
지난 게시글에서는 ORM의 탄생이전까지 역사를 얘기했다.그럼 ORM의 특징과 ORM이 풀어나가야될 과제는 무엇이있을까?
ORM은 QueryMapper의 DB의존성 및 중복 쿼리 문제로 탄생하였다고 얘기하였다. ORM은 기존의 문제들을 DAO 또는 Mapper가 아닌 테이블 자체를 하나의 객체(Object)와 대응하였다. 그럼 왜 테이블과 객체를 대응하였을까?
- 객체 지향 프로그래밍의 장점을 활용가능
- 이를 통해, 비즈니스 로직 구현 및 테스트 구현의 편의성
- 각종 디자인 패턴 사용하여 성능 개선 가능
- 코드 재사용
등등.. 이러한 장점이있지만 당연히 객체의 형태가 아닌것을 객체로 대응시킬려니 문제가 발생하게된다.
- 상속의 문제
객체 : 객체간 멤버 변수나 상속관계를 맺을 수 있다.
RDB : 테이블들은 상속관계가 없고 모두 독립적으로 존재한다.
--> 해결방법 : 매핑정보에 상속정보를 넣어준다. (@OneToMany,@ManyToOne)
- 관계의 문제
객체 : 참조를 통해 관계를 가지며 방향을 가진다.(다대다 관계가 존재하기도함)
RDB : 외래키(FK)를 설정하여 Join으로 조회시에만 참조가 가능하다.(즉, 다대다는 매핑 테이블 필요하다.)
--> 해결방법 : 매핑정보에 방향정보를 넣어준다.(@JoinColumn,@MappedBy)
- 탐색의 문제
객체 : 참조를 통해 다른 객체로 순차적 탐색이 가능하며 콜렉션도 순회한다.
RDB : 탐색시 참조하는 만큼 추가 쿼리나, Join 이 발생하여 비효율적이다.
--> 해결방법 : 매핑/조회 정보로 참조탐색 시점을 관리한다.(@FetchType,fetchJoin())
- 밀도의 문제
객체 : 멤버 객체크기가 매우 클 수 있다.
RDB : 기본 데이터 타입만 존재한다.
--> 해결방법 : 크기가 큰 멤버 객체는 테이블을 분리하여 상속으로 처리한다. (@embedded)
- 식별성의 문제
객체 : 객체의 hashCode 또는 정의한 equals() 메소드를 통해 식별
RDB : PK 로만 식별
--> 해결방법 : PK 를 객체 Id로 설정하고 EntityManager는 해당 값으로 객체를 식별하여 관리 한다.(@Id,@GeneratedValue)
이러한 문제들을 여러가지 방법으로 해결하면서 까지 ORM이 대세가 된이유는 뭘까?
ORM은 객체지향 프로그래밍이 가지는 큰 장점인 캐싱기능을 활용하여 1차캐시, 2차캐시를 구현하여 DataSource조회시 최적화를 진행한다.
1차 캐시
- 영속성 컨텍스트 내부에는 엔티티를 보관하는 저장소가 있는데 이를 1차 캐시라 한다.
- 일반적으로 트랜잭션을 시작하고 종료할때까지만 1차 캐시가 유효하다.
- 1차캐시는 트랜잭션이 종료 후 원본객체를 넘겨준다.
2차 캐시
- 어플리케이션 범위의 캐시로, 공유 캐시라고도 하며, 애플리케이션을 종료할 때 까지 캐시가 유지된다.
- 2차 캐시는 캐시 한 객체 원본을 넘겨주지 않고 복사본을 만들어서 넘겨준다.
- 복사본을 주는 이유는 여러 트랜잭션에서 동일한 원본객체를 수정하는 일이 없도록 하기 위해
2차 캐시의 적용 방법
// Entity에 @Cacheable 적용 후 설정 추가 @Entity @Cacheable public class Team { @Id @GeneratedValue private Long id; ... }# application.yml spring.jpa.properties.hibernate.cache.use_second_level_cache: true # 2차 캐시 활성화합니다. spring.jpa.properties.hibernate.cache.region.factory_class: XXX # 2차 캐시를 처리할 클래스를 지정합니다. spring.jpa.properties.hibernate.generate_statistics: true # 하이버네이트가 여러 통계정보를 출력하게 해주는데 캐시 적용 여부를 확인할 수 있습니다. spring.jpa.properties.javax.persistence.sharedCache.mode: ENABLE_SELECTIVE
영속성 컨텍스트(1차캐시)를 활용한 쓰기지연
우선 영속성에 대해 알아보자면 아래와같다.
영속성이란?
데이터를 생성한 프로그램이 종료되어도 사라지지 않는 데이터의 특성을 말한다.
영속성을 갖지 않으면 데이터는 메모리에서만 존재하게 되고 프로그램이 종료되면 해당 데이터는 모두 사라지게 된다.
그래서 우리는 데이터를 파일이나 DB에 영구 저장함으로써 데이터에 영속성을 부여한다.
영속성의 4가지 상태( 비영속 > 영속 > 준영속 | 삭제)
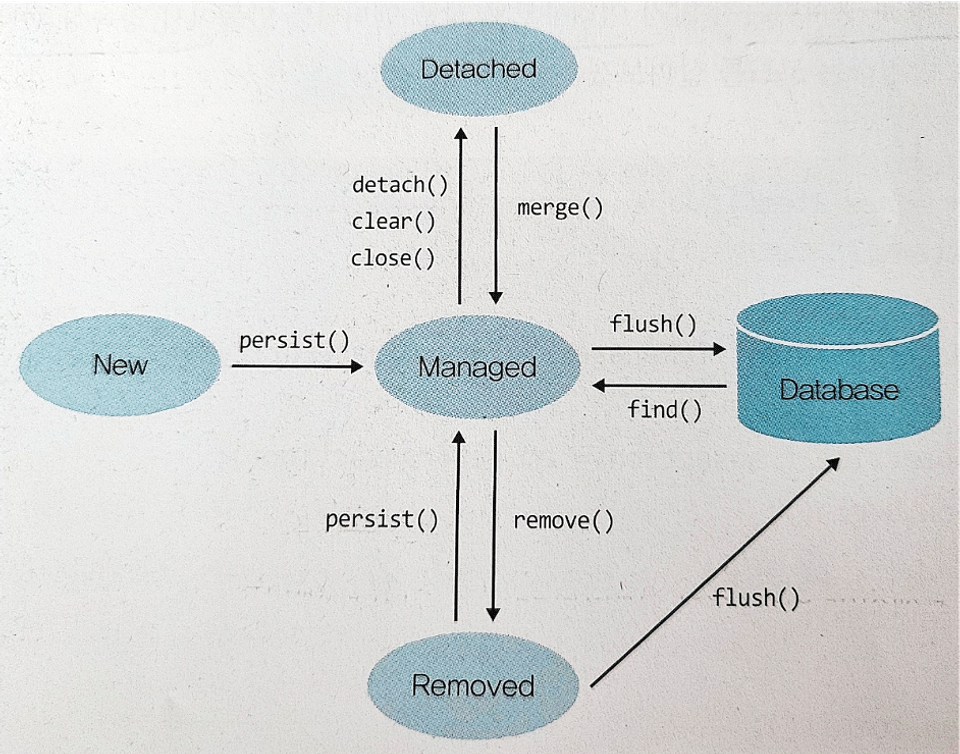
① 비영속(new/transient) - 엔티티 객체가 만들어져서 아직 저장되지 않은 상태로, 영속성컨텍스트와 전혀 관계가 없는 상태
② 영속(managed) - 엔티티가 영속성 컨텍스트에 저장되어, 영속성 컨텍스트가 관리할 수 있는 상태
③ 준영속(detached) - 엔티티가 영속성 컨텍스트에 저장되어 있다가 분리된 상태로, 영속성컨텍스트가 더 이상 관리하지 않는 상태
④ 삭제(removed) - 엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제하겠다고 표시한 상태
persist(),merge() > (영속성 컨텍스트에 저장된 상태) > flush() > (DB에 쿼리가 전송된 상태) > commit() > (DB에 쿼리가 반영된 상태)
다시 돌아와서 영속성을 알아봤으나 그런 영속성을 가지고 무엇을 할수있는데? 라는 질문이 떠오른다. 영속성을 가지고 쓰기지연저장소를 활용하는데 쓰기지연이 무엇이며 어떤 장점이있는지 알아보자.
쓰기지연이 발생하는 시점
- flush() 동작이 발생하기 전까지 최적화한다.
- flush() 동작으로 전송된 쿼리는 더이상 쿼리 최적화는 되지 않고, 이후 commit()으로 반영만 가능하다.
쓰기지연의 장점
- 여러개의 객체를 생성할 경우 모아서 한번에 쿼리를 전송한다.
- 영속성 상태의 객체가 생성 및 수정이 여러번 일어나더라도 해당 트랜잭션 종료시 쿼리는 1번만 전송될 수 있다.
- 영속성 상태에서 객체가 생성되었다 삭제되었다면 실제 DB에는 아무 동작이 전송되지 않을 수 있다.
- 즉, 여러가지 동작이 많이 발생하더라도 쿼리는 트랜잭션당 최적화 되어 최소쿼리만 날라가게된다. (DB조회 수를 감소시켜 서버 부하를 낮춤)
but. 키 생성전략이
generationType.IDENTITY로 설정되어있는경우
단일쿼리로 수행함으로써 외부 트랜잭션에 의한 중복키 생성을 막기위해 쓰기지연 발생x
