 최솟값 구하기
SELECT 범주가 담긴 필드명, min(최솟값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;SELECT week, min(likes) from checkins
group by week;동일한 범주에서의 최댓값 구하기
SELECT week, max(likes) from checkins
group by week;동일한 범주의 평균 구하기
SELECT week, avg(likes) from checkins
group by week;동일한 범주의 합계 구하기
SELECT week, sum(likes) from checkins
group by week;Order by
위의 데이터를 정렬할 수 있다.
SELECT name, count(*) from users
group by name;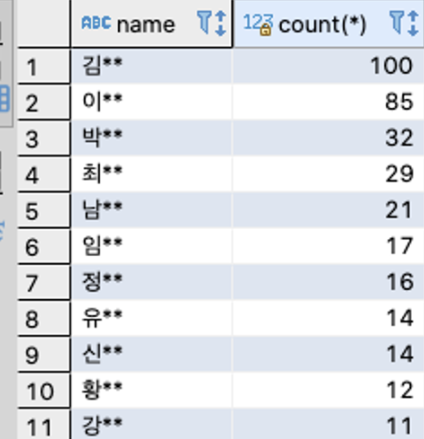
결과의 개수 오름차순 정렬
order by count(); 만 추가해도 count()값을 기준으로 정렬한다.
SELECT name, count(*) from users
group by name
order by count(*);결과의 개수 내림차순 정렬
SELECT name, count(*) from users
group by name
order by count(*) desc;위 쿼리가 실행되는 순서: from → group by → select → order by
order by는 정렬해주기 때문에 맨 나중에 실행이된다.
WHERE와 함께 사용해보기
select payment_method, count(*) from orders
where course_title = "웹개발 종합반"
group by payment_method;위 쿼리가 실행되는 순서: from → where → group by → select
별칭?

Join
두 테이블의 공통된 정보 (key값)를 기준으로 테이블을 연결해서 한 테이블처럼 보일 수 있다. 여러 데이터를 합쳐서 분석(Join) 해볼 수 있다.
Subquery, 그 외
데이터 분석을 위해서 데이터를 원하는 형태로 정리하는 방법(Subquery)을 배워보자.
참고 자료
- 스파르타코딩클럽 엑셀보다 쉬운 sql 강의 자료
https://teamsparta.notion.site/SQL-78066b30b7e1483f9f68d31e7b97ad7e
