요새는 집중이 잘 안되서 고민 입니다. 차라리 코딩을 한다면 시간도 빨리가고 좋지만 요새는 면접준비와 공부를 하느라 정신이 없습니다.
그리고 카카오 커머스 1차 코딩테스트 결과가 나왔는데 합격입니다. 간단한 집합, dfs와 비트마스킹 + dp가 나왔습니다. 요새 dp와 비트마스킹이 인기인 것 같습니다. 트리도 요새 좀 많이나오는 것 같고..
만약 코테를 준비하신다면 구현, dfs, bfs, 트리, dp, 그리디를 우선적으로 풀어보시는 것을 추천 드립니다.
운영체제
오늘은 페이징 메모리 관리에서 present bit에 관련된 메커니즘을 배웠습니다. 사실 전에 페이지 스왑 알고리즘과 페이지를 불러오는 것을 간단하게 알고 있었는데 이번에는 캐싱의 원리와 함께 page fault가 일어났을 때 어떤 일이 하드웨어에서 일어나고 운영체제가 어떤 일을 해야하는지에 대해 공부했습니다.

page fault를 처리하는 흐름입니다. 만약 TLB에서 page를 찾았는데 present bit이 False라면 트랩을 일으켜 트랩핸들러를 통해 page fault를 처리합니다. 위에 코드가 어떻게 처리하는지를 잘 보여주고 있습니다.
만약 PFN(page frame number)가 -1이라면 현재 메모리에 빈 공간이 없다는 의미이기 때문에 원래 있던 메모리를 내쫓아야 합니다.
내 쫓는 방법은 크게 4가지가 존재합니다. OPT, FIFO, Random, LRU로 OPT는 사실 실제 운영체제에 적용할 수 없는 가장 이상적인 지표를 나타내는 알고리즘입니다. 우리가 나중에 미래를 예측해서 어떤 작업이 어떤 순서로 사용될지 알게 된 것을 가정하고 알고리즘을 만든 것이기 때문에 비교 지표로 쓰이는 알고리즘입니다.
OPT는 간단하게 가장 나중에 사용될 것을 내쫓는다고 생각하시면 편합니다.
FIFO 알고리즘은 우리에게도 익숙한 선입 선출방법입니다. 성능이 썩 좋지 않고 locality를 전혀 고려하지 않은 알고리즘이기 때문에 별로 좋지 않습니다. locality는 나중에 캐시를 다룰 때에 좀 더 자세히 서술하겠습니다. 심지어 이 FIFO 알고리즘은 Belay's exception이라고 메모리를 늘리면 오히려 table miss가 줄어야 하는데 fifo알고리즘은 이상하게 종종 메모리를 늘리면 더 miss가 많이 나는 예외 사항도 존재합니다.
Radom은 말 그대로 무작위로 내쫓는 것입니다. 오히려 FIFO보다 좋은 것은 규모가 커지면 커질 수록 그나마 쓸만한 성능을 나타낸다 합니다. 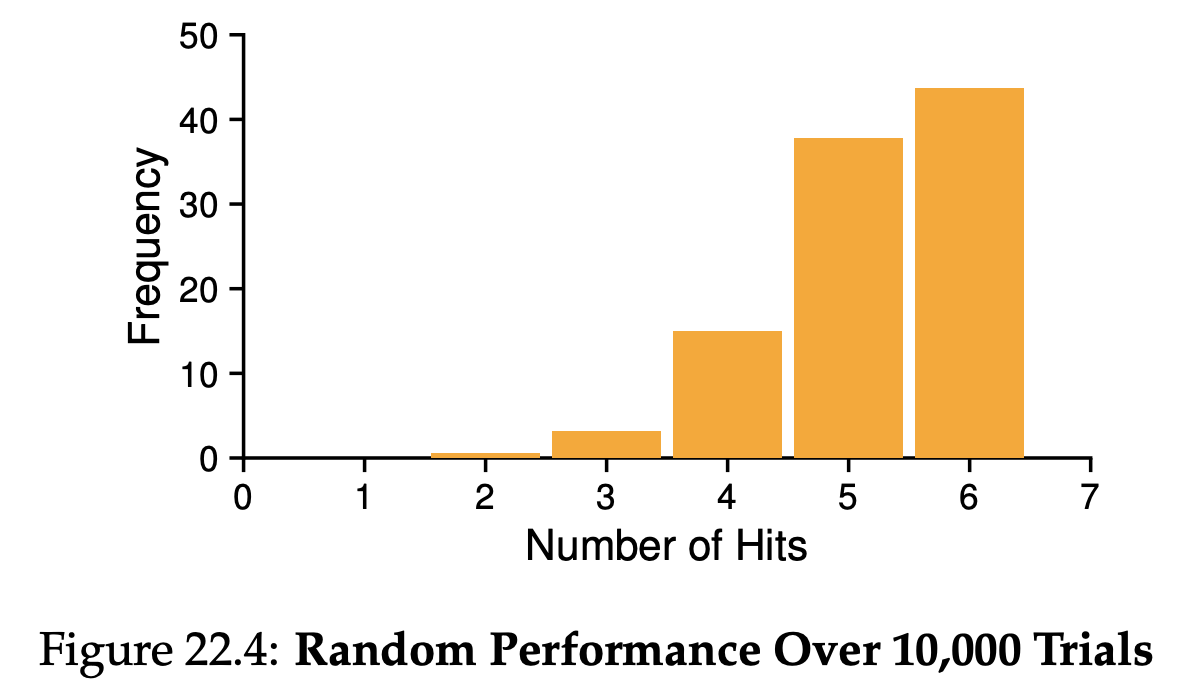
마지막으로 LRU는 Least Recently Used의 줄임말로 가장 최근에 사용이 안된 친구를 내쫓는 것을 의미합니다. 가장 합리적이고 FIFO와 Random과 다르게 locality를 고려해 훨씬 hit rate이 높습니다. 아마 링크드 리스트와 해시를 통해 제작한다면 빠른 속도를 유지하면서 구현 할 수 있을 것이라 생각됩니다.
쫓아낸 이후 자리가 만들어 졌다면 하드 디스크에서 불러와 (프로세스는 I/O 작업으로 인한 Blocked 상태) 메모리에 올리고 전에 요청했던 작업을 다시 진행합니다.
여기서 제가 헷갈렸던 것은 만약 메모리로 올라온 페이지는 페이지 테이블에 등록이 되어있을까? 에 대한 질문이었습니다. 저는 당연히 등록이 되어있는 줄 알았지만 등록이 안되어 TLB miss가 한번 더 발생이 한다고 합니다. 깊이 생각하지 않으면 계속 헷갈릴 수 있었던 부분이었습니다.
추가적으로 캐시에 대한 이야기와 캐시 라인에 대한 이야기를 해볼까 합니다.
캐시는 왜 빠르게 무엇인가에 접근 할 수 있을까요? -> 이것에 대한 답변은 지역성으로 설명할 수 있습니다.
지역성에는 두가지가 있는데 시간적 지역성(temporal locality)와 공간적 지역성(spatial locality)입니다.
시간적 지영성은 반복문 처럼 최근 접근한 데이터를 자주 사용할 수 있다는 특징입니다.
공간적 지역성은 배열 처럼 연속된 데이터는 페이지에 몰려있어 캐시에 저장하게 된다면 적은 호출 빈도를 통해 데이터에 접근하는 시간을 줄이게 되는 것입니다.
이런 특징들로 저장해 두고 있는 데이터들을 빠르게 호출 할 수 있게 됩니다.
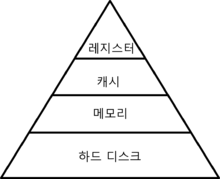
컴퓨터 메모리 구조는 다음과 같은 형태입니다. 크기가 클 수록 용량이 크고 작을 수록 빠르게 접근 할 수 있습니다. 레지스터는 거의 CPU나 하드웨어에서 관리하고 직접적으로 계산합니다.
페이징 구조에서는 두가지 캐시가 발생합니다. 하나는 하드디스크에서 메모리로 옮기는 캐슁, 그리고 메모리에서 캐시로 올리는 캐시라인 두 가지가 존재합니다.
하드디스크에서 메모리로 올리는 페이징은 위에서 말씀드렸던 presnet bit이 False라면 page falut 가 발생하고 TLB를 통해 빠르게 접근이 가능합니다.
또 다른 캐슁으로 캐시 라인은 자주 사용하는 페이지 블록 (바이트 단위로 구성된 여러개의 페이지 테이블 엔트리) 들을 캐시 메모리로 올리는 것을 뜻합니다. 주로 32byte나 64byte로 구성된 이 블록들은 여러 페이지 정보를 가지고 있는 덩어리 입니다. 이 캐시라인은 태그, 인덱스, 셀렉트로 구성되어 있습니다. 캐시에는 실제 주소들과 함께 페이지들의 위치를 같이 저장해 두었기 때문에 빠르게 접근이 가능합니다.
