앞선 게시글에서 JPA의 기본개념을 알아보았다. 그럼 JPA는 어떻게 DB와 소통을 하며 주어진 요청을 어떻게 처리하는걸까?
영속성 컨텍스트
영속성 컨텍스트는 쉽게 생각해서 Entity를 효율적으로 쉽게 관리하기위해 만들어진 "공간"이다.
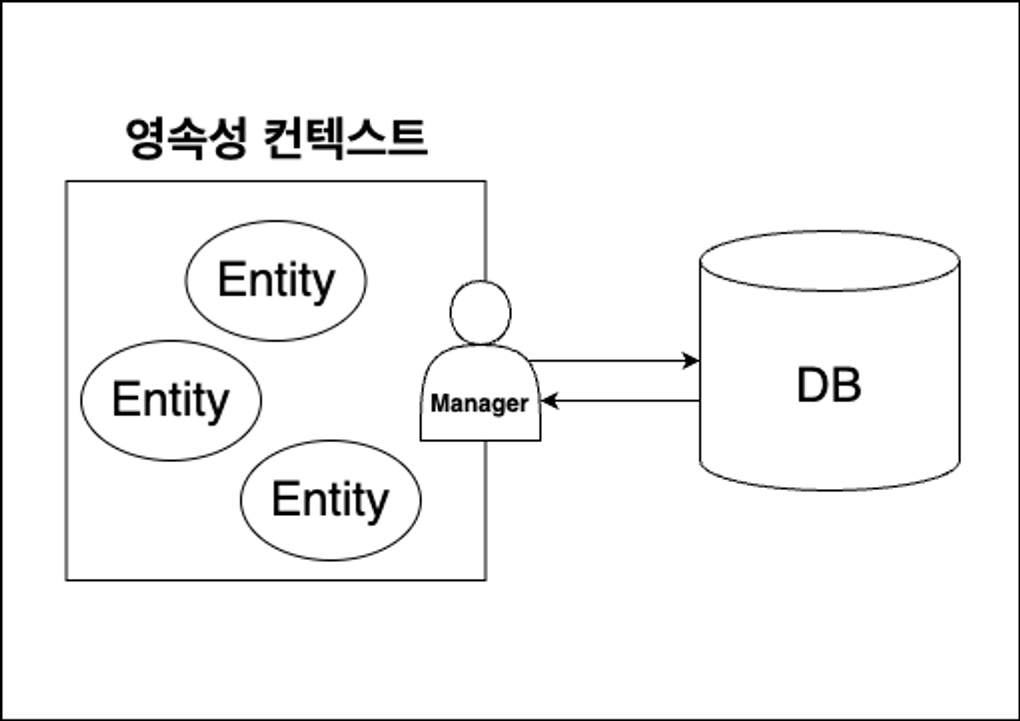
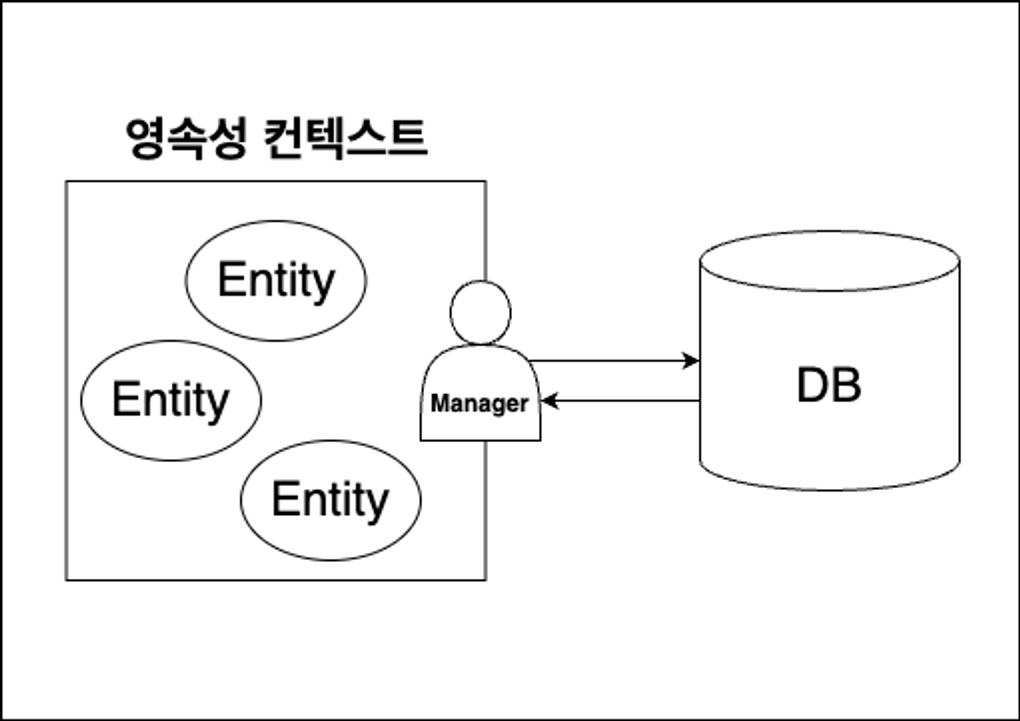
영속성 컨텍스트는 사진과 같이 Manager를 둬서 Entity 객체들을 조작하는데 이 Manager를 EntityManager라 부르며 줄여서 "em"으로 표기 하기도한다. 우리는 이러한 em들을 통해서 Entity를 저장하고 조회하고 수정하며 삭제도 가능하다. 이러한 em을 생성하기위해선 EntityManagerFactory를 통해 생성할수있는데 줄여서 "emf"라 불리는 이것은 일반적으로 DB하나당 하나만 생성되어 애플리케이션 동작중에만 사용된다. em 과 emf를 자바환경에서 사용하기위해 해당 DB설정이 필요하기때문에 persistence.xml파일을 설정해줘야한다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("Entity");
EntityManager em = emf.createEntityManager();위 코드를 사용하여 emf와 em을 생성한후 이를 통해 Entity를 관리한다.
트랜잭션
트랜잭션 : DB 데이터들의 무결성과 정합성을 유지하기 위한 하나의 논리적 개념
JPA는 트랜잭션이라는 개념을 사용하는데 쉽게말해서 모든 SQL이 성공적으로 수행될경우에만 이를 DB에 영구적으로 변경을 반영하지만 SQL 하나라도 실패한다면 모든변경을 다시 되돌린다.
이러한 개념은 영속성 컨텍스트에도 반영되어 아래와 같이 쓰기저장소(Action Queue)를 통해 모든 SQL을 한번에 처리한다.
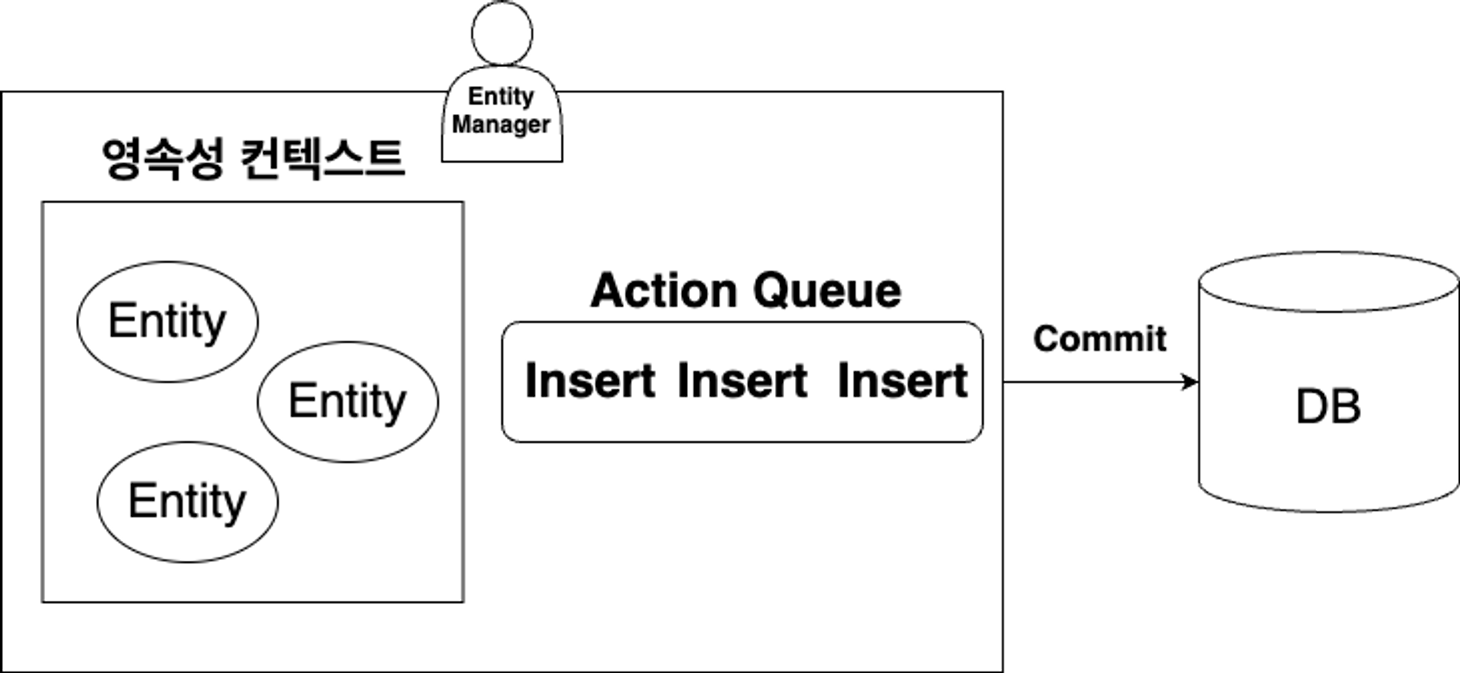
구체적인 코드의 흐름은 아래와 같다.
EntityTransaction et = em.getTransaction(); // EntityManager 에서 EntityTransaction 을 가져옵니다.
et.begin(); // 트랜잭션을 시작합니다.
try {
~~
et.commit(); // 오류가 발생하지 않고 정상적으로 수행되었다면 commit 을 호출합니다.
// commit 이 호출되면서 DB 에 수행한 DB 작업들이 반영됩니다.
} catch (Exception ex) {
et.rollback(); // DB 작업 중 오류 발생 시 rollback 을 호출합니다.
// rollback : 오류가 발생했을 때 트랜잭션의 작업을 모두 취소하고, 이전 상태로 되돌리는 명령어입니다.
} finally {
em.close(); // 사용한 EntityManager 를 종료합니다.
emf.close(); // 사용한 EntityManagerFactory 를 종료합니다.
영속성 컨텍스트의 기능
앞선 영속성 컨텍스트에서 영속성 컨텍스트는 Entity객체를 효율적으로 관리한다고 했는데 어떻게 효율적으로 관리하고있을까?
영속성 컨텍스트는 내부적으로 캐시 저장소를 가지고 있다. 우리가 저장하는 객체들은 캐시 저장소에 저장되며 캐시 저장소의 자료구조는 map 형태로 식별자(Id) key값과 객체 value로 이뤄져있다.
1. Entity 저장
em.persist(Entity);em의 의해 persist메서드가 실행이 되면 해당 엔티티 객체를 캐시 저장소에 저장한다. 그 이유는 앞선 트랜잭션을 생각하면 모든 요청이 성공적으로 실행이 될때에만 마지막으로 commit으로 DB에 반영이 되기때문에 그 동안 저장되는 공간이기 때문이다.
2. Entity 조회
트랜잭션은 DB의 데이터 편집을 할경우 반드시 사용되어야하지만 조회의 경우는 편집이 이뤄지지않기때문에 트랜잭션사용의 필요성은 개발자가 결정할수있다.
em.find(Entity.class, key);조회는 두가지로 나뉘는데
우선적으로 앞선 캐시 저장소에 찾는 Id가 존재하지 않을때 로직을 먼저 알아보자면
1. 캐시 저장소에 해당 Id가 존재하는지 조회 --> 존재x
2. DB SELECT 조회 후 캐시 저장소에 저장 --> DB로부터 캐시저장소로
3. 캐시 저장소에 저장된 값 반환
ID가 캐시저장소에 존재할때
1. 캐시 저장소에 해당 Id가 존재하는지 조회 --> 존재o
2. 캐시 저장소에 저장된 값 반환
지금까지 우리가 클라이언트로부터 요청된 데이터를 매번 DB를 조회하여 반환하였다면 영속성 컨텍스트의 캐시저장소를 이용하면 DB 조회 횟수를 줄일수 있는 장점이있다.
또 다른 장점으로는 자바에서 DB에서 같은 데이터라 할지라도 해당 객체를 인스턴스화 시키게 되면 두개의 주소값은 달라지지만(객체 동일성 훼손) 캐시저장소를 사용하면 주소값은 동일하기 때문에 객체 동일성을 보장할수있다.
3. Entity 삭제
em.remove(entity); Entity 삭제의 경우 트랜잭션을 따라 바로 삭제가 이뤄지는것이 아닌 Deleted상태로 변환 후 commit이 진행되면 삭제가 이뤄진다.
앞서 서술한 쓰기저장소와 같이 영속성 컨텍스트의 특징이 하나더 있는데 그것은 Dirty Checking(변경 감지)이다.
변경 감지는 말그대로 변경이 이뤄진 Enity만 DB에 변경이 요청된다는점인데 어떠한 원리로 이뤄지는지 알아보자.
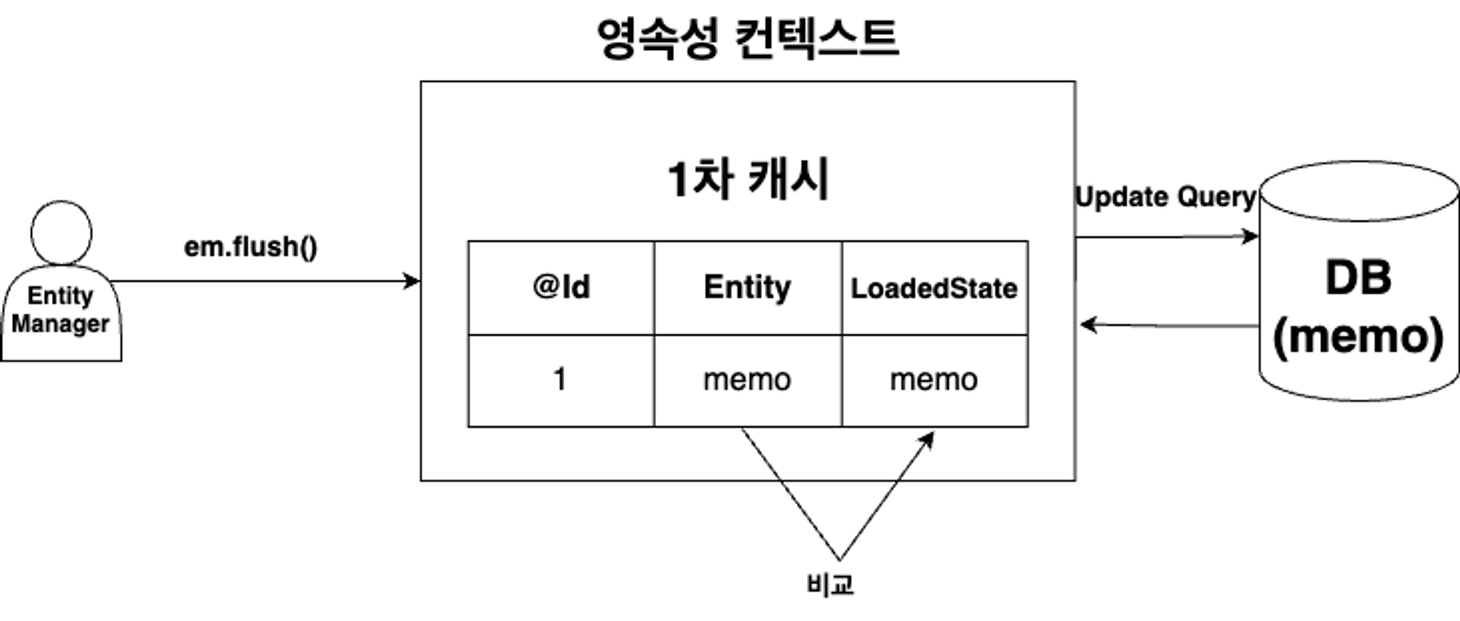
영속성 컨텍스트의 캐시저장소는 ID와 Entity말고도 LoadeState상태를 저장하는 공간이 있는데 이는 최초 Entity가 저장될때 같이 저장되는 공간이다.
트랜잭션이 commit되고 em.flush(); 가 호출되면 Entity 현재상태와 저장한 최초상태를 비교하는데 이때 변경내용이 있으면 Update SQL을 생성하여 쓰기 지연 저장소에 저장하고 모든 쓰기지연 저장소의 SQL을 DB에 요청한다. 이후 마지막으로 DB의 트랜잭션이 commit 되면서 반영이된다.
Diry Checking 또한 DB의 무의미한 반복적 요청을 줄이는데 도움이 된다.
